TF-IDF算法
转自:http://www.cnblogs.com/eyeszjwang/articles/2330094.html
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被正规化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)对于在某一特定文件里的词语 ti 来说,它的重要性可表示为:

以上式子中 ni,j 是该词在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中
- |D|:语料库中的文件总数
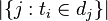 :包含词语ti的文件数目(即
:包含词语ti的文件数目(即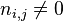 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用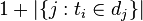
然后
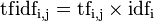
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
在向量空间模型里的应用
TF-IDF权重计算方法经常会和余弦相似度(cosine similarity)一同使用于向量空间模型中,用以判断两份文件之间的相似性。
TF-IDF的理论依据及不足
TF-IDF算法是建立在这样一个假设之上的:对区别文档最有意义的词语应该是那些在文档中出现频率高,而在整个文档集合的其他文档中出现频率少的词 语,所以如果特征空间坐标系取TF词频作为测度,就可以体现同类文本的特点。另外考虑到单词区别不同类别的能力,TF-IDF法认为一个单词出现的文本频数 越小,它区别不同类别文本的能力就越大。因此引入了逆文本频度IDF的概念,以TF和IDF的乘积作为特征空间坐标系的取值测度,并用它完成对权值TF的
调整,调整权值的目的在于突出重要单词,抑制次要单词。但是在本质上IDF是一种试图抑制噪音的加权 ,并且单纯地认为文本频数小的单词就越重要,文本频数大的单词就越无用,显然这并不是完全正确的。IDF的简单结构并不能有效地反映单词的重要程度和特征 词的分布情况,使其无法很好地完成对权值调整的功能,所以TF-IDF法的精度并不是很高。
此外,在TF-IDF算法中并没有体现出单词的位置信息,对于Web文档而言,权重的计算方法应该体现出HTML的结构特征。特征词在不同的标记符中 对文章内容的反映程度不同,其权重的计算方法也应不同。因此应该对于处于网页不同位置的特征词分别赋予不同的系数,然后乘以特征词的词频,以提高文本表示 的效果。
TF-IDF算法的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- windows多线程详解
转自:http://blog.csdn.net/zhouxuguang236/article/details/7775232 在一个牛人的博客上看到了这篇文章,所以就转过来了,地址是http://bl ...
- java杂记——数组拷贝
这里介绍两种java提供的数组拷贝方法: (1)Arrays提供的copyOf(T src, T desLength)和copyOfRange(T src, int from, int to) (2) ...
- MATLAB中stem函数用法
stem(Y) 将数据序列Y从x轴到数据值按照茎状形式画出,以圆圈终止.如果Y是一个矩阵,则将其每一列按照分隔方式画出. stem(X,Y)在X的指定点处画出数据序列Y. stem(...,'fil ...
- Linux学习笔记(7)Linux常用命令之压缩解压命令
(1)gzip gzip命令用于压缩文件,英文原意为GNU zip,所在路径/bin/gzip,其语法格式为: gzip [文件] 压缩后的文件格式为.gz. 例:将/etc目录下的services文 ...
- 【MongoDB --番外】错误集合
1.在第一次安装成功之后,就瞬间发现了如下问题 mongodb无法启动,由于目标计算机积极拒绝,无法连接 解决方法: 这不是mongodb无法启动,是你还没有启动mongodb就来连接使用它了,肯定是 ...
- MVVM模式下实现拖拽
在文章开始之前先看一看效果图 我们可以拖拽一个"游戏"给ListBox,并且ListBox也能接受拖拽过来的数据, 但是我们不能拖拽一个"游戏类型"给它. 所以 ...
- requireJS的使用_API(1)
之前有介绍过requireJS(模块化开发),可以看看 ,但是不详细,所以今天参考官网来详细介绍一下: 1.加载js文件: RequireJS的目标是鼓励代码的模块化,它使用了不同于传统<scr ...
- zookeeper启动错误 transaction type: 2 error: KeeperErrorCode = NoNode for /hbase
hbase伪分布式,与zookeeper同一台机器的时候,运行一段时间,启动zookeeper的时候,日志中有如下错误,导致无法启动zookeeper java.io.IOException: Fai ...
- iOS学习28之UITabBarController
1. 标签视图控制器 -- UITabBarController 视图(UIView) ---> 图层 ---> 子视图 视图控制器(UIViewController) ---> 管 ...
- webpack练手项目之easySlide(二):代码分割(转)
在上一篇 webpack练手项目之easySlide(一):初探webpack 中我们一起为大家介绍了webpack的基本用法,使用webpack对前端代码进行模块化打包. 但是乍一看webpack ...