SQL Server 索引中include的魅力(具有包含性列的索引)
2010-01-11 20:44 by 听风吹雨, 22580 阅读, 24 评论, 收藏, 编辑
开文之前首先要讲讲几个概念
【覆盖查询】
当索引包含查询引用的所有列时,它通常称为“覆盖查询”。
【索引覆盖】
如果返回的数据列就包含于索引的键值中,或者包含于索引的键值+聚集索引的键值中,那么就不会发生Bookup Lookup,因为找到索引项,就已经找到所需的数据了,没有必要再到数据行去找了。这种情况,叫做索引覆盖;
【复合索引】
和复合索引相对的就是单一索引了,就是索引只包含一个字段,所以复合索引就是包含两个或者多个字段的索引;
【非键列】
键列就是在索引中所包含的列,当然非键列就是该索引之外的列了;
下面就开始今天的主题
【摘要1】
在 SQL Server 2005 中,可以通过将非键列添加到非聚集索引的叶级别来扩展非聚集索引的功能。通过包含非键列,可以创建覆盖更多查询的非聚集索引。这是因为非键列具有下列优点:
* 它们可以是不允许作为索引键列的数据类型。
* 在计算索引键列数或索引键大小时,数据库引擎不考虑它们。
当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。
说明:第一:只能是针对非聚集索引;第二:比起复合索引是有性能上的提升的,因为索引的大小变小了;
【摘要2】
键列存储在索引的所有级别中,而非键列仅存储在叶级别中。
说明:这就表现为包含与不包含的关系了。有关索引级别的详细信息,请参阅表组织和索引组织。
【摘要3】
使用包含性列以避免大小限制
可以将非键列包含在非聚集索引中,以避免超过当前索引大小的限制(最大键列数为 16,最大索引键大小为 900 字节)。数据库引擎计算索引键列数或索引键大小时,不考虑非键列。
例如,假设要为 AdventureWorks 示例数据库的 Document 表中的以下列建立索引:
Title nvarchar(50)
Revision nchar(5)
FileName nvarchar(400)
因为 nchar 和 nvarchar 数据类型的每个字符需要 2 个字节,所以包含这三列的索引将超出 900 字节的大小限制 10 个字节 (455 * 2)。使用 CREATE INDEX 语句的 INCLUDE 子句,可以将索引键定义为 (Title, Revision),将 FileName 定义为非键列。这样,索引键大小将为 110 个字节 (55 * 2),并且索引仍将包含所需的所有列。下面的语句就创建了这样的索引。
说明:当你把一个nvarchar(500)的字段设置为主键的时候,你就可以看到不能超出900字节的提示了。一般来说我们是不太会做这些操作的,所以那个错误提示也是不常见的,也许你可能还见过。
一个数据页的大小才8k,所以我们合理的设置每个字段的大小,不要浪费太多的空间,这样对查询也是有好处的,这个include就比较好的的解决了索引和空间的问题,虽然那些include的数据也会占用空间。
虽然可以设置include,但是也尽量不要使用太多的字段作为索引包含的非键列。
【摘要4】
带有包含性列的索引准则
设计带有包含性列的非聚集索引时,请考虑下列准则:
* 在 CREATE INDEX 语句的 INCLUDE 子句中定义非键列。
* 只能对表或索引视图的非聚集索引定义非键列。
* 除 text、ntext 和 image 之外,允许所有数据类型。
* 精确或不精确的确定性计算列都可以是包含性列。有关详细信息,请参阅为计算列创建索引。
* 与键列一样,只要允许将计算列数据类型作为非键索引列,从 image、ntext 和 text 数据类型派生的计算列就可以作为非键(包含性)列。
* 不能同时在 INCLUDE 列表和键列列表中指定列名。
* INCLUDE 列表中的列名不能重复。
说明:include不能使用在聚集索引中。后面的两点,这个在实际中很难想象会有这样的需求要把重复列放到一个索引中。如果有朋友遇到过这样的需求可以告知一些,不胜感激。那如果有是否可以通过不同的列名(其实保存是同样的值)来解决这个问题呢??
【摘要5】
列大小准则
* 必须至少定义一个键列。最大非键列数为 1023 列。也就是最大的表列数减 1。
* 索引键列(不包括非键)必须遵守现有索引大小的限制(最大键列数为 16,总索引键大小为 900 字节)。
* 所有非键列的总大小只受 INCLUDE 子句中所指定列的大小限制;例如,varchar(max) 列限制为 2 GB。
说明:varchar(max)这样的定义是在2005之后才有的,所以这些数值也是对2005后的版本才生效的。
最大的表列数为:1024
最大非键列数为:
【摘要6】
修改已定义为包含性列的表列时,要受下列限制:
* 除非先删除索引,否则无法从表中删除非键列。
* 除进行下列更改外,不能对非键列进行其他更改:
o 将列的为空性从 NOT NULL 改为 NULL。
o 增加 varchar、nvarchar 或 varbinary 列的长度。
* 这些列修改限制也适用于索引键列。
说明:这些细小的东西一直没有注意过。所以要记录下来,用来“防身”,呵呵。
【摘要7】
设计建议
重新设计索引键大小较大的非聚集索引,以便只有用于搜索和查找的列为键列。将覆盖查询的所有其他列设置为包含性非键列。这样,将具有覆盖查询所需的所有列,但索引键本身较小,而且效率高。
说明:也就是说把常用的where后面的条件查询的字段作为索引的键列,而需要返回的字段就作为索引包含的非键列。
如果where的是两个或两个以上的谓词的话,这个索引就可以创建为复合索引了。以前天真的认为要返回的字段只能通过在复合索引中入这些字段,不管它是否会用来做谓词。看到这篇文章,才有了豁然开朗的感觉。
【摘要8】
USE AdventureWorks;
GO
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
说明:这个是使用include的语法,在表的设计中的索引设计中是没有办法选择的;
【摘要9】
性能注意事项
避免添加不必要的列。添加过多的索引列(键列或非键列)会对性能产生下列影响:
* 一页上能容纳的索引行将更少。这样会使 I/O 增加并降低缓存效率。
* 需要更多的磁盘空间来存储索引。特别是,将 varchar(max)、nvarchar(max)、varbinary(max) 或 xml 数据类型添加为非键索引列会显著增加磁盘空间要求。这是因为列值被复制到了索引叶级别。因此,它们既驻留在索引中,也驻留在基表中。
* 索引维护可能会增加对基础表或索引视图执行修改、插入、更新或删除操作所需的时间。
您应该确定修改数据时在查询性能上的提升是否超过了对性能的影响,以及是否需要额外的磁盘空间要求。有关评估查询性能的详细信息,请参阅查询优化。
说明:“这是因为列值被复制到了索引叶级别”这句很好的说明了物理上的存储结构和原理。
【图片解析】
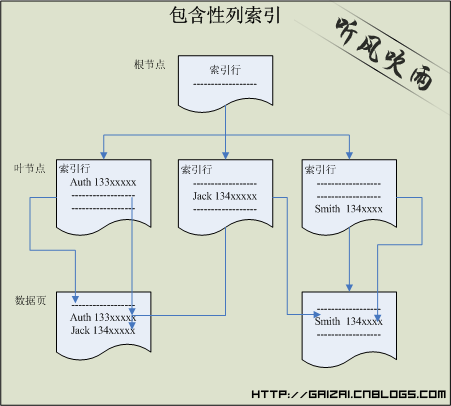
上图也说明了为什么不能在聚集索引中建立具有包含性列的索引,因为非聚集索引的叶层是由索引页而不是由数据页组成,这就得说到聚集和非聚集索引的的物理存储了,聚集索引的顺序排序和存储就是基表的顺序和存储结构。
【一个例子】
SELECT UserName,Password,RealName,Mobile,Age FROM bw_Users WHERE UserName = XXX AND Age = XX
说明:
- 这是一个我们很常见的查询语句,我们如何提高查询效率呢?
- 首先我们来看看谓词,这条语句是通过UserName = XXX AND Age = XX作为条件的,那么我们就应该建立一个组合索引,也称为复合索引,注意索引中的键列的位置,先UserName后Age;
- 其实上面那个是一个非聚集索引,那我们就可以把Password,RealName,Mobile这三列作为索引包含列;
- 所以,最终就是建立一个以UserName 和 Age做为键列、Password,RealName,Mobile作为非键列的非聚集索引;
- 通常来说我们系统的用户表并不是很大,所以这样的优化起不了很明显的效果,如果有兴趣的可以使用大表进行性能测试;
【其它】
- 有一点我很奇怪,那就是为什么在修改表的时候,为什么【包含的列】是不可用的?只能通过命令来编写该类索引?
- 另外一点我想说,微软的MSDN的确是最好的学习工具,在网络上搜索出来的东西很多都是重复的,而且说的不全,不过能讲的比较简单、通俗而已。所以有空还是多看看MSDN吧。这句话是对自己说的。呵呵。
SQL Server 索引中include的魅力(具有包含性列的索引)的更多相关文章
- [转帖]SQL Server 索引中include的魅力(具有包含性列的索引)
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 上个 ...
- SQL Server 索引中include的魅力(具有包含性列的索引)(转载)
开文之前首先要讲讲几个概念 [覆盖查询] 当索引包含查询引用的所有列时,它通常称为“覆盖查询”. [索引覆盖] 如果返回的数据列就包含于索引的键值中,或者包含于索引的键值+聚集索引的键值中,那么就不 ...
- 索引中include的魅力(具有包含性列的索引) (转)
开文之前首先要讲讲几个概念 [覆盖查询] 当索引包含查询引用的所有列时,它通常称为“覆盖查询”. [索引覆盖] 如果返回的数据列就包含于索引的键值中,或者包含于索引的键值+聚集索引的键值中,那么就不会 ...
- SQL Server 索引中include
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 开文 ...
- SQL Server 2005 中的分区表和索引
SQL Server 2005 中的分区表和索引 SQL Server 2005 69(共 83)对本文的评价是有帮助 - 评价此主题 发布日期 : 3/24/2005 | 更新 ...
- SQL server 表中如何创建索引?
SQL server 表中如何创建索引?看个示例,你就会了 use master goif db_id(N'zhangxu')is not nulldrop database zhangxugocre ...
- SQL Server 2016中In-Memory OLTP继CTP3之后的新改进
SQL Server 2016中In-Memory OLTP继CTP3之后的新改进 转译自:https://blogs.msdn.microsoft.com/sqlserverstorageengin ...
- SQL Server 执行计划利用统计信息对数据行的预估原理以及SQL Server 2014中预估策略的改变
前提 本文仅讨论SQL Server查询时, 对于非复合统计信息,也即每个字段的统计信息只包含当前列的数据分布的情况下, 在用多个字段进行组合查询的时候,如何根据统计信息去预估行数的. 利用不同字段 ...
- SQL Server 2008中的数据压缩
SQL Server 2008中引入了数据压缩的功能,允许在表.索引和分区中执行数据压缩.这样不仅可以大大节省磁盘的占用空间,还允许将更多数据页装入内存中,从而降低磁 盘IO,提升查询的性能.当然,凡 ...
随机推荐
- ES5中新增的Array方法详细说明
一.前言-索引 ES5中新增的不少东西,了解之对我们写JavaScript会有不少帮助,比如数组这块,我们可能就不需要去有板有眼地for循环了. ES5中新增了写数组方法,如下: forEach (j ...
- Leetcode Unique Paths
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below). The ...
- 【BZOJ3122】【SDoi2013】随机数生成器
Description Input 输入含有多组数据,第一行一个正整数T,表示这个测试点内的数据组数. 接下来T行,每行有五个整数p,a,b,X1,t,表示一组数据.保证X1和t都是合法的页码. ...
- ios8 tableView设置滑动删除时 显示多个按钮
** * tableView:editActionsForRowAtIndexPath: //设置滑动删除时显示多个按钮 * UITableViewRowAction ...
- Selenium_模拟淘宝登录Demo
package com.lkb.start; import com.alibaba.fastjson.JSONObject; import com.lkb.bean.Entity; import co ...
- Emmet:HTML/CSS代码快速编写神器
本文来源:http://www.iteye.com/news/27580 ,还可参考:http://www.w3cplus.com/tools/emmet-cheat-sheet.html Em ...
- 【MongoDB】2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errno:10061 由于目标计算机积极拒绝,无法连接。
1:启动MongoDB 2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errn ...
- 相邻div实现一个跟着另一个自适应高度示例代码
方法一: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> < ...
- Hadoop.2.x_网站PV示例
一.网站基本指标(即针对于网站用户行为而产生的日志中进行统计分析) 1. PV:网页浏览量(Page View页面浏览次数,只要进入该网页就产生一条记录,不限IP,统计点每天(较多)/每周/每月/.. ...
- Android中Activity的四种启动模式
要了解Android的启动模式先要了解一下Activity的管理方式: 1.Activity的管理机制 Android的管理主要是通过Activity栈来进行的.当一个Activity启动时,系统根据 ...