Recurrent Neural Network(循环神经网络)
Reference: Alex Graves的[Supervised Sequence Labelling with RecurrentNeural Networks]
Alex是RNN最著名变种,LSTM发明者Jürgen Schmidhuber的高徒,现加入University of Toronto,拜师Hinton。
统计语言模型与序列学习
1.1 基于频数统计的语言模型
NLP领域最著名的语言模型莫过于N-Gram。
它基于马尔可夫假设,当然,这是一个2-Gram(Bi-Gram)模型:
任意一个词$W_{i}$出现的概率只同它前面的词$W_{i-1}$有关。
迁移到N-Gram中,就变成:
在一个句子当中,一个单词的T出现的概率,和其前N个单词是有关的:
$P(W_{t}|W_{t-N}....,W_{t-1},W_{t+1}....,W_{t+N})$
早期计算Bi-Gram的方法,正如吴军博士所著的《数学之美》里科普的那样,采用词频统计法:
$P(W_{i}|W_{i-1})=\frac{P(W_{i-1},W_{i})}{P(W_{i-1})}\approx \frac{Cnt(W_{i-1},W_{i})}{Cnt(W_{i-1})}$
只需要统计一下$W_{i}$、$W_{i-1}$一起出现的频数就可以了。
看起来确实很简单,很数学之美。当然,作为一本科普读物,它是不会告诉你这种方法是有多大危害的。
具体实现,可以使用以下两个算法:
①KMP:将$W_{i}$、$W_{i-1}$两个词拼在一起,跑一次Text串。
②AC自动机:同样拼接,不过是预先拼好所有的模式串,输入AC自动机里,仅仅跑一次Text串。
但如果你是一名ACM选手,应该对AC自动机深有体会,这玩意简直就是内存杀手。
两者相害,取其轻。很明显,实际运用的时候,根本不会考虑KMP,优先选择空间换时间的AC自动机算法。
在[CS224D Lecture7]中,Socher提到了N-Gram频数统计法的state-of-art结果,[Heafield 2013]
看看Abstract就够吓人了:
Using one machine with 140 GB RAM for 2.8 days, we built an unpruned model on 126 billion tokens.
还是建立在 MapReduce 上。这种吃硬件的方法,不得不说,真是够糟糕的。
1.2 基于神经网络的语言模型
Neural Network Language Model (NNLM),最早正式在[Bengio03]提出。
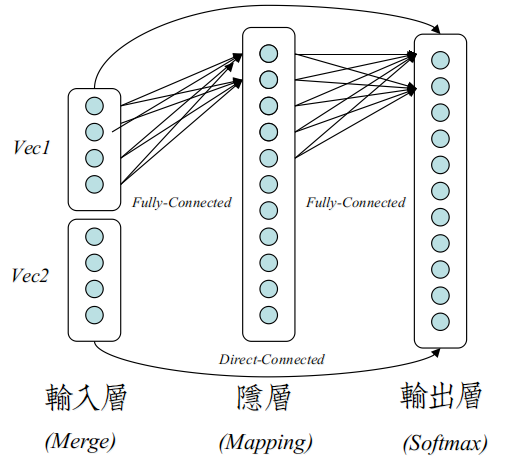
Bengio使用的是一个经典的前馈网络来训练N-Gram不同之处在于,输入层是可训练的。
输入层最后被训练成Word Vector,在[Mikolov13]提出Word2Vec之前,大多称为Word Embeddings。
具体的方法:
①为每个词,构建$|N*Dim|$的向量参数。这点与Word2Vec的简化方法有所不同。
Word2Vec取消训练了词序信息,所以向量大小是$|Dim|$。
②拿到一个句子,句子长度是T,利用词的索引,组合出$|T,N*Dim|$的输入矩阵。
③如普通NN一样,Softmax误差,BP传播,更新。
NNLM方法,轻量的复现的N-Gram模型,需要更少的内存。且无须做平滑处理,如[Katz backoff]。
1.3 序列学习
正如朴素贝叶斯假设一样,马尔可夫假设也是一种糟糕的近似。
对于一个词$W_{i}$,只覆盖前N个词,很多时候是抓不住重点的。
最好的解决方案,当然是对于一个词$W_{i}$,覆盖其前面的所有词。
模仿动态规划原理,构建成一个动态序列模型。这需要Recurrent Neural Network(RNN)来实现。
RNN通常译为循环神经网络,其类似动态规划的原理,也可译为时序递归神经网络。
当然还有结构递归神经网络RNN(Recursive Neural Network),使用频率不高,没落。
通常RNN指的是时序递归RNN。
RNN结构与更新
2.1 经典之作:Elman's Simple Recurrent Networks(SRN)
J. L. Elman提出的SRN是RNN系中结构最简单的一个变种,相较于传统的2层FC前馈网络,它仅仅在FC层添加了时序反馈连接。

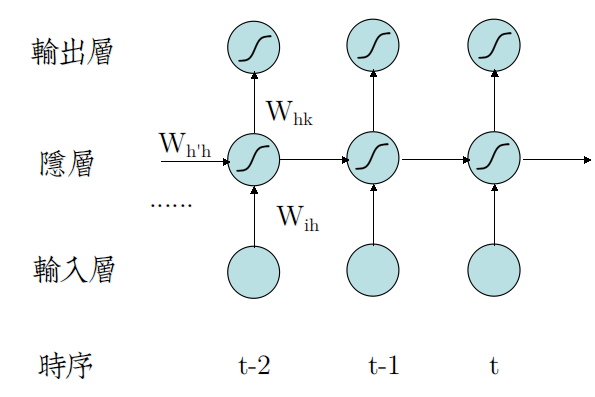
左图是不完整的结构图,因为循环层的环太难画,包含自环、交叉环。
所以RNN一般都画成时序展开图,如右图。
从时序展开图中,容易看出,SRN在时序t时,前面的全部状态,压缩在一起,输入到当前隐层中。
因而,RNN可以看成是具有动态深度结构的图模型,随着时序的增加,网络深度越来越大,因而属于深度神经网络。
2.2 前向传播
较于2层前馈网络,唯一变化是,时序为$t$时,隐层输入由两部分组成:
①输入层映射变换。(非递归)
②时序为$t-1$时,隐层神经元的激活输出。(时序递归)
以下用$a_{j}^{t}$表示神经元j的输入,$b_{j}^{t}$表示神经元j的激活后输出,为表示清晰,忽略Bias。
输入到达隐层时,有:
$a_{h}^{t}=\sum_{i=1}^{I}w_{ih}x_{i}^{t}+\sum_{h^{'}=1}^{H}w_{h^{'}h}b_{h^{'}}^{t-1}$
多出的$h^{'}->h$变换,大可称为隐隐层变换,为前馈网络带来记忆槽。
它记忆着时序$[1,t-1]$到达输出层之前的神经元的全部状态。
激活隐层神经元后,有:
$b_{h}^{t}=Activation(a_{h}^{t})$
经过输出层后,有:
$y_{k}^{t}=Softmax(W_{hk}b_{h}^{t})$
2.3 反向传播
仿照BP网络一样,定义局部梯度:
$\delta _{y}^{t}=\frac{\partial \mathcal{L}}{\partial b_{y}^{t}} \cdot \frac{\partial b_{y}^{t}}{\partial a_{y}^{t}}$
也就是说,从似然函数开始,由链式尾,导到$\partial W$的前一步。
对输出层,有:
$\frac{\partial \mathcal{L}}{\partial W_{hk}}=\delta_{k}^{t}\cdot\frac{\partial a_{j}^{t}}{\partial W_{hk}}$
$\delta_{k}^{t}$即,Softmax里的 $(1\{y_{i}=j\}-P(y^{(i)}=j|x;\theta_{j})),j=1,2....k$
对隐隐层,有:
$\frac{\partial \mathcal{L}}{\partial W_{h^{'}h}}=\sum_{p=1}^{t}\frac{\partial \mathcal{L}}{\partial b_{k}^{t}}\cdot\frac{\partial b_{k}^{t}}{\partial a_{k}^{t}}\cdot\frac{\partial b_{h}^{t}}{\partial b_{h}^{p}}\cdot\frac{\partial b_{h}^{p}}{\partial W_{h^{'}h}} \qquad where \quad \frac{\partial b_{h}^{t}}{\partial b_{h}^{p}}=\prod_{j=p+1}^{t}\frac{\partial b_{h}^{j}}{\partial b_{h}^{j-1}}$
上式来自[CS224d Lecture7],是RNN的Feet of Clay,需要牢记。
因为需要累乘,相当于求一个超深度神经网络结构的梯度,会带来严重的Gradient Vanish\Exploding。下文会详细描述。
至于为什么可以写成那样,你可以用一个简单的单神经元,无激活函数的网络推一下:
$a_{3}=wx_{3}+w^{'}a_{2}=....=wx_{3}+w^{'}wx_{2}+(w^{'})^{2}wx_{1}\\\\\frac{\partial a_{3}}{w^{'}}=????\\\\Answer=\frac{\partial a_{3}}{\partial a_{3}}\cdot\frac{\partial a_{3}}{w^{'}}+\frac{\partial a_{3}}{\partial a_{3}}\cdot\frac{\partial a_{3}}{\partial a_{2}}\cdot\frac{\partial a_{2}}{w^{'}}+\frac{\partial a_{3}}{\partial a_{3}}\cdot\frac{\partial a_{3}}{\partial a_{2}}\cdot\frac{\partial a_{2}}{\partial a_{1}}\cdot\frac{\partial a_{1}}{w^{'}}$
同样,去掉后面的部分,有局部梯度:
$\delta_{h^{'}}^{t}=\sum_{p=1}^{t}\frac{\partial \mathcal{L}}{\partial b_{k}^{t}}\cdot\frac{\partial b_{k}^{t}}{\partial a_{k}^{t}}\cdot\frac{\partial b_{h}^{t}}{\partial b_{h}^{p}} \qquad where \quad \frac{\partial b_{h}^{t}}{\partial b_{h}^{p}}=\prod_{j=p+1}^{t}\frac{\partial b_{h}^{j}}{\partial b_{h}^{j-1}}$
这样,对隐层,就有著名的BPTT更新法则,正如[Alex]书中所写:
$\delta _{h}^{t}=Activation^{'}(a_{h}^{t})\begin{pmatrix}\sum_{k=1}^{K}\delta _{k}^{t}w_{hk}+\sum_{h^{'}=1}^{H}\delta _{h^{'}}^{t+1}w_{hh^{'}}\end{pmatrix}$
当然$\delta _{h^{'}}^{T+1}$会越界,等于0。
这里,最头疼的是,为什么隐隐层的局部梯度是取决于时序t+1的?
这个需要跨越一步来看,$W^{t}$不仅会在当前时序t,作为隐层参数出现,还会在时序t+1,作为隐隐层的附加参数出现。
这样,链式法则波及到了时序t,以及时序t+1,所以局部梯度由两部分组成,这是BPTT更新法的精髓。
最后一部分:
$\frac{\partial \mathcal{L}}{\partial W_{ih}}=\frac{\partial \mathcal{L}}{\partial a_{h}^{t}}\cdot\frac{\partial a_{h}^{t}}{\partial W_{ih}}=\delta _{h}^{t}x_{i}^{t}$
RNN与语义分析
RNN的祖先是1982年提出的Hopfield网络。
Hopfield网络因为实现困难,外加没有合适应用,被86年后的前馈网络取代。
90年代恰逢神经网络衰落期,前馈MLP在Optimization上被揪出种种弊端,又被SVM取代。
在Represention上,CV界老一辈还在用着hand-made特征,Speech&NLP也偏重Statistics的特征。
1990年提出的两种变种RNN,Elman&Jordan SRN同样因为没有合适的实际应用,很快又被无视。
过了十几年,遇上了DL热潮,RNN被研究出具有挖掘语义信息的Distrubuted Represention能力。
终于被拿来做Speech和Language Model方面语义分析相关任务。
3.1 记忆特性
一个时长为T的Simple RNN,unfold(展开)后实质是一个深度为T的前馈网络。
序列上所有的输入信息、non-linearity变换的隐态信息从开始时刻,一直保留至当前时刻。
从生物神经学角度,就是长期记忆(Long-Term Memory)特性。
前馈网络不是万能的,尽管在CV上大放光彩,但确实不适合解决逻辑问题。
Prolog曾经大放光彩,很多人坚信概率解决不了逻辑智能问题,但被RNN打脸了,比如下面这个问题:

RNN就能够通过长记忆,向前搜索出输入中的关键信息。
3.2 Gradient Vanish
深度神经网络的头号问题就是Gradient Vanish,尤其是比MLP还要深多少倍的RNN。
★数学角度:[Bengio94]给出了Simple RNN出现Gradient Vanish的原因:
$\left | \prod_{j=p+1}^{t}\frac{\partial b_{h}^{j}}{\partial b_{h}^{j-1}}\right |\leqslant (\beta_{W}\cdot\beta_{h})^{t-p} \quad where \quad \beta =UpperBound$
W、h两个参数矩阵,先积后幂,导致上界突变速度飞快,要么$\rightarrow 0$,要么$\rightarrow \infty$
如若引入大量的饱和Non-Linearity,如Sigmoid(Logistic|Tanh),那么最普遍的情况就是$Gradient \rightarrow 0$
★生物学角度:

术语称之为Long-Term Memory退化到Short-Term Memory,只能记忆短期记忆。
3.3 RNNLM
尽管Simple RNN有诸多缺陷,但Short-Term Memory毕竟聊胜于无。
[Mikolov10]最先提出用RNN来做LM,不过并没有用Word Embedings。
RNNLM从sentence-level切入,把一个sentence看成是一个sequence,逐个跑word推动时序。
3.4 RNN For Speech Understanding
[Mesnil13]则又将RNN同最近比较火的Word Embedings结合起来。
这篇paper是Bengio组Mesnil和在微软实习的时候和Redmond研究院语音领域两位大牛Xiaodong He、Li Deng合作的。
目测是在MS传播导师的Theano。(OS:看你们还在公式推Gradient,啊哈哈哈)

3.4.1 Word embeddings
回过头来再看[Mikolov13]的Word2Vec,13年开始真是全民玩起了词向量。
[Mesnil13]总结了词向量的几点好处:
★以较小的维度向量,提纯出Word的N维的欧几里得空间信息,俗称降维。
★可以先在Wiki之类的大型Corpus上Pre-Training出部分语义语法信息,
然后根据实际任务Fine-Tuning,符合深度学习原则。
★大幅度提升Generalization。
3.4.2 Context Window
另一个流行起来的Trick就是Context Window,Word2Vec的核心之一。
不同的是,Word2Vec丢弃了窗口词的空间排列信息,而正常方法则选择将窗口词合并。
[Bengio03]中的词向量,是在词典里直接取整个Dim长度的向量,设Dim=350。
而做了Context Window之后,单个词的Dim变小,通常为(50|100),窗口大小通常为(3~19):
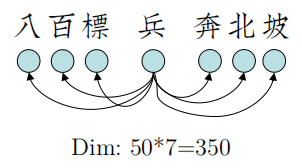
[Mesnil13]给出Context Window的唯一作用:
★强化短期记忆(Short-Term)
看起来不是很有说服力,从Word2Vec来看,起码还有这些作用:
★强化上下文信息捕捉能力
★强化语义、语法信息捕捉能力
Recurrent Neural Network(循环神经网络)的更多相关文章
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- 循环神经网络(Recurrent Neural Network,RNN)
为什么使用序列模型(sequence model)?标准的全连接神经网络(fully connected neural network)处理序列会有两个问题:1)全连接神经网络输入层和输出层长度固定, ...
- 4.5 RNN循环神经网络(recurrent neural network)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 RNN循环神经网络 ...
- Recurrent Neural Network(递归神经网络)
递归神经网络(RNN),是两种人工神经网络的总称,一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
- Recurrent Neural Network系列4--利用Python,Theano实现GRU或LSTM
yi作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORK ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
随机推荐
- JavaScript基础——数据类型
JavaScript使用数据类型来确定如何处理被分配给一个变量的数据.变量的类型决定了你可以对变量进行什么操作,如循环或者执行.下面描述了最常用的变量类型. 字符串(String):此数据类型将字符数 ...
- elk安装(这个是初级的可以把这个套件安上)
http://udn.yyuap.com/doc/logstash-best-practice-cn/index.html ELK其实并不是一款软件,而是一整套解决方案,是三个开源软件Elastics ...
- Oracle Redo Log
http://blog.itpub.net/27039319/viewspace-2120623/ 11.2和11.2以下的区别:http://blog.itpub.net/27039319/view ...
- linux清除当前屏幕
linux清除当前屏幕:直接clear命令即可 而在windows下的话用cls命令
- maven 错误: 程序包org.junit不存在
该错误在入门例子中使用mvn clean test时出现该错误. 原因: 测试用例应该放在src/test/java/...路径下,我是放在了src/main/java/..路径下了. 因为没有遵守其 ...
- jq与js 区别
$(this).html(666); <div id="a">123</div> <script> $("#a").clic ...
- hdu 2509 博弈 *
多堆的情况要处理好孤单堆 #include<cstdio> #include<iostream> #include<algorithm> #include<c ...
- [Oracle] PL/SQL学习笔记
-- 1. 使用一个变量 declare -- Local variables here v_name ); begin -- Test statements here select t.user_n ...
- [SQL]查询及删除重复记录的SQL语句
一:查询及删除重复记录的SQL语句1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select ...
- 【使用Unity开发Windows Phone上的2D游戏】(1)千里之行始于足下
写在前面的 其实这个名字起得不太欠当,Unity本身是很强大的工具,可以部署到很多个平台,而不仅仅是可以开发Windows Phone上的游戏. 只不过本人是Windows Phone 应用开发出身, ...