提升50%!Presto如何提升Hudi表查询性能?
分享一篇关于使用Hudi Clustering来优化Presto查询性能的talk

talk主要分为如下几个部分
- 演讲者背景介绍
- Apache Hudi介绍
- 数据湖演进和用例说明
- Hudi Clustering介绍
- Clustering性能和使用
- 未来工作

该talk的演讲者为Nishith Agarwal和Satish Kotha,其中Nishith Agarwal是Apache Hudi PMC成员,在Uber任职团队Leader,Satish Kotha是Apache Hudi Committer,也在Uber任职软件工程师。

什么是Apache Hudi?Hudi是一个数据湖平台,提供了一些核心功能,来构建和管理数据湖,其提供的核心能力是基于DFS摄取和管理超大规模数据集,包括:增量数据库摄取、日志去重、存储管理、事务写、更快的ETL数据管道、数据合规性约束/数据删除、唯一键约束、处理延迟到达数据等等。

现在Hudi在Uber内部的生产应用规模已经达到了一个新台阶,数据总规模超过了250PB,8000+张表,每天摄取5000亿条数据。

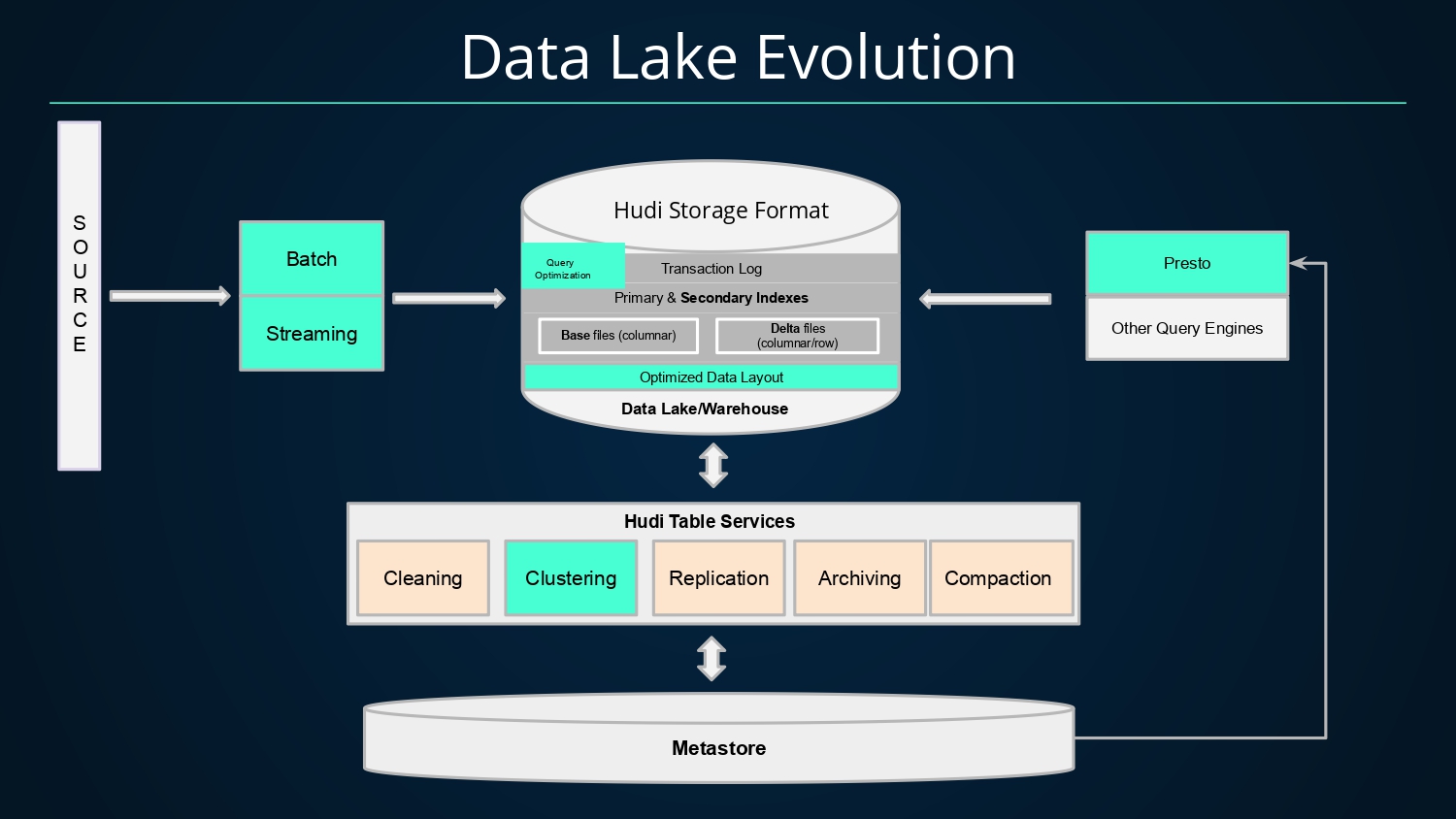
基于Hudi的数据湖架构演进如下。通过批、流方式将数据以Hudi格式写入数据湖中,而Hudi提供的事务、主键索引以及二级索引等能力均可加速数据的写入,数据写入Hudi后,数据文件的组织会以列存(基础文件)和行存(增量日志文件)方式存储,同时借助Hudi提供的各种表服务,如
- Cleaning:清理服务,用来清理过期版本的文件;
- Clustering:数据聚簇,将文件按照某些列进行聚簇,以重新布局,达到优化查询性能的效果;
- Replication:复制服务,将数据跨地域进行复制;
- Archiving:归档服务,归档commit元数据,避免元数据不断膨胀;
- Compaction:压缩服务,将基础文件和增量日志文件进行合并,生成新版本列存文件,提升查询性能;
而对于查询引擎而言,Hudi可以将其表信息注册至Metastore中,查询引擎如Presto即可与Metastore交互获取表的元信息并查询表数据。
由于Uber内部大规模使用了Presto查询引擎,下面重点介绍Hudi和PrestoDB的集成细节。

现阶段PrestoDB支持查询两种Hudi表类型:针对读友好的COPY_ON_WRITE类型(存列存格式)和写友好的MERGE_ON_READ类型(列存+行存格式);支持已经相对完备。

介绍完Hudi和PrestoDB集成现状后,来看看使用案例和场景,Hudi与Presto的集成是如何降低成本和提高查询性能的

大数据场景下,对于写入(摄取)和查询引擎的优化思路通常不同,可以从两个维度进行对比,如数据位置和文件大小,对于写入而言,数据位置一般决定于数据到达时间,文件大小则更倾向于小文件(小文件可减小写入延迟);而对于查询而言,数据位置会更倾向于查询的数据在同一位置,文件大小则更倾向于大文件,小文件带来额外的开销。

有没有一种方式可以兼顾写入和查询呢,答案是肯定的,引入Clustering,对于Clustering,说明如下。
Clustering是Hudi提供的一种改变数据布局的框架
- 提供了可插拔的策略来重组数据;
- 开源版本提供了一些开箱即用的策略;
Clustering还提供了非常灵活的配置
- 可以单独挑出部分分区进行数据重组;
- 不同分区可使用不同方式处理;
- 支持不同粒度的数据重组:全局、本地、自定义方式;
Clustering提供了快照隔离和时间旅行
- 与Hudi的Rollback和Restore兼容;
- 更新Hudi元数据和索引;
Clustering还支持多版本并发控制
- Clustering可与摄取并发执行;
- Clustering和其他Hudi表服务如Compaction可并发执行;

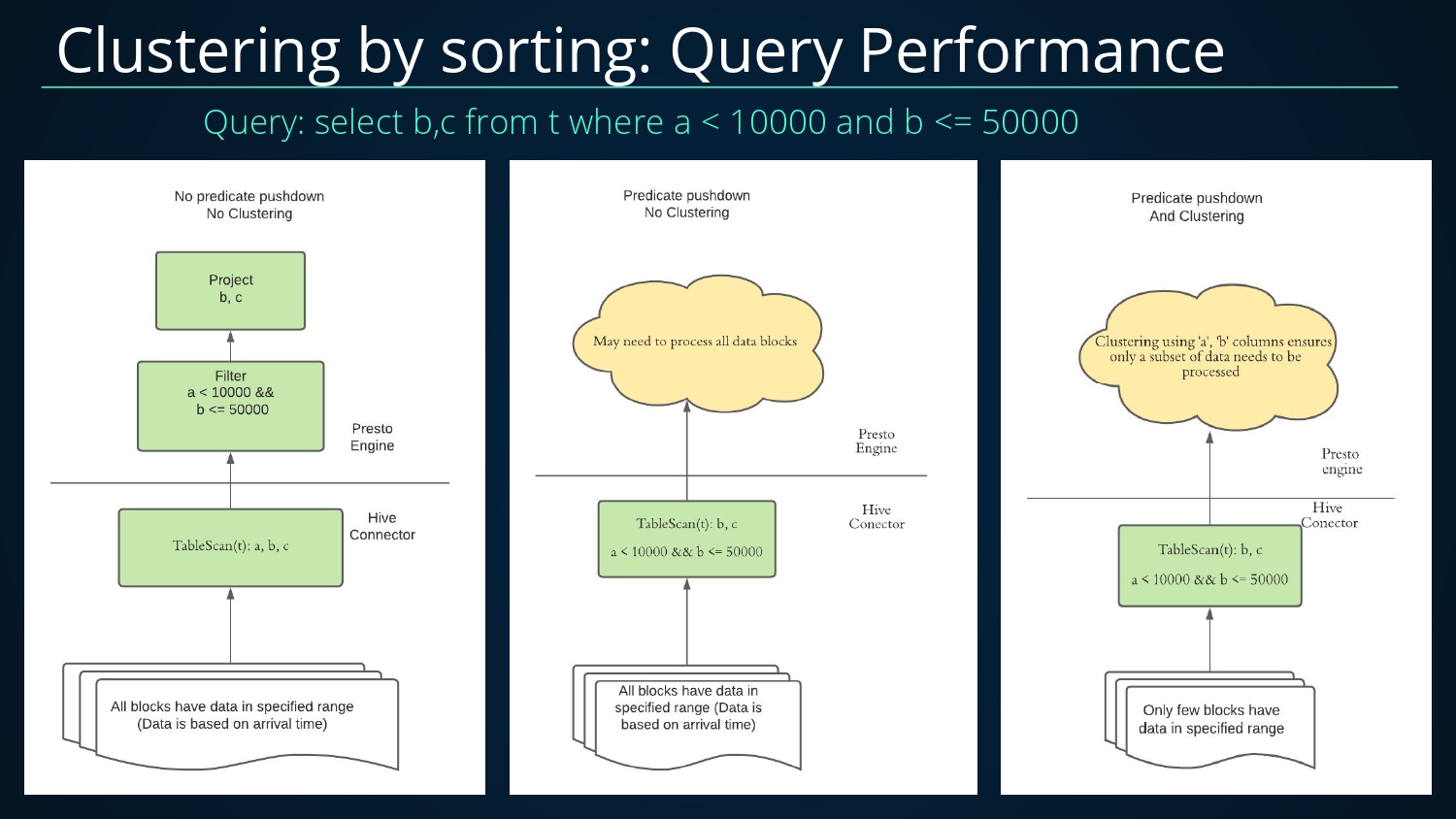
下面来看一个使用Clustering来提高查询性能的案例,使用的的SQL如下select b,c from t where a < 10000 and b <= 50000;列举了三种情况。
- 未下推但未进行Clustering,扫描的文件数很多;
- 下推但未进行Clustering,扫描及处理的文件数也很多;
- 下推并且进行Clustering,扫描及处理的数据量变得较少;
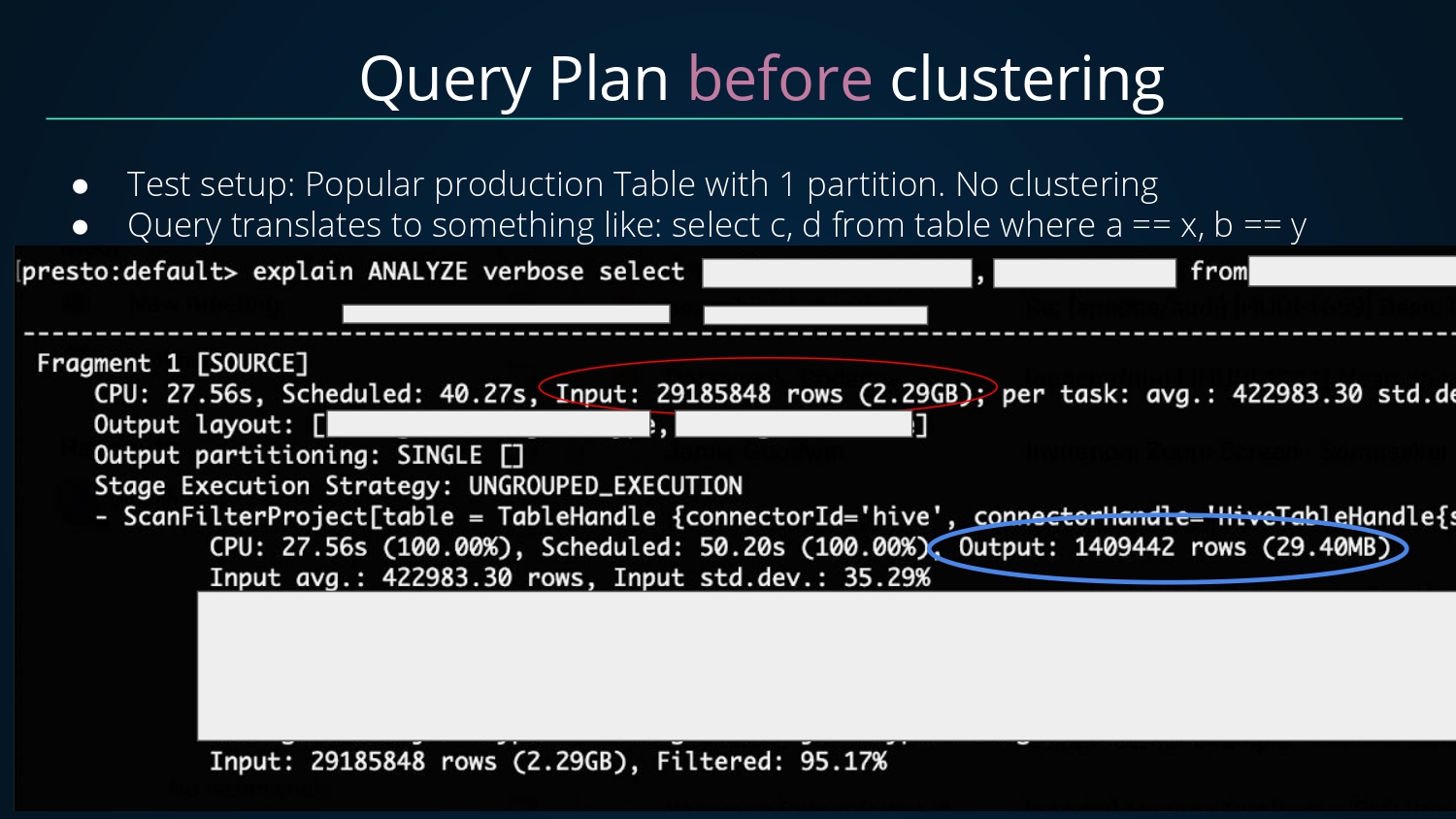
接着看看未进行Clustering之前的查询计划,总共扫描输入了2900W+条数据,最后过滤输出了140W+条数据,过滤掉数据的比例达95.17%;
经过Clustering之后的执行计划,总共扫描输入了371W+条数据,最后过滤输出了140W+条数据;相比未进行Clustering,扫描的数据量从2900W+减少到了371W+;可见Clustering的效果提升非常显著。
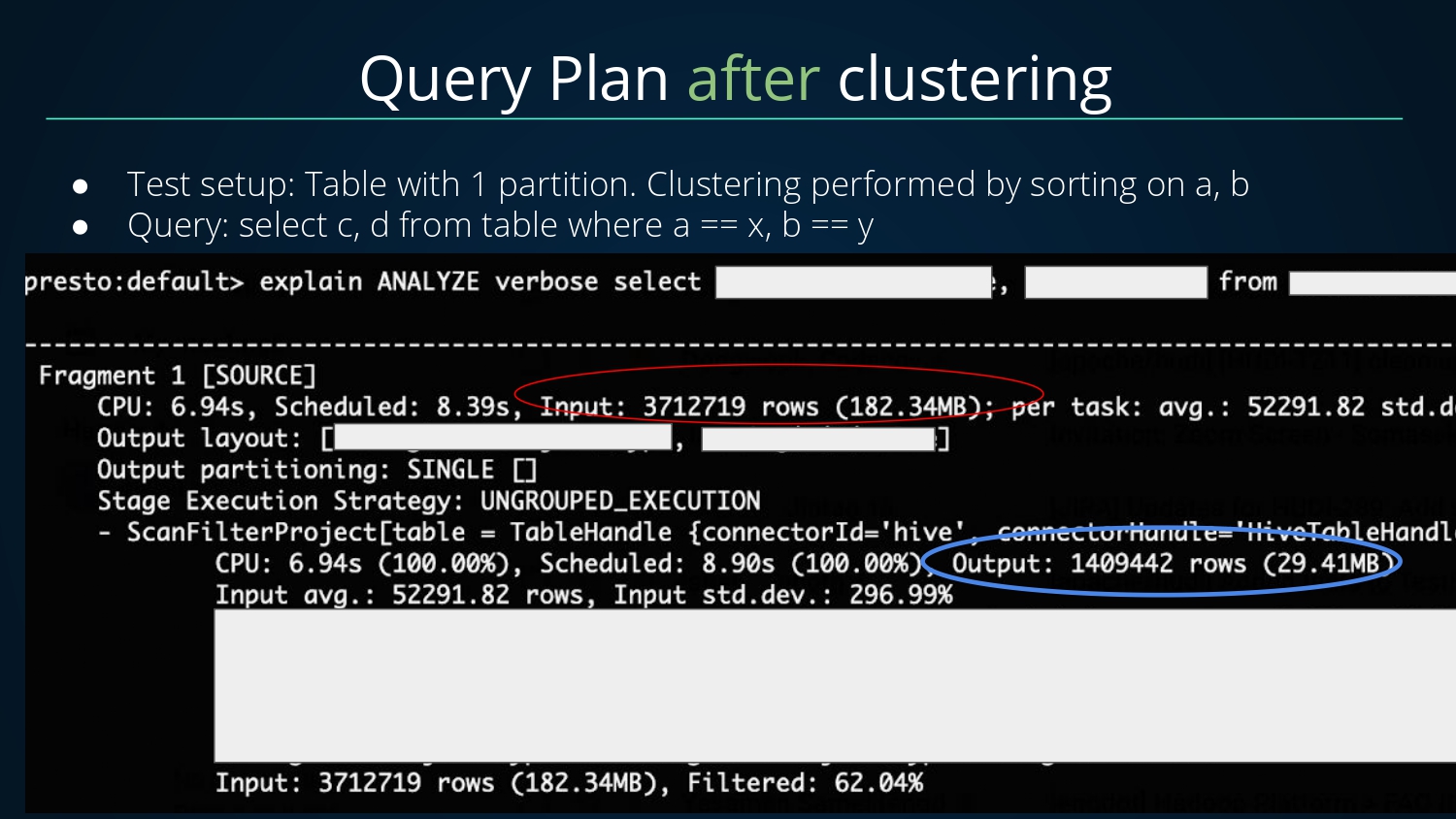
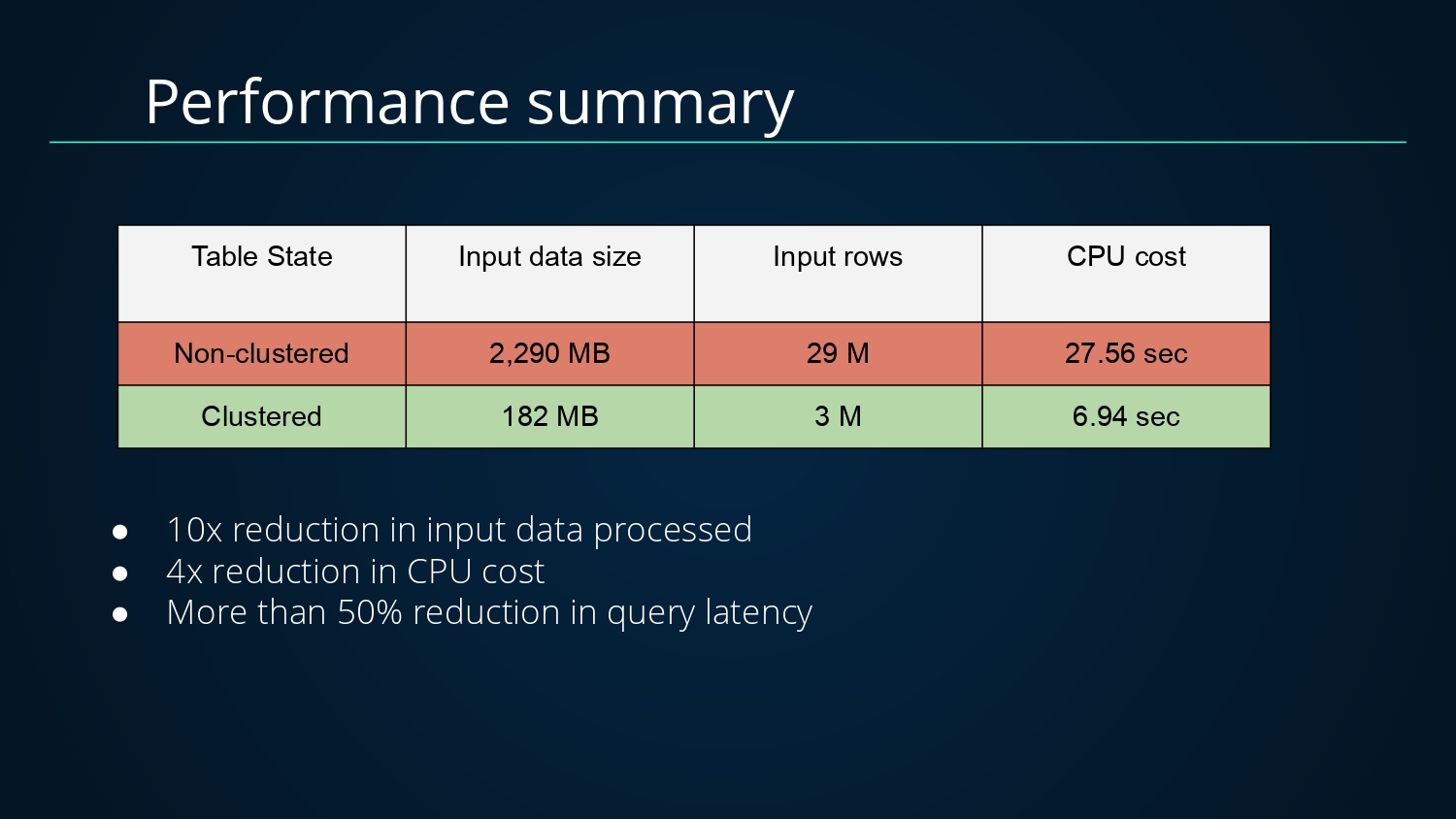
对于Clustering带来的查询性能优化如下
- 未进行Clustering,扫描输入数据量大小为2290MB,条数为2900W+,CPU耗时27.56S
- 进行Clustering后,扫描输入数据量大小为182MB,条数为300W+,CPU耗时6.93S
扫描数据量减少了10倍,CPU消耗减少了4倍,查询延迟降低了50%+
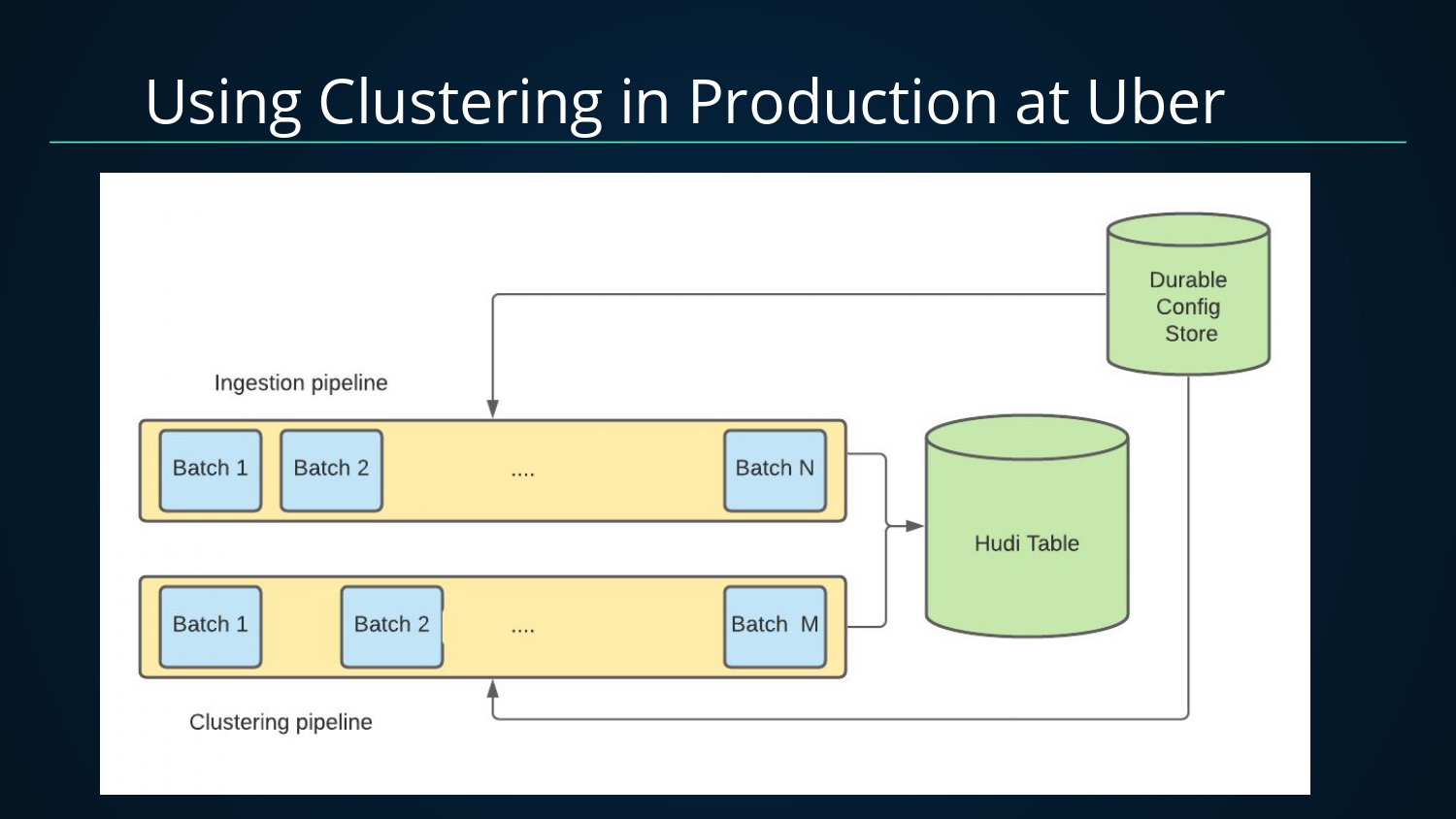
基于Clustering可提供强大的的性能优化,在Uber内部也已经在生产上使用了Clustering,利用了Clustering可以和摄入并发执行的特性。生产中使用了两条Pipeline,一条摄入Pipeline,一条Clustering Pipeline,这样摄入Pipeline可以不断产生新的小文件,而通过异步的Clustering Pipeline将小文件合并,从而对查询端暴露大文件,避免查询端受写入端产生太多小文件问题影响。
关于通过Clustering加速Presto的查询性能上面已经讲述完了,当然对于Clustering还有后续的规划:落地更多的用例;将Clustering作为一个更轻量级的服务调用;分优先级及分层(如多个Job跨表重组数据布局);根据历史查询性能优化新的数据布局;在Presto中添加二级索引进一步减少查询时间;提升重写性能(如对于某些策略降低重写数据开销);

好了,今天的分享就这里,欢迎关注Hudi邮件列表dev@hudi.apache.org 以及 star & fork https://github.com/apache/hudi
提升50%!Presto如何提升Hudi表查询性能?的更多相关文章
- Oracle Spatial分区应用研究之一:分区与分表查询性能对比
1.名词解释 分区:将一张大表在物理上分成多个分区,逻辑上仍然是同一个表名. 分表:将一张大表拆分成多张小表,不同表有不同的表名. 两种数据组织形式的原理图如下: 图 1分表与分区的原理图 2.实验目 ...
- Oracle总结【SQL细节、多表查询、分组查询、分页】
前言 在之前已经大概了解过Mysql数据库和学过相关的Oracle知识点,但是太久没用过Oracle了,就基本忘了...印象中就只有基本的SQL语句和相关一些概念....写下本博文的原因就是记载着Or ...
- Elasticsearch索引和查询性能调优的21条建议
Elasticsearch部署建议 1. 选择合理的硬件配置:尽可能使用 SSD Elasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能.使用SSD(PCI-E接口SSD卡/SA ...
- 查询性能提升3倍!Apache Hudi 查询优化了解下?
从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持. 1. 背景 Amazon EMR 团队最近发表了一 ...
- 填坑!线上Presto查询Hudi表异常排查
1. 引入 线上用户反馈使用Presto查询Hudi表出现错误,而将Hudi表的文件单独创建parquet类型表时查询无任何问题,关键报错信息如下 40931f6e-3422-4ffd-a692-6c ...
- 【宇哥带你玩转MySQL】索引篇(一)索引揭秘,看他是如何让你的查询性能指数提升的
场景复现,一个索引提高600倍查询速度? 首先准备一张books表 create table books( id int not null primary key auto_increment, na ...
- 天天动听MP3解码器性能提升50%
天天动听今日升级提醒,发现有一句 “使用新的MP3解码器,性能提升50%”,太惊讶了. 之前版本的MP3解码器使用libmpg123,效果已经是MP3解码器中非常不错的了. 50%的提升,应该不仅仅是 ...
- day056-58 django多表增加和查询基于对象和基于双下划线的多表查询聚合 分组查询 自定义标签过滤器 外部调用django环境 事务和锁
一.多表的创建 from django.db import models # Create your models here. class Author(models.Model): id = mod ...
- Phoenix表和索引分区数对插入和查询性能的影响
1. 概述 1.1 HBase概述 HBase由master节点和region server节点组成.在100-105集群上,100和101是master节点,102-105是region serve ...
随机推荐
- flutter兼论
Flutter是Google开发的一套全新的跨平台.开源UI框架,支持iOS.Android系统开发,并且是未来新操作系统Fuchsia的默认开发套件.自从2017年5月发布 第一个版本以来,目前Fl ...
- sqli-labs系列——第一关
先看了一遍关于sql的一些知识点,通关sqli-labs加深下印象.之前也因为作业的原因通关过前10关,但那时候不懂得原理,跟着网上的教程做的,所以这次尝试自己思考通关. less1 尝试and1=2 ...
- 国产mcu理论数据评估工作记录
目录 前言 简要工作记录 前言 时间:20210315 主要记录这两天对国内各IC厂商的 MCU 了解记录. 大环境,ST 厂商 MCU 疯狂涨价,国内 MCU 也越来越完善,还便宜.同时,全球缺晶圆 ...
- 学习C#第一天
学习C#第一天 先是了解了VS 2019编辑器的基本使用 安装Visual Studio https://mp.weixin.qq.com/s?__biz=MzU0MTg5NDkzNA==&m ...
- 分享一次排查CLOSE_WAIT过多的经验
关键词:TCP.CLOSE_WAIT 问题背景 某日下午有测试人员急匆匆的跑来跟我反馈:"有客户反馈供应商附件预览不了,流程阻塞,需要紧急处理",我立马精神起来,毕竟都是付费客户( ...
- Vue.js 带下拉选项的输入框(Textbox with Dropdown)组件
带下拉选项的输入框 (Textbox with Dropdown) 是既允许用户从下拉列表中选择输入又允许用户自由键入输入值.这算是比较常见的一种 UI 元素,可以为用户提供候选项节省操作时间,也可以 ...
- BUAA_2020_OO_UNIT4_REVIEW&ALL_REVIEW
OO第四单元总结&&学期总结 1. 第四单元作业总结 本单元三次作业都围绕了UML图的建模展开,第十三次作业只有类图,第十四次作业增加了顺序图和状态图,第十五次增加了部分UML规则的判 ...
- Spring-@PostConstruct注解
@PostConstruct注解 @PostConstruct注解好多人以为是Spring提供的.其实是Java自己的注解. Java中该注解的说明:@PostConstruct该注解被用来修饰一个非 ...
- (数据科学学习手札118)Python+Dash快速web应用开发——特殊部件篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- 哈工大LTP基本使用-分词、词性标注、依存句法分析、命名实体识别、角色标注
代码 import os from pprint import pprint from pyltp import Segmentor, Postagger, Parser, NamedEntityRe ...