论文解读(MPNN)Neural Message Passing for Quantum Chemistry
论文标题:DEEP GRAPH INFOMAX
论文方向:
论文来源:ICML 2017
论文链接:https://arxiv.org/abs/1704.01212
论文代码:
1 介绍
本文的目标是证明:「能够应用于化学预测任务的模型可以直接从分子图中学习到分子的特征,并且不受到图同构的影响。」
本文提出的 MPNN 是一种用于图上监督学习的框架。为此,作者将应用于图上的监督学习框架称之为消息传递神经网络(MPNN),这种框架是从目前比较流行的支持图数据的神经网络模型中抽象出来的一些共性,抽象出来的目的在于理解它们之间的关系。
本文以 QM9 作为 benchmark 数据集,该数据集由 $130k$ 个分子组成,每个分子有 $13$个特征,这些特征是通过一种计算昂贵的量子力学模拟方法(DFT)近似生成的,相当于 $13$ 个回归任务。这些任务似乎代表了许多重要的化学预测问题,并且目前对许多现有方法来说是困难的。
本文给出的一个例子是利用 MPNN 框架代替计算代价昂贵的 DFT 来预测有机分子的量子特性:
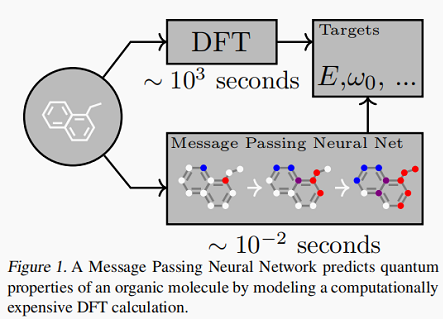
本文提出的模型的性能度量采用两种形式:
- DFT近似的平均估计误差;
- 化学界已经确立的目标误差,称为“化学精度”。
2 消息传递神经网络(MPNN)
本文首先通过八篇文献来举例验证 MPNN 框架的通配性。
3 论文文献总结
Paper 1 : Convolutional Networks for Learning Molecular Fingerprints, Duvenaud et al. (2015)
消息传递函数为:
$M\left(h_{v}, h_{w}, e_{v w}\right)=\left(h_{w}, e_{v w}\right)$
其中 $(., .) $ 表示拼接 (concat) ;
节点更新函数为:
$U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=\sigma\left(H_{t}^{d e g(v)} m_{v}^{t+1}\right)$
其中 $ \sigma$ 为 sigmoid 函数, $ \operatorname{deg}(v) $ 表示节点 $ v$ 的度, $ H_{t}^{N}$ 是一个可学习的矩阵,$ \mathrm{t}$ 为时间步, $ \mathrm{N}$ 为节点度;读出函数 $ \mathrm{R} $ 将先前所有隐藏层的状态 $ h_{v}^{t}$ 进行连接:
$R=f\left(\sum \limits _{v, t} \operatorname{softmax}\left(W_{t} h_{v}^{t}\right)\right)$
其中 $f$ 是一个神经网络,$ W_{t}$ 是一个可学习的读出矩阵。
在消息传递阶段可能会存在一些问题,如最终的消息向量分别对连通的节点和连通的边求和 $m_{v}^{t+1}=\left(\sum h_{w}^{t}, \sum e_{v w}\right) $。可见,该模型实现的消息传递无法识别节点和边之间的相关性。
Paper 2 : Gated Graph Neural Networks (GG-NN), Li et al. (2016)
消息传递函数为:
$M_{t}\left(h_{v}^{t}, h_{w}^{t}, e_{v w}\right)=A_{e_{v w}} h_{w}^{t}$
其中 $A_{e_{v w}}$ 是 $e_{v w}$ 的一个可学习矩阵,每条边都会对应那么一个矩阵。
更新函数为:
$U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=G R U\left(h_{v}^{t}, m_{v}^{t+1}\right)$
其中 $GRU$ 为门控制单元 (Gate Recurrent Unit) 。使用了权值捆绑(weight tying),所以在每一个时间步 $\mathrm{t}$ 下都会使用相同的更新函数。
读出函数 $\mathrm{R}$ 为:
$R=\sum \limits_{v \in V} \sigma\left(i\left(h_{v}^{(T)}\right), h_{v}^{0}\right) \odot\left(j\left(h_{v}^{(T)}\right)\right)$
其中 $i$ 和 $j$ 为神经网络, $\odot$ 即哈达玛积,表示元素相乘。
Paper 3 : Interaction Networks, Battaglia et al. (2016)
$M\left(h_{v}, h_{w}, e_{v w}\right)$ 是一个以 $\left(h_{v}, h_{w}, e_{v w}\right)$ 为输入的神经网络。
节点更新函数:
$U\left(h_{v}, x_{v}, m_{v}\right)$ 是一个以 $\left(h_{v}, x_{v}, m_{v}\right)$ 为输入的神经网络。
读出函数 $\mathrm{R}$(图级别的输出):
$R=f\left(\sum_{v \in G} h_{v}^{T}\right)$ ,其中 $\mathrm{f}$ 是一个神经网络,输入是最终的隐藏层状态的和。原论文中 $T=1$ 。
Paper 4 : Molecular Graph Convolutions, Kearnes et al. (2016)
该论文与其他 MPNN 稍有不同,主要区别在于考虑了边表示 $e_{v, w}^{t}$ ,并且在消息传递阶段会进行更新。
消息传递函数用的是节点的消息:
$M_{t}\left(h_{v}^{t}, h_{w}^{t}, e_{v w}^{t}\right)=e_{v w}^{t}$
节点的更新函数:
$U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=\alpha\left(W_{1}\left(\alpha\left(W_{0} h_{v}^{t}\right), m_{v}^{t+1}\right)\right)$
其中 $ (., .) $ 表示拼接 (concat), $ \alpha$ 为 $ \operatorname{ReLU}$ 激活函数, $ W_{0}$,$W_{1}$ 为可学习权重矩阵。
边状态的更新定义为:
$e_{v w}^{t+1} =U_{t}^{\prime}\left(e_{v w}^{t}, h_{v}^{t}, h_{w}^{t}\right) =\alpha\left(W_{4}\left(\alpha\left(W_{2}, e_{v w}^{t}\right), \alpha\left(W_{3}\left(h_{v}^{t}, h_{w}^{t}\right)\right)\right)\right)$
其中,$W_{i}$ 为可学习权重矩阵。
Paper 5 : Deep Tensor Neural Networks, Schutt et al. (2017)
$M_{t}=\tanh \left(W^{f c}\left(\left(W^{c f} h_{w}^{t}+b_{1}\right) \odot\left(W^{d f} e_{v w}+b_{2}\right)\right)\right)$
其中 $ W^{f c}, W^{c f}, W^{d f}$ 为矩阵, $ b_{1}, b_{2}$ 为偏置向量;
更新函数:
$U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=h_{v}^{t}+m_{v}^{t+1}$
读出函数(通过单层隐藏层接受每个节点并且求和后输出):
$R=\sum_{v} N N\left(h_{v}^{T}\right)$
Paper 6 : Laplacian Based Methods, Bruna et al. (2013); Defferrard et al. (2016); Kipf \& Welling (2016)
基于拉普拉斯矩阵的方法将图像中的卷积运算扩展到网络图 $G$ 的邻接矩阵 $A$ 中。
在 Bruna et al. (2013); Defferrard et al. (2016)的工作中:
消息函数:
$M_{t}\left(h_{v}^{t}, h_{w}^{t}\right)=C_{v w}^{t} h_{w}^{t}$
其中,矩阵 $C_{v w}^{t}$ 为拉普拉斯矩阵 $L$ 的特征向量组成的矩阵;
更新函数:
$U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=\sigma\left(m_{v}^{t+1}\right)$
$M_{t}\left(h_{v}^{t}, h_{w}^{t}\right)=C_{v w} h_{w}^{t}$
其中, $C_{v w}=(\operatorname{deg}(v) \operatorname{deg}(w))^{-1 / 2} A_{v w} $;
更新函数:
$U_{v}^{t}\left(h_{v}^{t}, m_{v}^{t+1}\right)=\operatorname{Re} L U\left(W^{t} m_{v}^{t+1}\right)$
上述模型都是 MPNN 框架的不同实例,作者呼吁大家应致力于将这一框架应用于某个实际应用,并根据不同情况对关键部分进行修改,从而引导模型的改进,这样才能最大限度的发挥模型的能力。
4 MPNN 变种
4.1 Message Functions
作者将 MPNN 框架应用于分子预测领域,提出了 MPNN 的变种,并以 QM9 数据集为例进行实验。任务是根据分子结构预测分子所属类别。
作者主要是基于 GG-NN 来探索 MPNN 的多种改进方式(不同的消息函数、输出函数等)。
下文中以 $d$ 代表节点特征的维度,以 $n$ 代表图的节点数量。同样适用于有向图,入边和出边有分别的信息通道,那么节点 $v$ 的信息 $m_{v}$ 由 $m_{v}^{i n}$ 和 $m_{v}^{out }$ 拼接而成。在无向图中,可以将无向图的边看做两条边,一条入边和一条出边,有相同的标签,那么信息通道的大小是 $2 d$ 而不是 $d$ 。
模型的输入是每个节点的特征向量 $x_{v}$ 以及邻接矩阵 $A$ ,邻接矩阵 $A$ 具有向量分量,表示分子中的不同化学键以及两个原子之间的成对空间距离。初始状态 $h_{v}^{0}$ 是原子输入特征集合 $x_{v}$ ,并且需要 padding 到维度 $d$。在实验中的每个时间步 $t$ 都要进行权重共 享 , 并且更新函数 GRU。
消息函数:
GG-NN 采用的消息函数,采用矩阵相乘的方式(GG-NN 的边有离散的标签):
$M\left(h_{v}, h_{w}, e_{v w}\right)=A_{e_{v w}} h_{w}$
$M\left(h_{v}, h_{w}, e_{v w}\right)=A\left(e_{v w}\right) h_{w}$
其中, $A\left(e_{v w}\right)$ 是一个神经网络,将边的向量 $e_{v w}$ 映射到 $\mathrm{d} \times \mathrm{d}$ 维矩阵。
上述两种消息函数的特点是,从节点 $v$ 到节点 $w$ 的函数仅与隐藏层状态 $h_{v}$ 和边向量 $e_{v w}$ 有关,而和隐藏状态 $h_{v}^{t}$ 无关。实际上,节点消息同时依赖于源节点 $v$ 和目标节点 $w$ 的话,网络的消息通道将会得到更有效的利用。所以也可以尝试去使用一种消息函数的变种:
$m_{v w}=f\left(h_{w}^{t}, h_{v}^{t}, e_{v w}\right)$
其中, $f$ 为神经网络。
4.2 Virtual Graph Elements
本文作者探索了两种不同的消息传递方式。
- 为没有连接的节点添加一个虚拟的边,这样消息便具有更长的传播距离;
- 使用潜在的“主”节点(master node),这个节点可以通过特殊的边来连接到图中任意一个节点。主节点充当了一个全局的暂存空间,每个节点都会在消息传递过程中通过主节点进行读取和写入。同时允许主节点具有自己的节点维度,以及内部更新函数(GRU)的单独权重。目的同样是为了在传播阶段传播很长的距离。
4.3 Readout Functions
作者尝试了两种读出函数:
考虑 GG-NN 中的读出函数:
$R=\sum \limits_{v \in V} \sigma\left(i\left(h_{v}^{(T)}\right), h_{v}^{0}\right) \odot\left(j\left(h_{v}^{(T)}\right)\right)$
考虑 set2set 模型。set2set 模型是专门为在集合运算而设计的,并且相比简单累加节点的状态来说具有更强的表达能力。模型首先通过线性映射将数据映射到元组 $ \left(h_{v}^{t}, x_{v}\right)$ ,并将投影元组作为输入 $ T=\left\{\left(h_{v}^{T}, x_{v}\right)\right\}$,然后经过 $\mathrm{M}$ 步计算后, set2set 模型会生成一 个与节点顺序无关的 Graph-level 的 embeedding 向量,从而得到我们的输出向量。
4.4 Multiple Towers
考虑 MPNN 的伸缩性。
对一个稠密图来说,消息传递阶段的每一个时间步的时间复杂度为 $O\left(n^{2} d^{2}\right)$,其中 $\mathrm{n}$ 为节点数,$ \mathrm{d}$ 为向量维度,显然计算复杂度还是较高的。
处理的方法是将向量维度为 $d$ 的 $h_{v}^{t}$ 拆分成 $k$ 份,就变成了 $k$ 个 $\mathrm{d} / \mathrm{k}$ 维向量 $h_{v}^{t, k} $,并在每个 $h_{v}^{t, k}$ 传播过程中分别进行传播和更新,最后再进行合并。
$\left(h_{v}^{t, 1}, h_{v}^{t, 2}, \cdots, h_{v}^{t, k}\right)=g\left(\tilde{h}_{v}^{t, 1}, \tilde{h}_{v}^{t, 2}, \cdots, \tilde{h}_{v}^{t, k}\right)$
$g$ 代表神经网络, $(x, y, \cdots) $ 代表拼接,$g$ 在所有节点上共享。这样就保持了节点排列不变性,同时允许图的不同副本在传播阶段相互通信
此时子向量时间复杂度为 $O\left(n^{2}(d / k)^{2}\right)$,考虑 $\mathrm{k}$ 个子向量的时间复杂度为 $O\left(n^{2} d^{2} / k\right)$ 。
5 输入表示

对于邻接矩阵,作者模型尝试了三种边表示形式:
- 化学图 (Chemical Graph) :在不考虑距离的情况下,邻接矩阵的值是离散的键类型:单键,双键,三键或芳香键;
- 距离分桶(Distance bins):基于矩阵乘法的消息函数的前提假设是边信息是离散的,因此作者将键的距离分为 10 个 bin, 比如说 $[2,6]$ 中均匀划分 8 个 bin,$[0,2]$ 为 1 个 bin, $[6,+\infty]$ 为 1 个 bin;
- 原始距离特征(Raw distance feature):也可以同时考虑距离和化学键的特征,这时每条边都有自己的特征向量,此时邻接矩阵的每个 实例都是一个 5 维向量,第一维是距离,其余 4 维是四种不同的化学键。
6 实验
实验以 QM-9 数据集为例,包含 130462 个分子,以 MAE 为评估指标。
下图为现有算法和作者改进的算法之间的对比:

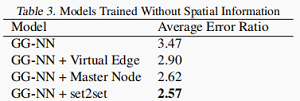
下图为不考虑空间信息的结果:
下图为考虑多塔模型和结果:
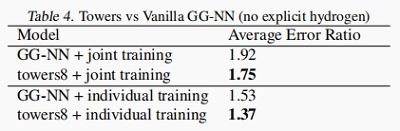
7 总结
作者从众多模型中总结出 MPNN 框架,并且通过实验表明,具有消息函数、更新函数和读出函数的 MPNN 具有良好的归纳能力,可以用于预测分析特性,优于目前的 Baseline,并且无需进行复杂的特征工程。此外,实验结果也揭示了全局主节点和利用 set2set 模型的重要性,多塔模型也使得 MPNN 更具伸缩性,方便应用于大型图中。
看完点个关注呗!!(总结不易)
论文解读(MPNN)Neural Message Passing for Quantum Chemistry的更多相关文章
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(Graph-MLP)《Graph-MLP: Node Classification without Message Passing in Graph》
论文信息 论文标题:Graph-MLP: Node Classification without Message Passing in Graph论文作者:Yang Hu, Haoxuan You, ...
- 论文解读(PPNP)《Predict then Propagate: Graph Neural Networks meet Personalized PageRank》
论文信息 论文标题:Predict then Propagate: Graph Neural Networks meet Personalized PageRank论文作者:Johannes Gast ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- CVPR2020行人重识别算法论文解读
CVPR2020行人重识别算法论文解读 Cross-modalityPersonre-identificationwithShared-SpecificFeatureTransfer 具有特定共享特征变换 ...
- Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
背景 消息传递模型(Message Passing Model)基于拉普拉斯平滑假设(领居是相似的),试图聚合图中的邻居的信息来获取足够的依据,以实现更鲁棒的半监督节点分类. 图神经网络(Graph ...
随机推荐
- 基于Linux系统ipython和集成开发环境Pycharm的安装
1.简介 Python是一门跨平台的开源.免费的.解释型.面向对象.带有动态语义的脚本语言,同时也支持伪编译以进行优化和提高运行速度,还支持使用py2exe工具将Python程序转换为exe可执行程序 ...
- 使用 baget 搭建私有 nuget 私有服务
现在几乎所有语言都提供包管理工具,比如 JavaScript 的 npm ,Java 的 Maven ,Dart 的 pub ..Net 程序当然是 NuGet .NuGet 也出现很多年了,奇怪的是 ...
- leetcode 位运算异或
1. 只出现一次的数字(136) 异或的性质总结: 相异为1,相同为0: a ^ a = 0; 0 ^ a = a; 如果 a ^ b = c 成立,那么a ^ c = b 与 b ^ c = a 均 ...
- 羽夏笔记——PE结构(不包含.Net)
写在前面 本笔记是由本人独自整理出来的,图片来源于网络.本人非计算机专业,可能对本教程涉及的事物没有了解的足够深入,如有错误,欢迎批评指正. 如有好的建议,欢迎反馈.码字不易,如果本篇文章有帮助你 ...
- Django——Paginator分页功能练习
1.路由urls.py from django.contrib import admin from django.urls import path from app01.views import in ...
- UNION / UNION ALL 区别
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序: Union All:对两个结果集进行并集操作,包括重复行,不进行排序: 使用union all: select top 5 ...
- inet_aton和inet_ntoa
3.1 inet_aton() int inet_aton(const char *cp, struct in_addr *inp); 参数说明: cp : IPv4点分十进制字符串,例如" ...
- AI异构通信:重压下的突围,华为P50系列的卓越体验
撰文 |懂懂 编辑 | 秦言 来源:懂懂笔记 "华为不会让消费者失望."华为消费者业务CEO余承东在P50系列发布会上如是说. 今年4月美国对华为第四轮制裁以来,华为终端产品无缘5 ...
- 解决sofaboot项目右键入口方法没有run sofa application
选中入口方法名,右键出现run sofa application
- 还不知道PHP有闭包?那你真OUT了
做过一段时间的Web开发,我们都知道或者了解JavaScript中有个非常强大的语法,那就是闭包.其实,在PHP中也早就有了闭包函数的功能.早在5.3版本的PHP中,闭包函数就已经出现了.到了7以及后 ...