第51篇-SharedRuntime::generate_native_wrapper()生成编译入口
当某个native方法被调用时,一开始它会从解释入口进入,也就是我之前介绍的、由InterpreterGenerator::generate_native_entry()函数生成的入口例程。在这个例程中,其实还有一些统计的相关代码,但是当时为了专注研究解释执行的主要流程,为虚拟机增加了-XX:-ProfileInterpreter选项,这样就不会生成相关的统计代码。
实际上,当统计到一个native方法被调用足够多次之后,HotSpot VM会为它专门生成编译执行的入口例程。这个入口例程是通过调用SharedRuntime::generate_native_wrapper()函数生成的,生成这个例程的目的与生成解释执行的入口例程一样,都是因为调用约定不同,所以要进行栈帧布局和转换。
下面以arraycopy()这个本地native、静态staic方法为例介绍编译执行的入口例程。在Java主类中调用arraycopy()方法进行数组的拷贝,如下:
public class TestCopyArray {
public static void main(String[] args) {
byte[] srcBytes = new byte[] { 2, 4, 0, 0, 0, 0, 0, 10, 15, 50 };
byte[] destBytes = new byte[5];
System.arraycopy(srcBytes, 0, destBytes, 0, 5);
for (int i = 0; i < destBytes.length; i++) {
System.out.print("-> " + destBytes[i]);
}
}
}
调用的java.lang.arraycopy()是个native方法,如下:
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
在HotSpot VM中对应的本地函数的实现如下:
JVM_ENTRY(void, JVM_ArrayCopy(
JNIEnv *env, jclass ignored,
jobject src, jint src_pos,
jobject dst, jint dst_pos,
jint length))
// ...
arrayOop s = arrayOop(JNIHandles::resolve_non_null(src));
arrayOop d = arrayOop(JNIHandles::resolve_non_null(dst));
// 进行数组的拷贝操作
s->klass()->copy_array(s, src_pos, d, dst_pos, length, thread);
JVM_END
可以看到,Java方法调用时的入参为5个,而本地函数为7个。我们看一下main()方法是如何一步步调用到JVM_ArrayCopy()这个本地函数的。
为了更好的研究,我们给虚拟机加选项-Xcomp,这样main()方法会编译执行,当调用arraycopy()方法时就会从编译执行的入口进入。调用链如下:
SharedRuntime::resolve_static_call_C() sharedRuntime.cpp
...
CompileBroker::compile_method() compileBroker.cpp
AdapterHandlerLibrary::create_native_wrapper() sharedRuntime.cpp
SharedRuntime::java_calling_convention() sharedRuntime_x86_64.cpp
当main()方法编译执行时会通过SharedRuntime::resolve_static_call_C()函数查找调用的目标函数,这我们在后面介绍编译执行时会详细介绍。最终会调用到SharedRuntime::java_calling_convention()函数,在这个函数中首先会计算出一些变量的值。
调用的Java方法arraycopy()的5个入参信息:
const int total_in_args=5 BasicType* in_sig_bbt=[T_OBJECT,T_INT,T_INT,T_OBJECT,T_INT,T_INT] VMRegPair* in_regs=[
VMRegPair(_first=6*2,_second=13) // 传递的是T_OBJECT
VMRegPair(_first=2*2,_second=-1)
VMRegPair(_first=1*2,_second=-1)
VMRegPair(_first=8*2,_second=17) // 传递的是T_OBJECT
VMRegPair(_first=9*2,_second=-1)
]
其中的变量total_in_args、in_sig_bbt和in_regs都是表示Java方法参数的,尤其是in_regs数组中的5个值表示了5个寄存器,这5个寄存器就是用来进行编译执行时传递参数约定好的。
调用的本地函数JVM_ArrayCopy()函数的入参如下:
const int total_c_args=7 BasicType* out_sig_bt=[T_ADDRESS,T_OBJECT,T_OBJECT,T_INT,T_OBJECT,T_INT,T_INT] VMRegPair* out_regs=[
VMRegPair(first=c_rarg0*2=0xe ,second=0xf) // 传递T_ADDRESS
VMRegPair(first=c_rarg1*2=0xc ,second=0xd) // 传递T_OBJECT
VMRegPair(first=c_rarg2*2=0x4 ,second=0x5) // 传递T_OBJECT
VMRegPair(first=c_rarg3*2=0x2 ,second=-1)
VMRegPair(first=c_rarg4*2=0x10,second=0x11) // 传递T_BOEJCT
VMRegPair(first=c_rarg5*2=0x12,second=-1)
// 由于6个寄存器已经用完,所以接下来的一个整数将存储在栈中
VMRegPair(first=184+0=0xb8 ,second=-1)
]
total_in_args的值为5。而total_c_args的值为7,因为当为实例方法时,需要JNIEnv*,所以实际上为6;当为静态方法,因为有JNIEnv*和jclass,所以实际上为7。
因为arraycopy是静态方法,所以total_c_args的值为7。
其中的VMRegPair类的定义如下:
class VMRegPair {
private:
VMReg _second; // VMReg是VMRegImpl*的别名,Register是RegisterImpl*的别名
VMReg _first;
...
}
然后调用如下函数:
out_arg_slots = c_calling_convention(out_sig_bt, out_regs, total_c_args);
最终返回的out_arg_slots的值为2,表示需要2个slot位置来存储第7个int参数,注意这里的slot的大小为4个字节。
在SharedRuntime::generate_native_wrapper()函数中,计算出本实例需要的栈大小共96字节,也就是24个slot(每个slot为4字节)。
形成的栈桢的状态如下所示。
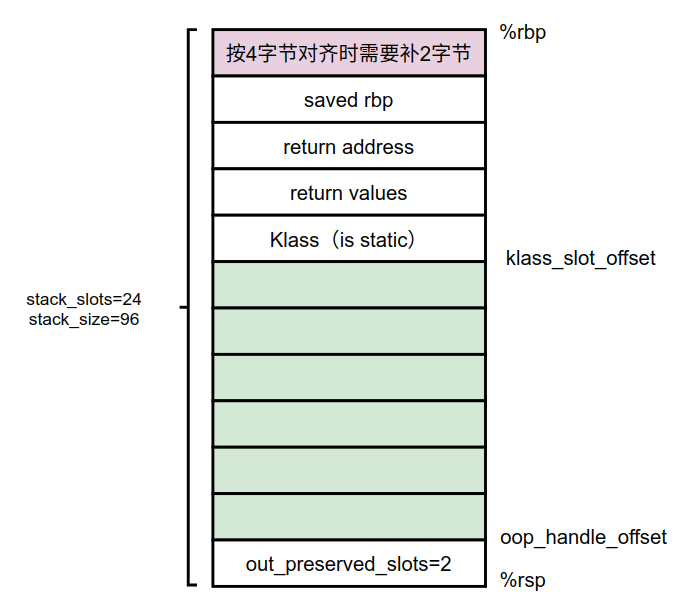
stack_size最终的值为96 (24*VMRegImpl::stack_slot_size)
调用SharedRuntime::generate_native_wrapper()函数生成的汇编片段如下:
// 将receiver.Klass存储到%r10d中,%rsi对于编译方法调用约定
// 来说,存储的是第1个参数,也就是实例方法的receiver
0x00007fffe110a1a0: mov 0x8(%rsi),%r10d
0x00007fffe110a1a4: shl $0x3,%r10
// %rax中存储的是ic_reg,进行类型检查
0x00007fffe110a1a8: cmp %r10,%rax
// 如果类型相等,则表示缓存命中,跳转到----hit----
0x00007fffe110a1ab: je 0x00007fffe110a1b8 // 缓存没有命中,跳转执行SharedRuntime::get_ic_miss_stub()指向的例程,
// 这个例程在后面会详细介绍
0x00007fffe110a1b1: jmpq 0x00007fffe1105be0
0x00007fffe110a1b6: nop
0x00007fffe110a1b7: nop // **** hit ****
// verified entry point=vep 验证过的入口,也就是缓存中已经比较成功了,可直接调用 // 缓存命中直接执行这里,这里可以计算一个vep_offset,其值为24
// 对栈溢出进行检查,如果%rsp向下的某个位置写入时,发生了Segment Fault,则会处理
0x00007fffe110a1b8: mov %eax,-0x16000(%rsp) // 开辟新的栈桢
0x00007fffe110a1bf: push %rbp
0x00007fffe110a1c0: mov %rsp,%rbp // stack_size=96,需要减去2个字(在开辟新栈帧时已经将return address
// 与saved rbp压入了栈帧中),剩下就是80,也就是0x50
0x00007fffe110a1c3: sub $0x50,%rsp // 计算frame_complete的值为39,也就是
// 0x00007fffe110a1c3 + 3(sub指令的大小) - 0x00007fffe110a1a0
通过%rax寄存器中的值进行缓存命中检查,如果命中,则直接执行vep,否则需要执行SharedRuntime::get_ic_miss_stub()指向的例程。
在SharedRuntime::generate_native_wrapper()函数中接下来就要计算Java编译执行时的参数与本地函数参数的对应关系了,然后将计算出来的对应关系对存储到arg_order一维数组中。最终计算的arg_order的值为{[4,6]、[3,5]、[2,4]、[1,3]、[0,2]},也就是将入参的第4个参数传递到native的第6个参数上,其它的类似。编译执行时,调用约定为:
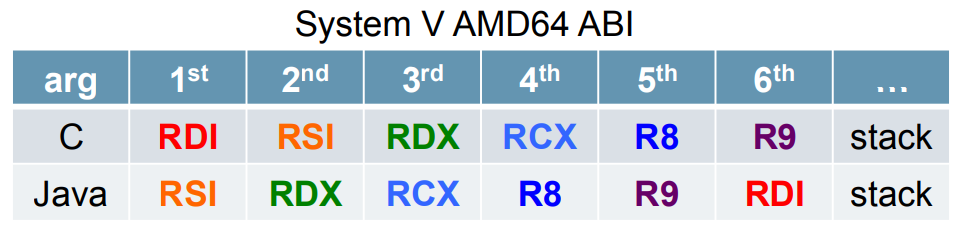
也就是说,Java编译执行时,也是通过C/C++函数使用的那6个寄存器来传递参数的,只是用来规定传递参数的寄存器顺序不同,如Java的第1个参数使用%rsi寄存器,而C/C++函数使用%rdi来传递。这样的规定是有原因的,假设现在Java编译执行调用native实例方法,那么native方法的本地函数实现会多出一个参数JNIEnv*,那么我们只需要使用%rdi存储即可,如果%rdi中存储着Java方法的参数,需要保存到栈中,而其它的寄存器不需要移动。
如果是native静态方法,那么寄存器其实还是需要移动的,因为native静态方法对应的本地函数会多出来2个参数JNIEnv*和jclass。我们本次介绍的arraycopy()方法就是个静态方法,所以仍然需要移动许多寄存器。
下面接着看SharedRuntime::generate_native_wrapper()函数生成的汇编代码,如下:
0x00007fffe110a1c7: mov %r9,(%rsp)
0x00007fffe110a1cb: mov %r8,%r9
// 传递Object类型,因为要给本地函数传递句柄,所以需要在
// 栈上分配句柄
0x00007fffe110a1ce: mov %rcx,0x18(%rsp)
0x00007fffe110a1d3: cmp $0x0,%rcx
0x00007fffe110a1d7: lea 0x18(%rsp),%r8 // 执行有条件的指令移动
0x00007fffe110a1dc: cmove 0x18(%rsp),%r8 0x00007fffe110a1e2: mov %rdx,%rcx // 传递Object类型
0x00007fffe110a1e5: mov %rsi,0x8(%rsp)
0x00007fffe110a1ea: cmp $0x0,%rsi
0x00007fffe110a1ee: lea 0x8(%rsp),%rdx
0x00007fffe110a1f3: cmove 0x8(%rsp),%rdx // 将JNIHandles::make_local(method->method_holder()->java_mirror())
// 获取到的方法对应类的java.lang.Class对象存储到%r14中
0x00007fffe110a1f9: movabs $0x7ffff00efb90,%r14 // 因为arraycopy()是静态方法,所以需要传递的第2个参数为mirror,不过要句柄化
0x00007fffe110a203: mov %r14,0x38(%rsp)
0x00007fffe110a208: lea 0x38(%rsp),%r14
0x00007fffe110a20d: mov %r14,%rsi
如上汇编对参数进行移动。如下图所示。

所以对于静态的native方法来说,需要的寄存器移动操作还是非常多。最终的移动结果如下图所示。

其中的红色为对象类型,对象类型的数据需要进行句柄化,所以我们才会在栈上开辟0x50大小的slot。所以如果是对象,那么会将真实的对象地址存放到栈的slot中,然后返回slot的地址,这样就完成了句柄操作。各个参数对应的slot如下图所示。
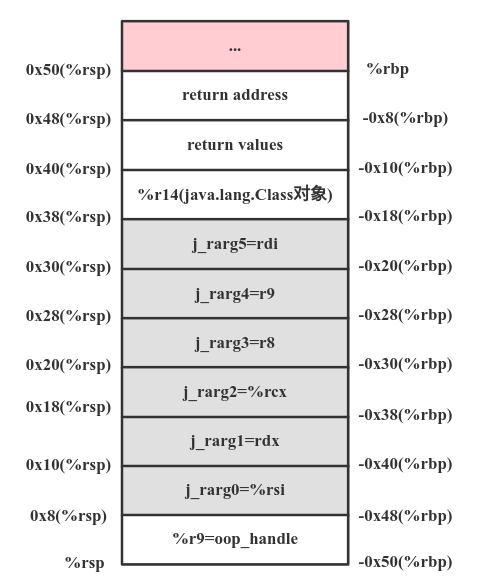
下面接着看SharedRuntime::generate_native_wrapper()函数生成的汇编代码,如下:
// 调用MacroAssembler::set_last_Java_frame()函数将当前指令的地址存储到
// JavaThread::last_Java_pc中,将%rsp存储到JavaThread::last_Java_sp中
0x00007fffe110a210: movabs $0x7fffe110a210,%r10
0x00007fffe110a21a: mov %r10,0x1f8(%r15)
0x00007fffe110a221: mov %rsp,0x1f0(%r15) // 为调用SharedRuntime::dtrace_method_entry()函数生成如下的汇编代码
0x00007fffe110a228: cmpb $0x0,0x1628ef2b(%rip) # 0x00007ffff739915a
0x00007fffe110a22f: je 0x00007fffe110a273
0x00007fffe110a235: push %rsi
0x00007fffe110a236: push %rdx
0x00007fffe110a237: push %rcx
0x00007fffe110a238: push %r8
0x00007fffe110a23a: push %r9
0x00007fffe110a23c: movabs $0x7fffd781df98,%rsi // Method*移动到%rsi
0x00007fffe110a246: mov %r15,%rdi // Thread*移动到%rdi
0x00007fffe110a249: test $0xf,%esp
0x00007fffe110a24f: je 0x00007fffe110a267
0x00007fffe110a255: sub $0x8,%rsp
0x00007fffe110a259: callq 0x00007ffff6a0c21c
0x00007fffe110a25e: add $0x8,%rsp
0x00007fffe110a262: jmpq 0x00007fffe110a26c
0x00007fffe110a267: callq 0x00007ffff6a0c21c
0x00007fffe110a26c: pop %r9
0x00007fffe110a26e: pop %r8
0x00007fffe110a270: pop %rcx
0x00007fffe110a271: pop %rdx
0x00007fffe110a272: pop %rsi
是以编译的方式调用native方法,所以要遵守编译的调用约定。如上代码涉及到了DTrace Probes,可参考如下文章:
(1)https://myaut.github.io/dtrace-stap-book/app/java.html
(2)https://blog.csdn.net/weixin_30751947/article/details/98747442
继续看SharedRuntime::generate_native_wrapper()函数生成的如下汇编代码:
// 获取Thread::_jni_environment属性的值并存储到%rdi中,这就是调用C/C++函数时需要
// 传递的第1个参数JNIEnv*
0x00007fffe110a273: lea 0x210(%r15),%rdi // 将线程中Thread::_thread_state的值更新为_thread_in_native
0x00007fffe110a27a: movl $0x4,0x288(%r15) // 重点来了,调用本地函数native_function
0x00007fffe110a285: callq 0x00007ffff672a9b2 0x00007fffe110a28a: vzeroupper
// 将Thread::_thread_state的值更新为_thread_in_native_trans
0x00007fffe110a28d: movl $0x5,0x288(%r15) // 调用MacroAssembler::serialize_memory()函数生成的如下汇编
// Write serialization page so VM thread can do a pseudo remote membar.
// We use the current thread pointer to calculate a thread specific
// offset to write to within the page. This minimizes bus traffic
// due to cache line collision.
0x00007fffe110a298: mov %r15d,%ecx
0x00007fffe110a29b: shr $0x4,%ecx
0x00007fffe110a29e: and $0xffc,%ecx
0x00007fffe110a2a4: movabs $0x7ffff7ff5000,%r10
0x00007fffe110a2ae: mov %ecx,(%r10,%rcx,1)
// 结束调用MacroAssembler::serialize_memory()函数 // 检查SafepointSynchronize::_state的状态是否
// 为SafepointSynchronize::_not_synchronized
0x00007fffe110a2b2: cmpl $0x0,0x1629f224(%rip) # 0x00007ffff73a94e0
// 在需要进入安全点的状态下直接跳转到----L----
0x00007fffe110a2bc: jne 0x00007fffe110a2d0 // 执行到这里时,表示不需要进入安全点
// 检查Thread::_suspend_flags的状态,如果在执行native_function期间没有
// 发生异步异常,则直接跳转到----Continue----
0x00007fffe110a2c2: cmpl $0x0,0x30(%r15)
0x00007fffe110a2ca: je 0x00007fffe110a2e9 // **** L ****
// 在执行完成native_function后会返回到Java方法中,因为Java方法是非GC安全的,所以
// 需要检查安全点;如果在执行native_function期间发生了异步异常,也需要处理 // 将Thread*存储到%rdi中,这是调用C/C++函数的第1个参数
0x00007fffe110a2d0: mov %r15,%rdi
0x00007fffe110a2d3: mov %rsp,%r12 // 用%r12记录%rsp
0x00007fffe110a2d6: sub $0x0,%rsp
// ABI要求进行栈对齐
0x00007fffe110a2da: and $0xfffffffffffffff0,%rsp
// 调用 JavaThread::check_special_condition_for_native_trans()函数,这个函数在下面有说明
0x00007fffe110a2de: callq 0x00007ffff6ab14a4
0x00007fffe110a2e3: mov %r12,%rsp // 恢复%rsp的值
0x00007fffe110a2e6: xor %r12,%r12 // xor后将%r12清零
调用的JavaThread::check_special_condition_for_native_trans()函数如下:
void JavaThread::check_special_condition_for_native_trans(JavaThread *thread) {
check_safepoint_and_suspend_for_native_trans(thread);
if (thread->has_async_exception()) {
thread->check_and_handle_async_exceptions(false);
}
}
如果明确要求当前线程挂起,或GC要求进入安全点,则执行如上函数的当前线程会挂起。同时还也会检测异步异常。调用的JavaThread::check_safepoint_and_suspend_for_native_trans()函数等不再详细介绍,这些是为了支持GC而进行的一些安全点等操作,关于安全点等在《深入剖析Java虚拟机:源码剖析与实例详解(基础卷)》一书中详细介绍过,这里不再介绍。
下面接着看汇编代码,如下:
// **** Continue ****
// 当不需要进入安全点并且没有异步异常需要处理的情况下执行如下汇编 // 更新线程的状态为_thread_in_Java,因为native_function已经执行完成
0x00007fffe110a2e9: movl $0x8,0x288(%r15)
// 将Thread::_stack_guard_state属性值与JavaThread::stack_guard_yellow_disabled枚举类值进行比较,
// 如果相等就表示栈需要保护,跳转到----- reguard -----
0x00007fffe110a2f4: cmpl $0x1,0x2b4(%r15)
0x00007fffe110a2ff: je 0x00007fffe110a388 // **** reguard_done ****
// 执行这里的汇编代码时,表示栈不需要保护 // 如下汇编片段都是为了调用SharedRuntime::dtrace_method_exit()函数
0x00007fffe110a305: cmpb $0x0,0x1628ee4e(%rip) # 0x00007ffff739915a
0x00007fffe110a30c: je 0x00007fffe110a342
// 将Method*保存到%rsi中,C语言使用%rsi来存储第2个参数
0x00007fffe110a312: movabs $0x7fffd781df98,%rsi
0x00007fffe110a31c: mov %r15,%rdi
0x00007fffe110a31f: test $0xf,%esp
0x00007fffe110a325: je 0x00007fffe110a33d
0x00007fffe110a32b: sub $0x8,%rsp
0x00007fffe110a32f: callq 0x00007ffff6a0c3d0
0x00007fffe110a334: add $0x8,%rsp
0x00007fffe110a338: jmpq 0x00007fffe110a342
0x00007fffe110a33d: callq 0x00007ffff6a0c3d0 // 调用MacroAssembler::reset_last_Java_frame()函数生成如下2句汇编代码
// 清空JavaThread::last_java_sp属性的值
0x00007fffe110a342: movabs $0x0,%r10
0x00007fffe110a34c: mov %r10,0x1f0(%r15)
// 清空JavaThread::last_java_pc属性的值
0x00007fffe110a353: movabs $0x0,%r10
0x00007fffe110a35d: mov %r10,0x1f8(%r15) // 获取线程中的JavaThread::_active_handles属性值
0x00007fffe110a364: mov 0x38(%r15),%rcx
// 将JNIHandleBlock::_top属性的值设置为NULL
0x00007fffe110a368: movq $0x0,0x108(%rcx) // 弹出native方法的栈帧
// leave通过恢复ebp与esp寄存器来移除使用enter指令建立的栈帧。相当于
// mov %rbp, %rsp
// pop %rbp
// 将栈指针指向帧指针,然后pop备份的原帧指针到%ebp
0x00007fffe110a373: leaveq // 检查Thread::_pending_exception属性的值是否为NULL,
// 如果不为NULL,则跳转到---- exception_pending ----
0x00007fffe110a374: cmpq $0x0,0x8(%r15)
0x00007fffe110a37c: jne 0x00007fffe110a383
// ret指令用于从子函数中返回。X86架构的Linux中是将函数的返回
// 值设置到eax寄存器并返回的。相当于指令:pop %eip
0x00007fffe110a382: retq // **** exception_pending **** // 当执行本地函数时发生了异常,则跳转到
// StubRoutines::forward_exception_entry()指向的例程去执行
0x00007fffe110a383: jmpq Stub::forward exception // **** reguard **** // 通过慢路径来保护栈
0x00007fffe110a388: mov %rsp,%r12
0x00007fffe110a38b: sub $0x0,%rsp
0x00007fffe110a38f: and $0xfffffffffffffff0,%rsp
// 调用SharedRuntime::reguard_yellow_pages()函数
0x00007fffe110a393: callq 0x00007ffff6a10642
0x00007fffe110a398: mov %r12,%rsp
0x00007fffe110a39b: xor %r12,%r12
// 已经完成了必要的保护操作,跳转到----reguard_done-----
0x00007fffe110a39e: jmpq 0x00007fffe110a305
执行完汇编后,在SharedRuntime::generate_native_wrapper()函数中最终会执行如下语句生成一个nmethod实例并返回,nmethod可以表示一个编译后的Java方法,也可以表示执行一个“编译”了的native方法(实际上是从编译执行调用到native方法,其中固化了调用native方法的一些例程,主要用来进行调用约定的转换以及GC支持等)。调用的语句如下:
nmethod *nm = nmethod::new_native_nmethod(method,
compile_id,
masm->code(),
vep_offset,
frame_complete,
stack_slots / VMRegImpl::slots_per_word,
(is_static ? in_ByteSize(klass_offset) : in_ByteSize(receiver_offset)),
in_ByteSize(lock_slot_offset*VMRegImpl::stack_slot_size),
oop_maps);
方法中还会有加锁和释放锁的逻辑,这些逻辑比较多,因为我们现在还没有介绍锁相关的内容,所以暂时不介绍为native方法加锁的逻辑。
参考文章:
(1)[讨论] 请教HotSpot源码中关于JNI handle的问题
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流
第51篇-SharedRuntime::generate_native_wrapper()生成编译入口的更多相关文章
- C#使用Xamarin开发可移植移动应用进阶篇(8.打包生成安卓APK并精简大小),附源码
前言 系列目录 C#使用Xamarin开发可移植移动应用目录 源码地址:https://github.com/l2999019/DemoApp 可以Star一下,随意 - - 说点什么.. 嗯,前面讲 ...
- JAVA高级篇(三、JVM编译机制、类加载机制)
一.类的加载过程 JVM将类的加载分为3个步骤: 1.装载(Load) 2.链接(Link) 3.初始化(Initialize) 其中 链接(Link)又分3个步骤,如下图所示: 1) 装载:查找并加 ...
- 第一篇: openJDK源码编译安装--mac版本
1.为什么要编译JDK 想要一探JDK内部的实现机制,最便捷的路径之一就是自己编译一套JDK,通过阅读和跟踪调试JDK源码去了解Java技术体系的原理,虽然门槛高一点,但肯定比阅读各种书籍,文章,博客 ...
- 分布式架构高可用架构篇_06_MySQL源码编译安装(CentOS-6.7+MySQL-5.6)
redhat: 下载:http://dev.mysql.com/downloads/mysql/ 选择5.6 source包 解压 cmake . -DCMAKE_INSTALL_PREFIX=/us ...
- pentaho专题系列之kettle篇--kettle源码编译
最近看了一些kettle的文章,都是kettle7.0以前的,已经跟不上时代了.截止笔者写这篇文章的时候,github上面的已经是7.1.0.3了,而且是发行版的,最新的快照版本已经是8.0的了.基于 ...
- HelloDjango 第 11 篇:自动生成文章摘要
作者:HelloGitHub-追梦人物 文中涉及的示例代码,已同步更新到 HelloGitHub-Team 仓库 博客文章的模型有一个 excerpt 字段,这个字段用于存储文章的摘要.目前为止,还只 ...
- C# 篇基础知识1——编译、进制转换、内存单位、变量
编译:C#语言要经过两次编译,程序员编写好源代码后进行第一次编译,将源代码编译为微软中间语言(MSIL),生成可以发布的应用软件:当用户使用软件时,MSIL代码会在首次载入内存后进行第二次编译,中间语 ...
- 【学习】从.txt文件读取生成编译代码。
string code = null; String projectName = Assembly.GetExecutingAssembly().GetName().Name; // 1. 生成要编译 ...
- 小书MybatisPlus第6篇-主键生成策略精讲
本文为mybatis系列文档的第6篇,前5篇请访问下面的网址. 小书MybatisPlus第1篇-整合SpringBoot快速开始增删改查 小书MybatisPlus第2篇-条件构造器的应用及总结 小 ...
随机推荐
- 效验pipeline语法
目录 一.简介 二.配置 一.简介 因为jenkins pipeline不像JAVA之类的语言那样应用广泛,所以没有相关的代码检测插件. 2018年11月初,Jenkins官方博客介绍了一个VS Co ...
- Nginx配置正向代理
目录 一.简介 二.配置 三.参数 一.简介 场景: 用于内网机器访问外网,就需要正向代理,类似VPN. 原理: A机器可以访问外网,而B,C,D机器只能内网,便可以设立正向代理,将B,C,D机器的访 ...
- Python pyecharts绘制饼图
一.pyecharts绘制饼图语法简介 饼图主要用于表现不同类目的数据在总和中的占比.每个的弧度不是数据量的占比pie.add()方法的用法add(name, attr, value, radius= ...
- linux 下查看文件修改时间
linux 下查看文件修改时间 等 http://blog.sina.com.cn/s/blog_6285b04e0100f4xr.html 查看文件时间戳命令:stat awk.txtFile: ` ...
- Java 自动给方法加注释
在代码的方法中先写/**,然后按回车键,即是键盘上的Enter键 但是首先得配置一下,配置如图所示:
- 【九度OJ】题目1078:二叉树遍历 解题报告
[九度OJ]题目1078:二叉树遍历 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1078 题目描述: 二叉树的前序.中序.后序遍历 ...
- 【LeetCode】1019. Next Greater Node In Linked List 解题报告 (Python&C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 单调递减栈 日期 题目地址:https://leetc ...
- 【LeetCode】79. Word Search 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 回溯法 日期 题目地址:https://leetco ...
- C#反射调用 异常信息:Ambiguous match found.
异常信息(异常类型:System.Reflection.AmbiguousMatchException)异常提示:Ambiguous match found.异常信息:Ambiguous match ...
- LeetCode—剑指 Offer学习计划
第 1 天 栈与队列(简单) 剑指 Offer 09. 用两个栈实现队列 class CQueue { public: CQueue() { } stack<int>s1,s2; void ...