Hadoop【MR开发规范、序列化】
Hadoop【MR开发规范、序列化】
一、MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver
1.Mapper阶段
(1)用户自定义Mapper要继承Mapper父类
(2)Mapper的输入时K-V对的形式(K-V可自定义)
(3)Mapper的业务逻辑写在map()方法中,要重写父类的map()方法
(4)MapTask进程会对每个输入的K-V调用一次map()方法
2.Reducer阶段
(1)用户自定义Reducer要继承Reducer父类
(2)Reducer的输入数据类型对应Mapper的输出的数据类型,也是K-V
(3)Reducer的业务逻辑写在reduce()方法中,要重写父类的reduce()方法
(4)ReduceTask进程会对一组相同K的K-V调用一次reduce()方法
3.Driver阶段
相当于Yarn集群的客户端,用于提交整个job程序到Yarn集群,提交了封装了mapreduce程序的和相关运行参数的job对象。
二、WordCount案例开发
开发前提 要配置好window本地的开发环境,详情可见:HDFS【hadoop3.1.3 windows开发环境搭建】
需求
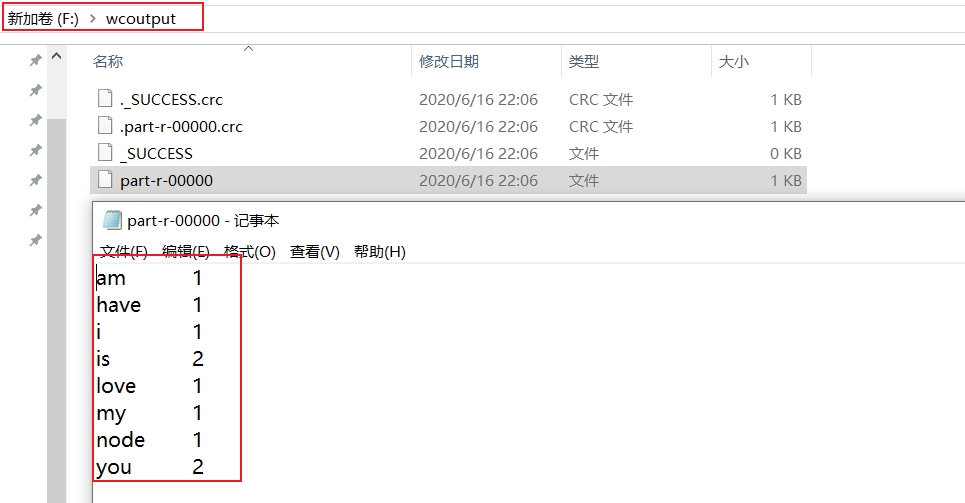
求出给定的wc.txt文本文件中统计输出每一个单词出现的总次数
【wc.txt文本】
is you am
i have you node
is my love
1. 创建maven工程
2.在pom.xml添加依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
3.项目的src/main/resources目录下,添加log4j2.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
4.编写Mapper、Reducer、Driver类
Mapper类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException; /**
* 1.自定义的类需要继承Mapper
* 2.Mapper的四个泛型KEYIN, VALUEIN, KEYOUT, VALUEOUT
* 这四个泛型是两对(K,V)。
* 第一对 :输入的数据类型
* KEYIN : 数据的偏移量(一行一行的读取数据用来记录数据读到哪里)
* VALUEIN :实际读取的具体的一行数据
* 第二对 :输出的数据类型
* KEYOUT : 单词
* VALUEOUT :单词出现的数量(1)
*/
public class CountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
//输出的key
private Text outKey = new Text();
//输出的value
private IntWritable outValue = new IntWritable(1);
/**
* 该方法用来处理具体的业务逻辑
* @param key 输入数据的KEYIN ,数据的偏移量
* @param value 输入数据的VALUEIN,实际读取的具体的一行数据
* @param context 上下文 (在这里用来将数据写出去)
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.先将读进来的数据转换成String便于操作
String line = value.toString();
//2.切割数据(按照空格切数据)
String[] words = line.split(" ");
//3.遍历所有的单词并进行封装(K,V)
for (String word : words) {
//给outKey赋值
outKey.set(word);
//写数据
context.write(outKey,outValue);
}
}
}
Reducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; /**
* 1.自定义的类需要继承Reducer
* 2.4个泛型 : KEYIN,VALUEIN,KEYOUT,VALUEOUT
* 4个泛型实际为两对
* 第一对 输入的类型 :
* KEYIN :mapper中输出的key的类型
* VALUEIN :mapper中输出的value的类型
* 第二对 输出的类型 :
* KEYOUT :实际要写出去的数据的key的类型
* VALUEOUT :实际要写出的数据的value的类型
*/
public class CountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outValue = new IntWritable();//输出的value的类型
/**
* 该方法就是具体操作业务逻辑的方法
* 注意 :一组一组的读取数据。key相同则为一组
* @param key :单词
* @param values :相同单词的一组value
* @param context : 上下文(在这用来将数据写出去)
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;//用来累加value值
//遍历所有的value
for (IntWritable value : values) {
//value.get() : 将IntWritable转成基本数据类型
sum += value.get();
}
//封装(K,V)
outValue.set(sum);
//将数据写出去
context.write(key,outValue);
}
}Driver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException; /**
* 本地运行MR任务
*
* 驱动类 :1.作为程序的入口 2.进行相关的一些关联 3.一些参数的设置
*/
public class CountDriver {
/*
1.获取配置信息、封装job对象
2.关联jar,Driver类
3.关联mapper和reducer
4.设置mapper的输出的key和value类型
5.设置最终(reducer)输出的key和value的类型
6.设置输入输出路径
7.提交job任务
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取配置信息、封装job对象
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2.关联jar,Driver类
job.setJarByClass(CountDriver.class);
//3.关联mapper和reducer
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
//4.设置mapper的输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终(reducer)输出的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入输出路径
//注意 :FileInputFormat导入org.apache.hadoop.mapreduce.lib包
FileInputFormat.setInputPaths(job,new Path(args[0]));
//注意 :输出目录必须不存在
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.提交job任务
//boolean verbose是否打印进度
boolean isSuccess = job.waitForCompletion(true);
//虚拟机退出的状态 :0是正常退出,1非正常退出
System.exit(isSuccess ? 0 : 1);
}
}
5.本地测试
在idea中配置输入参数-args[0]、输出参数-args[1]
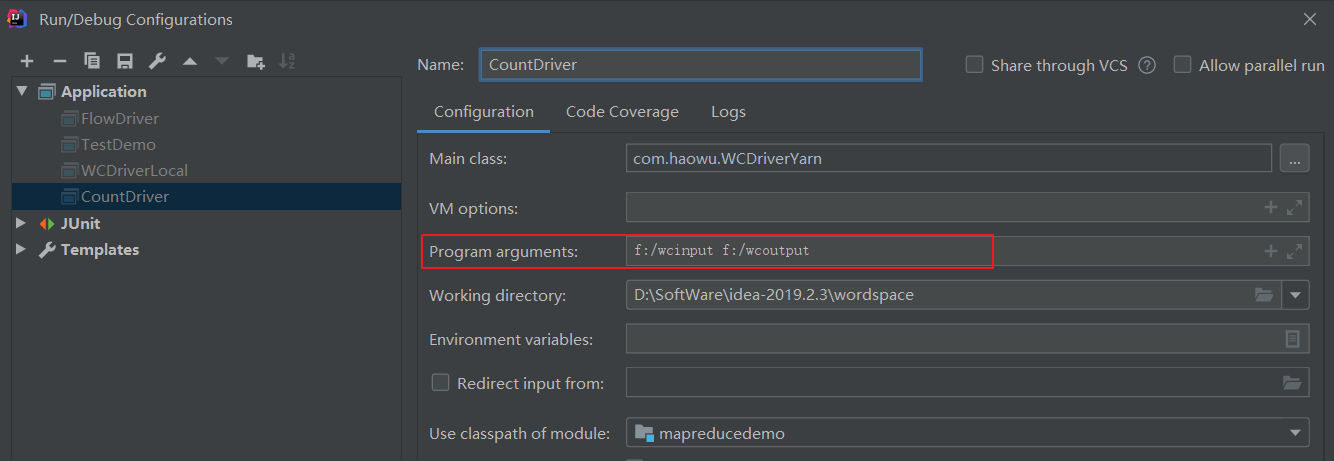
跑任务,运行Driver类,查看结果
6.集群测试
1.maven打jar包,需要添加的打包插件依赖
注意:标记红颜色的部分需要替换为自己工程主类
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 工程主类 -->
<mainClass>com.haowu.WCDriverYarn</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
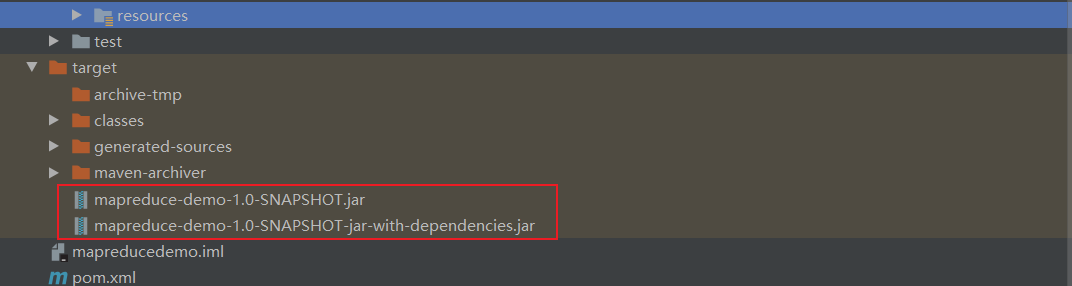
2.打jar包
将target包下不带依赖的jar-->mapreduce-demo-1.0.SNAPSHOT.jar重命名为wc.jar-->拷贝到hadoop集群
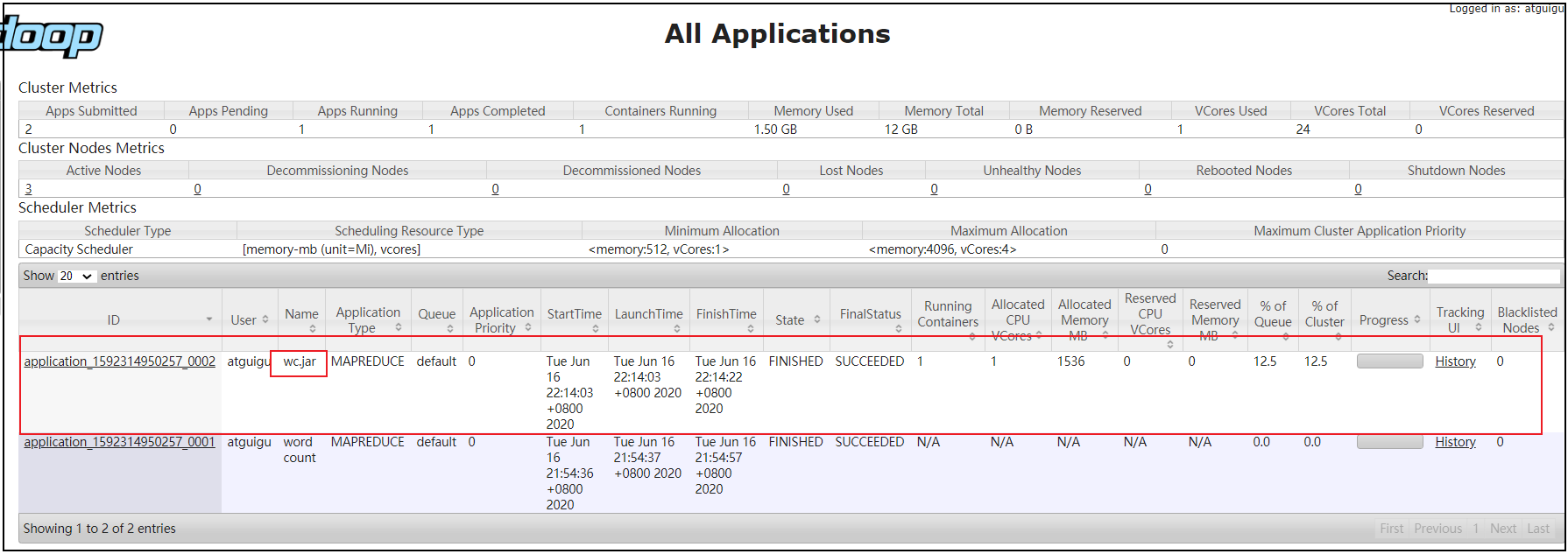
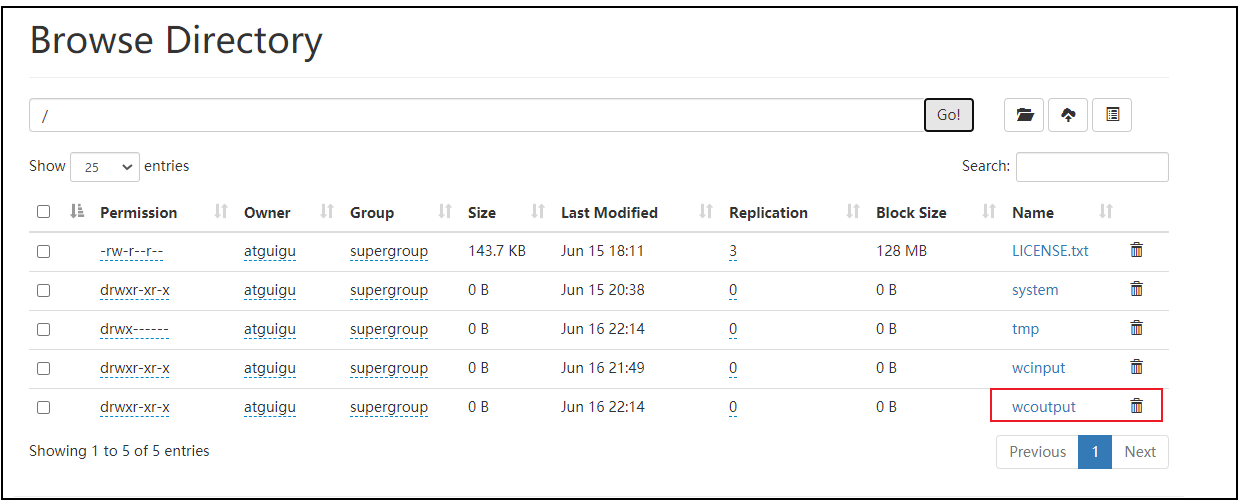
3.启动集群,执行wc.jar
[haowu@hadoop102 ~]$ hadoop jar wc.jar com.haowu.WCDriverYarn /wcinput /wcoutput
运行前
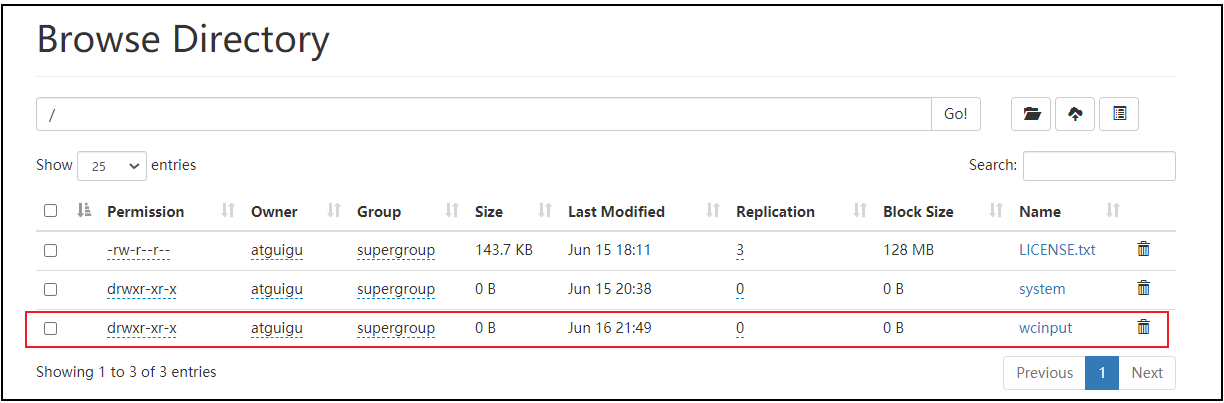
运行后
三、Hadoop序列化
1.序列化概述


2.java、hadoop序列化数据类型对比
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
3.自定义bean对象实现序列化(Writable)
基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口
具体实现bean对象序列化步骤如下7步:
(1).实现Writable接口
(2).必须有空参构造
public FlowBean() {
super();
}
(3).重写序列化、反序列化方法
注意反序列化的顺序和序列化的顺序完全一致
序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
反序列化
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5).想把结果显示在文件中,需要重写toString(),可用”\t”分开
(6).如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
4.序列化案例实操
需求:统计每一个手机号耗费的总上行流量、下行流量、总流量
输入数据:phone.txt
数据格式
id 手机号码 网络ip 上行流量 下行流量 网络状态码
7 13560436666 120.196.100.99 1116 954 200
15 13682846555 192.168.100.12 1938 2910 200
16 13992314666 192.168.100.13 3008 3720 200
17 13509468723 192.168.100.14 7335 110349 404
18 18390173782 192.168.100.15 9531 2412 200
需求分析:

编写程序
1.编写Bean对象
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 使用hadoop序列化框架
* 1.自定义类并实现Writable接口
* 2.重写write和readFields方法
* 3.读时数据的顺序必须和写时数据的顺序相同
*/
public class FlowBean implements Writable {
//上行流量
private long upFlow;
//下行流量
private long downFlow;
//总流量
private long sumFlow;
public FlowBean() {
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
/**
* 当我们通过reducer向外写数据时(对象)实际上是调用toString方法写出toString方法中的字符串
* @return
*/
@Override
public String toString() {
return upFlow + " " + downFlow + " " + sumFlow;
}
/**
* 序列化:写
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
//顺序随意,类型不能错
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化 :读
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
//注意:读取数据的顺序必须和写的顺序相同
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
}
2.编写Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* outkey : 手机号
* outvalue : FlowBean对象
*/
public class FlowMapper extends Mapper<LongWritable,Text, Text,FlowBean> {
private Text outkey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//分割数据
String[] phoneInfo = value.toString().split("\t");
//封装K,V
outkey.set(phoneInfo[1]);
//从数组中取出对应的数据,并转成long类型
long upFlow = Long.parseLong(phoneInfo[phoneInfo.length - 3]);
long downFlow = Long.parseLong(phoneInfo[phoneInfo.length - 2]);
//封装value
FlowBean flowBean = new FlowBean(upFlow, downFlow);
//写数据
context.write(outkey,flowBean);
}
}
3.编写Reducer类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)
throws IOException, InterruptedException {
long upFlow = 0; //累加相同手机号的upflow
long downFlow = 0; //累加相同手机号的downflow
//遍历一组一组的数据
for (FlowBean value : values) {
//取出每一条数据的upflow,downflow并将upflow和downflow分别累加
upFlow += value.getUpFlow();
downFlow += value.getDownFlow();
}
//封装K,V
FlowBean outValue = new FlowBean(upFlow, downFlow);
//写出数据
context.write(key,outValue);
}
}
4.编写driver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
/*
1.获取job对象
2.关联jar
3.关联mapper和reducer
4.设置mapper的输出的key和value类型
5.设置最终(reducer)输出的key和value的类型
6.设置输入输出路径
7.提交job任务
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job对象
Job job = Job.getInstance(new Configuration());
//2.关联jar
job.setJarByClass(FlowDriver.class);
//3.关联mapper和reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4.设置mapper的输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5.设置最终(reducer)输出的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6.设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.提交job任务
job.waitForCompletion(true);
}
}
5.本地测试
在idea中配置输入参数-args[0]、输出参数-args[1]
6.测试结果
13560436666 1116 954 2070
13682846555 1938 2910 4828
11399231466 3008 3720 6728
13509468723 7335 1 7336
18390173782 2412 20 2432
Hadoop【MR开发规范、序列化】的更多相关文章
- 【Hadoop】Hadoop MR 自定义序列化类
1.基本概念 2.Mapper代码 package com.ares.hadoop.mr.flowsum; import java.io.IOException; import org.apache. ...
- Python3基础(4)匿名函数、装饰器、生成器、迭代器、内置函数、json&pickle序列化、软件目录开发规范、不同目录间模块调用
---------------个人学习笔记--------------- ----------------本文作者吴疆-------------- ------点击此处链接至博客园原文------ 1 ...
- python27期day16:序列化、json、pickle、hashlib、collections、软件开发规范、作业。
序列化模块:什么是序列化呢? 序列化的本质就是将一种数据结构(如字典.列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化.将这个字典直接写入文件是不可以的,必须转化成字符串的形式, ...
- python中软件开发规范,模块,序列化随笔
1.软件开发规范 首先: 当代码都存放在一个py文件中时会导致 1.不便于管理,修改,增加 2.可读性差 3.加载速度慢 划分文件1.启动文件(启动接口)--starts文件放bin文件里2.公共文件 ...
- 转载 C#中敏捷开发规范
转载原地址 http://www.cnblogs.com/weixing/archive/2012/03/05/2380492.html 1.命名规则和风格 Naming Conventions an ...
- 前端开发规范:命名规范、html 规范、css 规范、js 规范
上周小组的培训内容是代码可读性艺术,主要分享如何命名.如何优化代码排版,如何写好的注释.我们都知道写出优雅的代码是成为大牛的必经之路. 下面感谢一位前端开发小伙伴总结的前端开发规范,通过学习相关开发规 ...
- 大数据开发实战:Hadoop数据仓库开发实战
1.Hadoop数据仓库架构设计 如上图. ODS(Operation Data Store)层:ODS层通常也被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度 ...
- hadoop应用开发技术详解
<大 数据技术丛书:Hadoop应用开发技术详解>共12章.第1-2章详细地介绍了Hadoop的生态系统.关键技术以及安装和配置:第3章是 MapReduce的使用入门,让读者了解整个开发 ...
- WEB前端开发规范文档[转]
为新项目写的一份规范文档, 分享给大家. 我想前端开发过程中, 无论是团队开发, 还是单兵做站, 有一份开发文档做规范, 对开发工作都是很有益的. 本文档由本人编写, 部分意见来源于网络, 以此感谢, ...
随机推荐
- JAVA笔记 **__Netbeans常用快捷键
sout + Tab 生成输出语句 alt+shift+F 格式化代码 Alt+insert 插入代码(包括构造函数,setter和getter方法等) Ctrl+O或Ctrlt+单击 转 ...
- Nginx多种安装方式
不指定参数配置的Nginx编译安装 ./configuremake make install wget下载或浏览器下载上传.解压进入目录[root@mcw1 nginx-1.10.2]# ls #查看 ...
- 阿里云ECI如何6秒扩容3000容器实例?
引言 根据最新CNCF报告,有超过90%的用户在生产环境使用容器,并且有超过80%的用户通过Kubernetes管理容器.是不是我们的生产环境上了K8s就完美解决了应用部署的问题?IT界有句俗语,没有 ...
- 官宣 .NET RC 2
我们很高兴发布 .NET 6 RC(Release Candidate) 2.它是生产环境中支持的两个"go live"候选版本中的第二个. 在过去的几个月里,团队一直专注于质量的 ...
- Python推导式详解,带你写出比较精简酷炫的代码
Python推导式详解,带你写出比较精简酷炫的代码 前言 1.推导式分类与用法 1.1 列表推导 1.2 集合推导 1.3 字典推导 1.4 元组推导?不存在的 2.推导式的性能 2.1 列表推导式与 ...
- Vue3+Vue-cli4项目中使用腾讯滑块验证码
Vue3+Vue-cli4项目中使用腾讯滑块验证码 简介: 滑块验证码相比于传统的图片验证码具有以下优点: 验证码的具体验证不需要服务端去验证,服务端只需要核验验证结果即可. 验证码的实现不需要我们去 ...
- selenium截屏操作(也支持截长图)
1.常用的可能是谷歌和火狐做自动化在抛异常的时候可以截屏保存 from selenium import webdriver br=webdriver.Chrome() br.maximize_wind ...
- Java经典面试题(二)-不古出品
@ 目录 1. 为什么说 Java 语言"编译与解释并存"? 2.Oracle JDK 和 OpenJDK 的对比? 3.字符型常量和字符串常量的区别? 4.Java 泛型了解么? ...
- [atARC103F]Distance Sums
给定$n$个数$d_{i}$,构造一棵$n$个点的树使得$\forall 1\le i\le n,\sum_{j=1}^{n}dist(i,j)=d_{i}$ 其中$dist(i,j)$表示$i$到$ ...
- [loj3246]Cave Paintings
题中所给的判定条件似乎比较神奇,那么用严谨的话来说就是对于两个格子(x,y)和(x',y'),如果满足:1.$x\le x'$:2.从(x,y)通过x,x+1,--,n行,允许向四个方向走,不允许经过 ...