Sharding-JDBC 实现水平分库分表
1、需求分析
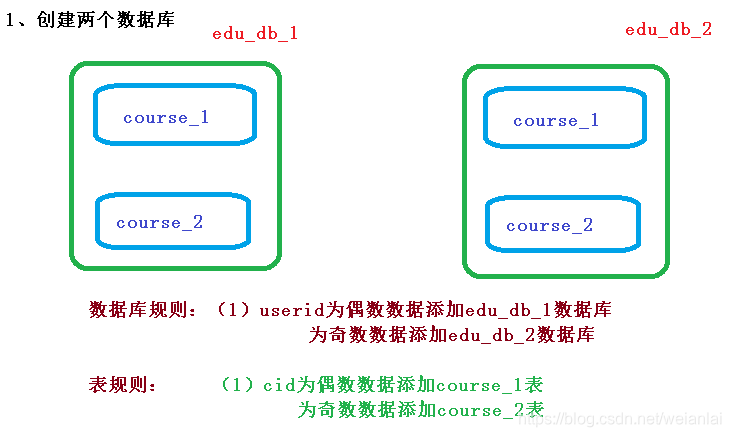
![]()
CREATE TABLE `edu_db_1`.`course_1` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) NULL,
`user_id` bigint(20) NULL,
`cstatus` varchar(10) NULL,
PRIMARY KEY (`cid`)
);
CREATE TABLE `edu_db_1`.`course_2` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) NULL,
`user_id` bigint(20) NULL,
`cstatus` varchar(10) NULL,
PRIMARY KEY (`cid`)
);
CREATE TABLE `edu_db_2`.`course_1` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) NULL,
`user_id` bigint(20) NULL,
`cstatus` varchar(10) NULL,
PRIMARY KEY (`cid`)
);
CREATE TABLE `edu_db_2`.`course_2` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) NULL,
`user_id` bigint(20) NULL,
`cstatus` varchar(10) NULL,
PRIMARY KEY (`cid`)
);![]()
3、在 SpringBoot 配置文件配置数据库分片规则
## 配置数据源,给数据源起名称
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m1,m2
## 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
##配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
##配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=root
#指定数据库分布情况,数据库里面表分布情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 指定 course 表里面主键 cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定数据库分片策略 约定 user_id 是偶数添加 m1,是奇数添加 m2
#spring.shardingsphere.sharding.default-database-strategy.inline.shardingcolumn=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithmexpression=m$->{user_id % 2 + 1}
spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show=true![]()
4、编写测试方法
//添加操作
@Test
public void addCourseDb() {
for (int i = 0; i < 10; i++) {
Course course = new Course();
course.setCname("javademo" + i);
//分库根据 user_id
course.setUserId(100L + i);
course.setCstatus("Normal1");
courseMapper.insert(course);
}
}
//查询操作
@Test
public void findCourseDb() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("user_id",101L);
//设置 cid 值
wrapper.eq("cid",581615031192387584L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}![]()
Sharding-JDBC 实现水平分库分表的更多相关文章
- 分库分表中间件sharding-jdbc的使用
数据分片产生的背景,可以查看https://shardingsphere.apache.org/document/current/cn/features/sharding/,包括了垂直拆分和水平拆分的 ...
- MySQL 分库分表方案,总结的非常好!
前言 公司最近在搞服务分离,数据切分方面的东西,因为单张包裹表的数据量实在是太大,并且还在以每天60W的量增长. 之前了解过数据库的分库分表,读过几篇博文,但就只知道个模糊概念, 而且现在回想起来什么 ...
- mysql分库分表(二)
mysql分库分表 参考: https://www.cnblogs.com/dongruiha/p/6727783.html https://www.cnblogs.com/oldUncle/p/64 ...
- 采用Sharding-JDBC解决分库分表
源码:Sharding-JDBC(分库分表) 一.Sharding-JDBC介绍 1,介绍 Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被 ...
- 分库分表之ShardingSphere
目录 分库分表诞生的前景 分库分表的方式(垂直拆分,水平复制) 1.垂直拆分 1.1 垂直分库 1.2 垂直分表 2.水平拆分 2.1 水平分库 2.2 水平分表 分库分库中间件 ShardingSp ...
- sharding-jdbc之——分库分表实例
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/79368021 一.概述 之前,我们介绍了利用Mycat进行分库分表操作,Mycat ...
- Java互联网架构-Mysql分库分表订单生成系统实战分析
概述 分库分表的必要性 首先我们来了解一下为什么要做分库分表.在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量.连接数.处理能力等都很有限,数据库本身的“有状态性” ...
- Mysql 分库分表方案
0 引言 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. mysql中有一种机制是表锁定和行锁 ...
- 【转】mysql分库分表,数据库分库分表思路
原文:https://www.cnblogs.com/butterfly100/p/9034281.html 同类参考:[转]数据库的分库分表基本思想 数据库分库分表思路 一. 数据切分 关系型数 ...
随机推荐
- C#笔记2__Char类、String类、StringBuilder类 / 正则表达式 /
Char类 String类 字符串的格式化:String类的Format方法 StringBuilder类 以上:百度 or 查手册.....
- cm0 逆向分析
目录 cm0 逆向分析 前言 Strings工具复习 String工具使用说明 Strings工具解cm0题 cm0 逆向分析 前言 Emmmmm,我假装你看到这里已经学过了我的<恶意代码分析实 ...
- S 锁与 X 锁的爱恨情仇《死磕MySQL系列 四》
系列文章 一.原来一条select语句在MySQL是这样执行的<死磕MySQL系列 一> 二.一生挚友redo log.binlog<死磕MySQL系列 二> 三.MySQL强 ...
- RocketMQ源码详解 | Broker篇 · 其二:文件系统
概述 在 Broker 的通用请求处理器将一个消息进行分发后,就来到了 Broker 的专门处理消息存储的业务处理器部分.本篇文章,我们将要探讨关于 RocketMQ 高效的原因之一:文件结构的良好设 ...
- Device /dev/sdb excluded by a filter
原因是添加的磁盘是在另一个虚拟机中新建的,已经有了分区表,现在的虚拟机并不能识别磁盘的分区表,运行parted命令重做分区表,中途需要输入三次命令(mklabel msdos -> yes-&g ...
- 【Go语言学习笔记】函数做参数和闭包
函数做参数 在Go语言中,函数也是一种数据类型,我们可以通过type来定义它,它的类型就是所有拥有相同的参数,相同的返回值的一种类型.类似于重写(同名覆盖). 回调函数:函数有一个参数是函数类型,这个 ...
- MySQL到底能否解决幻读问题
先说结论,MySQL 存储引擎 InnoDB 在可重复读(RR)隔离级别下是解决了幻读问题的. 方法:是通过next-key lock在当前读事务开启时,1.给涉及到的行加写锁(行锁)防止写操作:2. ...
- SpringCloud 2020.0.4 系列之 Stream 消息广播 与 消息分组 的实现
1. 概述 老话说的好:事情太多,做不过来,就先把事情记在本子上,然后理清思路.排好优先级,一件一件的去完成. 言归正传,今天我们来聊一下 SpringCloud 的 Stream 组件,Spring ...
- SpringCloud升级之路2020.0.x版-34.验证重试配置正确性(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 在前面一节,我们利用 resilience4j 粘合了 OpenFeign 实现了断路器. ...
- RocketMQ架构原理解析(二):消息存储
一.概述 由前文可知,RocketMQ有几个非常重要的概念: broker 服务端,负责存储.收发消息 producer 客户端1,负责产生消息 consumer 客服端2,负责消费消息 既然是消息队 ...