莫烦python教程学习笔记——总结篇
一、机器学习算法分类:
监督学习:提供数据和数据分类标签。——分类、回归
非监督学习:只提供数据,不提供标签。
半监督学习
强化学习:尝试各种手段,自己去适应环境和规则。总结经验利用反馈,不断提高算法质量
遗传算法:淘汰弱者,留下强者,进行繁衍和变异穿产生更好的算法。
二、选择机器学习算法和数据集
sklearn中有很多真实的数据集可以引入,也可以根据自己的需求自动生成多种数据集。对于数据集可以对其进行归一化处理。
sklearn中的有着多种多样的算法,每一种算法都有其适用的场合、不同的属性和功能,按需选择。
三、评价机器学习算法:
1、算法效果不好:在训练过程中,可能因为数据集问题,学习效率,参数问题可能导致算法效果不好。
2、评价学习算法:将数据集分为训练集和测试集,根据算法在测试集上的表现评价算法,随着训练时间变长,网络层数变多,误差变小,精确度变高,但是变化的速度都是减缓的。
不同的模型有着是个自己的不同的评分方法:
R2-score:衡量回归问题的精度。最大精度也是100%
F1-score:用于测量不均衡数据的精度。
3、交叉验证用于调参(手动写循环):用于算法的调参(不同的参数也就是不同的模型)。
用交叉验证的方法进行调参或者模型选择时不需要手动划分用于k折验证的数据集,只需要将X和Y,还有k作为参数传进去即可:
#for regreesion
losss=-cross_val_score(knn,X,y,cv=10,scoring=’mean_squared_error’)
#for classification
scores=cross_val_score(knn,X,y,cv=10,scoring=’accuracy’)
交叉验证时,对于模型的评分,分类时用精确度accuracy来衡量模型表现,回归时用损失值mean_squard_error来衡量模型表现。
losss和 scores是两个数组,数组的长度为交叉验证的分割份数。
可使用scores.mean()来得到交叉验证的平均分数。
改变Knn中的参数值,根据交叉验证的得分高低来选择合适的模型参数。
4、learn_curve曲线用于过拟合问题:横轴数据量,纵轴模型得分
过拟合:对于样本的过度学习,过分关注样本的细节。
解决过拟合:L1/L2 regularization,dropout(留出法)
为了找出欠拟合和过拟合的节点我们可以绘制learn_curve曲线,这是一个根据数据量不同显示算法性能的图。显示了过拟合问题的两种误差:蓝色是traindata的算法表现,红色是testdata的算法表现。因为模型是基于traindata进行训练的,所以其在traindata上的表现更好一些。

train_sizes,train_loss,test_loss=learning_curve(
SVC(gramma=0.001),
X,
y,
Cv=10.
Scoring=’mean_squard_error’,
Train_sizes=[0.1,0.25,0.5,0.75,1])
Train_loss_mean=-np.mean(train_loss,axis=1) #10次交叉验证结果取平均
Test_loss_mean=-np.mean(test_loss,axis=1)
train_loss,test_loss是二维数组,长度为5,即为Train_sizes的步数
train_loss[0]是一个数组,存放0.1数据量时10个交叉验证的结果。
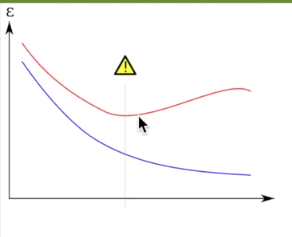
如上图所示,黄色警告处即为欠拟合和过拟合的分界点处。
5、使用交叉验证validation_curve自动调参:横坐标是模型参数,纵坐标是模型交叉验证得分
param_range = np.logspace(-6, -2.3, 5)
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10,
scoring='mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
train_loss,test_loss是二维数组,长度为参数的取值个数
train_loss[0]是一个数组,存放参数为某一个值时10个交叉验证的结果。
以模型参数为横坐标,以模型交叉验证得分为纵坐标绘图,最低点即为最佳参数。
莫烦python教程学习笔记——总结篇的更多相关文章
- 莫烦python教程学习笔记——保存模型、加载模型的两种方法
# View more python tutorials on my Youtube and Youku channel!!! # Youtube video tutorial: https://ww ...
- 莫烦python教程学习笔记——validation_curve用于调参
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——learn_curve曲线用于过拟合问题
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——利用交叉验证计算模型得分、选择模型参数
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——数据预处理之normalization
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——线性回归模型的属性
#调用查看线性回归的几个属性 # Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg # ...
- 莫烦python教程学习笔记——使用波士顿数据集、生成用于回归的数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——使用鸢尾花数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦大大TensorFlow学习笔记(9)----可视化
一.Matplotlib[结果可视化] #import os #os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf i ...
随机推荐
- hive 权限排查
show grant role role_username id username
- Idea tomcat debug按钮灰色无法运行
打开Project Structure 2.选中src,点击按钮关闭界面,重启idea即可
- [loj3146]路灯
显然,能从$l$到$r$当且仅当$[l,r)$中的灯全部都亮,以下不妨令询问的$r$全部减1 当修改节点$x$时,找到包含$x$的极大的灯(除$x$以外)全部都亮的区间$[l,r]$,即令$l_{0} ...
- [bzoj2743]采花
预处理出每一个点下一个相同颜色的位置,记为next,然后将询问按左端点排序后不断右移左指针,设要删除i位置,就令f[next[next[i]]+1,同时还要删除原来的标记,即令f[next[i]]-1 ...
- [atAGC106F]Figures
考虑purfer序列,若生成树的pufer序列为$p_{i}$,则答案为$(\prod_{i=1}^{n}a_{i})\sum_{p}\prod_{i=1}^{n}\frac{(a_{i}-1)!}{ ...
- 洛谷 P5406 - [THUPC2019]找树(FWT+矩阵树定理)
题面传送门 首先看到这道题你必须要有一个很清楚的认识:这题新定义的 \(\oplus\) 符号非常奇怪,也没有什么性质而言,因此无法通过解决最优化问题的思路来解决这个问题,只好按照计数题的思路来解决, ...
- DirectX12 3D 游戏开发与实战第六章内容
利用Direct3D绘制几何体 学习目标 探索用于定义.存储和绘制几何体数据的Direct接口和方法 学习编写简单的顶点着色器和像素着色器 了解如何用渲染流水线状态对象来配置渲染流水线 理解怎样创建常 ...
- window文件挂载到linux
- jenkins原理简析
持续集成Continuous Integration(CI) 原理图: Gitlab作为git server.Gitlab的功能和Github差不多,但是是开源的,可以用来搭建私有git server ...
- Shell中 ##%% 操作变量名
在linxu平台下少不了对变量名的处理,今天记录下shell中 ##%% 对变量名的操作. #操作左侧,%操作右侧. #号处理方式: 对于单个#,处理对象为变量中指定的第一个符号左侧字符串, 对于两个 ...