菜鸟到大神之多图预警——从 RAID 到分布式系统中的副本分布
我们知道,在面对大规模数据的计算和存储时,有两种处理思路:
- 垂直扩展(scale up):通过升级单机的硬件,如 CPU、内存、磁盘等,提高计算机的处理能力。
- 水平扩展(scale out):通过添加更多的机器到分布式系统中,提高整个系统的处理能力。
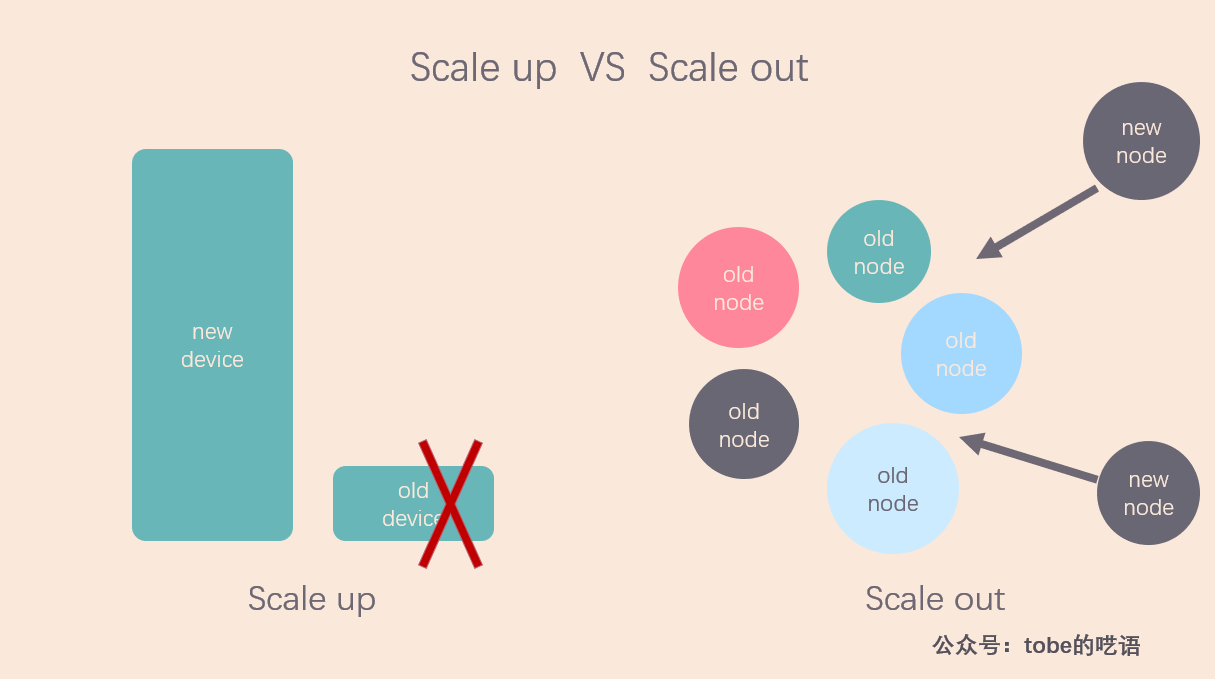
在分布式技术尚未成熟的时候,小型机、中型机、大型机、超级计算机逐步升级的方案几乎是大型公司的唯一选择,但是这种垂直扩展是有天花板的,硬件升级的速度远远比不上数据规模的增速,即使是超级计算机也无法满足人们对计算资源的需求。
水平扩展方案,也就是在一个系统里不断添加机器的方案,就这么走上了历史舞台。这就是现在的分布式技术。
在这篇文章里,我将分别介绍单机系统下的 RAID 存储技术以及分布式系统下的存储分布技术,这两种技术在思想上有很相近的地方,希望读者慢慢体会。
RAID
RAID,全称是Redundant Array of Inexpensive/Independent Disks,也就是磁盘冗余阵列,这里的 I 有两种说法,一种是 Inexpensive,廉价,另一种是Independent ,独立。所谓 RAID 就是将多块磁盘组合在一起,对外抽象成一个容量大,读写速度高,容错性好的大型磁盘。
我很喜欢「抽象」这个概念,因为它为我们屏蔽了更底层的细节,比如操作系统中的文件系统,虚拟内存等。在我看来,RAID 就是对多个独立磁盘的抽象。
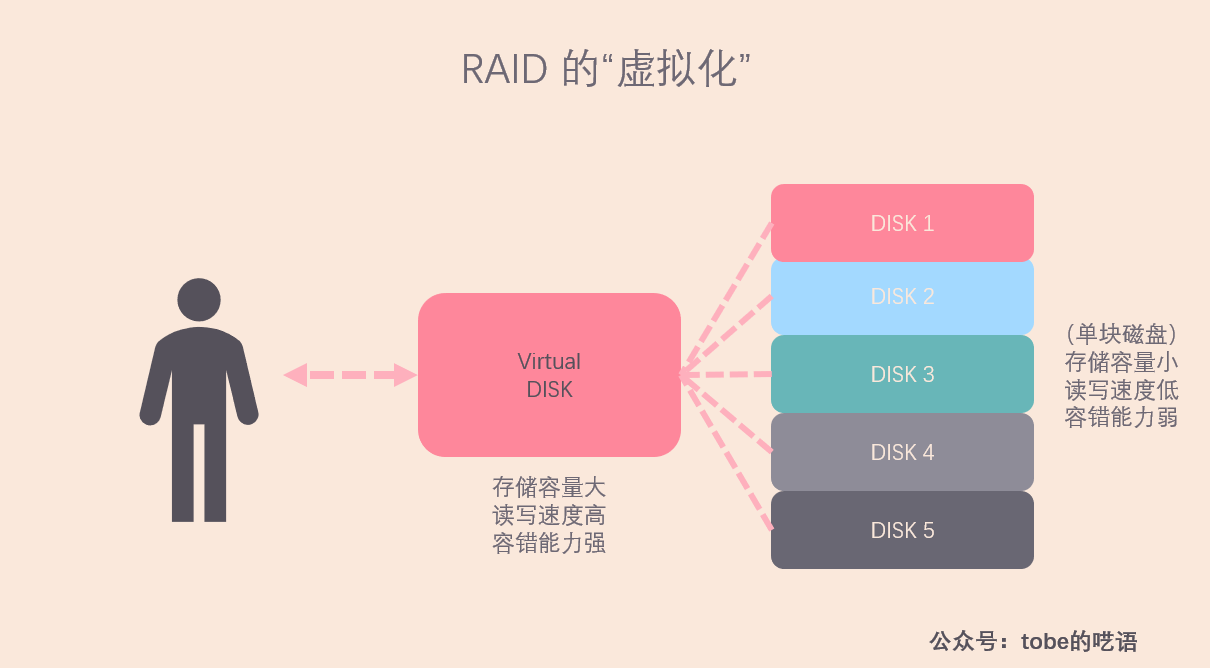
注意,上面的图里的三个方面(存储容量、读写速度、数据可靠性)是衡量存储系统的重要标准,我们在分布式系统里也会提及,不过现在让我们先来看看常用的 RAID 技术。
RAID 0
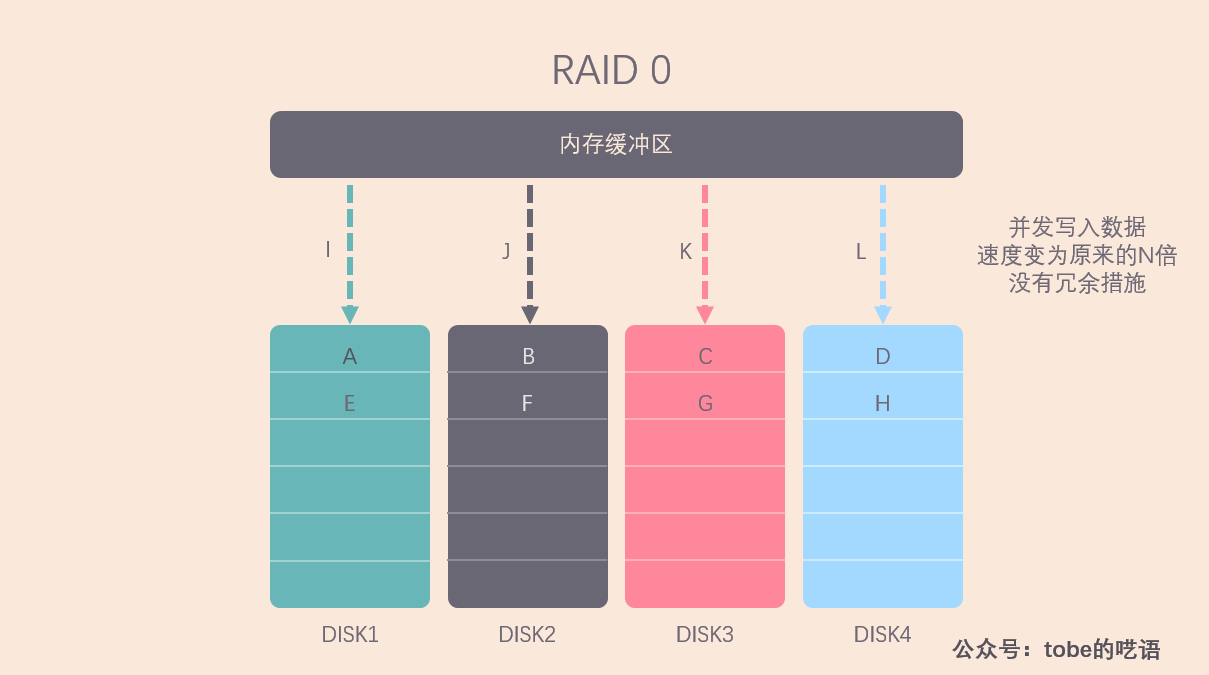
RAID 0 是数据在从内存缓冲区写入磁盘时,根据磁盘的数量,将数据分成 N 份,然后把这些数据并发写入 N 块磁盘,每块磁盘上存储不同的数据,这样整体的数据写入速度是单个磁盘的 N 倍,读取当然也是并发执行的。
因此 RAID 0 具有极快的数据读写速度。但是RAID 0不做数据备份,N块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据就无法使用了。
RAID 1
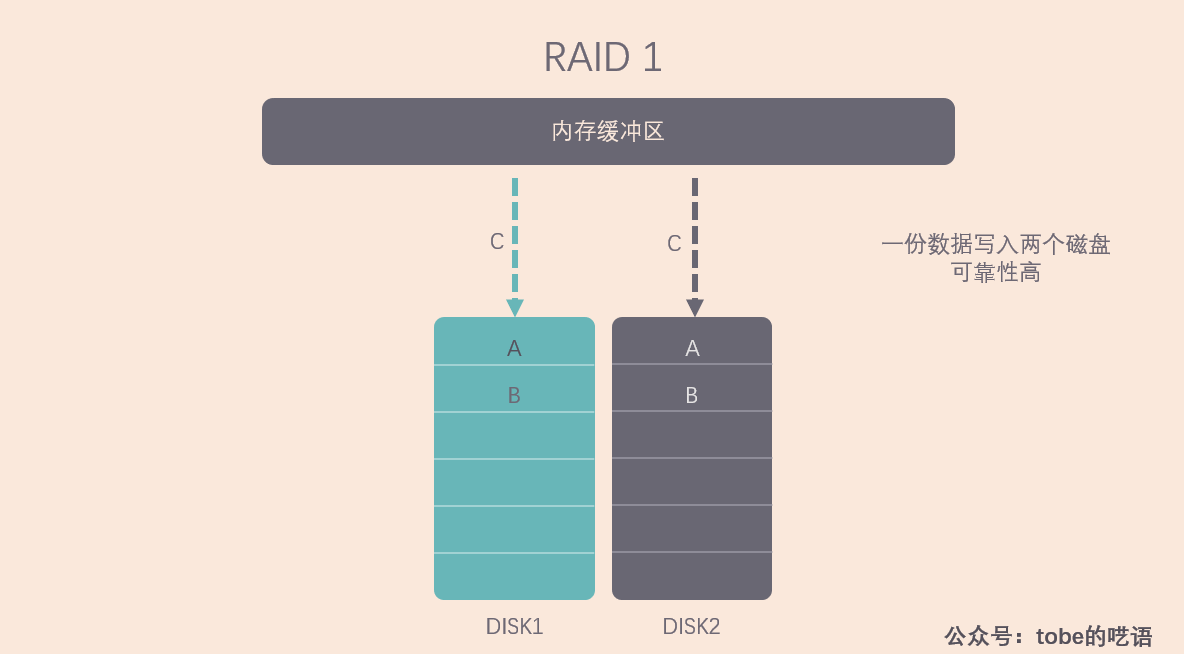
RAID 1 的策略更为简单,不管你有几个磁盘,都给我存一样的数据,这样数据的可靠性极高,但是写入速度收到很大影响。
Any read request can be serviced by any drive in the set. If a request is broadcast to every drive in the set, it can be serviced by the drive that accesses the data first (depending on its seek time and rotational latency), improving performance. Sustained read throughput, if the controller or software is optimized for it, approaches the sum of throughputs of every drive in the set, just as for RAID 0. Actual read throughput of most RAID 1 implementations is slower than the fastest drive. Write throughput is always slower because every drive must be updated, and the slowest drive limits the write performance. The array continues to operate as long as at least one drive is functioning.1
这段话意思是说,RAID 1 的读取速度取决于哪一个硬盘能最先访问到待读取的数据,如果软件上有优化,可以达到 RAID 0 的读取速度。但是最慢的磁盘限制了写入速度,因为系统需要等待最慢的磁盘完成写入并做好检验工作。RAID 1 的可靠性好,只要阵列里有任意一块磁盘还能用,阵列就能继续工作,而且当新磁盘替代旧磁盘后,系统会自动复制数据。
RAID 10
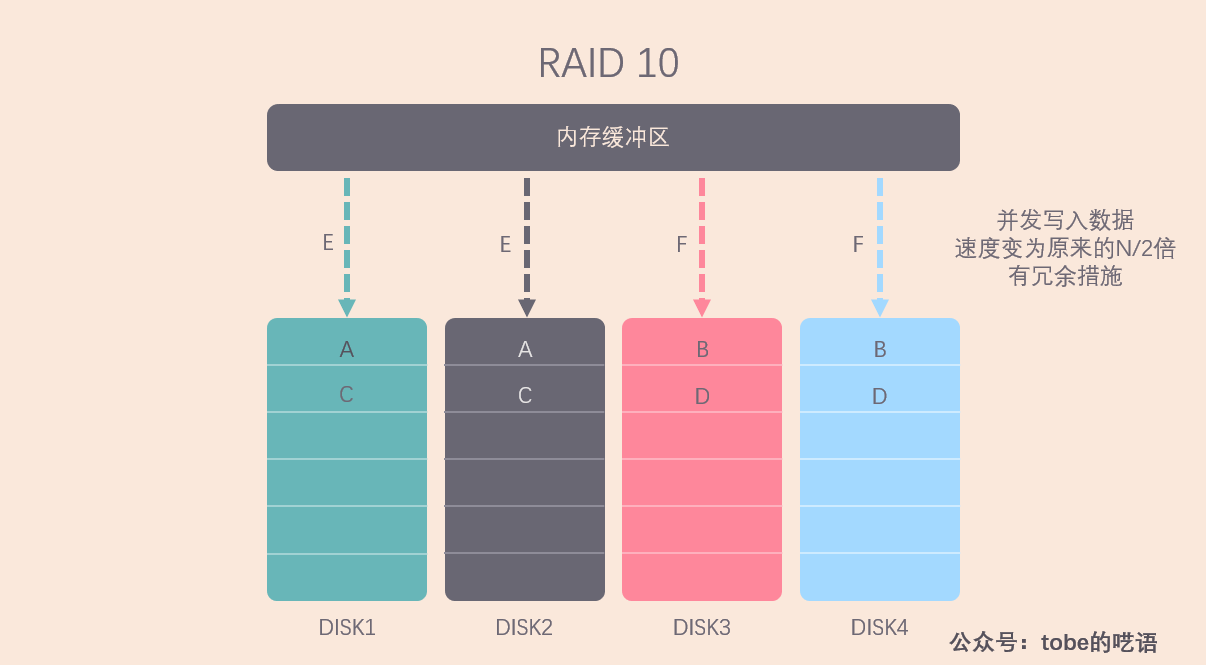
RAID 0 读写速度高,但没有数据冗余, RAID 1 做了数据备份,但读写速度受到制约,所以就需要想办法结合 RAID 0 和 RAID 1,扬长避短,RAID 10 就这么出现了。
RAID 10 就是将 N 个磁盘平均分成两份,这两份互为镜像,相当于是 RAID 1,但对于每份磁盘中的 N/2 块磁盘来说,其存储方式像 RAID 0 一样,可以做到并发读写。这样就做到了折中,在读写速度和容错能力上有一个平衡。
我们不难看出来,RAID 10 的磁盘利用率较低,有一半的磁盘都拿来做备份了,着实有些奢侈。
就一般情况而言,服务器上很少出现同时损坏两块磁盘的情况,往往是损坏一块磁盘的时候,就换上新的磁盘,然后利用恢复技术恢复损坏磁盘上的数据,所以我们可以据此设计一个磁盘利用率更高的方案。
RAID 3 and RAID 5
有了前面的讨论,我们可以想到,如果任何一块磁盘上的数据,都能通过其它 N-1 块磁盘上的数据恢复出来,不就解决我们的问题了吗?
校验机制正好满足我们的要求。
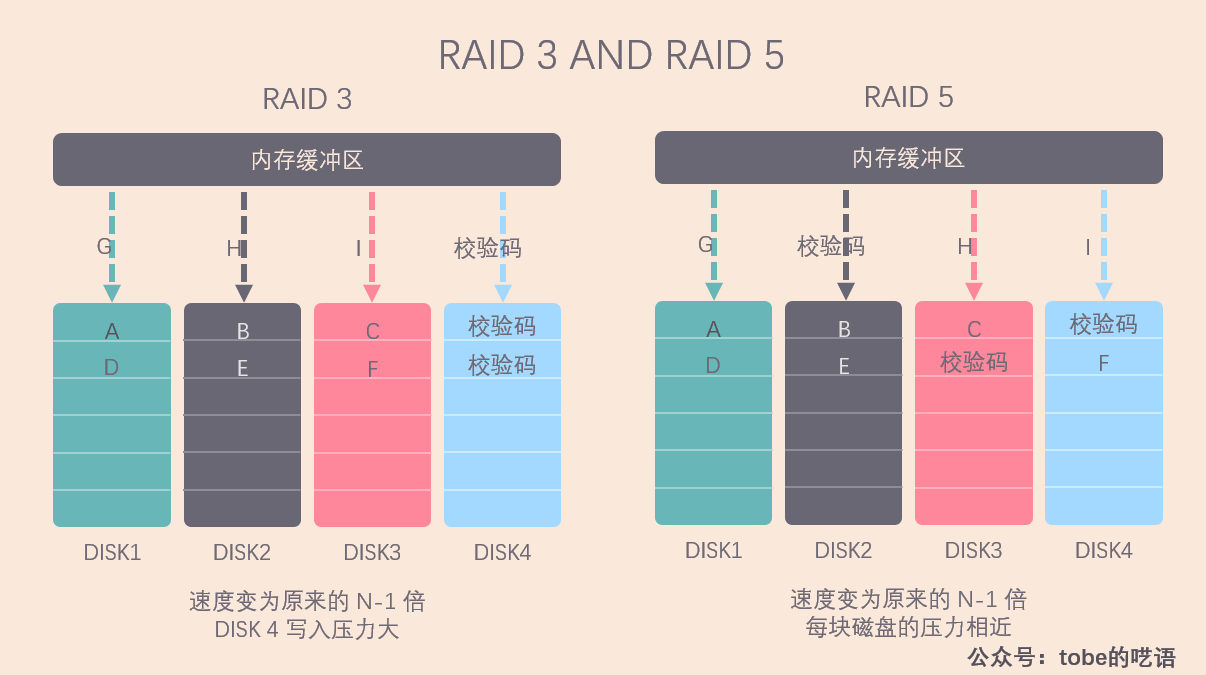
在写入磁盘的时候,我们把数据分成 N-1 份,并发写入 N-1 块磁盘,然后用剩下的一块磁盘记录校验数据,这样我们就可以容忍任意一块磁盘的损坏。
根据校验数据写入的位置,我们有了两种方案:
- RAID 3:所有的校验数据写在同一块磁盘上。在数据修改较频繁的场景下,任何一块磁盘上数据的修改都会导致校验盘要重新写入数据。这会导致校验盘比其他磁盘更容易损坏,所以 RAID 3 很少在实践中使用。用专业一点的话来说,就是负载不均衡了。
- RAID 5:校验数据螺旋式地写入所有磁盘。看上面的图就能分辨出这两种方案的差别,RAID 5 让每一块磁盘都承担一部分的校验工作,这样修改校验数据的压力也就被分散到了所有的磁盘,做到了我们所期望的负载均衡。因此 RAID 5 是使用更为广泛的方案。
RAID 6
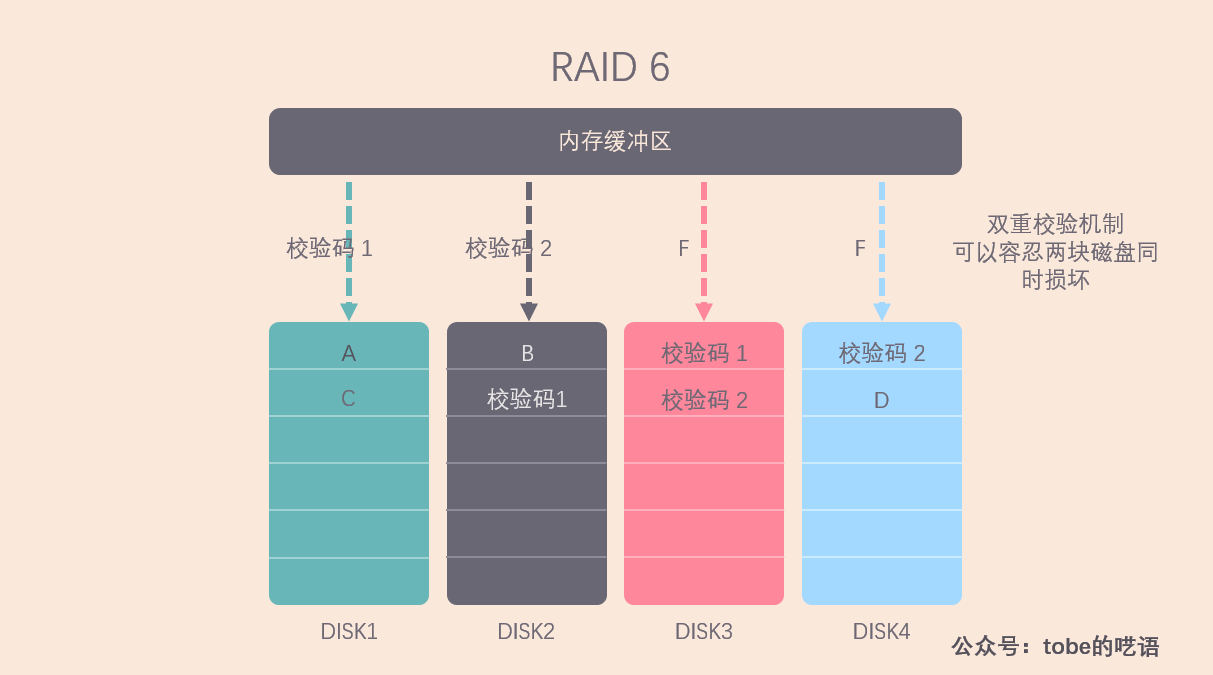
相较于 RAID 5,RAID 6 的可靠性更高,因为 RAID 6 采用了两种校验码螺旋写入的方案,这样可以容忍两块磁盘同时损坏。
什么情况下需要这样的容错能力?在大型服务器上,每块磁盘的容量往往很大,在某一块磁盘损坏后,即使立马替换上了新磁盘,也需要很长时间才能把所有数据恢复完毕,那么在这段时间里,如果有另一块磁盘损坏,数据就没办法恢复了,这是我们不能接受的,因此就需要 RAID 6 来确保数据的完整性。
分布式存储方案
PS:本文着重于分布式系统的副本与数据分布的关系,因为这部分的思想与 RAID 有相似之处,关于一致性哈希等问题将单独写一篇文章介绍。
分布式系统应对的存储规模要比单机大很多,但基本思想和设计目标都是一致的:
- 提高系统的吞吐量
- 提高系统的存储容量
- 利用数据备份,提高系统可靠性
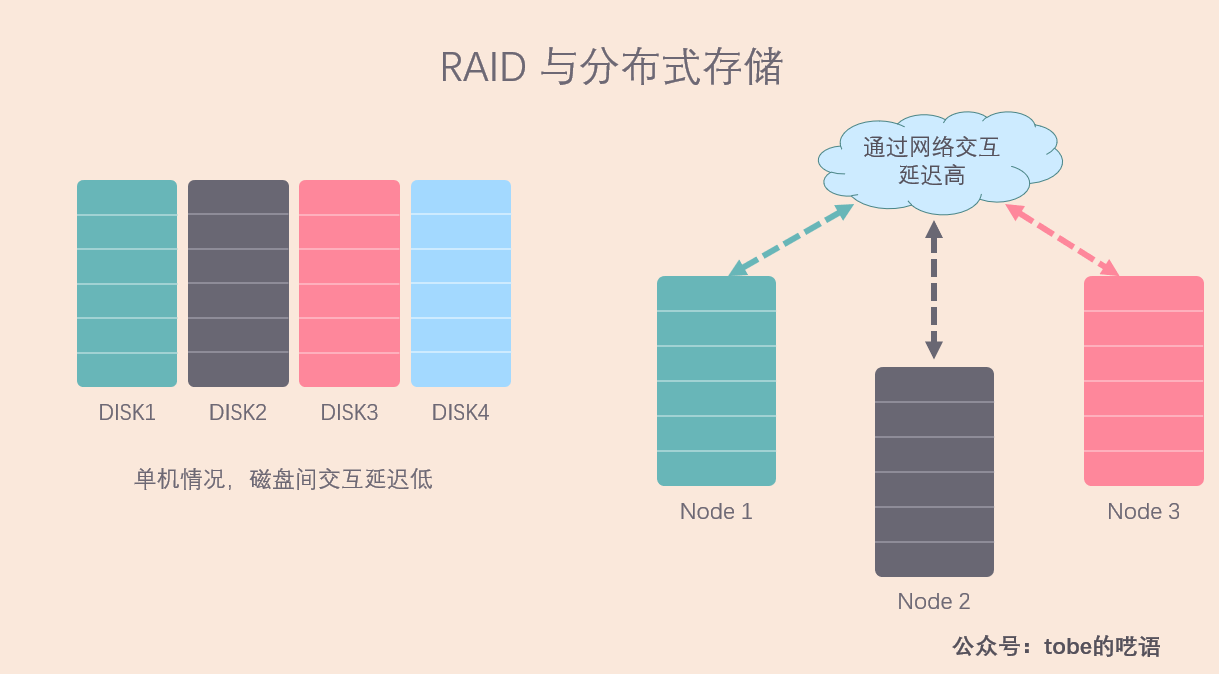
与单机情况不同,分布式系统面临的问题要多得多,因为服务器之间的数据是通过网络传输,延时较高,甚至可能会出现网络中断,导致某些机器无法访问。这对我们的存储方案有很大影响,比如,我们还能用类似 RAID 5 的校验方式来做冗余吗?
答案是否定的,因为做校验的成本太高了,一次校验需要其它 N-1 台机器的响应,一等就是几十毫秒,效率极低,而且网络负载太大了。相反,RAID 10 的方案看起来更适合现在的情况。
以机器为单位的副本
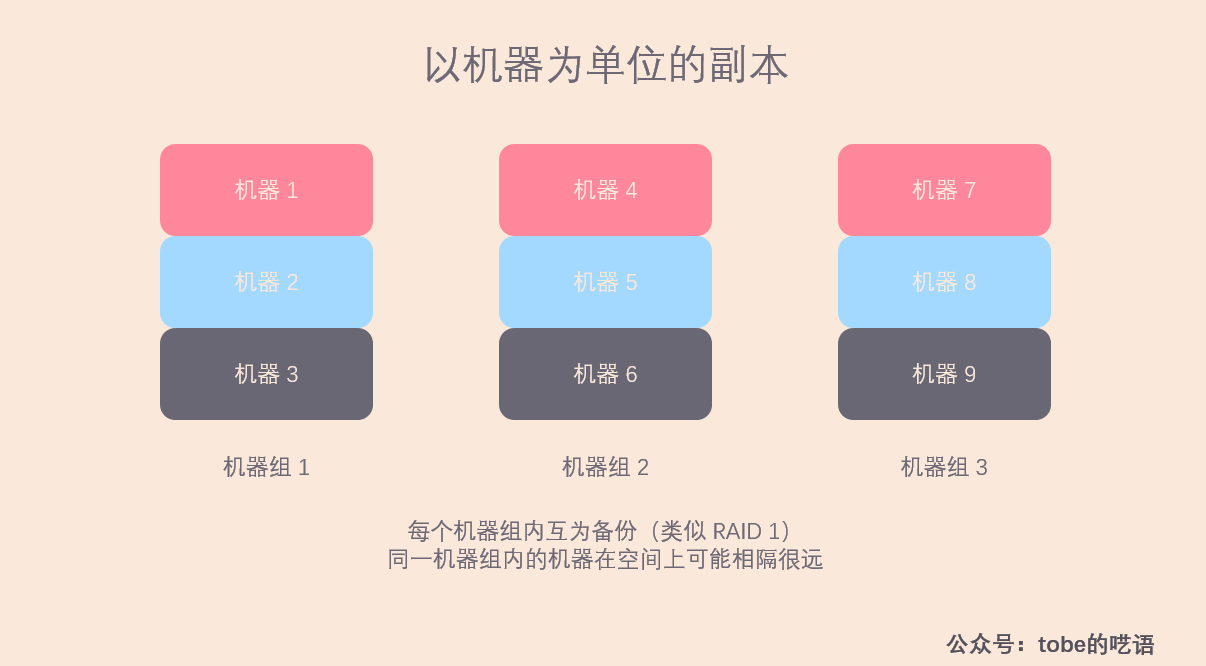
在该方式下,若干机器互为副本,副本机器之间的数据是完全一样的,就像 RAID 1 的方案一样。这种方式的优点就是简单,但缺点也很明显:
- 恢复数据的效率低:假如机器 3 磁盘损坏,丢失了所有的数据,于是我们又调度一台新机器进入该机器组,为了让该机器尽快提供服务,需要从其他两台机器上拷贝数据。但是由于网络带宽的限制,数据恢复的速度慢。
- 可扩展性不高:每个机器组有三台机器,想要扩展,就需要一次加三台机器。
- 不利于系统容错:一台机器宕机,读写压力将由剩下的两台机器承担,压力增加了 50 %,很有可能超过单台机器的处理能力。
因此,以机器作为副本单位不适合当前的场景,我们需要寻找其它的途径。
以数据段为单位的副本
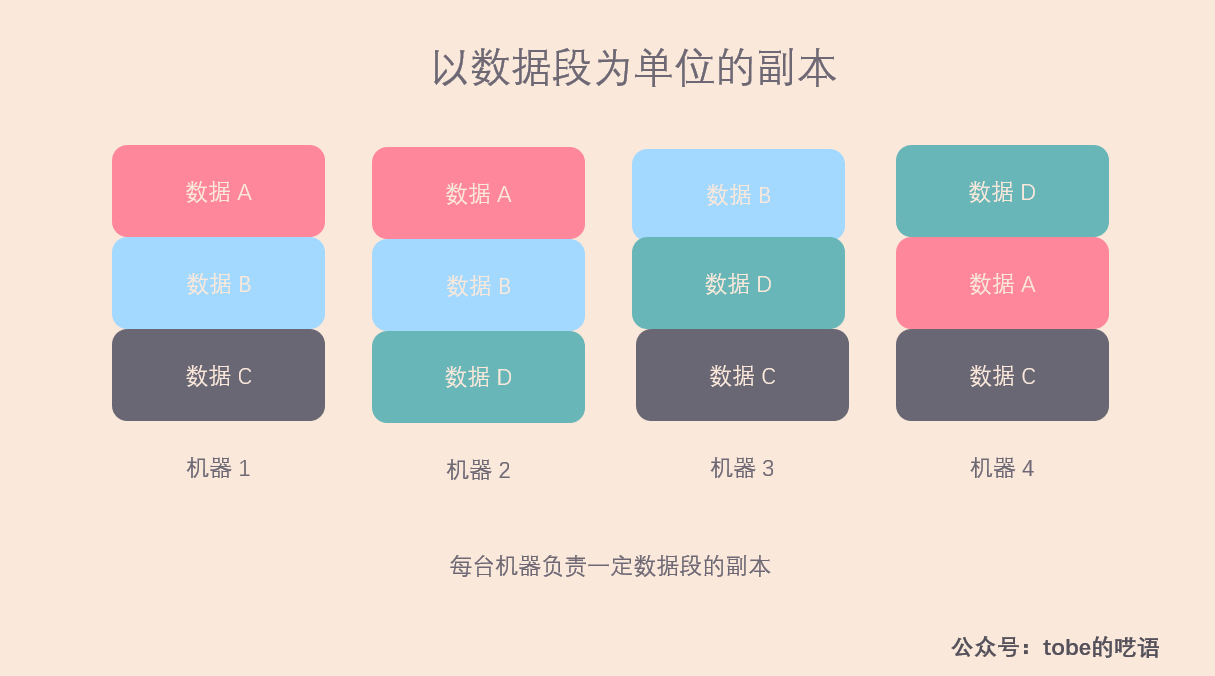
相较于以机器为副本单位,将数据拆分成以数据段为单位作为副本的灵活性更佳,下面我就用一个更直观例子来说明该方案的优点。
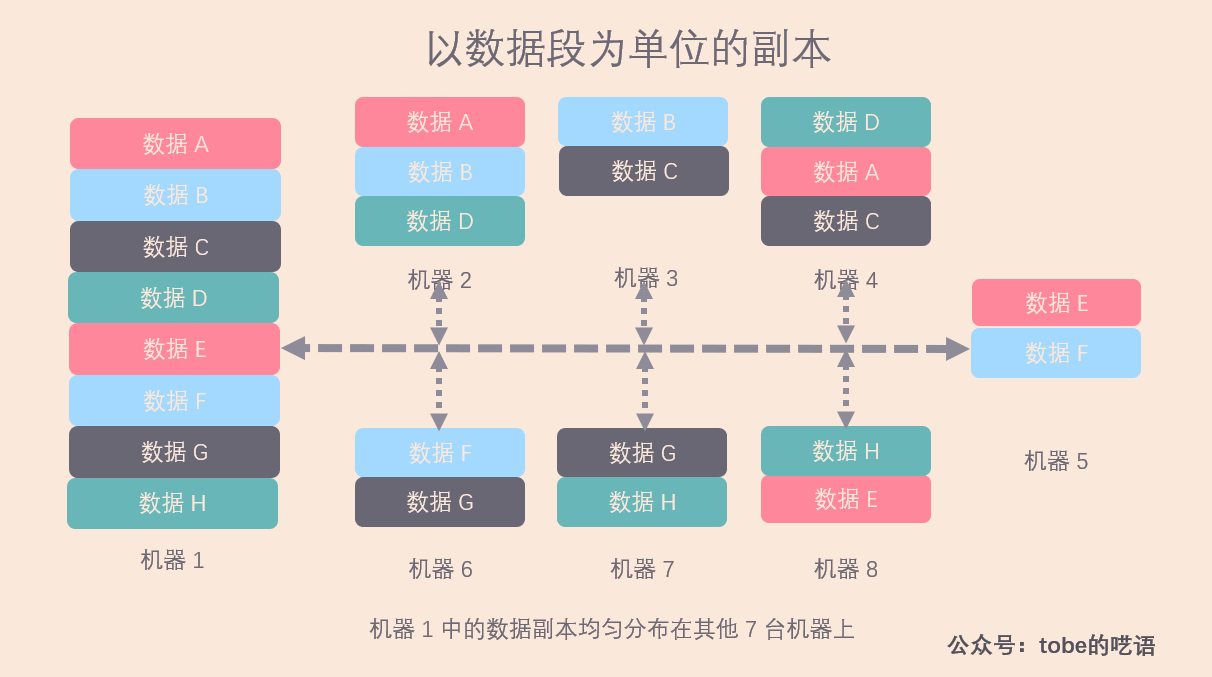
该例子下,机器 1 的所有数据都分布在其他的 7 台机器上,忽略集群中其他的机器。
这种方案为我们带来了什么好处?
- 恢复数据的效率高。假设机器 1 数据丢失,需要重新拷贝所有数据,由于数据分布在剩下的 7 台机器上,我们可以从剩下的所有机器同时拷贝恢复数据,这样,即使每台机器都以较低的资源做拷贝工作,也能很快将数据复制完毕。注意,集群越大,每台机器上承担的工作量就越小,而且实现了负载均衡。
- 集群的可扩展性高。当加入一台新的机器时,我们只需要从每台机器上迁移 1/8 比例的数据段到新机器上,实现新的负载均衡。
- 系统容错性高。假设机器 1 宕机,暂时无法提供服务,那么剩余 7 台机器的压力提高 14.3% ,可以接受。
但是这种方案不是没有问题,因为我们需要一台服务器来记录数据段与机器的对应关系,这台服务器称为元数据服务器。可以想象,随着集群规模的增长,需要管理的元数据的开销也会不断增大,副本的维护难度相应增大,所以现在一种折中的方案是,将某些数据段组成一个数据段分组,以数据段分组为粒度进行副本管理,这样,可以将副本粒度控制在一个较为合适的范围。
分布式存储的副本分布内容就介绍到这里了,希望你在看完我的文章之后有所收获,期待你的赞和转发!
如果本文对你有帮助,欢迎关注我的公众号 tobe的呓语 ,带你深入计算机的世界~ 公众号后台回复关键词【计算机】有惊喜哦~
菜鸟到大神之多图预警——从 RAID 到分布式系统中的副本分布的更多相关文章
- 多图预警——从 RAID 到分布式系统中的副本分布
原文首发于个人博客「tobe的呓语」欢迎大家的访问收藏啊~ 我们知道,在面对大规模数据的计算和存储时,有两种处理思路: 垂直扩展(scale up):通过升级单机的硬件,如 CPU.内存.磁盘等,提高 ...
- C语言是菜鸟和大神的分水岭
作为一门古老的编程语言,C语言已经坚挺了好几十年了,初学者从C语言入门,大学将C语言视为基础课程.不管别人如何抨击,如何唱衰,C语言就是屹立不倒:Java.C#.Python.PHP.Perl 等都有 ...
- 从菜鸟到大神:Java高并发核心编程(连载视频)
任何事情是有套路的,学习是如此, Java的学习,更是如此. 本文,为大家揭示 Java学习的套路 背景 Java高并发.分布式的中间件非常多,网上也有很多组件的源码视频.原理视频,汗牛塞屋了. 作为 ...
- 大神的P图过程!快来偷窥!
来自美国的艺术家James(@jameasons) 平时我们总是能看到一些大神合成出这样的图片, 但是他们P图的过程是怎样的,很多人都是不知道的. 接下来再看看这位大神的其他作品, 如果你看了上面视频 ...
- 大神的游戏(codevs 1353)
题目描述 Description 在那遥远的机房,有一片神奇的格子.为了方便起见,我们编号为1~n.传说只要放入一些卡片,就能实现愿望.卡片一共有m种颜色,但是相邻的格子间不能放入相同颜色的卡片.只要 ...
- 把所有时间用来做你最应该做的事,用尽全力竭尽所能成为DL and NLP大神。
两段代码,JAVA and CPP,输出相同结果: #include "stdafx.h" #include <iostream> using namespace st ...
- [转帖] select、poll、epoll之间的区别总结[整理] + 知乎大神解答 https://blog.csdn.net/qq546770908/article/details/53082870 不过图都裂了.
select.poll.epoll之间的区别总结[整理] + 知乎大神解答 2016年11月08日 15:37:15 阅读数:2569 http://www.cnblogs.com/Anker/p/3 ...
- 大神你好,可以帮我P张图吗?
韩国版的求大神帮我P张图,看得有点下巴脱臼啊!哈哈哈哈哈哈哈~ 感觉照片拍得很尴尬,请大神P得更有动感 拍了跳跃照片,但内衣露出来一点,能帮忙去掉吗 不喜欢没穿制服的样子,请帮忙加上制服 希望背景 ...
- ruby大神与菜鸟的代码区别
之前Brand类 has_and_belongs_to_many :categories, index: true 现在在Category类 增加 has_and_belongs_to_many ...
随机推荐
- 记一次ARM服务器(鲲鹏920)的PXE批量装机遇到的坑
由于近期项目需要,在对一批华为鲲鹏920的ARM服务器(型号为天宫TG225 B1)进行批量装机的过程中,遇到了各种各样千奇百怪的bug(换个高情商的说法就是遇到了各种各样和x86服务器不一样的地方) ...
- [BJDCTF2020]EzPHP-POP链
那次某信内部比赛中有道pop链问题的题目,我当时没有做出来,所以在此总结一下,本次以buu上复现的[MRCTF2020]Ezpop为例. 题目 1 Welcome to index.php 2 < ...
- 关于CKCsec安全研究院
关于CKCsec安全研究院 CKCsec安全研究院所有文档开源于语雀,会源源不断更新. 部分内容 微信公众号 知识星球 使用需知 由于传播.利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均 ...
- Android官方文档翻译 十二 3.Supporting Different Devices
Supporting Different Devices 支持不同设备 Dependencies and prerequisites 依赖关系和先决条件 Android 1.6 or higher A ...
- 集合框架-List集合的常见方法
1 package cn.itcast.p4.list.demo; 2 3 import java.util.List; 4 import java.util.ArrayList; 5 6 publi ...
- postgresql dba常用sql查询语句
查看帮助命令 DB=# help --总的帮助 DB=# \h --SQL commands级的帮助 DB=# \? --psql commands级的帮助 \dn[S+] [PATTERN],其中[ ...
- 幸运转轮(Cakra)
题目描述 lxx参加了某卫视举办的一场选秀节目,凭借曼妙的舞姿和动人的歌声,他在众多idol中脱颖而出.现在在他的面前,有四个大转轮,这四个转轮将决定他能否赢得最终大奖--出道,机会只有一次! 每 ...
- 1. idea spark scala 语言支持设置
Spark 版本为 3.0.0,默认采用的 Scala 编译版本为 2.12 1. 创建名为spark-project 的项目 2. 将src 删除,把spark-project 当成一个父项目, ...
- Hbase 项目
需求分析 1) 微博内容的浏览,数据库表设计 2) 用户社交体现:关注用户,取关用户 3) 拉取关注的人的微博内容 表结构 代码实现 1) 创建命名空间以及表名的定义 2) 创建微博内容表 3) 创 ...
- NOIP2018 Day2T3 保卫王国
首先不考虑强制要求的话是一个经典问题,令 \(f_{i, 0 / 1}\) 为 \(i\) 选或不选时以 \(i\) 为根的子树的最优答案.那么就有转移 \(f_{u, 0} = \sum f_{v, ...