论文笔记:(CVPR2019)PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing
PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing
Hengshuang Zhao Li Jiang Chi-Wing Fu Jiaya Jia
The Chinese University of Hong Kong Tencent Youtu Lab
论文地址:chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=http%3A%2F%2Fjiaya.me%2Fpapers%2Fpointweb_cvpr19.pdf
代码:https://github.com/hszhao/PointWeb
摘要
提出了一种从点云的局部邻域中提取上下文特征的新方法——PointWeb。与以往的工作不同,我们将局部邻域内的每个点紧密地连接起来,目的是根据局部区域特征来指定每个点的特征,以便更好地代表该区域。提出了一种新的特征自适应调整(AFA)模块,用于寻找点间的相互作用。对于每个局部区域,点对之间的元素间的影响映射应用于特征差异映射。然后根据自适应学习的影响指标,将每个特征由同一区域的其他特征拉动或推动。调整后的特征通过区域信息进行了很好的编码,有利于点云分割和分类等点云识别任务。实验结果表明,我们的模型在语义分割和形状分类数据集上都优于最新的技术。
一、引言
我们看到了图像识别任务的巨大进步,如图像分类[11,22,26,7,9,8]和语义分割[14,3,35],这主要是由于具有海量模型容量的深度学习技术的发展。除了2D图像识别,人们对3D视觉也越来越感兴趣[18, 36, 6, 34, 4]用于自动驾驶,增强现实,机器人等应用。大规模高分辨率3D数据集的出现[1,5]也带来了使用深度神经网络来推理3D数据的环境。
直接扩展二维图像的深度学习方法3D识别任务并不总是可行的,因为3D场景通常是由一组无序分散的点来描述的。简单地应用二维特征聚合操作也是不合理的,如对不规则点云的卷积,因为这些操作通常在规则网格上。方法[16,23,21]通过对点云进行体素化和使用3D CNN进行特征学习来解决这个问题,这是一种很自然的想法。这些方法运行缓慢,在体素化过程中可能会造成信息丢失。另外,PointNet[18]体系结构用共享的多层感知机(MLP)直接处理原始点云。下面的pointnet++[20]通过引入层次结构来提取全局和局部特征,进一步提高了性能。不像二维卷积,将一个像素的特征与其局部邻域进行整合,将一个局部区域的特征聚合pointnet++由最大池实现,如图1 (a)所示。
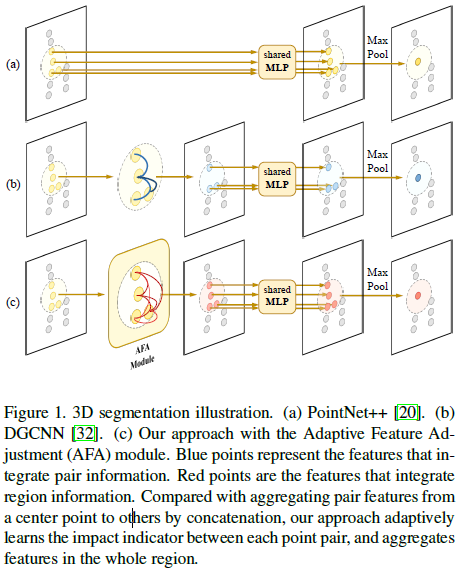
图1所示。三维分割插图。(一)PointNet + +[20]。(b)DGCNN[32]。(c)我们的方法带有自适应特征调整(AFA)模块。蓝色的点代表结合成对信息的特征。红点是融合区域信息的特征。与采用连接的方法从一个中心点聚合到另一个中心点的特征相比,该方法自适应地学习了每个中心点对之间的影响指标,并在整个区域内聚合特征。
对于动态图CNN (DGCNN)[32],它通过连接中心点的特征来聚合每个局部区域的信息。中心点的特征是通过将中心点与其k个最近邻之间的特征差异连接起来得到的,紧接着是MLP和max pooling (图1 (b))。这里只考虑中心点的成对关系,区域信息的整合仍然有限,因为实际的区域聚合操作也是通过简单的max pooling来实现的。PointCNN[13]解决了这个问题,它将这些点排序成一个可能的规范顺序,并对这些点应用卷积。点通过x变换[13]被置换和加权后是否处于规范顺序还需要进一步研究。
与上述方法不同的是,我们通过连接和探索区域内所有的点对来获取局部区域内的上下文信息。为此,我们制定了一个新的模块,即自适应特征调整(AFA),将局部区域内的所有对点连接起来,最终形成一个局部全链接的网络。然后从图1 (c)所示的点对差异中学习对点特征的调整,该策略丰富了局部区域的点特征,形成聚合特征,更好地描述局部区域,便于三维识别。
我们的网络从点对差异中学习影响指标,以确定特征调整,从而允许适当的适应,以获得更好的通用性。图2给出了特征调整的过程。进一步,我们提出了带有AFA模块的PointWeb框架用于三维场景识别,如图4所示,在点云场景理解任务上取得了最先进的结果,包括点云语义分割和形状分类。在三个最具竞争力的数据集上,即Stanford large 3D Indoor Space (S3DIS)[1]用于语义分割,ScanNet[5]用于语义体素标记,ModelNet40[33]用于形状分类,实验结果排名最高。我们相信这种有效的自适应特性调整模块可以使其他点云理解任务受益。我们给出了所有的实现细节,并使我们的代码和训练过的模型公开可用。
我们的主要贡献是双重的。
- 我们通过自适应特征调整,使成对的每个3D点之间的信息交换成为可能(AFA)。该模块极大地提高了学习到的点特征的表示能力。
- 提出了以AFA为核心模块的PointWeb框架。该算法在各种竞争性点云数据集上都取得了最佳性能,证明了该算法的有效性和通用性。
二、相关工作
3D数据表示
真实的扫描数据是一个三维点坐标的集合。为了使数据进行卷积,一种直接的方法是在三维网格结构中对其进行体素化[16,23]。然而,这种表示显然是低效的,因为大多数体素通常是空的。后来,OctNet[21]探索了体素数据的稀疏性并缓解了这个问题。然而,当涉及到更深层次的神经网络时,内存占用率仍然很高。此外,由于体素是空间的离散表示,这种方法仍然需要高分辨率网格和大量内存消耗作为交换,以保持一定的表示质量水平。
另一种常见的3D表示是多视图[19,24,25],其中点数据被投影到三维空间中各个特定的图像平面上,形成二维图像。通过这种方法,可以对二维图像上的点数据进行常规的卷积处理。但是这种方法忽略了三维点的内在几何关系,图像平面的选择会严重影响结果。由于投影造成3D数据中的遮挡部分不能被处理。
点云深度学习
PointNet [18]首先讨论了点集的不规则格式和置换不变性,提出了一种直接处理点云的网络。PointNet ++[20]对PointNet进行了扩展,不仅考虑了全局信息,还考虑了局部细节,采用了最远处采样层和分组层。尽管在PointNet++利用了局部上下文,但是仅仅使用max pooling可能不能很好地聚合局部区域的信息。因此,DGCNN[32]通过将每个中心点与其k个最近邻相连,来聚合局部上下文信息。成对的特征然后被一个MLP独立编码。局部区域上的聚合操作仍然是一个简单的max pooling。
最近的方法通过将卷积算子扩展到规则网格结构来处理无序点来改进上下文集成。PCNN[31]有参数化的连续卷积运算,它定义了连续支持域上的核函数。PointCNN[13]通过使用X-Conv算子对输入点和特征进行置换和加权来探索点的标准顺序,然后对重组后的点进行常规卷积处理。另外,Superpoint Graph (SPG)[12]侧重于处理大点云。这些点被自适应地分割成几何齐次的元素,建立一个超点图,然后送入图神经网络生成语义标签。
我们的工作也集中在局部特征的聚集上。与以往在点云中适应卷积的方法不同,我们将注意力放在每个局部邻域内点之间的相互作用上。通过挖掘所有点对之间的上下文信息,我们的网络模块细化了特征,使它们更能描述局部邻域。
三、我们的方法
探讨局部区域内各点之间的关系是本文的重点。特别是利用神经网络提取点对特征后,进一步聚合这些局部特征有助于提高语义分割和分类任务的点云识别质量。
对于一个三维点云,PointNet++[20]使用最远点采样选取点作为质心,然后应用kNN找到每个质心周围的邻近点,很好地定义了点云中的局部区域。对于m个点的局部区域(或局部邻域)R,用F表示R中的点的特征集合,令F ={ F1, F2,…,Fm},其中Fi∈R^C。C表示每个点特征中的通道数。
在这里,最终的目标是获得一个代表性的区域R的特征Fout ∈R^Cout,其中Cout为输出特征中的通道数。pointnet++使用MLP和最大池获得代表性特征。然而,该过程不涉及局部邻域点之间的区域信息交换。

在我们的方法中,我们将R中的点密集地连接成一个点的局部网络,并制定一个自适应特征调整(AFA)模块,学习每个点对其他点的影响,调整其特征。通过这种方法,我们将邻域上下文纳入点特征中,提高了特征描述局部邻域的能力。图2给出了AFA模块的概述。我们称我们的整个网络为PointWeb,因为我们的方法通过密集连接的点的网络有效地提取局部邻域上下文。
3.1 自适应特征调整(AFA)模块
给定区域R及其特征集F ={ F1, F2,…,Fm},我们首先制定了自适应特征调整(AFA)模块,通过学习局部邻域的上下文信息来增强F中的点特征:
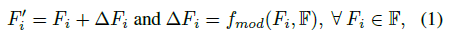
Fi’是增强的Fi, △Fi是通过特征调制器fmod从F中学习得到的。
下一个挑战是制定特征调制器来有效地交换和进一步聚集F中信息。直观上,局部区域的不同特征对每个Fi的提升产生不同的影响。我们的特征调制器通过自适应地学习F中每个特征对每个Fi的影响量来解决这个问题。它被表示为
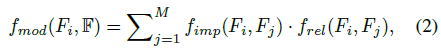
其中fimp是用于计算Fj对Fi的影响量的函数,而frel表示Fj和Fi如何有关。值得注意的是,我们在调制器中也包括了Fi的自影响。
3.1.1 影响函数fimp
多层感知(MLP)网络在[18,20]中提出,它近似于点集上的一般函数。我们使用MLP来计算影响函数fimp,如图3所示。它被表述为
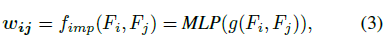
式中,g为特征Fi和Fj的组合函数,wij为Fj对Fi的影响指标。

模型g的一个简单方法是将这两个特性连接起来。这种解决方案有一个明显的局限性,即g完全包含了Fi和Fj,即使Fj变化,也有一半的特征通道保持不变。这使得Fi在计算影响时占主导地位。另一种选择是取特征相加(Fi + Fj)为g。我们注意到这个策略也是有问题的,因为Fj对Fi和Fi对Fj一样。这种类型的对称影响产生一个不期望的特性,这将在以后的实验中证明。
考虑到这些因素,我们因此建立了g(Fi,Fj) =Fi-Fj,计算两个特征向量之间的差异。稍后我们将在表3中显示从使用三种不同形式g的实验中得到的统计数据。注意,这里i = j是一种特殊情况,我们设g(Fi,Fi)作为Fi。因此,利用自身的特征Fi来估计Fi对自身的影响。
3.1.2 关系函数frel
另一方面,关系函数frel旨在确定影响指标wij对Fi的作用。一种简单的方法是直接将wij与Fj相乘
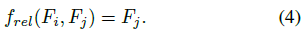
则式(2)中的总fmod为
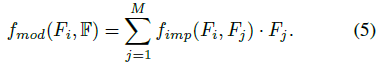
虽然使用这种朴素关系函数的点云识别任务的结果质量已经比基线有所提高,但是使用不同的frel向量形式可以进一步提高我们的框架的性能。在数学上,我们将关系函数建模为
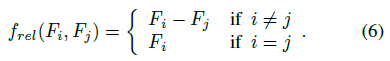
请参阅第4节的消融研究,比较使用不同形式的关系函数的性能。
现在,对于局部区域R中的每个特征Fi,特征调整的总输出为
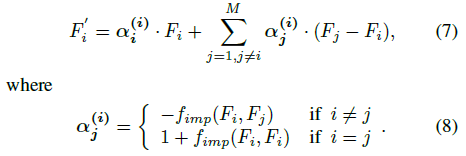
换句话说,这个公式就像局部区域R中的一个力场(图2 (c)),其中R中的所有其他特征都对Fi施加了一个力(在特征空间中),试图将Fi推向或远离它自己。力的强度和方向由系数α(i)j确定,该系数根据两个特征向量的差异自适应学习。因此,输出F’ i融入了整个区域的上下文信息,从而更好的描述了区域的特征。
3.1.3 逐元素影响图
除fimp和frel两个关键函数外,影响因素wij = fimp(Fi,Fj) (j = 1,…,M)以逐元素的方式操作特征差异图。每个因子的长度等于特征中通道的数量。考虑到两个点特征之间的相互作用在整个通道中可能不同,我们不需要计算逐点影响因子,而是对局部区域的每个特征得到覆盖整个区域和所有通道的的元素影响图。Fi的影响图公式为

将通道的数量表示为C,将影响图的大小表示为C X M。然后特征调制器以矩阵形式表示为

⊙表示逐元素相乘,e是一个全一矩阵,Fidiff是尺寸为C X M的特征差异图。特别地,

3.2带有局部特征调制的PointWeb
我们的框架是建立在pointnet++体系结构上的,这是一个由多个子集抽象级别组成的层次网络。在抽象模块的每个局部区域内,结合全局特征和局部特征进行点集识别。然而,在pointnet++中,在每个局部区域聚合信息的唯一操作是最大池化,而我们的PointWeb框架在每个局部区域的点特征之间构建一个完全链接的点网络,然后通过学习确定它们之间的相互影响来整合该区域的信息。语义分割的PointWeb总体框架如图4所示。提高性能的主要因素是自适应特征调整(AFA)模块,即图中突出显示的框。
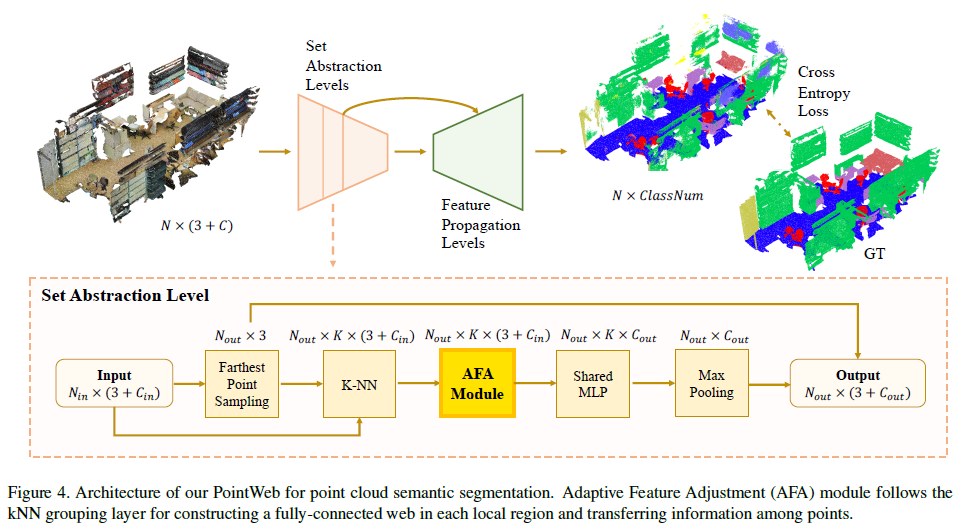
每个分组层后面是3.1节介绍的AFA模块。局部区域AFA模块示意图如图2所示。具体来说,将同一局部区域的每两个特征链接成一个网络(图2 (b))。然后,考虑特征之间的相互作用,对特征进行更新(图2)(c))。该框架根据区域特征将相同的特征分组到不同的局部区域中。
不改变特征的数量和大小,我们的AFA模块可以看作是一个特征转换模块,通过每个局部区域的空间和通道用于交换和聚合上下文信息。然后将调整后的特征赋给MLP和最大池化,以便在不同的通道进行进一步的信息集成。
四、实验评估
我们提出的PointWeb框架对于理解点云场景是有效的。为了验证该算法的有效性,我们在点云语义分割和分类任务上进行了实验。两个大型三维点云分割数据集,包括斯坦福采用大尺度3D室内空间(S3DIS)[1]和ScanNet[5]。另一种形状分类数据集ModelNet[33]用于分类评价。
4.1 应用细节
我们在PyTorch[17]平台上进行了实验。在培训过程中,我们使用了基础学习率为0.05的SGD求解器,mini-batch为16。动量衰减和权重衰减分别设置为0.9和0.0001。对于S3DIS数据集,我们训练100个epoch,并且每25个epoch将学习速率降低0.1。在ScanNet和ModelNet40数据集上,我们训练200个epoch和为每50个epoch,学习率衰减0.1。
4.2 S3DIS语义分割
数据和度量
S3DIS[1]数据集包含6个区域的3D扫描,包括271个房间。扫描中的每个点都用13个类别(椅子、桌子、天花板、地板、杂物等)语义标签的一个进行标注。为了准备训练数据,我们遵循[20],其中点被均匀采样到面积为1m*1m的块中。每个点都用一个9D向量(XY Z、RGB和房间里的标准化位置)表示。
在训练过程中,我们从每个块随机抽取4,096个点。在测试过程中,我们采用了所有的点进行评估。按照[20,28,12,13],我们报告了两种设置的结果,即面积测试5(房间不在其他折页中)和6折页交叉验证(合并不同折页的结果来计算指标)。对于评价指标,我们使用了类间交并集的均值(mIoU)、类间精度的均值(mAcc)和整体点间精度(OA)。
性能比较
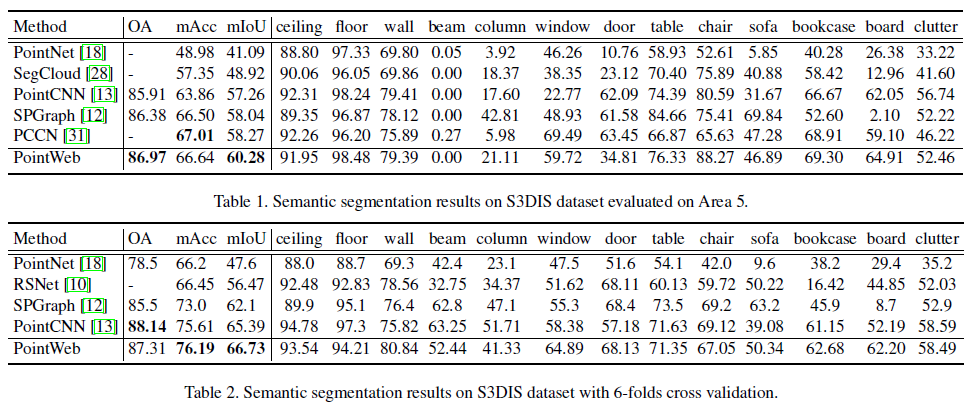
表1和表2给出了上述两种设置下不同方法的定量结果。在这个高度竞争性的数据集中,我们的PointWeb在5区域评估的mIoU和OA方面取得了最高的性能,并在6倍设置中产生了最高的mIoU和mAcc。PointWeb的mIoU在5区达到60.28%,比目前最先进的PCCN高出2.01%。同时,PointWeb在6次交叉评价中的mIoU达到66.73%,比之前最好的方法高出1.34。

如图5所示。PointWeb很好地捕获了点云中的某些详细结构。如图所示,可以正确地分辨出不显眼的物体部位,如椅子腿、桌子腿等。最后一行显示了两个失败案例。在左边的例子中,墙上的一些杂物被错误地归类为木板。而在第二种情况下,我们的算法能够识别出墙上杂乱的部分,但在ground truth中不能识别。左边的一些杂物和书架混在一起了。
消融研究
为了更好的理解我们设计逻辑的影响,我们采用Area 5对S3DIS数据集进行了消融实验。我们首先考察fimp中的组合函数g在每个局部组内的四种不同的类型,即每对点之间不组合,通过特征求和、特征减法和特征连接进行组合。定量结果如表3所示。我们选择局部特征上的减法操作进行调整,比其他方法更具鉴别性和代表性。
在不与其他特征交互的情况下,对单独特征进行学习调整,无法获得局部区域上下文。成对特征的求和运算会降低特征在局部区域的识别能力。这就损害了识别能力。成对特征的连接使得部分特征表示几乎相同,这不如我们选择的减法好。通过减法运算,每个特征对Fi和Fj的组合是唯一的,从而提高了分类能力。
并与为图问题设计的[29]图注意网络进行了比较(GANN)。GANN通过串联建立连接。注意系数采用Softmax运算,AFA运算则不采用。因此,AFA的影响可以是积极的,也可以是消极的,起到推或拉的作用。此外,正如Eq.(9)所示,我们的影响指标随着通道的变化而变化,这比GANN中跨通道共享权重的尺度系数具有更高的灵活性。比较如表4所示,我们的PointWeb得分最高。
最后,对于减法操作,我们研究了直接在特征本身操作的自适应学习影响指标,而不是在特征差图上操作。对特征的直接影响因素(frel(Fi,Fj) = Fj),测试结果为59.79%/66.63%/86.51% (mIoU/mAcc/OA)。它不如对差异图操作的影响特征 (frel(Fi,Fj) = Fi-Fj), 对差异图操作的影响特征的最高性能为60.28 / 66.64/86.97(%)。
特征可视化
以充分了解提出的AFA模块,我们产生了有和无调整模块的T-SNE[15]可视化的输入和输出特征。使用了13个类别的S3DIS上的特征。对于每个类别,我们从整个区域中随机抽取100个点,绘制特征分布如图7所示。从左到右分别是没有AFA的基线网络产生的输入特征和输出特征,以及带有AFA模块的PointWeb架构产生的输出特征,AFA模块能够加强局部区域内的信息交换和连接配对点。

与只用MLPs独立处理局部区域特征的基线网络相比,我们的密集连接特征自适应可以促进网络学习,生成更紧凑、更有代表性、更有特色的特征表示,从而更容易、准确地识别不同类别的点。定性可视化结果表明,AFA模块明显提高了点特征的识别能力。
4.3 ScanNet语义体素标记
ScanNet[5]数据集包含1513个扫描重建的室内场景,分为1201 /312个进行训练和测试。对于语义体素标记任务,使用了20个类别进行评价,1个类别用于自由空间。我们遵循之前的数据处理流程[5,20],从场景中均匀采样点,将点划分为块,每个块的大小为1.5m*1.5m。在训练期间,选取了8,192个点样本,其中不少于2%的体素被占据,至少70%的表面体素具有有效注释。点是实时采样的。测试集中的所有点都进行评估,测试时采用较小的采样步长,每对相邻块之间采样步长为0.5。在评价中,采用整体语义体素标记精度。为了与前面的方法进行比较,我们在训练和测试时不使用RGB颜色信息。
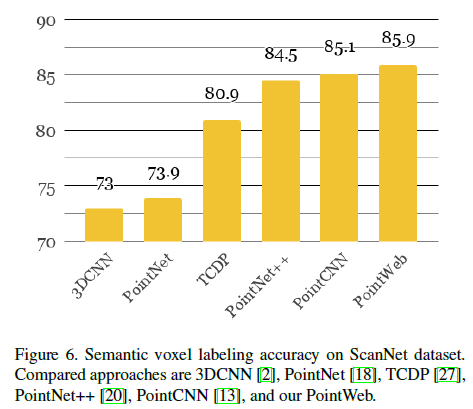
图6为语义体素标记结果。我们的方法到达这个数据集中的第一个位置。可视化结果如图8所示,其中PointWeb很好地分类了不同房间中周围的物体和东西。

4.4 ModelNet40 分类
ModelNet40[33]数据集包含来自40个对象类别的12311个CAD模型。它们是分开的用于训练的有9843个,用于测试的有2468个。遵循[20],我们统一地从每个点采样CAD模型与从对象网格计算法向量。在分类框架中,我们将特征传播层替换为全局最大池和完全连接(FC)层。对每个形状模型中的点进行随机打乱,以扩充训练集。在最后两个FC层中加入了下降率为0.5的两个dropout层,以减少过拟合。
表5显示了不同方法对每个类别的总体准确率和平均准确率的评价结果。我们的方法是这个数据集中排名最高的解决方案之一。为提高基于点策略的点云理解的适用性提供了一种有效的方法。
五、结束语
我们提出了自适应特征调整(AFA)模块和PointWeb架构用于三维点云处理和识别。它在局部区域内设置密集的点对连接,从而使每个点都能从所有其他点收集特征。与不知道局部上下文和与其他组件的信息交换的传统方法相比,我们的框架能够更好地学习用于点云处理的特征表示。广泛的实验与我们的最新结果在三个竞争数据集证明了我们的方法的有效性和一般性。我们相信所提出的模块在原则上可以推进社区中对3D场景理解的研究。
论文笔记:(CVPR2019)PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing的更多相关文章
- 论文笔记(3)-Extracting and Composing Robust Features with Denoising Autoencoders
这篇文章是Bengio研究的在传统的autoencoder基础上增加了噪声参数,也就是说在输入X的时候,并不直接用X的数据,而是按照一定的概率来清空输入为0.paper中的名词为corrupted.这 ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
- 基于3D卷积神经网络的人体行为理解(论文笔记)(转)
基于3D卷积神经网络的人体行为理解(论文笔记) zouxy09@qq.com http://blog.csdn.net/zouxy09 最近看Deep Learning的论文,看到这篇论文:3D Co ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
随机推荐
- 测试MySQL锁的问题
测试MySQL锁的问题 目录 测试MySQL锁的问题 1 Record Lock 2 Next-Key Lock 2 死锁测试 InnoDB支持三种行锁: Record Lock:单个行记录上面的锁 ...
- 20204107 孙嘉临《PYTHON程序设计》计算器设计实验二报告
课程:<python程序设计> 班级:2041 姓名:孙嘉临 学号:20204107 实验教师:王志强 实验日期:2021年4月12日 必修/选修:公选课 ##一.实验内容 设计并完成一个 ...
- hdu1233 最小生成树Prim算法和Kruskal算法
Prim算法 时间复杂度:O(\(N^2\),N为结点数) 说明:先任意找一个点标记,然后每次找一条最短的两端分别为标记和未标记的边加进来,再把未标记的点标记上.即每次加入一条合法的最短的边,每次扩展 ...
- Apache Hudi在Hopworks机器学习的应用
Hopsworks特征存储库统一了在线和批处理应用程序的特征访问而屏蔽了双数据库系统的复杂性.我们构建了一个可靠且高性能的服务,以将特征物化到在线特征存储库,不仅仅保证低延迟访问,而且还保证在服务时间 ...
- Unity的AnimationCurve
转自:风宇冲Unity3D教程学院http://blog.sina.com.cn/s/blog_471132920101f8nv.html,本文有多处增删减改,详细内容请查看原文. 1.介绍 Anim ...
- Linux搭建私有yum源
一.前期准备 环境:CentOS 8.3 镜像: CentOS-7-x86_64-Everything-2009.iso CentOS-8.3.2011-x86_64-dvd1.iso 二.搭建步骤 ...
- 资源:docker-compose下载路径
docker-compose下载路径: compose所有版本:https://github.com/docker/compose/releases
- Elasticsearch-04-master选举
3.2 master选举机制 3.2.1 选举算法 1)bully算法 核心思想 假定所有的节点都具有一个可以比较的ID,通过比较这个ID来选举master 流程说明 节点向所有比自己ID大的节点发送 ...
- 『动善时』JMeter基础 — 55、JMeter非GUI模式运行
目录 1.JMeter的非GUI模式说明 2.为什么使用非GUI模式运行JMeter 3.怎样使用非GUI模式运行JMeter (1)非GUI模式运行JMeter步骤 (2)其它参数说明 4.CLI模 ...
- c++中的继承关系
1 什么是继承 面向对象的继承关系指类之间的父子关系.用类图表示如下: 2 为什么要有继承?/ 继承的意义? 因为继承是面向对象中代码复用的一种手段.通过继承,可以获取父类的所有功能,也可以在子类中重 ...