Kubernetes实战之部署ELK Stack收集平台日志
主要内容
1 ELK概念
2 K8S需要收集哪些日志
3 ELK Stack日志方案
4 容器中的日志怎么收集
5 K8S平台中应用日志收集
准备环境
一套正常运行的k8s集群,kubeadm安装部署或者二进制部署即可
| ip地址 | 角色 | 备注 |
|---|---|---|
| 192.168.73.136 | nfs | |
| 192.168.73.138 | k8s-master | |
| 192.168.73.139 | k8s-node01 | |
| 192.168.73.140 | k8s-node02 |
1 ELK 概念
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
通过上面对ELK简单的介绍,我们知道了ELK字面意义包含的每个开源框架的功能。市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。我们本教程主要也是围绕通过ELK如何搭建一个生产级的日志分析平台来讲解ELK的使用。
官方网站:https://www.elastic.co/cn/products/
2 日志管理平台
在过往的单体应用时代,我们所有组件都部署到一台服务器中,那时日志管理平台的需求可能并没有那么强烈,我们只需要登录到一台服务器通过shell命令就可以很方便的查看系统日志,并快速定位问题。随着互联网的发展,互联网已经全面渗入到生活的各个领域,使用互联网的用户量也越来越多,单体应用已不能够支持庞大的用户的并发量,尤其像中国这种人口大国。那么将单体应用进行拆分,通过水平扩展来支持庞大用户的使用迫在眉睫,微服务概念就是在类似这样的阶段诞生,在微服务盛行的互联网技术时代,单个应用被拆分为多个应用,每个应用集群部署进行负载均衡,那么如果某项业务发生系统错误,开发或运维人员还是以过往单体应用方式登录一台一台登录服务器查看日志来定位问题,这种解决线上问题的效率可想而知。日志管理平台的建设就显得极其重要。通过Logstash去收集每台服务器日志文件,然后按定义的正则模板过滤后传输到Kafka或redis,然后由另一个Logstash从KafKa或redis读取日志存储到elasticsearch中创建索引,最后通过Kibana展示给开发者或运维人员进行分析。这样大大提升了运维线上问题的效率。除此之外,还可以将收集的日志进行大数据分析,得到更有价值的数据给到高层进行决策。
3 K8S需要收集哪些日志
这里只是以主要收集日志为例:
- K8S系统的组件日志
- K8S Cluster里面部署的应用程序日志
-标准输出
-日志文件
4 K8S中的ELK Stack日志采集方案
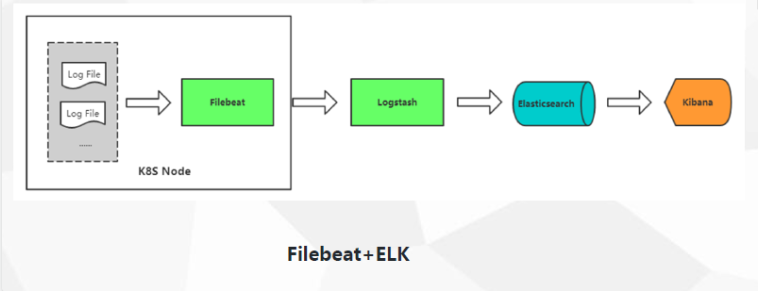
方案一:Node上部署一个日志收集程序
使用DaemonSet的方式去给每一个node上部署日志收集程序logging-agent
然后使用这个agent对本node节点上的/var/log和/var/lib/docker/containers/两个目录下的日志进行采集
或者把Pod中容器日志目录挂载到宿主机统一目录上,这样进行收集
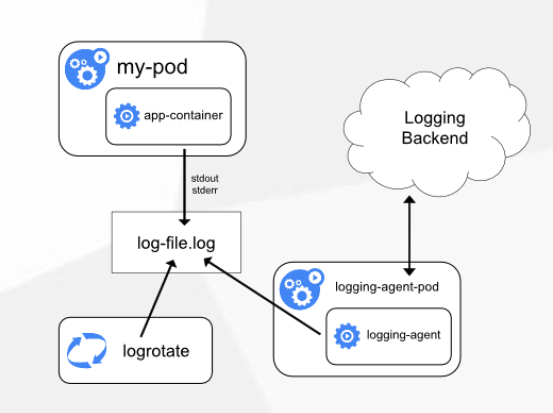
方案二:Pod中附加专用日志收集的容器
每个运行应用程序的Pod中增加一个日志收集容器,使用emtyDir共享日志目录让日志收集程序读取到。
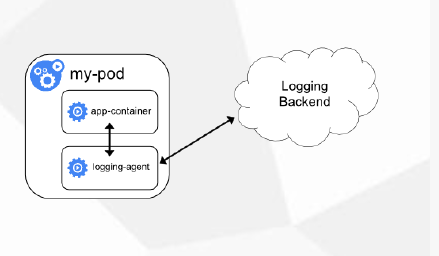
方案三:应用程序直接推送日志
这个方案需要开发在代码中修改直接把应用程序直接推送到远程的存储上,不再输入出控制台或者本地文件了,使用不太多,超出Kubernetes范围
| 方式 | 优点 | 缺点 |
|---|---|---|
| 方案一:Node上部署一个日志收集程序 | 每个Node仅需部署一个日志收集程序,资源消耗少,对应用无侵入 | 应用程序日志需要写到标准输出和标准错误输出,不支持多行日志 |
| 方案二:Pod中附加专用日志收集的容器 | 低耦合 | 每个Pod启动一个日志收集代理,增加资源消耗,并增加运维维护成本 |
| 方案三:应用程序直接推送日志 | 无需额外收集工具 | 浸入应用,增加应用复杂度 |
5 单节点方式部署ELK
单节点部署ELK的方法较简单,可以参考下面的yaml编排文件,整体就是创建一个es,然后创建kibana的可视化展示,创建一个es的service服务,然后通过ingress的方式对外暴露域名访问
首先,编写es的yaml,这里部署的是单机版,在k8s集群内中,通常当日志量每天超过20G以上的话,还是建议部署在k8s集群外部,支持分布式集群的架构,这里使用的是有状态部署的方式,并且使用动态存储进行持久化,需要提前创建好存储类,才能运行该yaml
[root@k8s-master fek]# vim elasticsearch.yamlapiVersion: apps/v1kind: StatefulSetmetadata:name: elasticsearchnamespace: kube-systemlabels:k8s-app: elasticsearchspec:serviceName: elasticsearchselector:matchLabels:k8s-app: elasticsearchtemplate:metadata:labels:k8s-app: elasticsearchspec:containers:- image: elasticsearch:7.3.1name: elasticsearchresources:limits:cpu: 1memory: 2Girequests:cpu: 0.5memory: 500Mienv:- name: "discovery.type"value: "single-node"- name: ES_JAVA_OPTSvalue: "-Xms512m -Xmx2g"ports:- containerPort: 9200name: dbprotocol: TCPvolumeMounts:- name: elasticsearch-datamountPath: /usr/share/elasticsearch/datavolumeClaimTemplates:- metadata:name: elasticsearch-dataspec:storageClassName: "managed-nfs-storage"accessModes: [ "ReadWriteOnce" ]resources:requests:storage: 20Gi---apiVersion: v1kind: Servicemetadata:name: elasticsearchnamespace: kube-systemspec:clusterIP: Noneports:- port: 9200protocol: TCPtargetPort: dbselector:k8s-app: elasticsearch
使用刚才编写好的yaml文件创建Elasticsearch,然后检查是否启动,如下所示能看到一个elasticsearch-0 的pod副本被创建,正常运行;如果不能正常启动可以使用kubectl describe查看详细描述,排查问题
[root@k8s-master fek]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-5bd5f9dbd9-95flw 1/1 Running 0 17helasticsearch-0 1/1 Running 1 16mphp-demo-85849d58df-4bvld 2/2 Running 2 18hphp-demo-85849d58df-7tbb2 2/2 Running 0 17h
然后,需要部署一个Kibana来对搜集到的日志进行可视化展示,使用Deployment的方式编写一个yaml,使用ingress对外进行暴露访问,直接引用了es
[root@k8s-master fek]# vim kibana.yamlapiVersion: apps/v1kind: Deploymentmetadata:name: kibananamespace: kube-systemlabels:k8s-app: kibanaspec:replicas: 1selector:matchLabels:k8s-app: kibanatemplate:metadata:labels:k8s-app: kibanaspec:containers:- name: kibanaimage: kibana:7.3.1resources:limits:cpu: 1memory: 500Mirequests:cpu: 0.5memory: 200Mienv:- name: ELASTICSEARCH_HOSTSvalue: http://elasticsearch:9200ports:- containerPort: 5601name: uiprotocol: TCP---apiVersion: v1kind: Servicemetadata:name: kibananamespace: kube-systemspec:ports:- port: 5601protocol: TCPtargetPort: uiselector:k8s-app: kibana---apiVersion: extensions/v1beta1kind: Ingressmetadata:name: kibananamespace: kube-systemspec:rules:- host: kibana.ctnrs.comhttp:paths:- path: /backend:serviceName: kibanaservicePort: 5601
使用刚才编写好的yaml创建kibana,可以看到最后生成了一个kibana-b7d98644-lshsz的pod,并且正常运行
[root@k8s-master fek]# kubectl apply -f kibana.yamldeployment.apps/kibana createdservice/kibana createdingress.extensions/kibana created[root@k8s-master fek]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-5bd5f9dbd9-95flw 1/1 Running 0 17helasticsearch-0 1/1 Running 1 16mkibana-b7d98644-48gtm 1/1 Running 1 17hphp-demo-85849d58df-4bvld 2/2 Running 2 18hphp-demo-85849d58df-7tbb2 2/2 Running 0 17h
最后,需要编写yaml在每个node上创建一个ingress-nginx控制器来对外提供访问
[root@k8s-master demo2]# vim mandatory.yamlapiVersion: v1kind: Namespacemetadata:name: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---kind: ConfigMapapiVersion: v1metadata:name: nginx-configurationnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---kind: ConfigMapapiVersion: v1metadata:name: tcp-servicesnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---kind: ConfigMapapiVersion: v1metadata:name: udp-servicesnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---apiVersion: v1kind: ServiceAccountmetadata:name: nginx-ingress-serviceaccountnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginx---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRolemetadata:name: nginx-ingress-clusterrolelabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxrules:- apiGroups:- ""resources:- configmaps- endpoints- nodes- pods- secretsverbs:- list- watch- apiGroups:- ""resources:- nodesverbs:- get- apiGroups:- ""resources:- servicesverbs:- get- list- watch- apiGroups:- ""resources:- eventsverbs:- create- patch- apiGroups:- "extensions"- "networking.k8s.io"resources:- ingressesverbs:- get- list- watch- apiGroups:- "extensions"- "networking.k8s.io"resources:- ingresses/statusverbs:- update---apiVersion: rbac.authorization.k8s.io/v1beta1kind: Rolemetadata:name: nginx-ingress-rolenamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxrules:- apiGroups:- ""resources:- configmaps- pods- secrets- namespacesverbs:- get- apiGroups:- ""resources:- configmapsresourceNames:# Defaults to "<election-id>-<ingress-class>"# Here: "<ingress-controller-leader>-<nginx>"# This has to be adapted if you change either parameter# when launching the nginx-ingress-controller.- "ingress-controller-leader-nginx"verbs:- get- update- apiGroups:- ""resources:- configmapsverbs:- create- apiGroups:- ""resources:- endpointsverbs:- get---apiVersion: rbac.authorization.k8s.io/v1beta1kind: RoleBindingmetadata:name: nginx-ingress-role-nisa-bindingnamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: nginx-ingress-rolesubjects:- kind: ServiceAccountname: nginx-ingress-serviceaccountnamespace: ingress-nginx---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRoleBindingmetadata:name: nginx-ingress-clusterrole-nisa-bindinglabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: nginx-ingress-clusterrolesubjects:- kind: ServiceAccountname: nginx-ingress-serviceaccountnamespace: ingress-nginx---apiVersion: apps/v1kind: DaemonSetmetadata:name: nginx-ingress-controllernamespace: ingress-nginxlabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxspec:selector:matchLabels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxtemplate:metadata:labels:app.kubernetes.io/name: ingress-nginxapp.kubernetes.io/part-of: ingress-nginxannotations:prometheus.io/port: "10254"prometheus.io/scrape: "true"spec:serviceAccountName: nginx-ingress-serviceaccounthostNetwork: truecontainers:- name: nginx-ingress-controllerimage: lizhenliang/nginx-ingress-controller:0.20.0args:- /nginx-ingress-controller- --configmap=$(POD_NAMESPACE)/nginx-configuration- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services- --udp-services-configmap=$(POD_NAMESPACE)/udp-services- --publish-service=$(POD_NAMESPACE)/ingress-nginx- --annotations-prefix=nginx.ingress.kubernetes.iosecurityContext:allowPrivilegeEscalation: truecapabilities:drop:- ALLadd:- NET_BIND_SERVICE# www-data -> 33runAsUser: 33env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespaceports:- name: httpcontainerPort: 80- name: httpscontainerPort: 443livenessProbe:failureThreshold: 3httpGet:path: /healthzport: 10254scheme: HTTPinitialDelaySeconds: 10periodSeconds: 10successThreshold: 1timeoutSeconds: 10readinessProbe:failureThreshold: 3httpGet:path: /healthzport: 10254scheme: HTTPperiodSeconds: 10successThreshold: 1timeoutSeconds: 10---
创建ingress控制器,可以看到使用的DaemonSet 的方式在每一个node都部署了ingress控制器,我们可以在本地host中绑定任意一个node ip,然后使用域名都可以访问
[root@k8s-master demo2]# kubectl apply -f mandatory.yaml[root@k8s-master demo2]# kubectl get pod -n ingress-nginxNAME READY STATUS RESTARTS AGEnginx-ingress-controller-98769 1/1 Running 6 13hnginx-ingress-controller-n6wpq 1/1 Running 0 13hnginx-ingress-controller-tbfxq 1/1 Running 29 13hnginx-ingress-controller-trxnj 1/1 Running 6 13h
绑定本机hosts,访问域名验证
windows系统,hosts文件地址:C:\Windows\System32\drivers\etc,Mac系统sudo vi /private/etc/hosts 编辑hosts文件,在底部加入域名和ip,用于解析,这个ip地址为任意node节点ip地址
加入如下命令,然后保存
192.168.73.139 kibana.ctnrs.com
最后在浏览器中,输入kibana.ctnrs.com,就会进入kibana的web界面,已设置了不需要进行登陆,当前页面都是全英文模式,可以修改上网搜一下修改配置文件的位置,建议使用英文版本
5.1 方案一:Node上部署一个filebeat采集器采集k8s组件日志
es和kibana部署好了之后,我们如何采集pod日志呢,我们采用方案一的方式,首先在每一个node上中部署一个filebeat的采集器,采用的是7.3.1版本,因为filebeat是对k8s有支持,可以连接api给pod日志打标签,所以yaml中需要进行认证,最后在配置文件中对获取数据采集了之后输入到es中,已在yaml中配置好
[root@k8s-master fek]# vim filebeat-kubernetes.yaml---apiVersion: v1kind: ConfigMapmetadata:name: filebeat-confignamespace: kube-systemlabels:k8s-app: filebeatdata:filebeat.yml: |-filebeat.config:inputs:# Mounted `filebeat-inputs` configmap:path: ${path.config}/inputs.d/*.yml# Reload inputs configs as they change:reload.enabled: falsemodules:path: ${path.config}/modules.d/*.yml# Reload module configs as they change:reload.enabled: false# To enable hints based autodiscover, remove `filebeat.config.inputs` configuration and uncomment this:#filebeat.autodiscover:# providers:# - type: kubernetes# hints.enabled: trueoutput.elasticsearch:hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']---apiVersion: v1kind: ConfigMapmetadata:name: filebeat-inputsnamespace: kube-systemlabels:k8s-app: filebeatdata:kubernetes.yml: |-- type: dockercontainers.ids:- "*"processors:- add_kubernetes_metadata:in_cluster: true---apiVersion: extensions/v1beta1kind: DaemonSetmetadata:name: filebeatnamespace: kube-systemlabels:k8s-app: filebeatspec:template:metadata:labels:k8s-app: filebeatspec:serviceAccountName: filebeatterminationGracePeriodSeconds: 30containers:- name: filebeatimage: elastic/filebeat:7.3.1args: ["-c", "/etc/filebeat.yml","-e",]env:- name: ELASTICSEARCH_HOSTvalue: elasticsearch- name: ELASTICSEARCH_PORTvalue: "9200"securityContext:runAsUser: 0# If using Red Hat OpenShift uncomment this:#privileged: trueresources:limits:memory: 200Mirequests:cpu: 100mmemory: 100MivolumeMounts:- name: configmountPath: /etc/filebeat.ymlreadOnly: truesubPath: filebeat.yml- name: inputsmountPath: /usr/share/filebeat/inputs.dreadOnly: true- name: datamountPath: /usr/share/filebeat/data- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: truevolumes:- name: configconfigMap:defaultMode: 0600name: filebeat-config- name: varlibdockercontainershostPath:path: /var/lib/docker/containers- name: inputsconfigMap:defaultMode: 0600name: filebeat-inputs# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart- name: datahostPath:path: /var/lib/filebeat-datatype: DirectoryOrCreate---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRoleBindingmetadata:name: filebeatsubjects:- kind: ServiceAccountname: filebeatnamespace: kube-systemroleRef:kind: ClusterRolename: filebeatapiGroup: rbac.authorization.k8s.io---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRolemetadata:name: filebeatlabels:k8s-app: filebeatrules:- apiGroups: [""] # "" indicates the core API groupresources:- namespaces- podsverbs:- get- watch- list---apiVersion: v1kind: ServiceAccountmetadata:name: filebeatnamespace: kube-systemlabels:k8s-app: filebeat---
使用编写好的yaml文件创建filebeat采集器,然后检查是否启动,如果不能正常启动可以使用kubectl describe查看详细描述,排查问题
[root@k8s-master fek]# kubectl apply -f filebeat-kubernetes.yamlconfigmap/filebeat-config createdconfigmap/filebeat-inputs createddaemonset.extensions/filebeat createdclusterrolebinding.rbac.authorization.k8s.io/filebeat createdclusterrole.rbac.authorization.k8s.io/filebeat createdserviceaccount/filebeat created[root@k8s-master fek]# lselasticsearch.yaml filebeat-kubernetes.yaml kibana.yaml[root@k8s-master fek]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEalertmanager-5d75d5688f-fmlq6 2/2 Running 11 58dcoredns-5bd5f9dbd9-rv7ft 1/1 Running 2 47dfilebeat-2dlk8 1/1 ContainerCreating 0 27sfilebeat-cqvmk 1/1 ContainerCreating 0 27sfilebeat-s2xmm 1/1 ContainerCreating 0 28sfilebeat-w28qc 1/1 ContainerCreating 0 27sgrafana-0 1/1 Running 5 64dkube-state-metrics-7c76bdbf68-48b7w 2/2 Running 4 47dkubernetes-dashboard-7d77666777-d5ng4 1/1 Running 9 65dprometheus-0 2/2 Running 2 47d
需要对k8s组件的日志进行采集,因为我的环境是用的kubeadm进行部署的,因此我的组件日志都在/var/log/message里面,因此我们还需要部署一个采集k8s组件日志的pod副本,自定义了索引k8s-module-%{+yyyy.MM.dd},编写yaml如下:
[root@k8s-master elk]# vim k8s-logs.yamlapiVersion: v1kind: ConfigMapmetadata:name: k8s-logs-filebeat-confignamespace: kube-systemdata:filebeat.yml: |filebeat.inputs:- type: logpaths:- /var/log/messagesfields:app: k8stype: modulefields_under_root: truesetup.ilm.enabled: falsesetup.template.name: "k8s-module"setup.template.pattern: "k8s-module-*"output.elasticsearch:hosts: ['elasticsearch.kube-system:9200']index: "k8s-module-%{+yyyy.MM.dd}"---apiVersion: apps/v1kind: DaemonSetmetadata:name: k8s-logsnamespace: kube-systemspec:selector:matchLabels:project: k8sapp: filebeattemplate:metadata:labels:project: k8sapp: filebeatspec:containers:- name: filebeatimage: elastic/filebeat:7.3.1args: ["-c", "/etc/filebeat.yml","-e",]resources:requests:cpu: 100mmemory: 100Milimits:cpu: 500mmemory: 500MisecurityContext:runAsUser: 0volumeMounts:- name: filebeat-configmountPath: /etc/filebeat.ymlsubPath: filebeat.yml- name: k8s-logsmountPath: /var/log/messagesvolumes:- name: k8s-logshostPath:path: /var/log/messages- name: filebeat-configconfigMap:name: k8s-logs-filebeat-config
创建编写好的yaml,并且检查是否成功创建,能看到两个命名为k8s-log-xx的pod副本分别创建在两个nodes上
[root@k8s-master elk]# kubectl apply -f k8s-logs.yaml[root@k8s-master elk]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-5bd5f9dbd9-8zdn5 1/1 Running 0 10helasticsearch-0 1/1 Running 1 13hfilebeat-2q5tz 1/1 Running 0 13hfilebeat-k6m27 1/1 Running 2 13hk8s-logs-52xgk 1/1 Running 0 5h45mk8s-logs-jpkqp 1/1 Running 0 5h45mkibana-b7d98644-tllmm 1/1 Running 0 10h
5.1.1 在kibana的web界面进行配置日志可视化
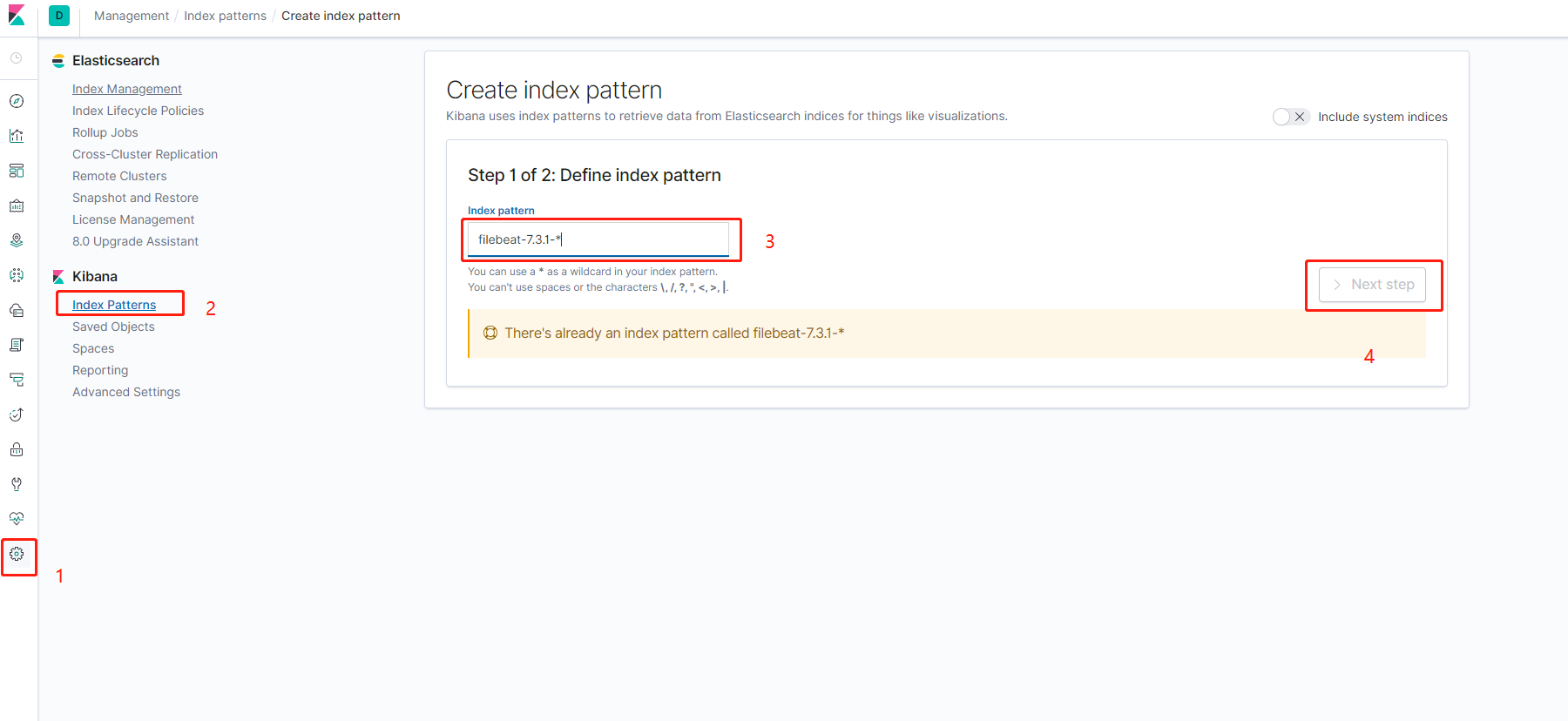
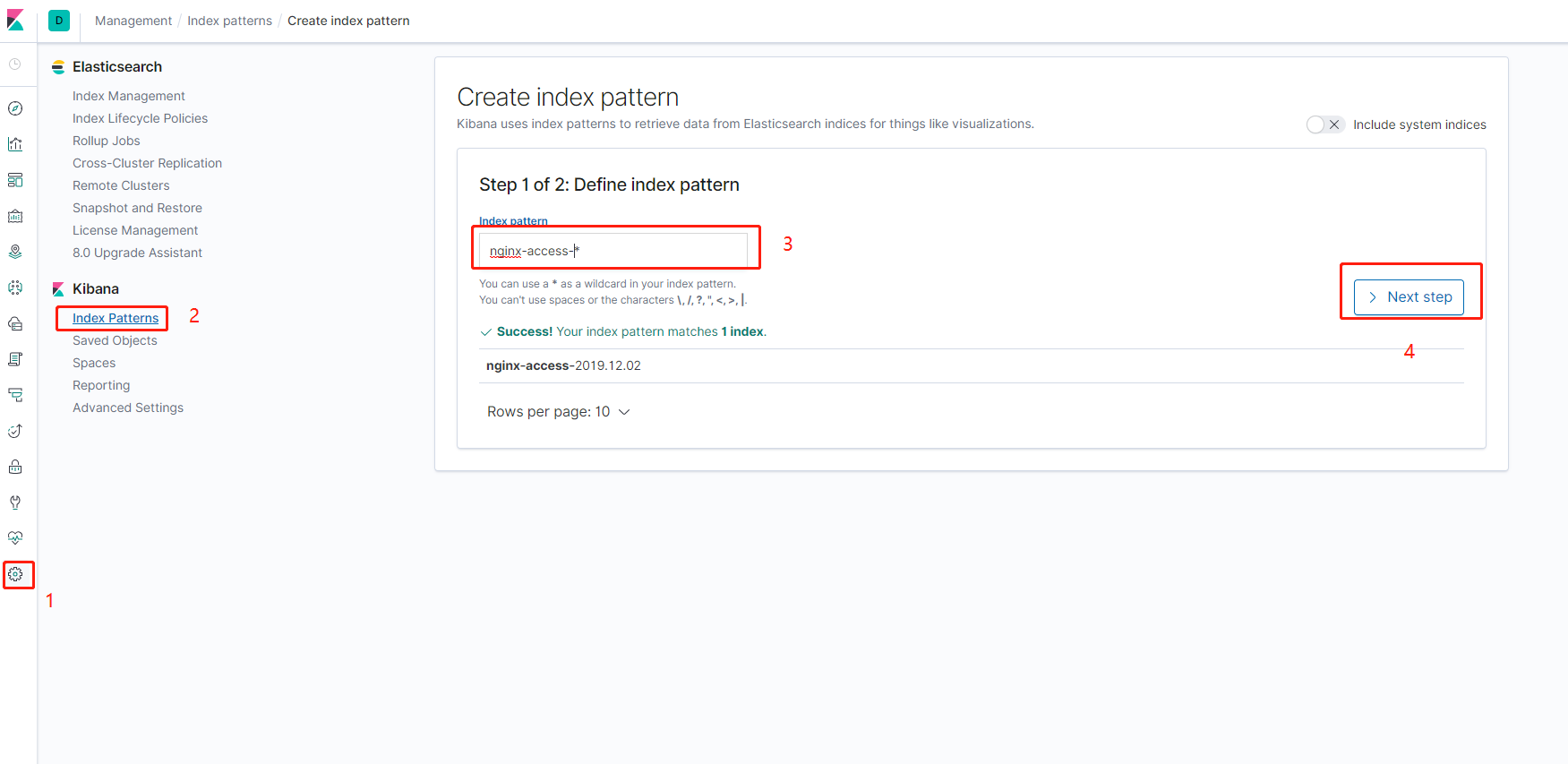
首先打开kibana的web界面,点击左边菜单栏汇中的设置,然后点击在Kibana下面的索引按钮,然后点击左上角的然后根据如图所示分别创建一个filebeat-7.3.1-和k8s-module-的filebeat采集器的索引匹配
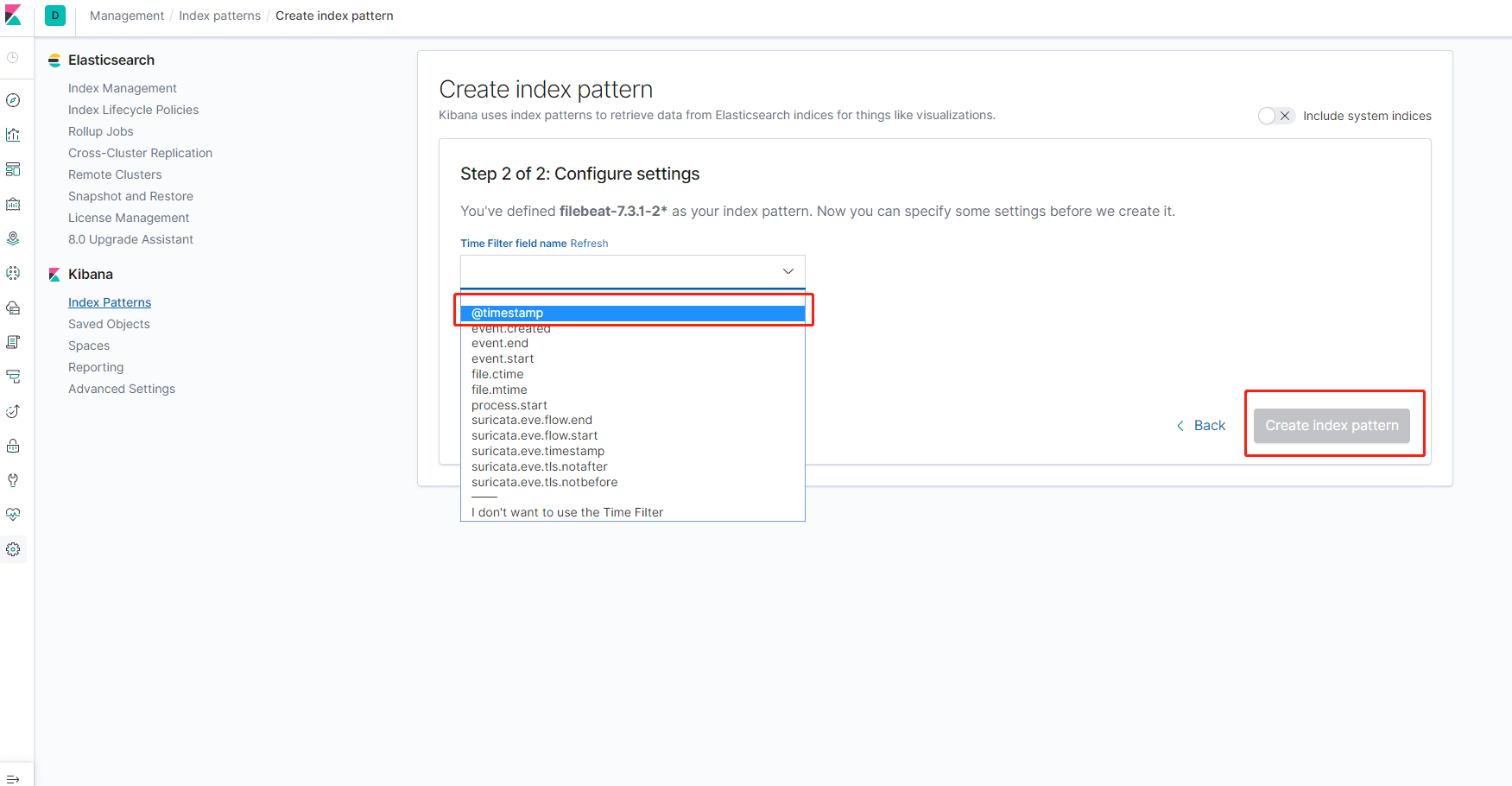
然后按照时间过滤,完成创建
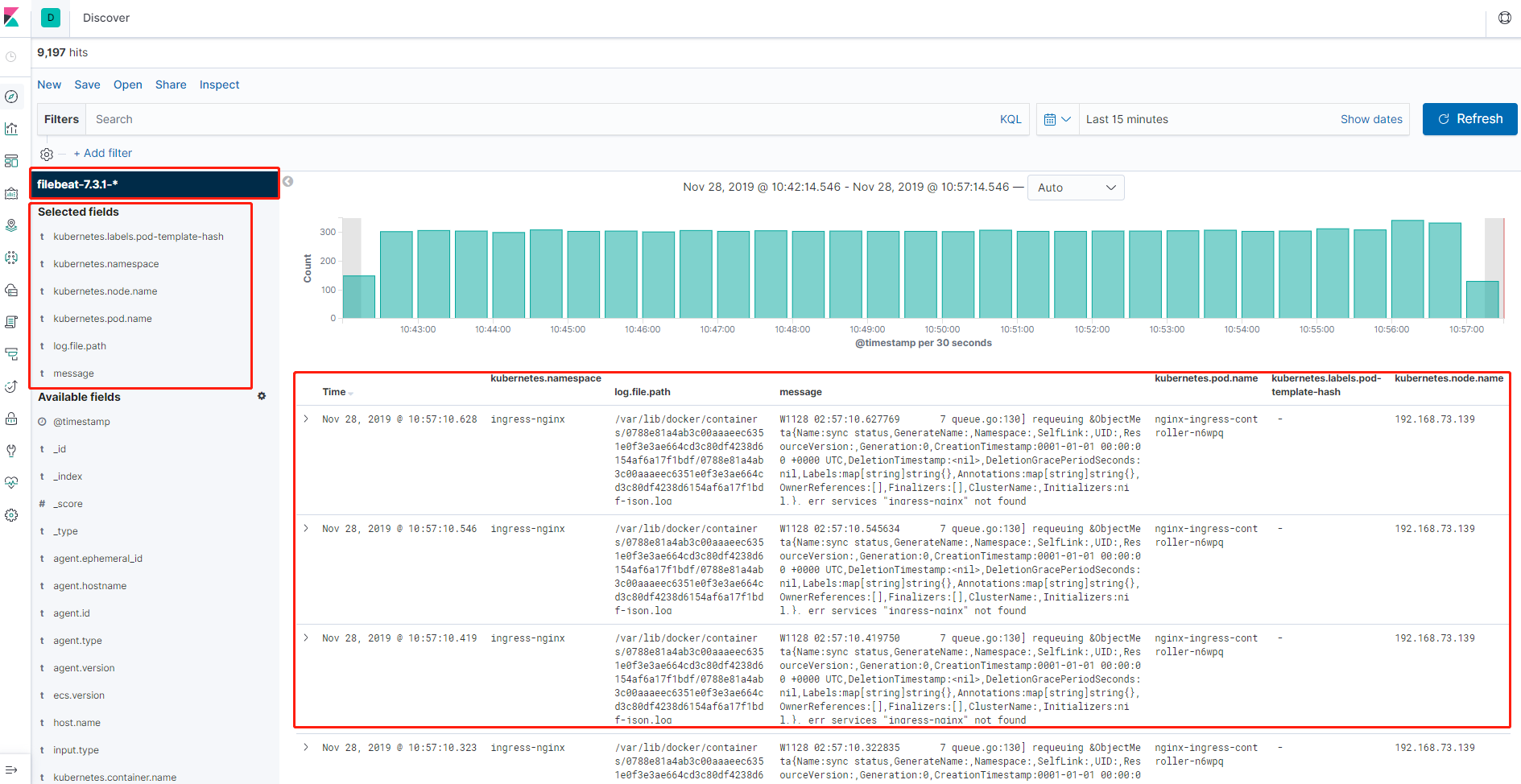
索引匹配创建以后,点击左边最上面的菜单Discove,然后可以在左侧看到我们刚才创建的索引,然后就可以在下面添加要展示的标签,也可以对标签进行筛选,最终效果如图所示,可以看到采集到的日志的所有信息
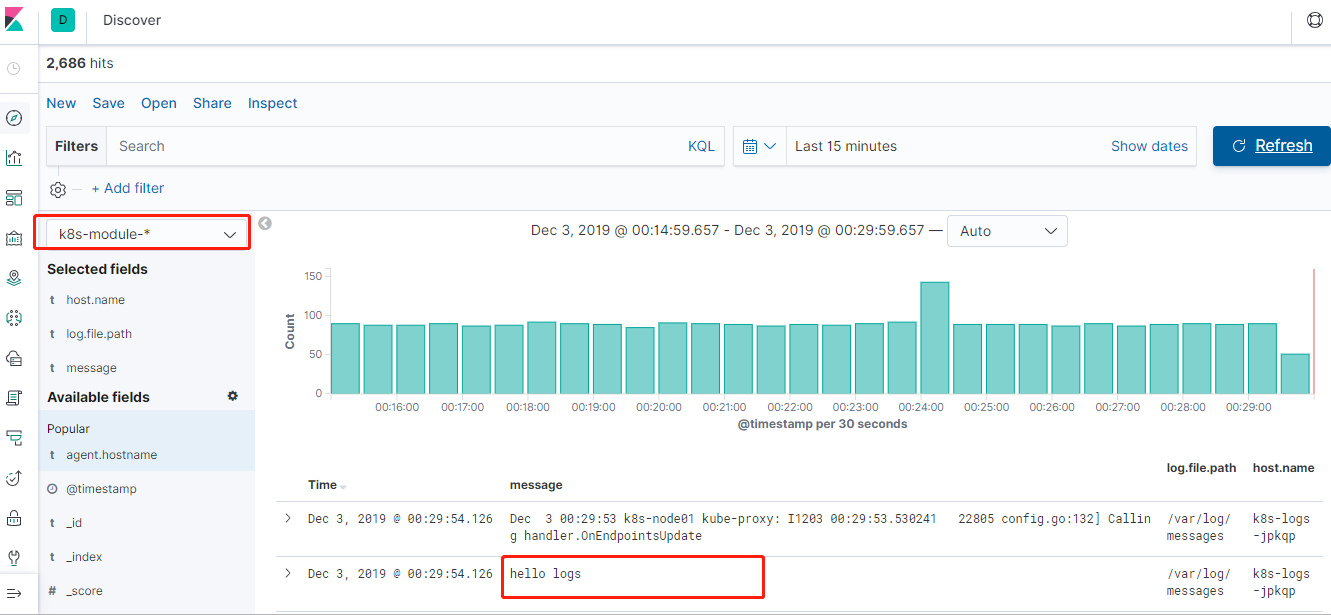
在其中一个node上,输入echo hello logs >>/var/log/messages,然后在web上选择k8s-module-*的索引匹配,就可以在采集到的日志中看到刚才输入的hello logs,则证明采集成功,如图所示
5.2 方案二:Pod中附加专用日志收集的容器
我们也可以使用方案的方式,通过在pod中注入一个日志收集的容器来采集pod的日志,以一个php-demo的应用为例,使用emptyDir的方式把日志目录共享给采集器的容器收集,编写nginx-deployment.yaml ,直接在pod中加入filebeat的容器,并且自定义索引为nginx-access-%{+yyyy.MM.dd}
[root@k8s-master fek]# vim nginx-deployment.yamlapiVersion: apps/v1beta1kind: Deploymentmetadata:name: php-demonamespace: kube-systemspec:replicas: 2selector:matchLabels:project: wwwapp: php-demotemplate:metadata:labels:project: wwwapp: php-demospec:imagePullSecrets:- name: registry-pull-secretcontainers:- name: nginximage: lizhenliang/nginx-phpports:- containerPort: 80name: webprotocol: TCPresources:requests:cpu: 0.5memory: 256Milimits:cpu: 1memory: 1GilivenessProbe:httpGet:path: /status.htmlport: 80initialDelaySeconds: 20timeoutSeconds: 20readinessProbe:httpGet:path: /status.htmlport: 80initialDelaySeconds: 20timeoutSeconds: 20volumeMounts:- name: nginx-logsmountPath: /usr/local/nginx/logs- name: filebeatimage: elastic/filebeat:7.3.1args: ["-c", "/etc/filebeat.yml","-e",]resources:limits:memory: 500Mirequests:cpu: 100mmemory: 100MisecurityContext:runAsUser: 0volumeMounts:- name: filebeat-configmountPath: /etc/filebeat.ymlsubPath: filebeat.yml- name: nginx-logsmountPath: /usr/local/nginx/logsvolumes:- name: nginx-logsemptyDir: {}- name: filebeat-configconfigMap:name: filebeat-nginx-config---apiVersion: v1kind: ConfigMapmetadata:name: filebeat-nginx-confignamespace: kube-systemdata:filebeat.yml: |-filebeat.inputs:- type: logpaths:- /usr/local/nginx/logs/access.log# tags: ["access"]fields:app: wwwtype: nginx-accessfields_under_root: truesetup.ilm.enabled: falsesetup.template.name: "nginx-access"setup.template.pattern: "nginx-access-*"output.elasticsearch:hosts: ['elasticsearch.kube-system:9200']index: "nginx-access-%{+yyyy.MM.dd}"
创建刚才编写的nginx-deployment.yaml,创建成果之后会在kube-system命名空间下面pod/web-demo-58d89c9bc4-r5692的2个pod副本,还有一个对外暴露的service/web-demo
[root@k8s-master elk]# kubectl apply -f nginx-deployment.yaml[root@k8s-master fek]# kubectl get pod -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-5bd5f9dbd9-8zdn5 1/1 Running 0 20helasticsearch-0 1/1 Running 1 23hfilebeat-46nvd 1/1 Running 0 23mfilebeat-sst8m 1/1 Running 0 23mk8s-logs-52xgk 1/1 Running 0 15hk8s-logs-jpkqp 1/1 Running 0 15hkibana-b7d98644-tllmm 1/1 Running 0 20hphp-demo-85849d58df-d98gv 2/2 Running 0 26mphp-demo-85849d58df-sl5ss 2/2 Running 0 26m
然后打开kibana的web,按照刚才的办法继续添加一个索引匹配nginx-access-*,如图所示
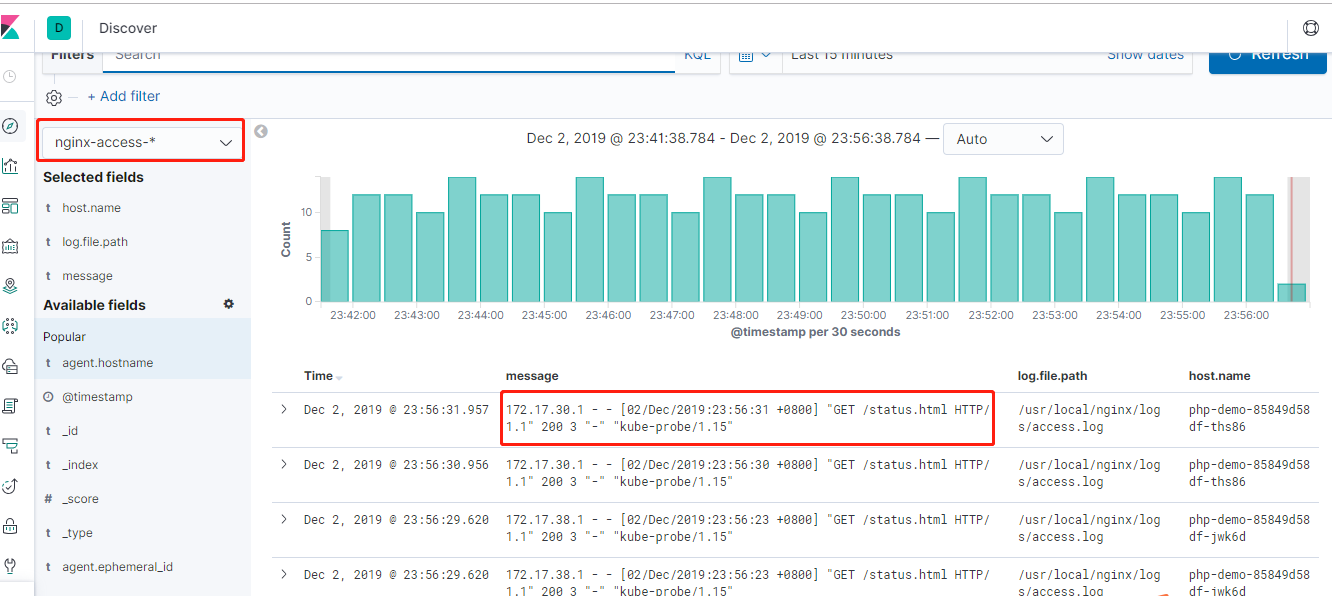
最后点击左边最上面的菜单Discove,然后可以在左侧看到我们刚才创建的索引匹配,下拉选择nginx-access-*,然后就可以在下面添加要展示的标签,也可以对标签进行筛选,最终效果如图所示,可以看到采集到的日志的所有信息,可以使用 http://node ip+30001的访问访问一下刚才创建的nginx,然后测试是否有日志产生
专注开源的DevOps技术栈技术,可以关注公众号,有问题欢迎一起交流

Kubernetes实战之部署ELK Stack收集平台日志的更多相关文章
- 被一位读者赶超,手摸手 Docker 部署 ELK Stack
被一位读者赶超,容器化部署 ELK Stack 你好,我是悟空. 被奇幻"催更" 最近有个读者,他叫"老王",外号"茴香豆泡酒",找我崔更 ...
- ELK Stack (2) —— ELK + Redis收集Nginx日志
ELK Stack (2) -- ELK + Redis收集Nginx日志 摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 ...
- ELK Stack 介绍 & Logstash 日志收集
ELK Stack 组成 Software Description Function E:Elasticsearch Java 程序 存储,查询日志 L:Logstash Java 程序 收集.过滤日 ...
- ELK之收集haproxy日志
由于HAProxy的运行信息不写入日志文件,但它依赖于标准的系统日志协议将日志发送到远程服务器(通常位于同一系统上),所以需要借助rsyslog来收集haproxy的日志.haproxy代理nginx ...
- ELK之收集Java日志、通过TCP收集日志
1.Java日志收集 使用codec的multiline插件实现多行匹配,这是一个可以将多行进行合并的插件,而且可以使用what指定将匹配到的行与前面的行合并还是和后面的行合并. 语法示例: inpu ...
- kubernetes实战之部署一个接近生产环境的consul集群
系列目录 前面我们介绍了如何在windows单机以及如何基于docker部署consul集群,看起来也不是很复杂,然而如果想要把consul部署到kubernetes集群中并充分利用kubernete ...
- ELK技术实战-安装Elk 5.x平台
ELK技术实战–了解Elk各组件 转载 http://www.ywnds.com/?p=9776 ELK技术实战-部署Elk 2.x平台 ELK Stack是软件集合Elasticsearch. ...
- ELK Stack部署
部署ELK Stack 官网:https://www.elastic.co 环境准备: ip hostname 服务 用户.组 192.168.20.3 node2003 kibana6.5,file ...
- ELK:收集Docker容器日志
简介 之前写过一篇博客 ELK:日志收集分析平台,介绍了在Centos7系统上部署配置使用ELK的方法,随着容器化时代的到来,容器化部署成为一种很方便的部署方式,收集容器日志也成为刚需.本篇文档从 容 ...
随机推荐
- Redisson分布式锁学习总结:可重入锁 RedissonLock#lock 获取锁源码分析
原文:Redisson分布式锁学习总结:可重入锁 RedissonLock#lock 获取锁源码分析 一.RedissonLock#lock 源码分析 1.根据锁key计算出 slot,一个slot对 ...
- springboot的build.gradle增加阿里仓库地址以及eclipse增加lombok
该随笔仅限自己记录,请谨慎参考!! 为什么把这2块内容放一个标题里? 发现lombok和eclipse结合的一些问题 关于lombok如何与eclipse结合,网上应该有很多教程,我这块已经做过了,但 ...
- RSA非对称加密算法实现:Python
RSA是1977年由罗纳德·李维斯特(Ron Rivest).阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)一起提出的.当时他们三人都在麻省理工学院工作.RSA ...
- shell2-if判断2
1.条件判断if 判断条件:then //单分支语句 命令1 命令2fi 例子: #!/bin/bash ls if [ $? -eq 0 ]; then echo "执行成功了" ...
- unittest_测试报告(6)
用例执行完成后,执行结果默认是输出在屏幕上,其实我们可以把结果输出到一个文件中,形成测试报告. unittest自带的测试报告是文本形式的,如下代码: import unittest if __nam ...
- go.mod file not found in current directory or any parent directory; see 'go help modules'
go的环境设置问题,执行 go env -w GO111MODULE=auto 我的环境:Windows 7, Go 1.17 D:\Apps\GOPATH\src\code.oldboyedu.co ...
- angularJS中$digest already in progress报错解决方法
看到一个前端群里有人问,就查了下解决"$digest already in progress"最好的方式,就是不要使用$scope.$apply()或者$scope.$digest ...
- 使用Swing的GUI编程
Swing AWT概述 AWT:抽象窗口工具包,提供了一套与本地图形界面进行交互的接口,是Java提供的用来建立和设置Java的图形用户界面的基本工具 Swing以AWT为基础的,尽管Swing消除了 ...
- Kube-OVN 1.2.0发布,携手社区成员打造高性能容器网络
Kube-OVN 1.2.0 新版本如期而至,支持 Vlan 和 OVS-DPDK 两种类型的高性能网络接口.本次发布得益于社区的壮大,感谢Intel爱尔兰开发团队与锐捷网络开发团队持续积极参与Kub ...
- XRecyclerView:实现下拉刷新、滚动到底部加载更多以及添加header功能的RecyclerView
介绍: 一个实现了下拉刷新,滚动到底部加载更多以及添加header功能的的RecyclerView.使用方式和RecyclerView完全一致,不需要额外的layout,不需要写特殊的adater. ...