ELK+kafka docker快速搭建+.NetCore中使用
ELK开源实时日志分析平台。ELK是Elasticsearch,Logstash,Kibana 的缩写。
Elasticsearch:是个开源分布式搜索引擎,简称ES
Logstash:是一个完全开源的工具,可以对日志进行收集,过滤,存储到ES
Kibana: 也是一个开源和免费的工具,这里主要用作ES的可视化界面工具,用于查看日志。
环境:centos7.9
一、搭建ES
先要调高jvm线程数限制,修改sysctl.conf
vim /etc/sysctl.conf
修改max_map_count调大,如果没有这个设置,则新增一行
vm.max_map_count=262144
改完保存后, 执行下面命令让sysctl.conf文件生效
sysctl –p
拉取es镜像
#拉取镜像,指定版本号
docker pull elasticsearch:7.13.2
新建elasticsearch.yml配置文件并上传到主机目录用于配置文件挂载,方便后面修改,这里上传到/home/es目录。
http.host: 0.0.0.0
#跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
启动es
docker run -d -p 9200:9200 -p 9300:9300 --name es -e ES_JAVA_OPTS="-Xms128m -Xmx256m" -v /home/es/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:7.13.2
#9200是对外端口,9300是es内部通信端口
#-e ES_JAVA_OPTS="-Xms128m -Xmx256m" 限制内存,最小128,最大256
#-v 把配置文件挂载到es的docker里的配置文件
在浏览器打开,ip:9200看到es信息,就成功了,启动可能需要一点时间,要等一会。
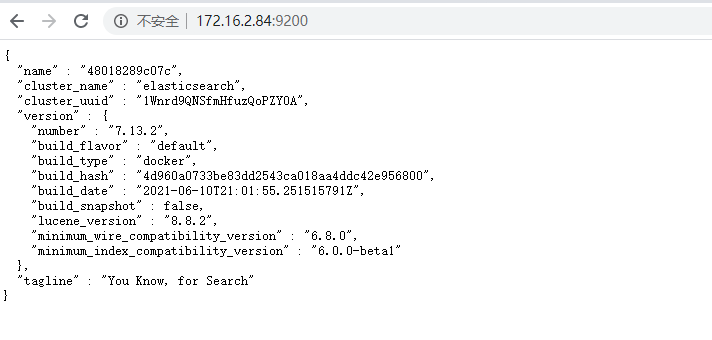
二、搭建Kibana
启动kibana,这里没有先拉取镜像,docker没有镜像会到公共库尝试拉取,下面的一样。
#如果没有镜像会自动到公共库拉取再启动,-e 环境配置指向es的地址
docker run -p 5601:5601 -d --name kibana -e ELASTICSEARCH_URL=http://172.16.2.84:9200 -e ELASTICSEARCH_HOSTS=http://172.16.2.84:9200 kibana:7.13.2
在浏览器输入ip:5601,能看到kibana的信息,说明成功了
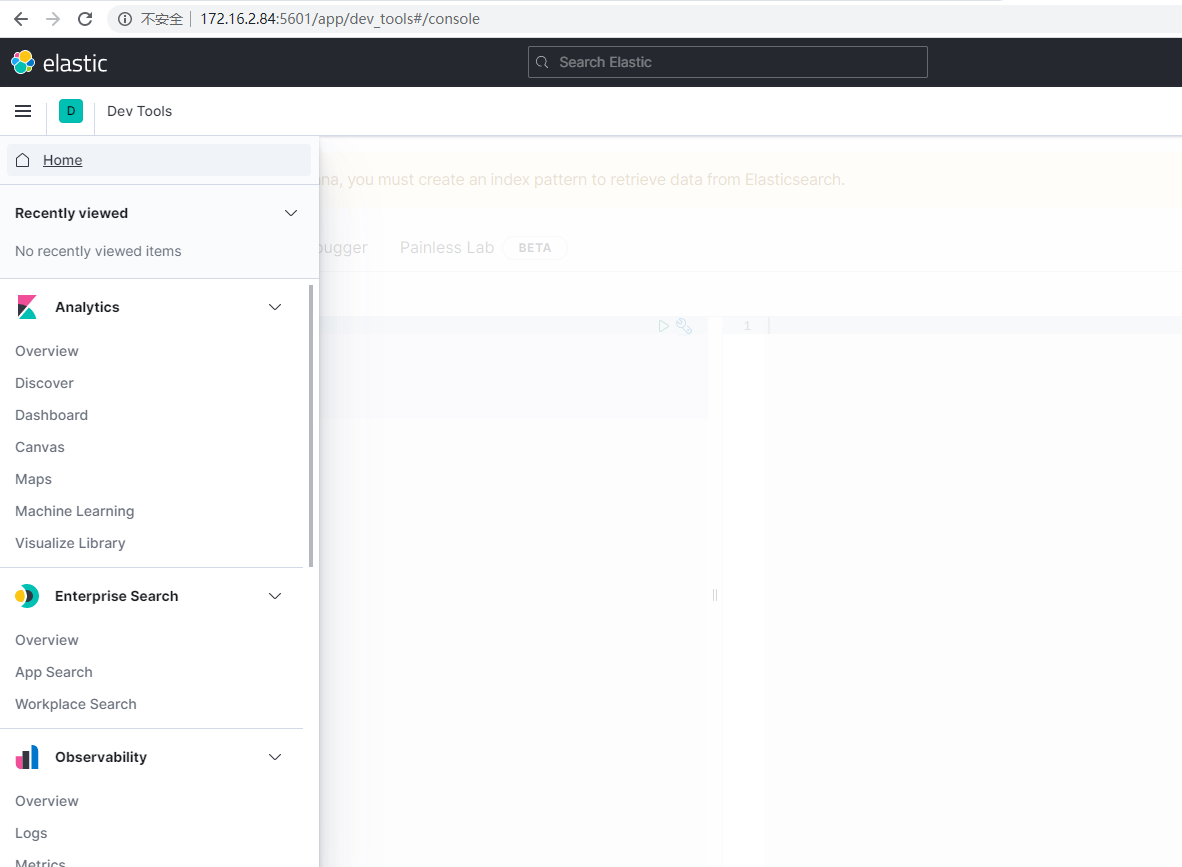
三、搭建kafka
1)kafka前置需要先安装zookeeper
#-v /etc/localtime:/etc/localtime把本机的时间挂载进docker,让docker同步主机的时间
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper
2)安装kafka
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=172.16.2.84:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.2.84:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
#KAFKA_BROKER_ID:kafka节点Id,集群时要指定
#KAFKA_ZOOKEEPER_CONNECT:配置zookeeper管理kafka的路径,内网ip
#KAFKA_ADVERTISED_LISTENERS:如果是外网的,则外网ip,把kafka的地址端口注册给zookeeper,将告诉 zookeeper 自己的地址为 XXXX,当消费者向 zookeeper 询问 kafka 的地址时,将会返回该地址
#KAFKA_LISTENERS: 配置kafka的监听端口
kafka界面查看可以用 kafka tool 地址:https://www.kafkatool.com/download.html

四、搭建Logstash
新建文件logstash.yml,logstash配置信息
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://172.16.2.84:9200" ]
#host多节点用逗号隔开
新建文件logstashkafka.conf,读取kafka信息和写到es的信息
input {
kafka {
topics => "logkafka" #订阅kafka的topics
bootstrap_servers => "172.16.2.84:9092" # 从kafka的leader主机上提取缓存
codec => "json" # 在提取kafka主机的日志时,需要写成json格式
}
}
output {
elasticsearch {
hosts => ["172.16.2.84:9200"]
index => "logkafka%{+yyyy.MM.dd}" #采集到es的索引名称
#user => "elastic"
#password => "changeme"
}
}
把这两个文件放到主机目录上,这里放到/home/logstash
启动logstash容器
docker run --rm -it --privileged=true -p 9600:9600 -d --name logstash -v /home/logstash/logstashkafka.conf:/usr/share/logstash/pipeline/logstash.conf -v /home/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml logstash:7.13.2
#-v 把logstashkafka.conf和logstash.yml挂载到logstash容器
好了,到这里所有需要的容器都建好了运行docker ps -a看下所有容器

五、.Net Core写日志到kafka
.Net Core只要把日志写到kafka,然后logstash订阅kafka把日志写到es即可,这里是.Net Core5.0演示。
NuGet包安装Confluent.Kafka
class Program
{
static async Task Main(string[] args)
{
Console.WriteLine("Hello World!");
//kafka节点
string brokerList = "172.16.2.84:9092";
string topicName = "logkafka";
while (true)
{
Console.WriteLine($"{Environment.NewLine}请输入发送的内容,发送topics名:{topicName}");
string content = Console.ReadLine();
await ConfluentKafka.PublishAsync(brokerList, topicName, content);
}
}
}
public class ConfluentKafka
{
public static async Task PublishAsync(string brokerList, string topicName, string content)
{
//生产者配置
var config = new ProducerConfig
{
BootstrapServers = brokerList, //kafka节点
Acks = Acks.None //ack机制,0不等服务器确认,1主节点确认返回ack,-1全部节点同步完返回ack
};
using (var producer = new ProducerBuilder<string, string>(config)
.Build())
{
try
{
//key要给值,根据key做负载均衡,不然如果多节点,key不给值会全部写有一个分区
var deliveryReport = await producer.
ProduceAsync(
topicName, new Message<string, string> { Key = (new Random().Next(1, 10)).ToString(), Value = content });
Console.WriteLine($"向kafka发送了数据: {deliveryReport.TopicPartitionOffset}");
}
catch (ProduceException<string, string> e)
{
Console.WriteLine($"向kafka发送数据失败:{e.Message}");
}
}
}
}
运行程序,向kafka写数据

查看kafka队列,已经有数据
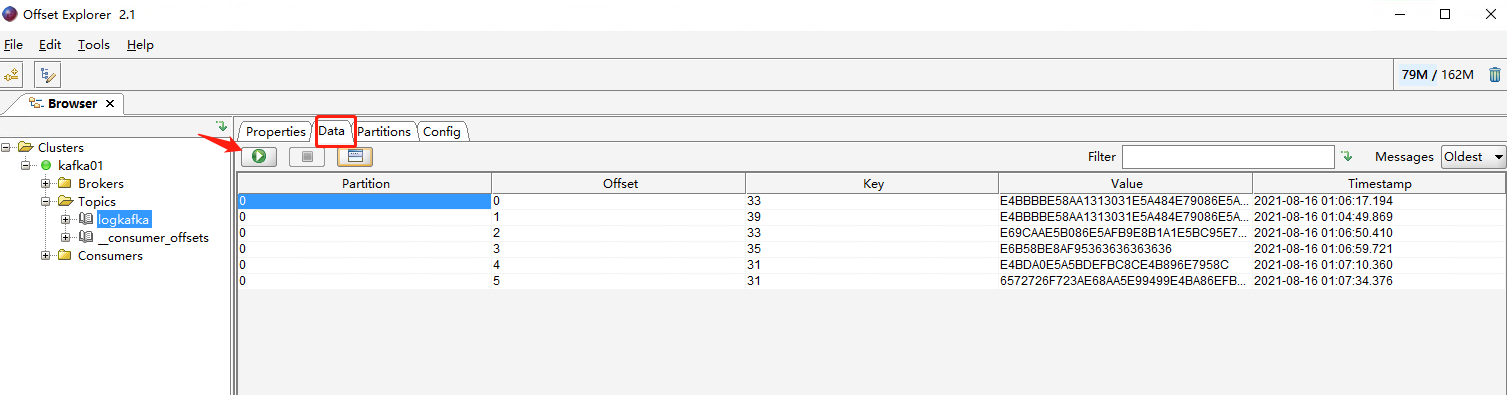
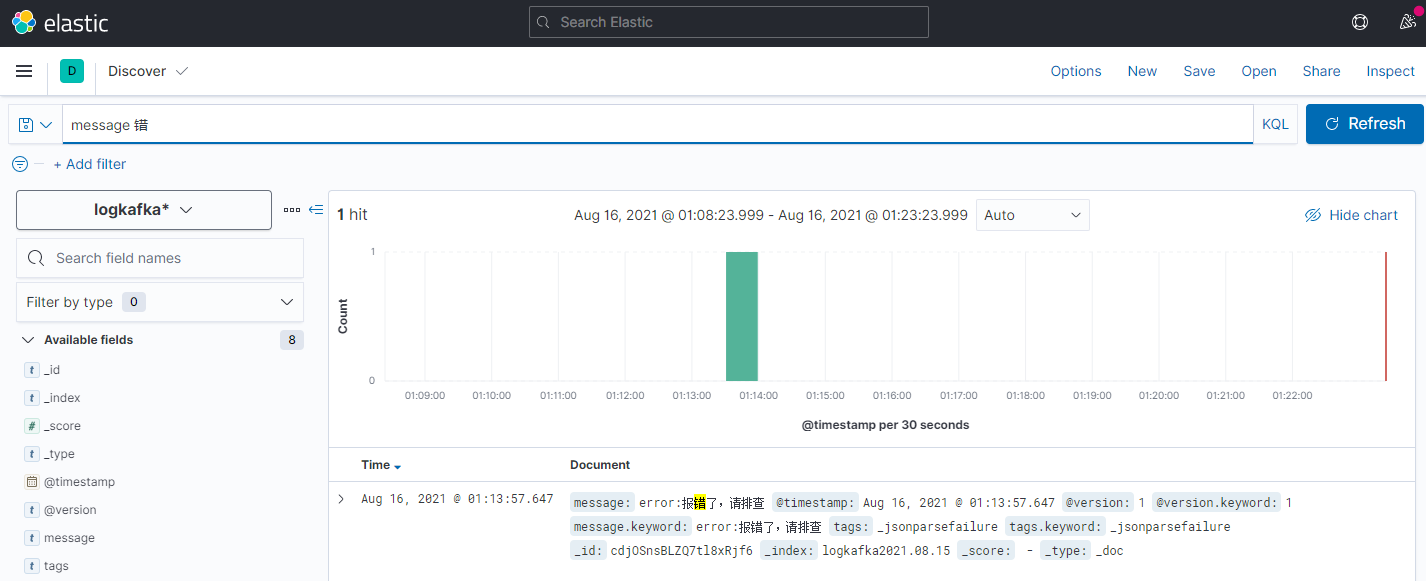
六、ELK日志查看
打开Kibana界面,ip:5601,打开左边的面板
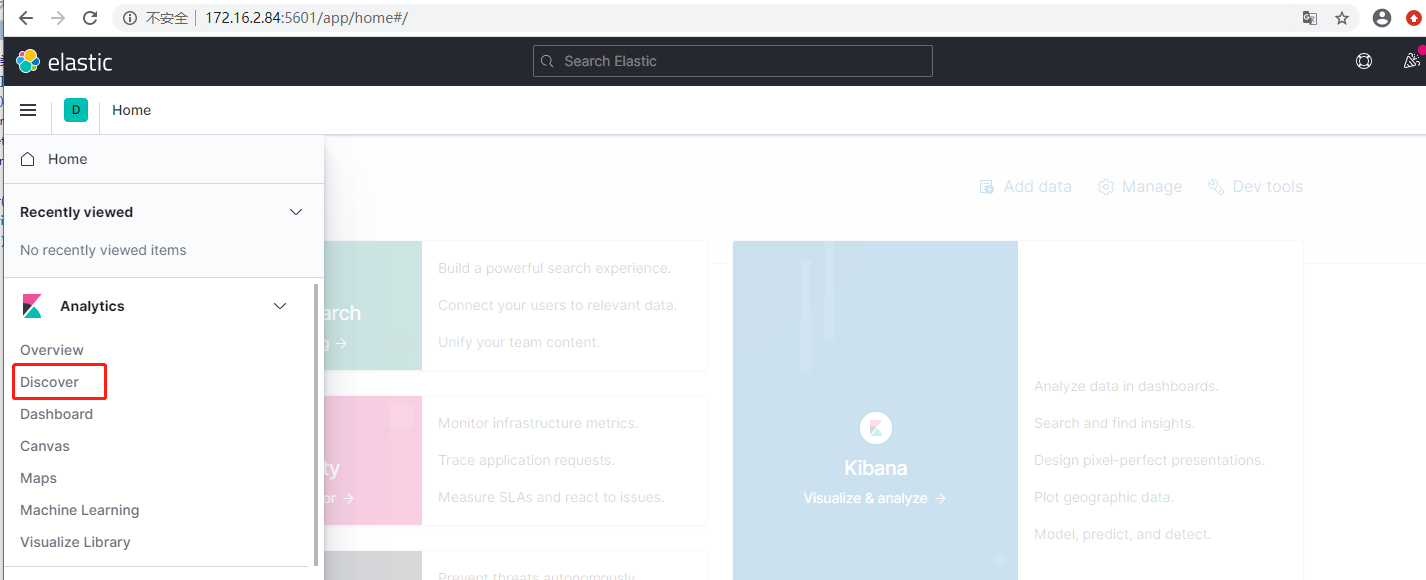
点击索引匹配

输入匹配符,匹配到es日志索引,下一步
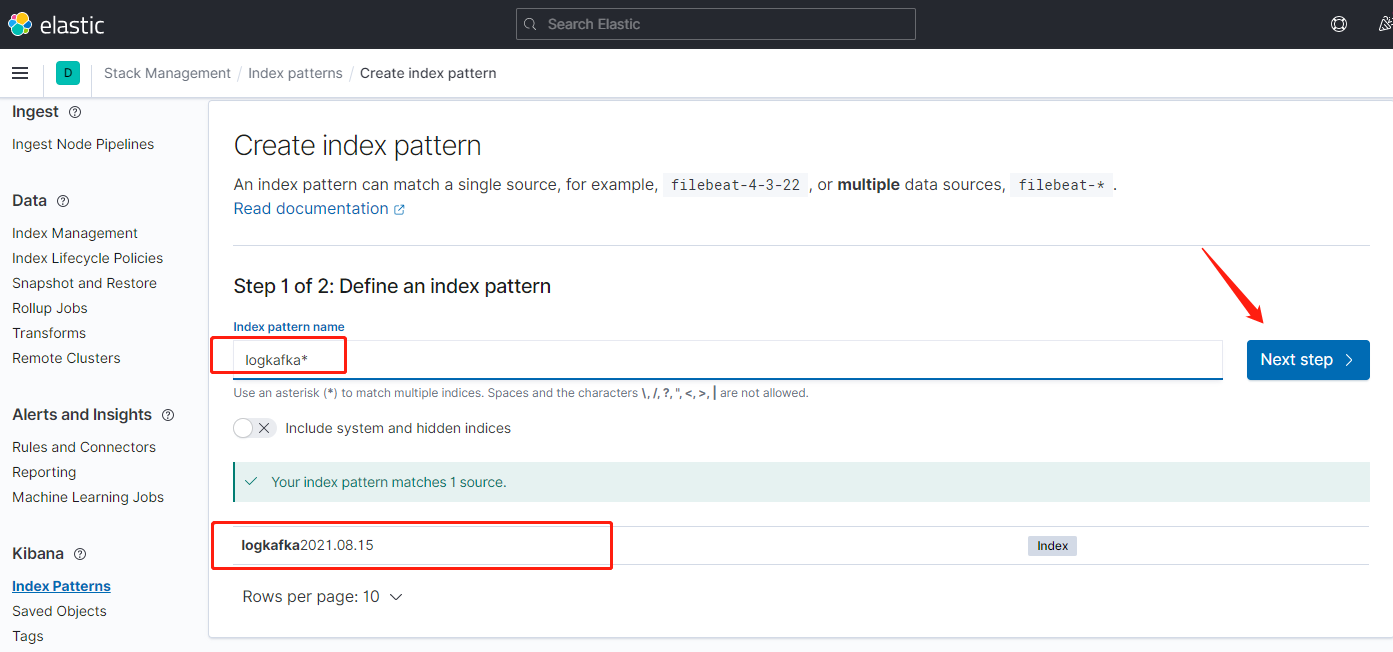
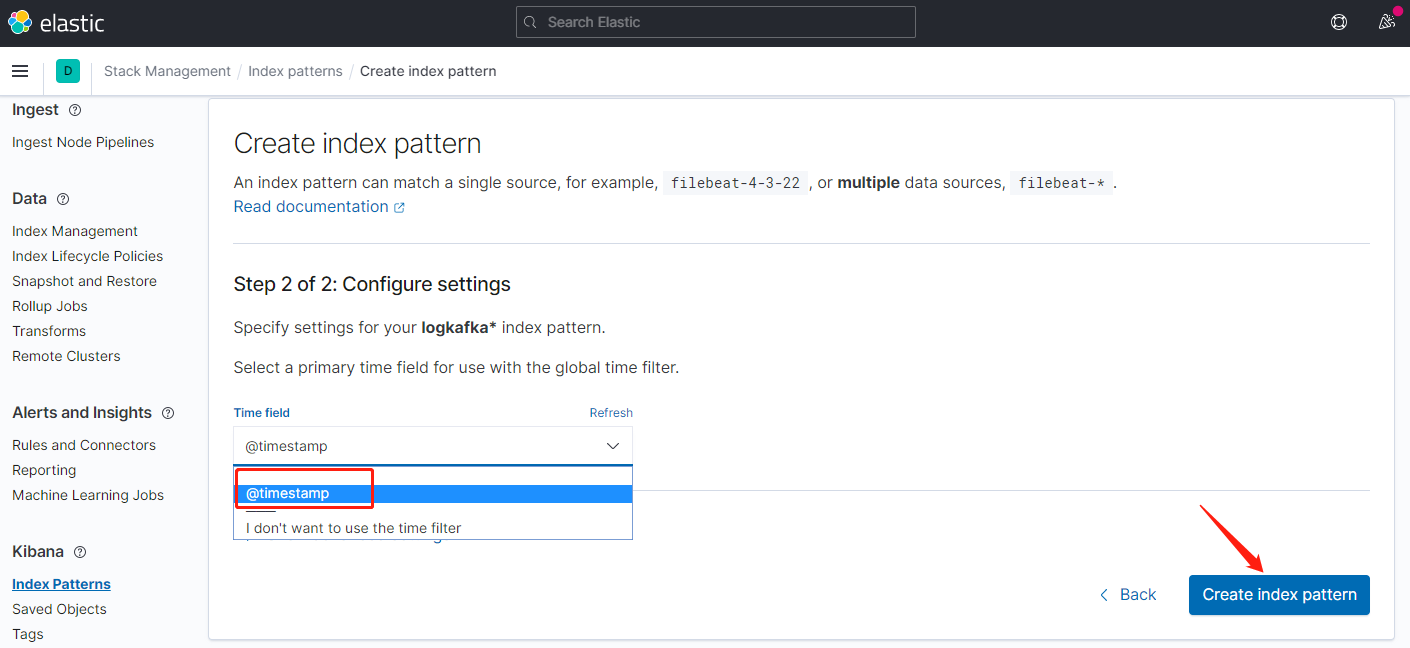
索引匹配创建完毕,返回到面板
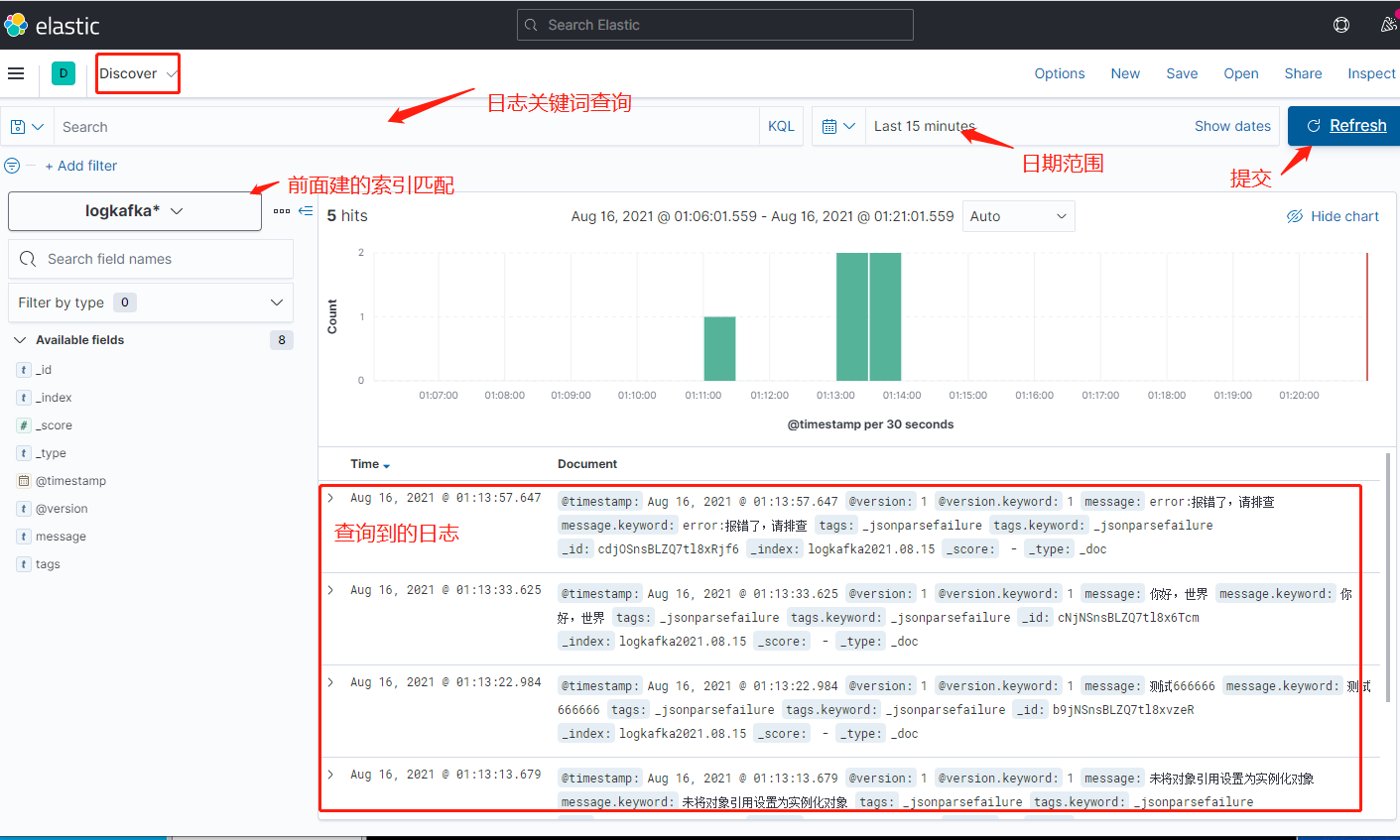
七、其他方式写日志
上面介绍的是kafka方式写日志,也是ELK最佳方式,能承载大量的日志传输,这里列一下其他常用的方式,主要是修改logstash采集配置就可以了。
1.读目录文件方式,根据给的目录,文件类型去读取写到es,logstash配置
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline. input {
file {
path => "D:/Log/Application/*log.log" #读取目录下log.log结尾的文件
start_position => beginning
}
file {
path => "D:/Log/Application2/*log.log" #读取目录下log.log结尾的文件
start_position => beginning
}
}
output {
elasticsearch {
hosts => ["172.16.2.84:9200"]
index => "filelog"
#user => "elastic"
#password => "changeme"
}
}
2.Tcp方式,通过tcp方式写日志,在log4net和nlog中直接可配tcp请求logstash,配置
input {
tcp{
port => 8001
type => "TcpLog"
}
}
output {
elasticsearch {
hosts => ["172.16.2.84:9200"]
index => "tcplog"
#user => "elastic"
#password => "changeme"
}
}
3.reids,把日志推送到一个list类型的Key,logstash会订阅这个key读取消息写到es
input {
redis {
codec => plain
host => "127.0.0.1"
port => 6379
data_type => list
key => "listlog"
db => 0
}
}
output {
elasticsearch {
hosts => ["172.16.2.84:9200"]
index => "redislog"
#user => "elastic"
#password => "changeme"
}
}
4.RabbitMQ,把日志写到一个队列,让logstash订阅队列获取日志写到es
input {
rabbitmq {
host => "127.0.0.1" #RabbitMQ-IP地址
vhost => "test" #虚拟主机
port => 5672 #端口号
user => "admin" #用户名
password => "123456" #密码
queue => "LogQueue" #队列
durable => false #持久化跟队列配置一致
codec => "plain" #格式
}
}
output {
elasticsearch {
hosts => ["172.16.2.84:9200"]
index => "rabbitmqlog"
}
}
ELK+kafka docker快速搭建+.NetCore中使用的更多相关文章
- docker快速搭建几个常用的第三方服务
本次和大家分享的内容是使用docker快速搭建工作中常用的第三方的服务,对于有一些互联网背景的公司来说,以下几个服务都是很需要的:redis,rabbit,elasticsearch: 本篇涉及内容深 ...
- 使用Docker快速搭建ELK环境
今天由于Win系统的笔记本没带回家,其次Docker在非Linux系统下都需要安装额外的软件去镜像才行 所以感觉没有差别,先直接用Mac搭建一遍呢, 本篇部分命令和配置内容为摘抄 Mac下使用Dock ...
- Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- 使用Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- spring boot / cloud (十八) 使用docker快速搭建本地环境
spring boot / cloud (十八) 使用docker快速搭建本地环境 在平时的开发中工作中,环境的搭建其实一直都是一个很麻烦的事情 特别是现在,系统越来越复杂,所需要连接的一些中间件也越 ...
- 一文教您如何通过 Docker 快速搭建各种测试环境(Mysql, Redis, Elasticsearch, MongoDB) | 建议收藏
欢迎关注个人微信公众号: 小哈学Java, 文末分享阿里 P8 高级架构师吐血总结的 <Java 核心知识整理&面试.pdf>资源链接!! 个人网站: https://www.ex ...
- 五分钟用Docker快速搭建Go开发环境
挺早以前在我写过一篇用 `Docker`搭建LNMP开发环境的文章:[用Docker搭建Laravel开发环境](http://mp.weixin.qq.com/s?__biz=MzUzNTY5MzU ...
- Docker-教你如何通过 Docker 快速搭建各种测试环境
今天给大家分享的主题是,如何通过 Docker 快速搭建各种测试环境,本文列举的,也是作者在工作中经常用到的,其中包括 MySQL.Redis.Elasticsearch.MongoDB 安装步骤,通 ...
- 使用docker快速搭建hive环境
记录一下使用docker快速搭建部署hive环境 目录 写在前面 步骤 安装docker 安装docker 安装docker-compose 配置docker国内镜像源(可选) 安装git & ...
随机推荐
- 29、windows下通过zip包方式安装mysql
29.1.下载mysql: 1. www.mysql.com 2. 3. https://dev.mysql.com/downloads/mysql/ 4. 29.2.安装mysql数据库: 1.把下 ...
- JS刷新窗口的几种方式
浮层内嵌iframe及frame集合窗口,刷新父页面的多种方法 <script language=JavaScript> parent.location.reload(); ...
- hdu 2159 二维完全背包
Problem Description 最近xhd正在玩一款叫做FATE的游戏,为了得到极品装备,xhd在不停的杀怪做任务.久而久之xhd开始对杀怪产生的厌恶感,但又不得不通过杀怪来升完这最后一级.现 ...
- Network:java中文转byte出现负数问题
字节的释义 字节(Byte) 是计算机信息技术用于计量存储容量的一种计量单位,通常情况下 1字节 = 8位(bit),也表示一些计算机编程语言中的数据类型和语言字符. 字符与字节 ASCII码:1个英 ...
- 「CF547D」 Mike and Fish
「CF547D」 Mike and Fish 传送门 介绍三种做法. \(\texttt{Solution 1}\) 上下界网络流 我们将每一行.每一列看成一个点. 两种颜色的数量最多相差 \(1\) ...
- Linux下如何使用Rsync备份服务器重要数据
Rsync介绍: Rsync英文全称Remote synchronization,从软件的名称就可以看出来,Rsync具有可使本地和远程两台主机之间的数据快速复制同步镜像,远程备份的功能,这个功能类似 ...
- 从sql2008导入表结构及数据到mysql
打开navicat for mysql连接mysqlcreate database lianxi刷新,双击lianxi,双击"表"点击右边的"导入向导"选择&q ...
- Linux从入门到进阶全集——【第十四集:Shell编程-export命令】
参考: https://www.cnblogs.com/guojun-junguo/p/9855356.html 功能说明:设置或显示环境变量. 语 法:export [-fnp][变量名称]=[变量 ...
- P6106 [Ynoi2010] Self Adjusting Top Tree
P6106 [Ynoi2010] Self Adjusting Top Tree 题意 给出平面直角坐标系上若干不与坐标轴平行的处于第一象限的互不相交的线段,多次询问平面中一个第一象限的矩形与这些线段 ...
- Vue全局引入JS的方法
两种情况: 1. js为ES5的写法时,如下(自定义的my.js): function fun(){ console.log('hello'); } Vue中的全局引入方式为,在index.html中 ...