DeepFool: a simple and accurate method to fool deep neural networks
@article{moosavidezfooli2016deepfool:,
title={DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks},
author={Moosavidezfooli, Seyedmohsen and Fawzi, Alhussein and Frossard, Pascal},
pages={2574--2582},
year={2016}}
概
本文从几何角度介绍了一种简单而有效的方法.
主要内容
adversarial的目的:
\Delta(x;\hat{k}):= \min_{r} \|r\|_2 \: \mathrm{subject} \: \mathrm{to} \: \hat{k}(x+r) \not = \hat{k}(x),
\]
其中\(\hat{k}(x)\)为对\(x\)的标签的一个估计.
二分类模型
当模型是一个二分类模型时,
\]
其中\(f:\mathbb{R}^n \rightarrow \mathbb{R}\)为分类器, 并记\(\mathcal{F}:= \{x: f(x)=0\}\)为分类边界.
\(f\)为线性
即\(f(x)=w^Tx+b\):
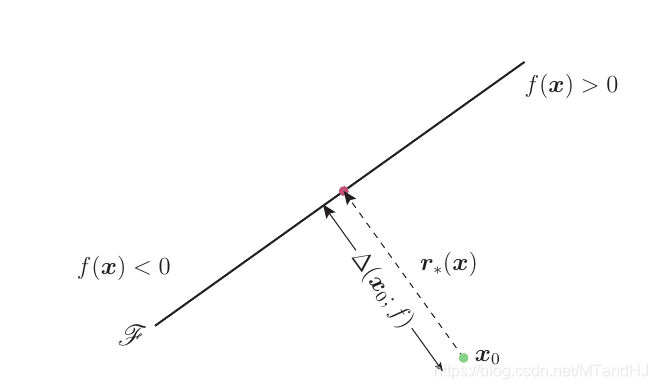
假设\(x_0\)在\(f(x)>0\)一侧, 则
\]
\(f\)为一般二分类
此时, 我们\(f\)的一阶近似为
\]
此时分类边界为\(\mathcal{F} =\{x:f(x_0)+\nabla^T f(x_0) (x-x_0)=0\}\),此时\(w=\nabla f(x_0),b=f(x_0),\) 故
r_*(x_0) \approx -\frac{f(x_0)}{\|\nabla f(x_0)\|_2^2} \nabla f(x_0).
\]
所以, 每次
x_{i+1} = x_i+r_i,
\]
直到\(\hat{k}(x_i) \not= \hat{k}(x_0)\)是停止, 算法如下

多分类问题
\(f:\mathbb{R}^n \rightarrow \mathbb{R}^c\), 此时
\hat{k}(x) = \arg \max_k f_k(x).
\]
\(f\)仿射
即\(f(x) = W^Tx + b\), 设\(W\)的第\(k\)行为\(w_k\),
P=\cap_{k=1}^c \{x: f_{\hat{k}(x_0)}(x) \ge f_k(x)\},
\]
为判定为\(\hat{k}(x_0)\)的区域, 则\(x+r\)应落在\(P^{c}\), 而
\]
当\(f\)为仿射的时候, 实际上就是找\(x_0\)到各分类边界(与\(x_0\)有关的)最短距离,
\hat{l}(x_0) = \arg \min _{k \not = \hat{k}(x_0)} \frac{|f_k(x_0) - f_{\hat{k}(x_0)}(x_0)|}{\|w_k-w_{\hat{k}(x_0)}\|_2},
\]
则
r_*(x_0)= \frac{|f_{\hat{l}(x_0)}(x_0) - f_{\hat{k}(x_0)}(x_0)|}{\|w_{\hat{l}(x_0)}-w_{\hat{k}(x_0)}\|_2^2}(w_{\hat{l}(x_0)}-w_{\hat{k}(x_0)}),
\]
\(f\)为一般多分类
\tilde{P}_i=\cap_{k=1}^c \{x: f_{\hat{k}(x_0)}(x_i) + \nabla^T f_{\hat{k}(x_0)}(x_i) (x-x_i)\ge f_k(x_i) + \nabla^Tf_k(x_i)(x-x_i)\},
\]
则
\]

\(l_p\)
\(p \in (1, \infty)\)的时候
考虑如下的问题
\min & \|r\|_p^p \\
\mathrm{s.t.} & w^T(x+r)+b=0,
\end{array}
\]
利用拉格朗日乘子
\]
由KKT条件可知(这里的\(r_k\)表示第\(k\)个元素)
\]
注: 这里有一个符号的问题, 但是可以把符号放入\(c_k\)中进而不考虑,
故
\]
其中\(q=\frac{p}{p-1}\)为共轭指数, 并\(c=[c_1,\ldots]^T\),且\(|c_i|=|c_j|,\) 记\(w^{q-1}=[|w_1|^{q-1},\ldots]^T\),又
\]
故
\]
故
\]
\(p=1\), 设\(w\)的绝对值最大的元素为\(w_{m}\), 则
\]
\(\mathrm{1}_m\)为第\(m\)个元素为1, 其余元素均为0的向量.
\(p=\infty\),
\]
故:
\(p \in [1, \infty)\):
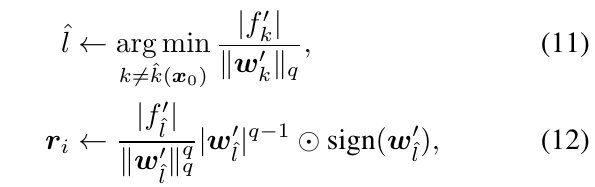
\(p=\infty\):
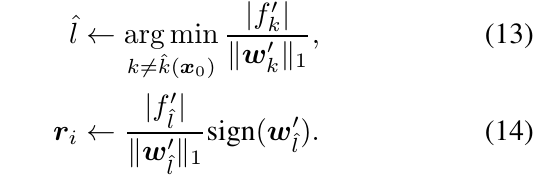
注: 因为, 仅仅到达边界并不足够, 往往希望更进一步, 所以在最后(?)\(x=x+ (1+\eta) r\), 文中取\(\eta=0.02\).
DeepFool: a simple and accurate method to fool deep neural networks的更多相关文章
- Dropout: A Simple Way to Prevent Neural Networks fromOverfitting
https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf Deep neural nets with a large number of par ...
- AUGMIX : A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTAINTY
目录 概 主要内容 实验的指标 Dan Hendrycks, Norman Mu,, et. al, AUGMIX : A SIMPLE DATA PROCESSING METHOD TO IMPRO ...
- 论文笔记系列-Simple And Efficient Architecture Search For Neural Networks
摘要 本文提出了一种新方法,可以基于简单的爬山过程自动搜索性能良好的CNN架构,该算法运算符应用网络态射,然后通过余弦退火进行短期优化运行. 令人惊讶的是,这种简单的方法产生了有竞争力的结果,尽管只需 ...
- 小米造最强超分辨率算法 | Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
本篇是基于 NAS 的图像超分辨率的文章,知名学术性自媒体 Paperweekly 在该文公布后迅速跟进,发表分析称「属于目前很火的 AutoML / Neural Architecture Sear ...
- PyNest——Part1:neurons and simple neural networks
neurons and simple neural networks pynest – nest模拟器的界面 神经模拟工具(NEST:www.nest-initiative.org)专为仿真点神经元的 ...
- 【论文阅读】DCAN: Deep Contour-Aware Networks for Accurate Gland Segmentation
DCAN: Deep Contour-Aware Networks for Accurate Gland Segmentation 作者:Hao Chen Xiaojuan Qi Lequan Yu ...
- simple factory, factory method, abstract factory
simple factory good:1 devide implementation and initialization2 use config file can make system more ...
- ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression笔记
前言 致力于滤波器的剪枝,论文的方法不改变原始网络的结构.论文的方法是基于下一层的统计信息来进行剪枝,这是区别已有方法的. VGG-16上可以减少3.31FLOPs和16.63倍的压缩,top-5的准 ...
- 论文笔记——ThiNet: A Filter Level Pruning Method for Deep Neural Network Compreesion
论文地址:https://arxiv.org/abs/1707.06342 主要思想 选择一个channel的子集,然后让通过样本以后得到的误差最小(最小二乘),将裁剪问题转换成了优化问题. 这篇论文 ...
随机推荐
- 2021广东工业大学十月月赛 F-hnjhd爱序列
题目:GDUTOJ | hnjhd爱序列 (gdutcode.cn) 一开始是用双指针从尾至头遍历,但发现会tle!! 后来朋友@77给出了一种用桶的做法,相当于是用空间换时间了. 其中用到的一个原理 ...
- Codeforces Round #754 (Div. 2) C. Dominant Character
题目:Problem - C - Codeforces 如代码,一共有七种情况,注意不要漏掉 "accabba" , "abbacca" 两种情况: 使用 ...
- 案例 stm32的dma传输过程
首先说一下:DMA_GetCurrDataCounter返回值是什么 返回值是dma缓存里还剩余多少空间. 上面本来应该是,发一下,改变一下.但是这里有一行是特殊的. long : 461,*ff l ...
- 实现nfs持久挂载+autofs自动挂载
实验环境: 两台主机 node4:192.168.37.44 NFS服务器 node2:192.168.37.22 客户端 在nfs服务器,先安装nfs和rpcbind [root@node4 fen ...
- 渐进式web应用 (PWA)
PWA(渐进式 Web 应用)运用现代的 Web API 以及传统的渐进式增强策略来创建跨平台 Web 应用程序. PWA的特点: Discoverable, 内容可以通过搜索引擎发现. Instal ...
- spring cloud 通过 ribbon 实现客户端请求的负载均衡(入门级)
项目结构 环境: idea:2020.1 版 jdk:8 maven:3.6.2 1. 搭建项目 ( 1 )父工程:spring_cloud_demo_parent pom 文件 <?xml v ...
- 使用$.ajax方式实现页面异步访问,局部更新的效果
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- ios self.和_区别
- "self."调用该类的setter或getter方法,"_"直接获取自己的实例变量.property 和 instance variable 是有区别的. ...
- HCNP Routing&Switching之组播技术-组播协议IGMP
前文我们了解了组播地址相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15616740.html:今天我们来聊一聊组播协议中IGMP协议相关话题: 组播 ...
- 为什么众多软件厂商无法提供APS高级计划排程系统?工厂目前生产计划是怎么排产的?
一.行业现状如想了解一下目前现状,去考察一下上了ERP的企业,会发现一个有趣的现象该企业无论ERP软件搞得如何如火如荼,似乎都与生产调度人员无关. 车间里或者生产线上的生产作业计划.生产过程的调度和管 ...