MIT6.828 Preemptive Multitasking(上)
Lab4 Preemptive Multitasking(上)
PartA : 多处理器支持和协作多任务
在实验的这部分中,我们首先拓展jos使其运行在多处理器系统上,然后实现jos内核一些系统功能调用以支持用户级环境去创建新环境。我们还需要实现协同式轮询调度(cooperative round-robin scheduling)算法,允许内核在旧的用户环境资源放弃CPU或者退出的时候切换到一个新的用户环境。
1. Multiprocessor Support
下面是一段对实验指导书的翻译。
我们将使JOS支持“对称多处理”(SMP)的多处理器模型,其中所有CPU都有对系统资源(如内存和I / O总线)的等同权限的访问。 虽然所有CPU在SMP中在功能上相同,但在引导过程中,它们可以分为两种类型:
- 引导处理器BSP(bootstrap processor)负责初始化系统并且引导操作系统。
- 应用处理器AP(application processor)在操作系统启动之后被BSP激活。
由哪个(些)处理器来担任BSP的功能是由BIOS和硬件决定的,之前的所有代码都是在BSP上实现的。
在一个SMP系统中,每一个CPU都有一个伴随的本地APIC(LAPIC)单元。LAPIC单元负责整个系统的中断传递。LAPIC为与其相关联的CPU提供了一个唯一的标识符。在这个实验中我们会使用LAPIC的一些基本功能(在kern/lapic.c中):
读取LAPIC标识符(APIC ID),告知我们的代码正运行在哪个CPU上(参考
cpunum())intcpunum(void){if (lapic)return lapic[ID] >> 24;return 0;}
从BSP向AP发送
STARTUP处理器间中断信号IPI(interprocessor interrupt),唤醒其他CPU(参考lapic_startup())在Part C中,我们将通过LAPIC单元内置的定时器来触发时钟中断,实现抢占式多任务(参考
apic_init())
处理器通过内存映射I/O也称为MMIO(memory-mapped I/O)来访问LAPIC单元。在MMIO中,一部分的物理内存被硬链接到某些I/O设备的寄存器。因此load/store访存指令也可以特别用于访问设备寄存器。
在之前的实验中我们已经知道了在物理地址0xA0000处有一个I/O hole(这个hole用于写VGA显示缓存)。LAPIC单元存在于第二个I/O hole上,物理地址0xFE000000(4064MB)。这个高地址无法用之前设置对KERNBASE的直接映射去访问。jos的虚拟内存映射在MMMIOBASE处留了4MB的空隙,所以我们可以在这里映射硬件去访问。之后的实验中还会引入更多的MMIO区域,我们需要实现一个函数来分配这部分区域并映射到I/O设备对应的内存
Exercise 1
实现
kern/pmap.c中的mmio_map_region()函数。我们可以看到它在kern/lapic.c中在lapic_init()的开头被调用。(为了让这个函数的测试案例能够正常运行,我还需要把下一个练习也做完。
本来这里想通过几个断点看一下运行流程的。。但是它的一堆assert测试会卡这个函数的实现。

好分析一下mmio_map_region()让我们干的事
整体来讲的功能就是把给定的[pa,pa+size]的物理地址和[MMIOBAZE, MMIOBASE + size]对应起来。
void *mmio_map_region(physaddr_t pa, size_t size){// Where to start the next region. Initially, this is the// beginning of the MMIO region. Because this is static, its// value will be preserved between calls to mmio_map_region// (just like nextfree in boot_alloc).static uintptr_t base = MMIOBASE;
根据代码提示其实这里可以很容易的写完
- size要和pagesize做上取整
- 如果size + base超过了
MMIOLIM则发出panic - 对应map则用我们之前实现过的
boot_map_region即可 - 这里的base是一个静态变量,所以我们要记得更新它,因为下一次分配的时候base就会变了
size = ROUNDUP(size,PGSIZE);if (size + base > MMIOLIM) {panic("wow overflow happen");}boot_map_region(kern_pgdir,base,size,pa,PTE_PCD|PTE_PWT|PTE_W);//panic("mmio_map_region not implemented");uintptr_t reserved_base = base;base += size;return (void*)reserved_base;
2. Application Processor Bootstrap
在引导AP之前,BSP首先需要收集有关多处理器系统的信息,比如总CPU数,每个CPU对应的APIC ID以及LAPIC的内存映射地址等。kern/mpconfig.c中的mp_init()函数通过读取BIOS内存中的MP配置表来获取相关信息。
kern/init.c中的boot_aps()函数驱动了AP的引导过程。AP从实模式开始启动(类似于bootloader),因此boot_aps()从kern/mpentry.S中拷贝了一份AP入口代码(entry code)到一个实模式下可以访问的内存位置。与bootloader不同的是,我们对于AP入口代码存放的位置可以有一定控制权:在jos中使用MPENTRY_PADDR(0x7000)作为入口地址的存放位置,但是实际上640KB下任何未使用的地址都是可以使用的。
接下来,boot_aps()向对应AP的LAPIC单元发送STARTUP的IPI信号(处理器间中断),使用AP的entry code初始化其CS:IP地址(在这里我们就使用MPENTRY_PADDR)依次激活APs。
在一些简单的设置之后,AP将启动分页并进入保护模式,然后调用在kern/init.c中的启动例程mp_main。boot_aps()在唤醒下一个AP之前会等待当前AP发出一个CPU_STARTED启动标记,这个标记位在struct CpuInfo中的cpu_status域。
Exercise 2
首先阅读kern/init.c中的boot_aps()以及mp_main()和kern/mpentry.S汇编代码。我们需要确保理解APs的bootstrap过程中的控制流切换。
控制流切换
首先在系统加载的过程中,
boot_aps()被调用。这个时候是由BSP调用然后使用
memmove()函数从mpentry.S中拷贝文件中.global mpentry_start标签处开始的入口代码直到.global mpentry_end结束,代码被拷贝到MPENTRY_PADDR(物理地址0x7000)对应的内核虚拟地址(别忘了必须拷贝到内核虚拟地址才可以被内核所操作)code = KADDR(MPENTRY_PADDR);memmove(code, mpentry_start, mpentry_end - mpentry_start);
然后
boot_aps()根据每一个CPU的栈配置percpu_kstacks[]来为每一个AP设置栈地址mpentry_stack。再之后调用
lapic_startup()函数来启动AP,并等待AP的状态变为CPU_STARTED以切换到下一个AP的配置。Lapis_startup后面看看在lab最后理解一下
AP启动后,执行从
mpentry.S中复制的入口代码:
然后修改我们之前在kern/pmap.c中page_init()的实现,避免将MPENTRY_PADDR的区域也添加到page_free_list中,这样我们才可以安全地在该物理地址处拷贝以及运行AP的引导代码。
其实只需要求出MPENTRY_PADDR对应在pages数组中的索引。当我们对page初始化的时候跳过MPENTRY_PADDR所在的页就好。
因为只是几行汇编代码一页足够了。

Question
比较kern/mpentry.S和boot/boot.S,记住两个代码都是编译连接后加载到KERNBASE之上运行的,为什么mpentry.S需要一个多余的宏定义MPBOOTPHYS?换句话说,如果在kern / mpentry省略它会出现问题
首先我们来看一下这个宏是在干嘛
这是用来计算对应汇编代码的绝对地址。
因为我们会把mpentry_start移动到MPENTRY_PADDR上。因此下面的宏定义就相当于在算当前的代码和起点的差值 + 真正的起始地址就会得到真正的地址
#define MPBOOTPHYS(s) ((s) - mpentry_start + MPENTRY_PADDR)
kern/mpentry.S是运行在KERNBASE之上的,与其他的内核代码一样。也就是说,类似于mpentry_start,mpentry_end,start32这类地址,都位于0xf0000000之上,显然,实模式是无法寻址的。因此,实模式下就可以通过MPBOOTPHYS宏的转换,运行这部分代码
3. Per-CPU State and Initialization
长长的翻译。说实话每次看完这些翻译,我还是一头雾水,都还是通过慢慢看代码看懂的。
在编写多处理器OS时,重要的是区分每个CPU的私有状态,以及整个系统共享的全局状态。kern/cpu.h中定义了绝大部分CPU的状态,包括用于储存cpu变量的struct CpuInfo。
cpunum()总是返回调用它的CPU ID,能用来索引例如cpus的数组。宏定义thiscpu是当前CPU的struct CpuInfo的简写。
下面是应该了解的每个CPU状态:
CPU内核堆栈
由于多个CPU可以同时陷入内核,我们需要为每个CPU设置独立的内核栈来避免相干扰。 percpu_kstacks [ncpu] [kstksize]保留NCPU的核堆栈的空间。
在Lab 2中,我们将BootStack指向的物理内存,映射到虚拟地址Kstacktop处作为BSP的内核堆栈。相似地我们在本次实验中需要为每个CPU的内核栈映射到数组的对应区域。 CPU 0的堆栈仍将从Kstacktop开始向下增长;之后第n个CPU的内核栈从KSTACKTOP - n*KSTKGAP处开始向下增长。如inc/memlayout.h中所示。
CPU的TSS和TSS描述符
每CPU都需要任务状态段(TSS),以便指定每个CPU的内核堆栈生命的位置。 CPU i的TSS存储在CPU [i] .cpu_ts中,并且在GDT条目GDT [(GD_TSS0 >> 3)+ i]中定义相应的TSS描述符。 kern / trap.c中定义的全局TS变量将不再有用。
CPU指向当前环境的指针
由于每个CPU可以同时运行不同的用户进程,将curenv定义为指向当前CPU(当前代码正在执行的CPU)正在执行的环境的cpus[cpunum()].cpu_env(或是thiscpu->cpu_env)
CPU的系统寄存器。
包括系统寄存器在内的所有寄存器都属于CPU私有。因此初始化这些寄存器的指令如lcr3, ltr, lgdt等,必须在每个CPU上都被执行。函数env_init_percpu()和trap_init_percpu的功能就在于此。
Exercise 3
修改kern/pmap.c中的mem_init_mp(),使CPU内核栈映射到相应的虚拟内存。
这个函数根据代码提示可以很快做完,基本上只有两点需要注意的
- 就是权限记得写成
PTE_W - 记得
percpu_kstacks对应的是内核栈的虚拟地址要利用PADDR宏定义把它转换成物理地址
// LAB 4: Your code here:int i = 0;for (; i < NCPU; i++) {boot_map_region(kern_pgdir,KSTACKTOP - i * (KSTKSIZE + KSTKGAP) - KSTKSIZE,KSTKSIZE, PADDR(percpu_kstacks[i]),PTE_W);}
Exercise 4
kern/trap.c中的trap_init_percpu()初始化了BSP的TSS和TSS描述符(它可以在lab3中给正常工作,但是本实验运行在其他CPU时不能正常工作),我们需要修改代码以使其支持所有CPU。
基本上也是根据代码提示来
- 不要使用ts寄存器。转而利用
thiscpu->cpu_ts来为每个cpu初始化tss寄存器的值 - 对于tss描述符要用这样的方式gdt[(GD_TSS0 >> 3) + i]来存储
thiscpu->cpu_ts.ts_esp0 = (uintptr_t)percpu_kstacks[cpunum()];thiscpu->cpu_ts.ts_ss0 = GD_KD;thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);// Initialize the TSS slot of the gdt.gdt[(GD_TSS0 >> 3) + cpunum()] = SEG16(STS_T32A, (uint32_t) (&(thiscpu->cpu_ts)),sizeof(struct Taskstate) - 1, 0);gdt[(GD_TSS0 >> 3) + cpunum()].sd_s = 0;// Load the TSS selector (like other segment selectors, the// bottom three bits are special; we leave them 0)ltr(GD_TSS0 + (cpunum() << 3));
可以得到下面的结果,发现确实可以产生合理的结果

4. Locking
当前我们的代码会在mp_main()初始化完成所有AP之后陷入自旋(spin)。在让这些AP做出下一步操作之前,我们需要解决多个CPU同时执行内核代码的竞争条件。
最简单的方式就是使用一个大内核锁(big kernel lock)。这个大内核锁是一个单一的全局锁,当一个环境进入内核模式的时候就可以被获取,然后返回到用户态的时候被释放。在这种模型下,用户模式的环境可以在任意多个CPU下并发运行(concurrently),但是只有一个环境能处于内核态,其余环境进入内核态需要强制等待。
kern/spinlock.h中声明了这个大内核锁的实现函数kernel_lock()。同时它提供了lock_kernel()和unlock_kernel()两个函数用于上锁和解锁,我们需要在以下四个场景使用大内核锁:
i386_init():在BSP唤醒其它CPU之前进行上锁mp_main():初始化AP之后进行上锁,然后调用sched_yield()在当前AP上运行环境trap():从用户模式陷入内核之前获得大锁进行上锁。通过TF_CS寄存器的低位来判断陷阱是否发生在用户模式或内核模式下env_run():在切换回用户态之前进行解锁。时机不对会导致竞争或死锁
这个整体按照代码提示,加一行减一行的非常容易
// In i386_init():// Acquire the big kernel lock before waking up APs// Your code here:lock_kernel();// In mp_main():// Now that we have finished some basic setup, call sched_yield()// to start running processes on this CPU. But make sure that// only one CPU can enter the scheduler at a time!//// Your code here:// lock the kernel and start running enviromentslock_kernel();sched_yield();// In trap():// Trapped from user mode.// Acquire the big kernel lock before doing any// serious kernel work.// LAB 4: Your code here.lock_kernel();// In env_run():// address space switch// reference from inc/x86.hlcr3(PADDR(e->env_pgdir));// release kernel lock hereunlock_kernel(); // newly added code// drop into user modeenv_pop_tf(&(e->env_tf));
exercise 5
通过调用lock_kernel()和unlock_kernel()函数来实现上面所描述的大内核锁
首先在i386_init()中实现在bsp其他cpu之前进行上锁
Question
似乎使用Big Kernel Lock保证了只能有一个CPU在内核态运行。 那为什么每个CPU还需要单独内核堆栈? 描述一个场景,其中使用共享内核堆栈将出错,即使是对大内核锁定的保护。
当cpu0在内核态运行的时候,这个时候如果cpu1发生中断想要陷入内核态,那么如果这两个cpu是共享内核态的话就会发生错误。当发生中断的时候,会进行栈的切换,cpu1再陷入之前要把一些参数保存到内核栈中。如果内核栈共享的话,则就出现问题
5. Round-Robin Scheduling
我们的下一个任务是改变jos内核,实现对用户环境的轮询调度:
kern/sched.c中的sched_yield()负责从用户环境中选择一个新环境执行。其按照顺序遍历envs[]数组,从上一次运行的环境开始,找到第一个ENV_RUNNABLE的环境然后调用env_run()。sched_yield()一定不能在两个CPU上同时运行相同的环境。它可以通过环境的状态是否为ENV_RUNNING来判断这个环境是否正运行在某个CPU上。- 我们提供了一个新的系统调用
sys_yield(),使得在用户环境中可以通过该系统调用唤醒sched_yield(),主动放弃CPU。
exercise 6
在sched_yield()中实现上述机制,注意我们要修改syscall()来支持对sys_yield()的调度。
// LAB 4: Your code here.size_t start = 0;if (curenv) {start = ENVX(curenv->env_id) + 1;}for (size_t i = 0; i < NENV; i++) {size_t index = (start + i) % NENV;if (envs[index].env_status == ENV_RUNNABLE) {env_run(&envs[index]);}}//// If no envs are runnable, but the environment previously// running on this CPU is still ENV_RUNNING, it's okay to// choose that environment.if(curenv && curenv->env_status == ENV_RUNNING) {env_run(curenv);}// sched_halt never returnssched_halt();
确保在mp_main()中调用sched_yield()。
修改kern/init.c来创建三个或者更多的用户环境,使其同时运行user/yield.c程序。
#else// Touch all you want.// ENV_CREATE(user_primes, ENV_TYPE_USER);ENV_CREATE(user_yield, ENV_TYPE_USER);ENV_CREATE(user_yield, ENV_TYPE_USER);ENV_CREATE(user_yield, ENV_TYPE_USER);
关于lab3的一个小bug
Lab3博客中已经修复
在trap.c中的trap_init(void)函数中
(-) SETGATE(idt[T_SYSCALL],1,GD_KT,syscall_handler,3);(+) SETGATE(idt[T_SYSCALL],0,GD_KT,syscall_handler,3);
关于系统调用是要关中断的也就是说它不是一个trap类型。不然这里会过不了

Question
In your implementation of
env_run()you should have calledlcr3(). Before and after the call tolcr3(), your code makes references (at least it should) to the variablee, the argument toenv_run. Upon loading the%cr3register, the addressing context used by the MMU is instantly changed. But a virtual address (namelye) has meaning relative to a given address context--the address context specifies the physical address to which the virtual address maps. Why can the pointerebe dereferenced both before and after the addressing switch?这个是因为e位于UTOP以上,而在这上面的地址给予env_pgdir和kern_pgdir是一样的
当内核进行用户环境切换的时候,必须要保证旧的环境的寄存器值被保存起来以便之后恢复。这个过程是在哪里发生的?
是在
trapentry.S中*/.global _alltraps_alltraps:// make the stack look like a struct Trapframepushl %ds;pushl %es;pushal;// load GD_KD into %ds and %esmovl $GD_KD, %edxmovl %edx, %dsmovl %edx, %es// push %esp as an argument to trap()pushl %esp;call trap;
6. System Calls for Environment Creation
Unix系统提供了fork()系统调用作为进程创建原语(process creation primitive)。Unix的fork()拷贝调用进程(父进程)的整个进程空间以创建子进程,这种情况下父子进程之间唯一可观察的区别就是他们的进程ID分别为pid和ppid(可以通过getpid()和getppid()查看)。在父进程中,fork()函数返回子进程的ID,而在子进程中返回0.
默认情况下,每一个进程都有其私有的地址空间,而且任意一个进程对于内核的修改对于其他进程而言都是不可见的。
现在我们将实现一个jos系统调用原语以使用户创建新的用户模式环境。完成这些这些系统调用。我们将实现以下的系统调用函数:
sys_exofork():创建一个几乎为空白状态的新环境:这个地址空间没有任何用户部分映射,也无法运行。新环境将会有和父亲环境完全一致的寄存器状态,而在父亲环境执行该系统调用后会返回新创建环境的envid_t(如果创建失败则返回错误码),子环境返回0。由于子环境最初被标记为不可执行,故在子环境中sys_exofork()会一直wait,直到父环境显式标记子环境为可执行,其才会在子环境中返回。sys_env_set_status():设置指定的环境的状态为ENV_RUNNABLE或者RUN_NOT_RUNNABLE。这个系统调用通常在一个新环境的地址空间和寄存器状态完全初始化完成之后将其标记为可执行。sys_page_alloc():分配一页的物理内存然后将其映射到特定环境的地址空间的给定虚拟地址。sys_page_map():将一个页映射关系(不是页的具体内容)从一个环境的地址空间拷贝到另一个环境的地址空间。实现共享内存。sys_page_unmap():将给定环境的虚拟地址页面解除映射。
上述所有系统调用函数都需要接受一个环境ID,jos的内核支持了环境号0代表当前环境。在kern/env.c中的envid2env()实现了这种映射。
我们在user/dumpfork.c中提供了和原始Unix 系统中fork()函数类似的函数实现。测试程序用上述系统调用创建并运行一个当前地址空间拷贝的子进程,然后两个环境使用sys_yield()来回切换。父进程在10次迭代后退出;子进程在20次迭代后退出。
exercise 7
实现上述在kern/syscall.c中的系统调用函数,确保syscall()可以调用它们。你可能需要用到kern/pmap.c和kern/env.c中的一些函数,尤其是envid2env()。
现在你使用envid2env()的时候,将checkperm参数设置为1,确保当你的一些系统调用参数无效的时候会返回-E_INVAL。使用user/dumpfork.c测试你实现的这些系统调用。
实现sys_exofork()
首先从dumpfork开始,可以找到sys_exofork的原始定义
- 通过int2中断进入
trapentry.s - 根据syscall进入
trap_dispatch()
// This must be inlined. Exercise for reader: why?static inline envid_t __attribute__((always_inline))sys_exofork(void){envid_t ret;asm volatile("int %2": "=a" (ret): "a" (SYS_exofork), "i" (T_SYSCALL));return ret;}
- 在trap_dispatch()中会保存当前寄存器信息,然后执行syscall
随后我们根据代码提示实现sys_exofork
static envid_tsys_exofork(void){struct Env *child_env;int eno;// if alloc env error// directly returnif ((eno = env_alloc(&child_env,curenv->env_id) < 0)) {return eno;}// same register state as parentchild_env->env_tf = thiscpu->cpu_env->env_tf;// status is not runchild_env->env_status = ENV_NOT_RUNNABLE;// child_env return 0child_env->env_tf.tf_regs.reg_eax = 0;// father env return child env_idreturn child_env->env_id;}
实现sys_env_set_status函数
首先找到这个函数的定义.
需要两个参数分别为env_id和对应的状态
int sys_env_set_status(envid_t env, int status);
env_set就是把指定的env的状态设置成传入的status参数,只不过要注意一些条件判断
static intsys_env_set_status(envid_t envid, int status) {if((status != ENV_RUNNABLE) && (status != ENV_NOT_RUNNABLE)){return -E_INVAL;}struct Env *env;int eno = envid2env(envid,&env,1);if (eno < 0) {return -E_BAD_ENV;;}env->env_status = status;return 0;}
实现sys_page_alloc()函数
基本按照提示来就可以了。但是有两个要注意的点
就是如何判断是否是页对齐点
PGOFF(va) != 0 // 来判断是否是页对奇的
PTE_SYSCALL
// Flags in PTE_SYSCALL may be used in system calls. (Others may not.)#define PTE_SYSCALL (PTE_AVAIL | PTE_P | PTE_W | PTE_U)
也就是说如果下面的式子成立的话,则出现了PTE_SYSCALL之外的位为1.
if (perm & (~PTE_SYSCALL))
// Allocate a page of memory and map it at 'va' with permission// 'perm' in the address space of 'envid'.// The page's contents are set to 0.// If a page is already mapped at 'va', that page is unmapped as a// side effect.//// perm -- PTE_U | PTE_P must be set, PTE_AVAIL | PTE_W may or may not be set,// but no other bits may be set. See PTE_SYSCALL in inc/mmu.h.//// Return 0 on success, < 0 on error. Errors are:// (1) -E_BAD_ENV if environment envid doesn't currently exist,// or the caller doesn't have permission to change envid.// (2) -E_INVAL if va >= UTOP, or va is not page-aligned.// (3) -E_INVAL if perm is inappropriate (see above).// (4) -E_NO_MEM if there's no memory to allocate the new page,// or to allocate any necessary page tables.static intsys_page_alloc(envid_t envid, void *va, int perm){// Hint: This function is a wrapper around page_alloc() and// page_insert() from kern/pmap.c.// Most of the new code you write should be to check the// parameters for correctness.// If page_insert() fails, remember to free the page you// allocated!// LAB 4: Your code here.//(1)struct Env *env;int eno;if ((eno = envid2env(envid,&env,1) < 0)) {return -E_BAD_ENV;}// (2)if((uintptr_t)va >= UTOP || PGOFF(va) != 0){return -E_INVAL;}// (3)if(!(perm & PTE_U) || !(perm & PTE_P) || (perm & (~PTE_SYSCALL))){return -E_INVAL;}// (4)struct PageInfo *page;page = page_alloc(ALLOC_ZERO);if(page == NULL){return -E_NO_MEM;}eno = page_insert(env->env_pgdir,page,va,perm);if (eno < 0) {page_free(page);return -E_NO_MEM;}return 0;}
实现sys_page_map函数
基本上按照提示也是比较好实现的
- 搞清楚page_map的功能就是把对应环境的虚拟地址和指定环境的虚拟地址相对应
static intsys_page_map(envid_t srcenvid, void *srcva,envid_t dstenvid, void *dstva, int perm){// Hint: This function is a wrapper around page_lookup() and// page_insert() from kern/pmap.c.// Again, most of the new code you write should be to check the// parameters for correctness.// Use the third argument to page_lookup() to// check the current permissions on the page.// LAB 4: Your code here.// case 1 -E_BAD_ENVstruct Env *srcv, *dstv;if (envid2env(srcenvid,&srcv,1) < 0 || envid2env(dstenvid,&dstv,1) < 0) {return -E_BAD_ENV;}// case 2 -E_INVALif (((uintptr_t)srcva >= UTOP) || ((uintptr_t)dstva >= UTOP) ||(PGOFF(srcva) != 0) || (PGOFF(dstva) != 0)) {return -E_INVAL;}// case 3 -E_INVALstruct PageInfo *srcpage;pte_t * scrpte_ptr;// use page look up to get source page and corresponding pte_t *if ((srcpage = page_lookup(srcv->env_pgdir, srcva, &scrpte_ptr)) ==NULL) {// srcva not mapped in srcenvid's address spacereturn -E_INVAL;}if ((perm & (~PTE_SYSCALL)) || !(perm & PTE_U) || !(perm & PTE_P)) {return -E_INVAL;}if ((perm & PTE_W) && (!((*scrpte_ptr) & PTE_W))) {return -E_INVAL;}if (page_insert(dstv->env_pgdir, srcpage, dstva, perm) < 0) {return -E_NO_MEM;}return 0;}
实现sys_page_unmap函数
static int sys_page_unmap(envid_t envid, void *va) {struct Env *curE;int eno;if ((eno = envid2env(envid,&curE,1) < 0)) {return -E_BAD_ENV;}if ((uintptr_t)va >= UTOP || PGOFF(va) != 0){return -E_INVAL;}page_remove(curE->env_pgdir,va);return 0;}
PartA+: 回顾parA
emmmpartA写了这么多代码,居然才5分。但是在写了几个关于创建新环境的函数之后,相信大家都好奇之间的调用关系是怎么样的。是在哪里执行了这些函数。以及之前的多cpu切换流程的梳理
1. 多cpu的初始化和启动
关于BSP和AP的说明可以参考x86-64的多核初始化
关于Jos多cpu切换的流程分析多参考于Xv6学习小记(二)——多核启动
感谢各位大佬们的无私分享。
1. 首先我们要从系统如何检测CPU的个数开始说起
系统首先进行查找MP浮点结构:
1.如果BIOS的EBDA已经定义,则在其中的第一K字节中进行查找,否则到2;
2.若EBDA未被定义,则在系统基本内存的最后一K字节中寻找;
3.在BIOS ROM里的0xF0000到0xFFFFF的地址空间中寻找。
关于内存低1MB的详细信息见下图

对应于mpsearch函数
如果EBDA(Extended BIOS Data Area,扩展BIOS数据区)不存在,BDA[0x0E]和BDA[0x0F]的值为0;如果EBDA存在,其段地址被保存在BDA[0x0E]和BDA[0x0F]中,其中BDA[0x0E]保存EBDA段地址的低8位,BDA[0x0F]保存EDBA段地址的高8位,所以(BDA[0x0F]<<8) | BDA[0x0E]就表示了EDBA的段地址,将段地址左移4位即为EBDA的物理地址。如下面的代码所示。
p <<= 4
static struct mp *mpsearch(void){uint8_t *bda;uint32_t p;struct mp *mp;static_assert(sizeof(*mp) == 16);// The BIOS data area lives in 16-bit segment 0x40.bda = (uint8_t *) KADDR(0x40 << 4);// [MP 4] The 16-bit segment of the EBDA is in the two bytes// starting at byte 0x0E of the BDA. 0 if not present.if ((p = *(uint16_t *) (bda + 0x0E))) {p <<= 4; // Translate from segment to PAif ((mp = mpsearch1(p, 1024))) // 在EBDA的前1kb个字节中查找return mp;} else {// The size of base memory, in KB is in the two bytes// starting at 0x13 of the BDA.p = *(uint16_t *) (bda + 0x13) * 1024; // 得到系统内存的末尾边界地址if ((mp = mpsearch1(p - 1024, 1024)))return mp;}return mpsearch1(0xF0000, 0x10000); // 在rom area中寻找}
关于mpsearch1函数
该函数将_MP_这个长度为4的字符串作为了MP浮点结构的标识,匹配到此字符串即找到了MP浮点结构,然后返回指向该MP浮点结构的指针。
// Look for an MP structure in the len bytes at physical address addr.static struct mp *mpsearch1(physaddr_t a, int len){struct mp *mp = KADDR(a), *end = KADDR(a + len);for (; mp < end; mp++)if (memcmp(mp->signature, "_MP_", 4) == 0 &&sum(mp, sizeof(*mp)) == 0)return mp;return NULL;}
在mp_init函数先执行了mpconfig方法返回了MP配置表头的虚拟地址
mpconfig函数
- 通过
mpsearch获得指向mp浮点结构的指针m - 随后通过m指针访问到mp配置表头,并将其转换成虚拟地址
static struct mpconf *mpconfig(struct mp **pmp){struct mpconf *conf;struct mp *mp;if ((mp = mpsearch()) == 0)return NULL;if (mp->physaddr == 0 || mp->type != 0) {cprintf("SMP: Default configurations not implemented\n");return NULL;}conf = (struct mpconf *) KADDR(mp->physaddr);if (memcmp(conf, "PCMP", 4) != 0) {cprintf("SMP: Incorrect MP configuration table signature\n");return NULL;}if (sum(conf, conf->length) != 0) {cprintf("SMP: Bad MP configuration checksum\n");return NULL;}if (conf->version != 1 && conf->version != 4) {cprintf("SMP: Unsupported MP version %d\n", conf->version);return NULL;}if ((sum((uint8_t *)conf + conf->length, conf->xlength) + conf->xchecksum) & 0xff) {cprintf("SMP: Bad MP configuration extended checksum\n");return NULL;}*pmp = mp;return conf;}
MP配置表头的结构体如下:
struct mpconf { // configuration table headeruchar signature[4]; // 标志为"PCMP"ushort length; // MP配置表的长度uchar version; // [14]uchar checksum; // all bytes must add up to 0uchar product[20]; // product iduint *oemtable; // OEM table pointerushort oemlength; // OEM table lengthushort entry; // 入口数uint *lapicaddr; // local APIC的地址ushort xlength; // extended table lengthuchar xchecksum; // extended table checksumuchar reserved;};
接下来来看mpinit方法
程序在mpinit()方法中遍历MP扩展部分通过判断入口类型来进行相应操作,如判断入口类型为MPPROC时则将ncpu加1,部分代码如下
bootcpu = &cpus[0];if ((conf = mpconfig(&mp)) == 0) //获得mp表头的指针return;ismp = 1;lapicaddr = conf->lapicaddr;// 遍历mp表的条目for (p = conf->entries, i = 0; i < conf->entry; i++) {switch (*p) {// 如果是处理器case MPPROC:proc = (struct mpproc *)p;if (proc->flags & MPPROC_BOOT) //判断此CPU是否为主引导CPU(BSP)bootcpu = &cpus[ncpu]; //若是BSP,将此CPU设为第0个CPUif (ncpu < NCPU) {cpus[ncpu].cpu_id = ncpu; //给每个CPU设置ID并存入cpus数组中ncpu++; //CPU个数+1} else {cprintf("SMP: too many CPUs, CPU %d disabled\n",proc->apicid);}p += sizeof(struct mpproc);continue;case MPBUS:case MPIOAPIC:case MPIOINTR:case MPLINTR:p += 8;continue;default:cprintf("mpinit: unknown config type %x\n", *p);ismp = 0;i = conf->entry;}}bootcpu->cpu_status = CPU_STARTED;if (!ismp) {// Didn't like what we found; fall back to no MP.ncpu = 1;lapicaddr = 0;cprintf("SMP: configuration not found, SMP disabled\n");return;}cprintf("SMP: CPU %d found %d CPU(s)\n", bootcpu->cpu_id, ncpu);}
2. 随后执行lapic_init函数
80486DX在1990年上市,其引入了SMP的概念,即多CPU(注意不是多核)。Intel为了适应SMP提出APIC(Advanced Programmable Interrupt Controller,高级中断控制器)的新技术。APIC 由两部分组成,一个称为LAPIC(Local APIC,本地高级中断控制器),一个称为IOAPIC(I/O APIC,I/O 高级中断控制器)。前者位于CPU中,在SMP 平台,每个CPU 都有一个自己的LAPIC(后期多核后,每个逻辑核都有个LAPIC)。后者通常位于外部设备芯片上,例如南桥上。像PIC 一样,连接各个产生中断的设备。而IOAPIC和LAPIC通过APIC Bus连接在一起。如图:
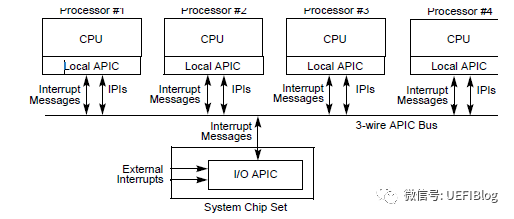
因此这里我们要做的就是初始每个cpu的Local APIC。同时多cpu的中断流程如下
- 一个 CPU 给其他 CPU 发送中断的时候, 就在自己的 ICR 中, 放中断向量和目标LAPIC ID, 然后通过总线发送到对应 LAPIC,
- 目标 LAPIC 根据自己的 LVT(Local Vector Table) 来对不同的中断进行处理.
通过lab中实现的
mmio_map_region函数将lapicaddr映射到虚拟地址.大小为4kbvoidllapic_init(void){if (!lapicaddr)return;// lapicaddr is the physical address of the LAPIC's 4K MMIO region. Map it in to virtual memory so we can access it.lapic = mmio_map_region(lapicaddr, 4096);
下面的函数大量用到
lapicw这里先看一下其实就是设置lvt表。具体关于apic的讨论可以看这里XV6 的中断和系统调用
static voidlapicw(int index, int value){lapic[index] = value;lapic[ID]; // wait for write to finish, by reading}
下面的代码就是对于LVT表的初始化操作。深究可能仔细看看那这个xv6中文文档
// Enable local APIC; set spurious interrupt vector.lapicw(SVR, ENABLE | (IRQ_OFFSET + IRQ_SPURIOUS));// The timer repeatedly counts down at bus frequency// from lapic[TICR] and then issues an interrupt.// If we cared more about precise timekeeping,// TICR would be calibrated using an external time source.lapicw(TDCR, X1);lapicw(TIMER, PERIODIC | (IRQ_OFFSET + IRQ_TIMER)); // 这会让lapic周期性地在iRQ_TIMER产生中断lapicw(TICR, 10000000);// Leave LINT0 of the BSP enabled so that it can get// interrupts from the 8259A chip.//// According to Intel MP Specification, the BIOS should initialize// BSP's local APIC in Virtual Wire Mode, in which 8259A's// INTR is virtually connected to BSP's LINTIN0. In this mode,// we do not need to program the IOAPIC.if (thiscpu != bootcpu)lapicw(LINT0, MASKED);// Disable NMI (LINT1) on all CPUslapicw(LINT1, MASKED);// Disable performance counter overflow interrupts// on machines that provide that interrupt entry.if (((lapic[VER]>>16) & 0xFF) >= 4)lapicw(PCINT, MASKED);// Map error interrupt to IRQ_ERROR.lapicw(ERROR, IRQ_OFFSET + IRQ_ERROR);// Clear error status register (requires back-to-back writes).lapicw(ESR, 0);lapicw(ESR, 0);// Ack any outstanding interrupts.lapicw(EOI, 0);// Send an Init Level De-Assert to synchronize arbitration ID's.lapicw(ICRHI, 0);lapicw(ICRLO, BCAST | INIT | LEVEL);while(lapic[ICRLO] & DELIVS);// Enable interrupts on the APIC (but not on the processor).lapicw(TPR, 0);}
3. boot_aps函数
随后进入boot_aps函数
- 先把
entryother.S的代码拷贝到以0x7000起始的这块内存。 - 然后逐步启动所有的ap cpu
- 为每一个ap分配自己的内核栈
- 通过
lapic_startap函数向这个CPU发中断,让此CPU执行boot程序
static voidboot_aps(void){extern unsigned char mpentry_start[], mpentry_end[];void *code;struct CpuInfo *c;// Write entry code to unused memory at MPENTRY_PADDRcode = KADDR(MPENTRY_PADDR);memmove(code, mpentry_start, mpentry_end - mpentry_start);// Boot each AP one at a timefor (c = cpus; c < cpus + ncpu; c++) {if (c == cpus + cpunum()) {// We've started already.cprintf("cpu has already startd(id): %08x\n", c->cpu_id);continue;}// Tell mpentry.S what stack to usempentry_kstack = percpu_kstacks[c - cpus] + KSTKSIZE;// Start the CPU at mpentry_startcprintf("cpu start(id): %08x\n", c->cpu_id);lapic_startap(c->cpu_id, PADDR(code));// Wait for the CPU to finish some basic setup in mp_main()while(c->cpu_status != CPU_STARTED);}}
lapic_startap函数
outb指令
用于向指定端口写入1字节的数据
static inline voidoutb(int port, uint8_t data){asm volatile("outb %0,%w1" : : "a" (data), "d" (port));}
看不懂下面这部分。。
voidlapic_startap(uint8_t apicid, uint32_t addr){int i;uint16_t *wrv;// "The BSP must initialize CMOS shutdown code to 0AH// and the warm reset vector (DWORD based at 40:67) to point at// the AP startup code prior to the [universal startup algorithm]."outb(IO_RTC, 0xF); // offset 0xF is shutdown codeoutb(IO_RTC+1, 0x0A);wrv = (uint16_t *)KADDR((0x40 << 4 | 0x67)); // Warm reset vectorwrv[0] = 0;wrv[1] = addr >> 4;
- BSP通过向AP逐个发送中断来启动AP,首先发送INIT中断来初始化AP,然后发送SIPI中断来启动AP,发送中断使用的是写ICR寄存器的方式
// 发送INIT中断以重置APlapicw(ICRHI, apicid<<24); //将目标CPU的ID写入ICR寄存器的目的地址域中lapicw(ICRLO, INIT | LEVEL | ASSERT); //在ASSERT的情况下将INIT中断写入ICR寄存器microdelay(200); //等待200mslapicw(ICRLO, INIT | LEVEL); //在非ASSERT的情况下将INIT中断写入ICR寄存器microdelay(100); // 等待100ms (INTEL官方手册规定的是10ms,但是由于Bochs运行较慢,此处改为100ms)//INTEL官方规定发送两次startup IPI中断for(i = 0; i < 2; i++){ lapicw(ICRHI, apicid<<24); //将目标CPU的ID写入ICR寄存器的目的地址域中 lapicw(ICRLO, STARTUP | (addr>>12));//将SIPI中断写入ICR寄存器的传送模式域中,将启动代码写入向量域中 microdelay(200); //等待200ms}
ICR寄存器说明
中断命令寄存器(ICR)是一个 64 位本地 APIC寄存器,允许运行在处理器上的软件指定和发送处理器间中断(IPI)给系统中的其它处理器。发送IPI时,必须设置ICR 以指明将要发送的 IPI消息的类型和目的处理器或处理器组。一般情况下,ICR寄存器的物理地址为0xFEE00300。
SIPI是一个特殊的IPI。典型情况下,在发送SIPI时,ICR的向量域中指向一个启动例程,本例中即将entryother的代码地址写入了ICR的向量域,以启动AP。
4. 运行boot函数
通过上面的分析我们可以知道是在lapicw(ICRLO, STARTUP | (addr>>12))之后执行了启动代码
在启动汇编代码的最后我们发现了对于mp_main函数的调用
- 在
mp_main函数中我们初始化了每一个ap的lapic和env以及trap - 然后通知bsp可以进行下一个ap的唤醒了
voidmp_main(void){// We are in high EIP now, safe to switch to kern_pgdirlcr3(PADDR(kern_pgdir));cprintf("SMP: CPU %d starting\n", cpunum());lapic_init();env_init_percpu();trap_init_percpu();xchg(&thiscpu->cpu_status, CPU_STARTED); // tell boot_aps() we're up // 这里的BSP就可以被重新唤醒了// Now that we have finished some basic setup, call sched_yield()// to start running processes on this CPU. But make sure that// only one CPU can enter the scheduler at a time!//// Your code here:lock_kernel();sched_yield();}
2. 多cpu的切换
我们以CPUS = 4为参数,执行qemu
在我们完成了对一个bsp和3个ap的设置之后。我们在实验中创建了三个user environment。来测试cpu切换
其中在user environment做了这样的事情
是非常简单的代码,输出当前环境之后切换环境。这里的sys_yied系统调用会执行我们上面实现的sched_yield()函数
#include <inc/lib.h>voidumain(int argc, char **argv){int i;cprintf("Hello, I am environment %08x.\n", thisenv->env_id);for (i = 0; i < 5; i++) {sys_yield();cprintf("Back in environment %08x, iteration %d.\n",thisenv->env_id, i);}cprintf("All done in environment %08x.\n", thisenv->env_id);}
1. Sched_yield函数
在进入这个函数之前我们先在shced_yield设一个断点。看一下在run 第一个用户环境之前的状态

可以发现我们已经创建了三个env并且启动了4个cpu。这里是在envs中找一个来在当前cpu执行
voidsched_yield(void){size_t start = 0;if (curenv) {start = ENVX(curenv->env_id) + 1;}for (size_t i = 0; i < NENV; i++) {size_t index = (start + i) % NENV;if (envs[index].env_status == ENV_RUNNABLE) {env_run(&envs[index]);}}if(curenv && curenv->env_status == ENV_RUNNING) {env_run(curenv);}// sched_halt never returnssched_halt();}
2. 加锁机制下的切换过程
- 在bsp中我们启动aps的过程中会在执行
boot_aps之前把内核锁住 - 这样当ap想要进入内核的时候就会pause住
- 当bsp内执行完第一个用户环境后就会把它的锁释放
- 这样pause在
mp_main的ap就会获得锁。然后执行sched_yiedld去看一下是否有可以run的env - 而在用户环境我们执行
sys_yied系统调用可以主动调用sched_yiedld

MIT6.828 Preemptive Multitasking(上)的更多相关文章
- MIT-6.828-JOS-lab4:Preemptive Multitasking
Lab 4: Preemptive Multitasking tags: mit-6.828, os 概述 本文是lab4的实验报告,主要围绕进程相关概念进行介绍.主要将四个知识点: 开启多处理器.现 ...
- MIT6.828 Lab4 Preemptive Multitasking(下)
Lab4 Preemptive Multitasking(下) lab4的第二部分要求我们实现fork的cow.在整个lab的第一部分我们实现了对多cpu的支持和再多系统环境中的切换,但是最后分析的时 ...
- MIT 6.828 Lab04 : Preemptive Multitasking
目录 Part A:Multiprocessor Support and Cooperative Multitasking Multiprocessor Support 虚拟内存图 Exercise ...
- MIT6.828 JOS系统 lab2
MIT6.828 LAB2:http://pdos.csail.mit.edu/6.828/2014/labs/lab2/ LAB2里面主要讲的是系统的分页过程,还有就是简单的虚拟地址到物理地址的过程 ...
- MIT6.828 虚拟地址转化为物理地址——二级分页
这个分页,主要是在mit6.828的lab2的背景下来说的. Mit6.828 Lab2:http://pdos.csail.mit.edu/6.828/2014/labs/lab2/ lab2主要讲 ...
- MIT6.828课程JOS在macOS下的环境配置
本文将介绍如何在macOS下配置MIT6.828 JOS实验的环境. 写JOS之前,在网上搜寻JOS的开发环境,很多博客和文章都提到"不是32位linux就不好配置,会浪费大量时间在配置环境 ...
- MIT6.828准备:MacOS下搭建xv6和risc-v环境
本文介绍在MacOS下搭建Mit6.828/6.S081 fall2019实验环境的详细过程,包括riscv工具链.qemu和xv6,对于Linux系统同样可以参考. 介绍 只有了解底层原理才能写好上 ...
- mit-6.828 Lab Tools
Lab Tools 目录 Lab Tools 写在前面 GDB GNU GPL (通用公共许可证) QEMU ELF 可执行文件的格式 Verbose mode Makefile 写在前面 操作系统小 ...
- 【MIT6.828】centos7下使用Qemu搭建xv6运行环境
title:[MIT6.828]centos7下使用Qemu搭建xv6运行环境 date: "2020-05-05" [MIT6.828]centos7下搭建xv6运行环境 1. ...
随机推荐
- shell基础之exit,break,continue
exit代码: 1 #!/bin/bash 2 echo "Is it morning? Please answer yes or no." 3 read YES_OR_NO 4 ...
- Python3统计gitlab上的代码量
import threading import gitlab import xlwt #获取所有的user def getAllUsers(): usersli = [] client = gitla ...
- Centos7 LVM管理的逻辑卷根目录扩容和/var目录扩容
Centos7 LVM管理的逻辑卷根目录扩容 fdisk /dev/sdb #对新加磁盘进行分区操作pvcreate /dev/sdb1 #创建一个物理卷vgs #查看现有的卷组vgextend ce ...
- KEIL-C下数组指针与指针数组实验
http://blog.csdn.net/men_wen/article/details/52694069 第一个: 数组指针的小实验 用指针传递参数 结果: 第二个: 数组指针实验 定义一个指针 ...
- 【JVM进阶之路】十三:类加载过程
通过前面的学习,我们了解了Class文件的结构,在Class文件中描述的各类信息,最终都需要加载到虚拟机中之后才能被运行和使用. 接下来,我们开始学习JVM的类加载. 一个类从被加载到虚拟机内存中开始 ...
- 关于lua闭包导致引用无法释放内存泄露
最近项目存在严重的内存泄漏问题,每次切level 会增加20M无法释放的内存,翻遍了项目用了多个工具,查询资料等 发现项目中两种存在内存泄露的情况 1.lua闭包的不当使用,对比包的引用要及时 释放. ...
- 项目中添加lib依赖
Project Structure-->Artifacts
- GO学习-(12) Go语言基础之函数
Go语言基础之函数 函数是组织好的.可重复使用的.用于执行指定任务的代码块.本文介绍了Go语言中函数的相关内容. 函数 Go语言中支持函数.匿名函数和闭包,并且函数在Go语言中属于"一等公民 ...
- MongoDB学习笔记:快速入门
MongoDB学习笔记:快速入门 一.MongoDB 简介 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统.在高负载的情况下,添加更多的节点,可以保证服务器性能.M ...
- LATEX如何写多个条件推导式推出一个结论
用markdown写推导式的时候,不太好写,故做个笔记记录一下,插入 公式块 : \left. \begin{aligned} \left. \begin{aligned} \text{这里可以写文字 ...