数据分析之pandas模块
一、Series
类似于一位数组的对象,第一个参数为数据,第二个参数为索引(索引可以不指定,就默认用隐式索引)
Series(data=np.random.randint(1,50,(10,)))
Series(data=[1,2,3],index=('a','b','c'))
dic={'math':88,'chinese':99,'english':50}
Series(data=dic)
对于data来说,可以是列表、np数组、字典,当用字典时,字典的key会成为行索引
1,索引和切片
用中括号时,可以是显示索引,也可以是隐式索引
用句点符‘.’
用.loc[]时,只能有显示索引
用.iloc[]时,只能用隐式索引
2,属性

3,去重

4,加法
索引相同的加在一起,当索引不一致的项,就用NaN填充

5,数据清洗
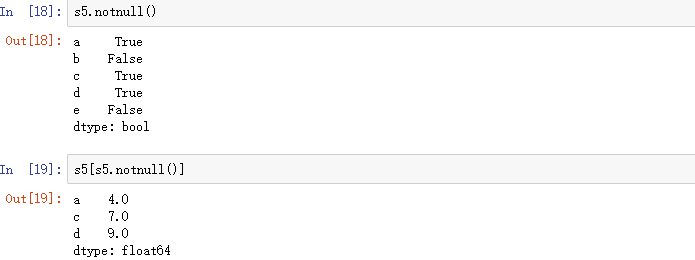
主要用isnull()判断值是否为空,notnull()判断值是否不为空,返回的都是值为bool型的Series,然后把它作为索引,就可以把为False的值给删除。
二、DataFrame
DataFrame是一个表格型的数据结构,DataFrame由一定顺序排列的多列数据组成,设计初衷是将Series的使用场景从一维拓展到多维,DataFrame既有行索引index,也有列索引columns,值values。
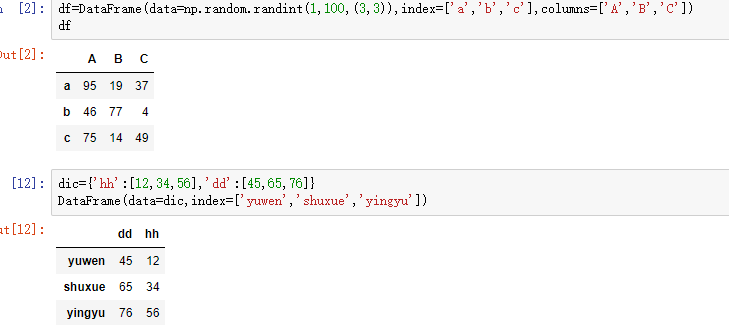
1,DataFrame的创建
最常用的方法是传递一个字典,以字典的key为列索引,以每一个key对应的值作为对应列的数据,所以值应该是个列表。还可以指定行索引,但不可以指定列索引。
2,索引和切片
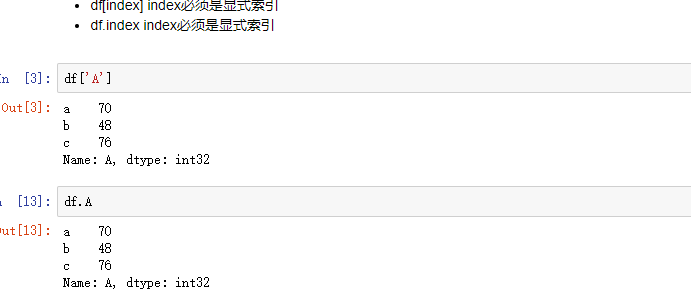
2.1 列索引
2.2 行索引
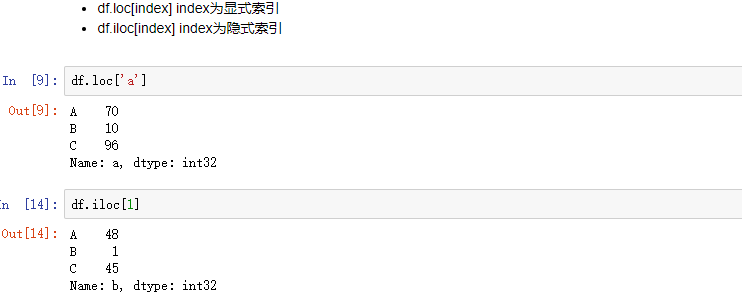
2.3 元素索引
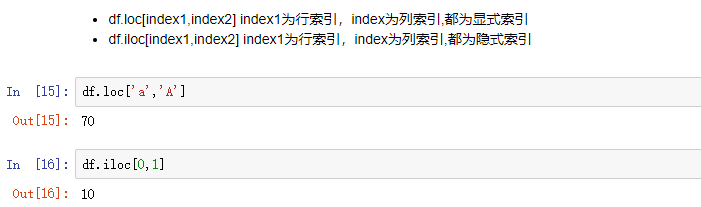
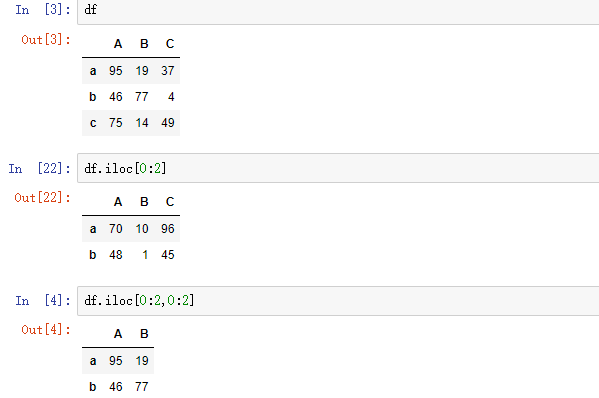
2.4 切片
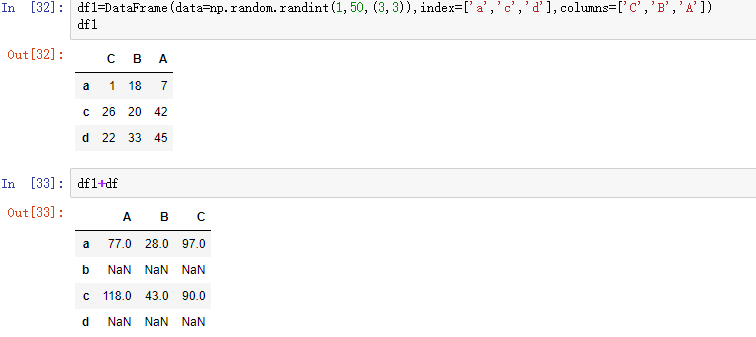
3,运算
要保证行索引和列索引都一致才能运算,否则用NaN填充
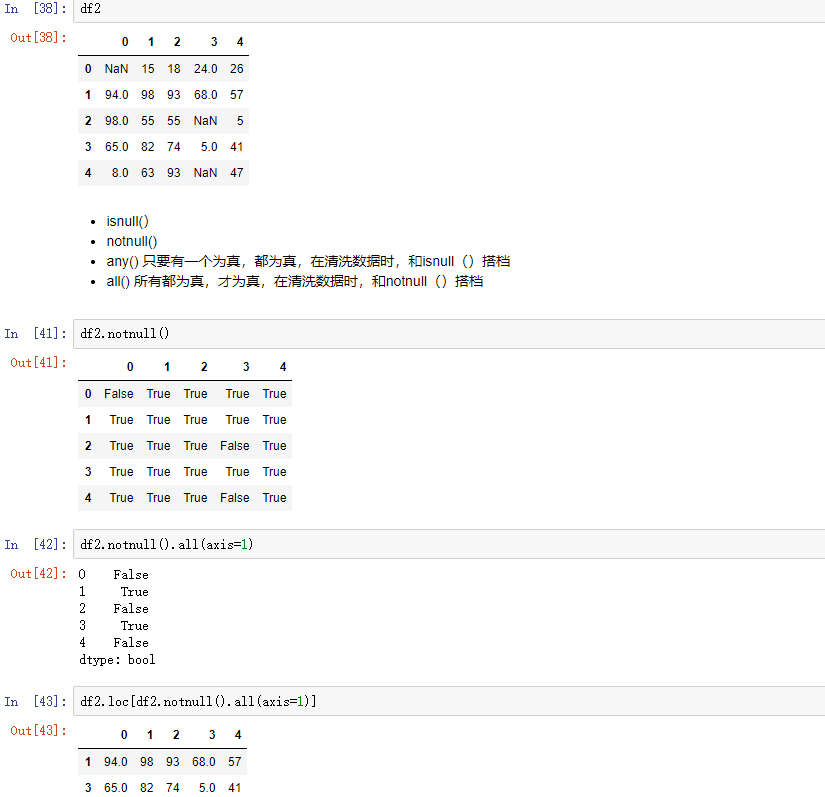
4,数据清洗
4.1 用isnull(),notnull(),any(),all()搭配使用,得到一组bool值的Series,然后把它作为索引,就可以清洗为False的行
4.2 还可以用drop(),drop系列的函数中,axis=1表示列,axis=0代表行,这和其他所有场景都是相反的
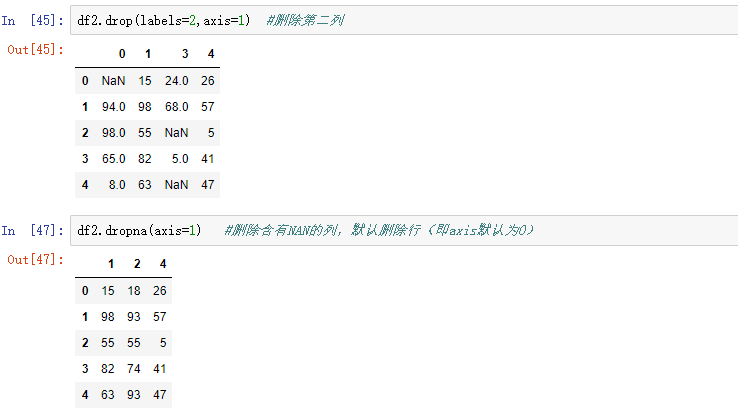
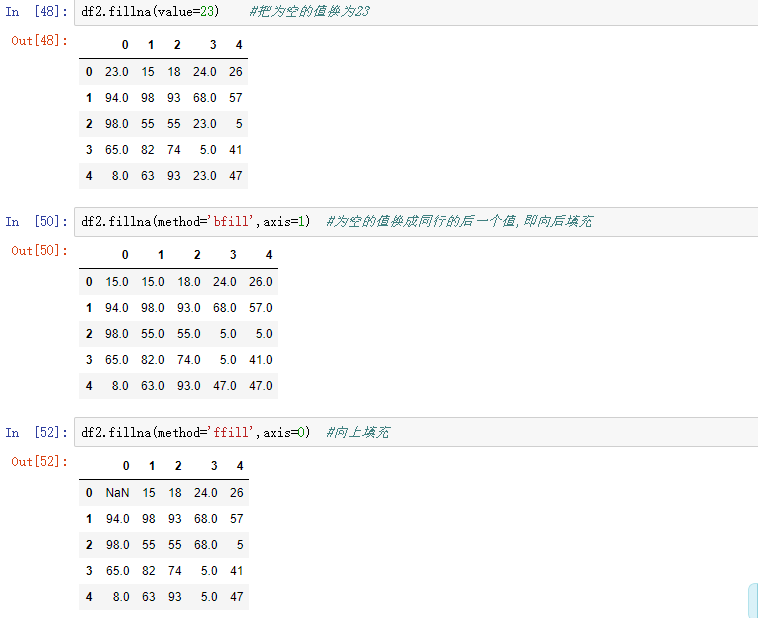
4.3 上面两种清洗方法都是删除整行或者,整列,有时是不允许这样子删除。我也可以用fillna()来把空值给填上。当inplace参数设为Ture时,表示修改后的数据映射到原数据,相当于修改原数据。
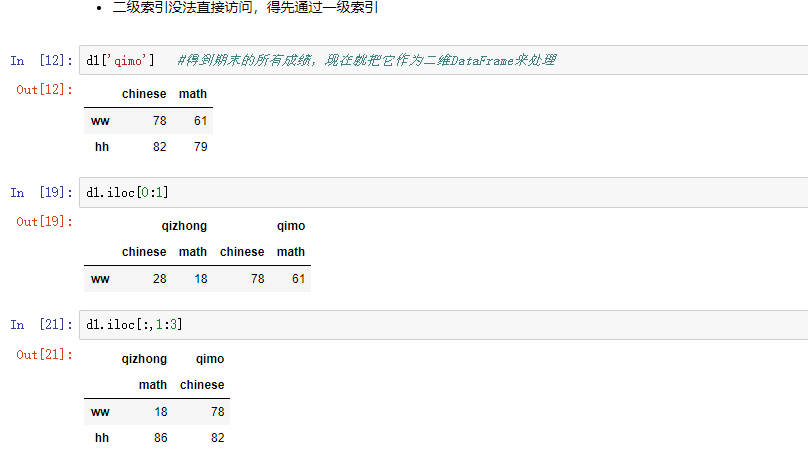
5,多层索引
5.1 隐式构造,最常用的方法是给DataFrame构造函数的index或columns传递两个或多个数组。

5.2 显式构造,用pd.MultiIndex.from_product

5.3 索引和切片
6,级联
pandas使用pd.concat(),与np.concatedate()类似,参数有些不同。
参数join:'outer'将所有的项进行级联(忽略匹配和不匹配),'inner'只会把匹配的项进行级联。

由于在以后的级联的使用很多,因此有一个函数append专门用于在后面添加。

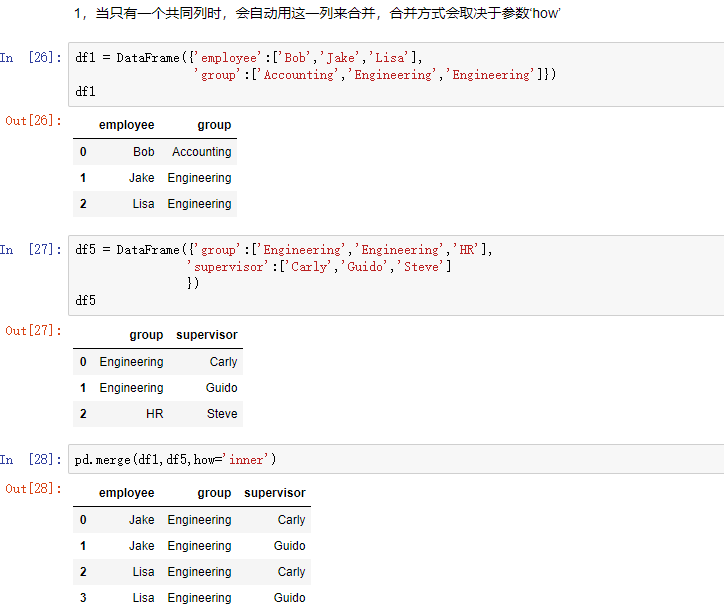
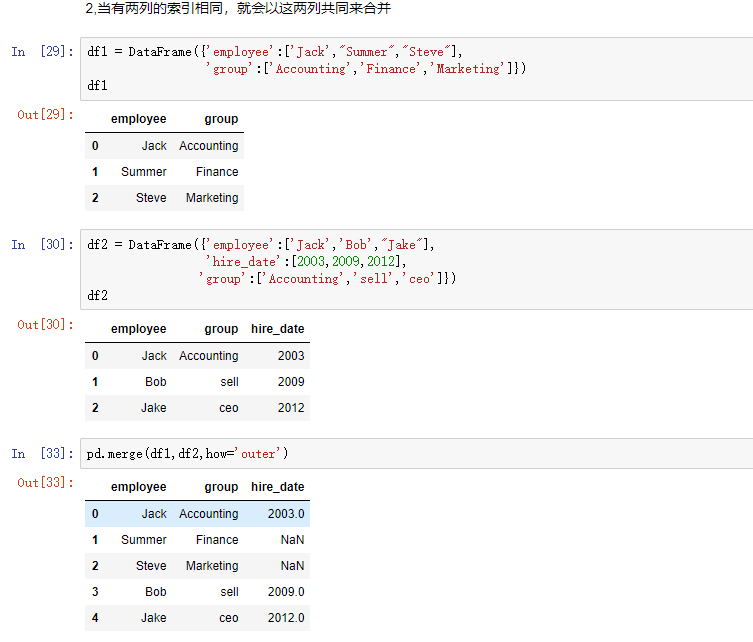
7,合并
合并用merge().它和数据库中的链表差不多
merge和concat的区别在于,merge需要依据某一共同的列进行合并。
在使用merge时,会自动根据两者相同的columns,来合并
每一列元素不要求一致
参数:
how:out取并集,inner取交集
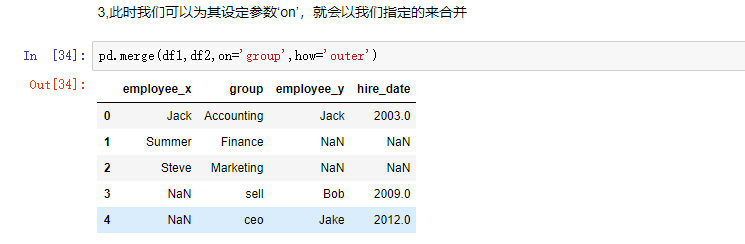
on:当两者有多列的名字相同时,我们想指定某一列进行合并,那我们就要把想指定列的名字赋给它
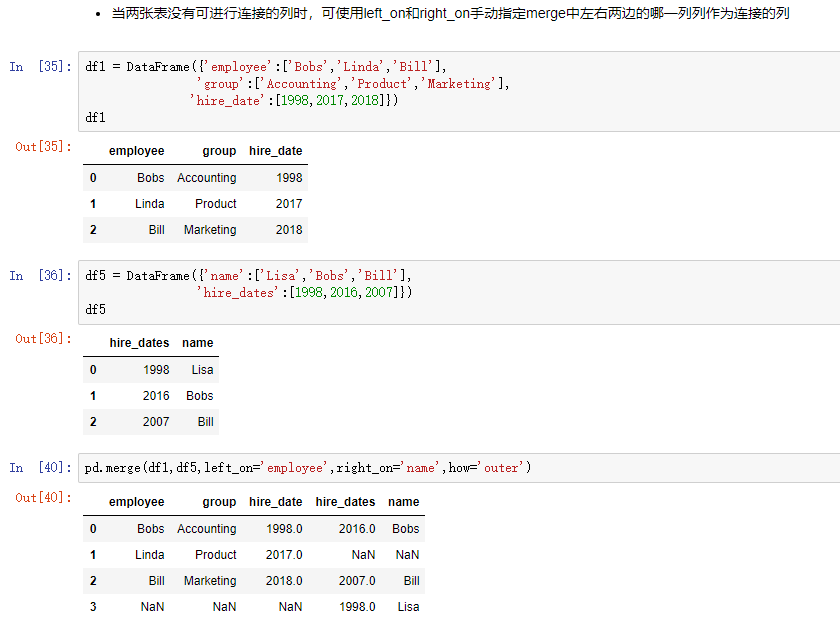
left_on和right_on:同时使用,当两者间没有共同的列名称时,可以分别指定
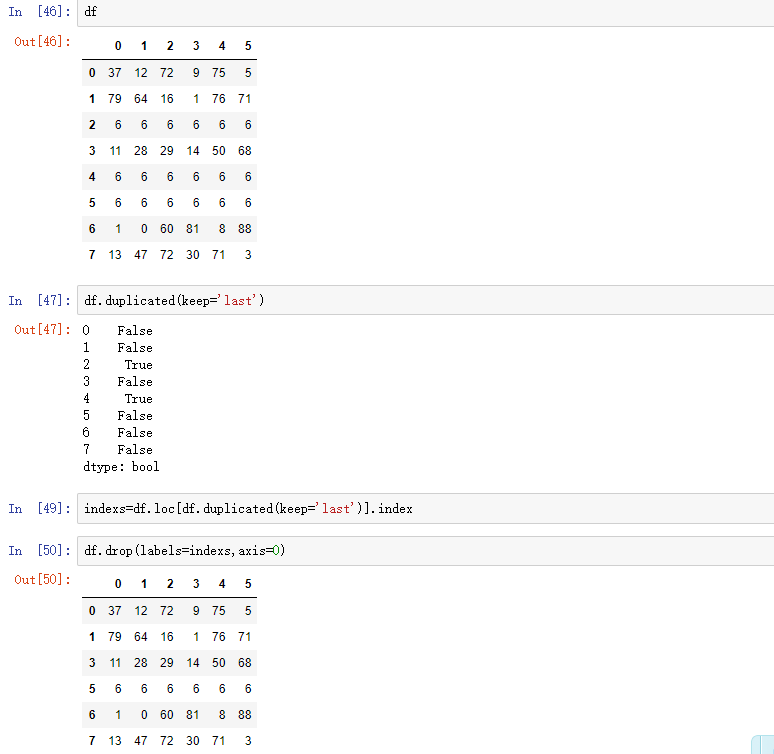
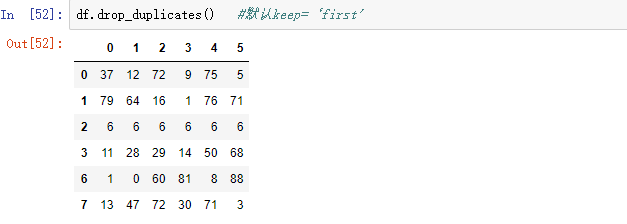
8,删除重复元素
使用duplicated()函数检测重复的行,返回元素为bool类型的Series对象,keep参数:指定保留哪一行重复的元素
还可以使用drop_duplicates(),这也是drop系列函数。
9 ,替换replace()
df.replace(to_replace=6,value='ww') #把所有的6换成‘ww’
df.replace(to_replace={2:6},value='ww') #把列索引为‘2’这列中‘6’换成‘ww’
df.replace(to_replace={2:6,3:9},value='ww')#把列索引为2中的6和列索引为3中的9换成‘ww’
df.replace(to_replace={6:'ww'}) #把所有的6换成‘ww’
df.replace(to_replace={6:'ww',1:'qq'}) #把所有的6换成‘ww’,把所有的1换成‘qq’
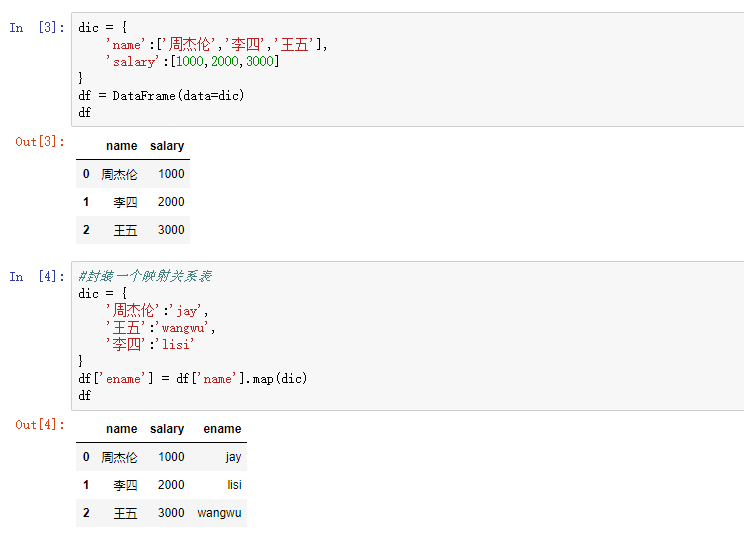
10,映射
10.1 用map()新建一列
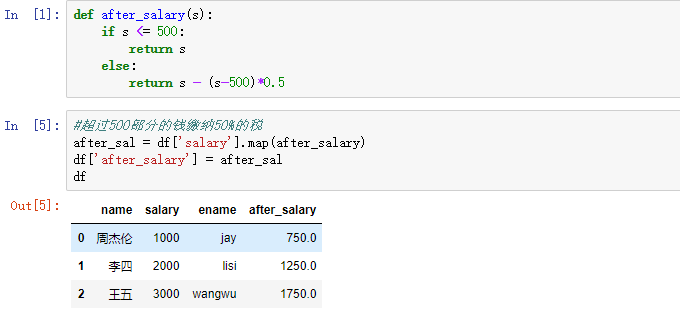
10.2 map()中还可以跟自定义函数
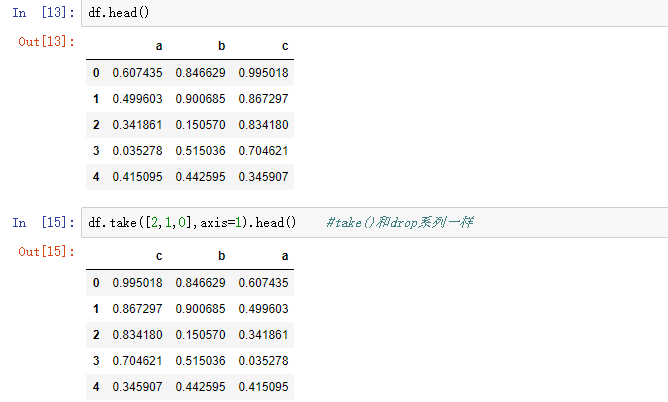
11,排序
使用take()函数排序,take接受一个索引列表,用数字表示,使得df会根据列表中索引的顺序进行排序
还可以使用np.random.permutation()函数随机排序,它返回的是一个一维的随机数组,比如参数为10,就会产生0到9这10个数字,不重复的,顺序还是打乱的。
当DataFrame规模足够大时,我们就可以借助它帮我们把数据打乱,然后用take函数实现随机抽样
values = df.take(np.random.permutation(1000),axis=0).take(np.random.permutation(3),axis=1).values
上面的代码是把1000行随机打乱,然后3列随机打乱
DataFrame(data=values)这就会映射会原数据,此时的原数据就是行和列都打乱的数据
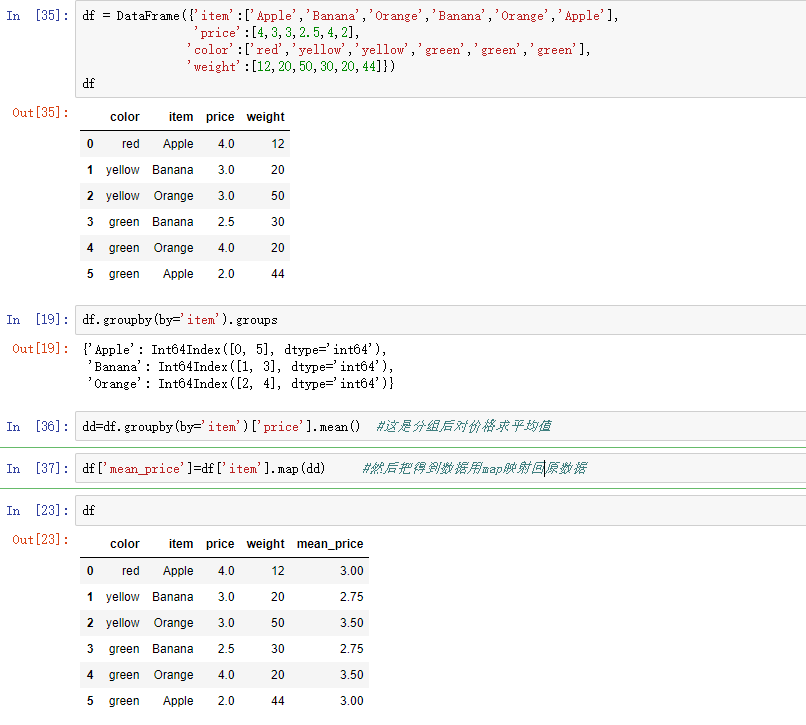
12,分类
分类就是把数据分为几个组,然后我可以对每个组进行操作,这和数据库分类是一样的效果。使用的是groupby()函数,参数by是分类的依据,groups属性可以查看分组情况
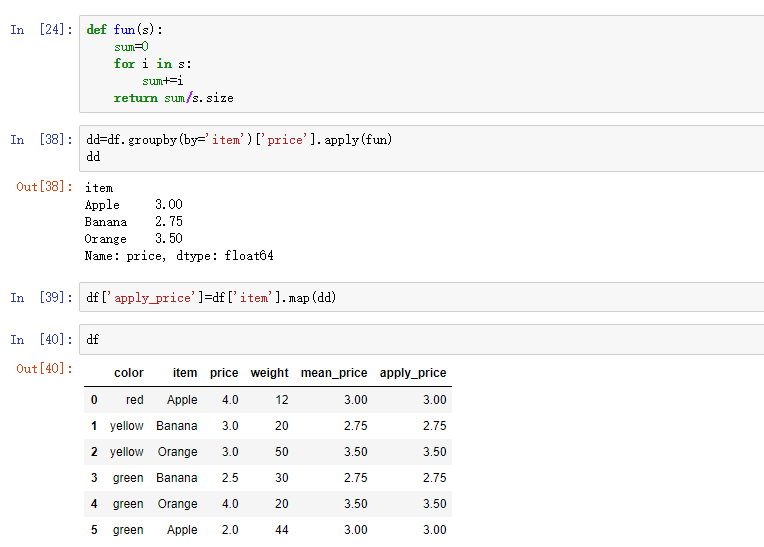
13,高级聚合
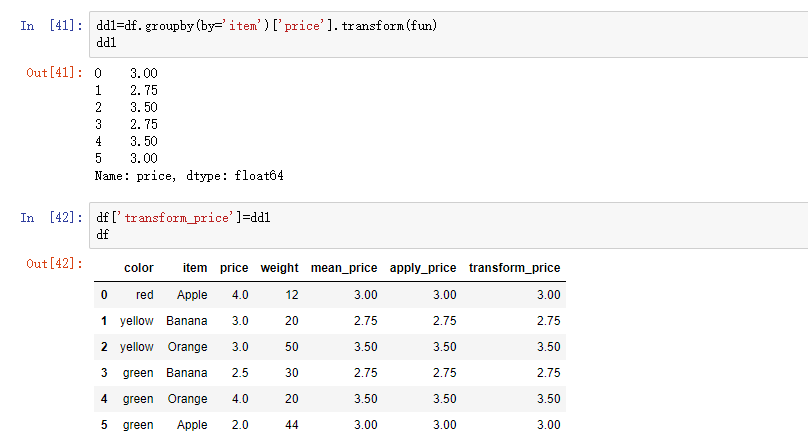
在分组后可以用sum(),mean()等聚合函数,其次还可以跟transform和apply函数,再给这两个函数传一个自定义函数,就可以是聚合函数以外的功能。
数据分析之pandas模块的更多相关文章
- 【Python 数据分析】pandas模块
上一节,我们已经安装了numpy,基于numpy,我们继续来看下pandas pandas用于做数据分析与数据挖掘 pandas安装 使用命令 pip install pandas 出现上图表示安装成 ...
- 关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题 ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析之pandas学习
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
- Pandas模块
前言: 最近公司有数据分析的任务,如果使用Python做数据分析,那么对Pandas模块的学习是必不可少的: 本篇文章基于Pandas 0.20.0版本 话不多说社会你根哥!开干! pip insta ...
- Python数据分析之pandas
Python中的pandas模块进行数据分析. 接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利 ...
- 4 pandas模块,Series类
对gtx图像进行操作,使用numpy知识 如果让gtx这张图片在竖直方向上进行颠倒. 如果让gtx这张图片左右颠倒呢? 如果水平和竖直方向都要颠倒呢? 如果需要将gtx的颜色改变一下呢 ...
随机推荐
- java多线程系列8 高级同步工具(2)CountDownLatch
CountDownLatch,计数器的初始值为线程的数量.每当一个线程完成了自己的任务后, 计数器的值就会减1.当计数器值到达0时,它表示所有的线程已经完成了任务, 然后在闭锁上等待的线程就可以恢复执 ...
- canvasJS
- 第34章:MongoDB-索引--用户管理
①用户管理 在MongoDB里面默认情况下只要是进行连接都可以不使用用户名与密码,因为要想让其起作用,则必须具备以下两个条件: ·条件一:服务器启动的时候打开授权认证: ·条件二:需要配置用户名和密码 ...
- PowerShell 使用.NetFramework
我们都知道,由于PowerShell是基于.NETFramework建立的所以它能够具备访问.NET的能力,因为.NET提供了庞大的数据类库,所以我们可以很好的使用PowerShell去完成一些Pow ...
- jsp和html的区别
html是超文本标记语言,只要有浏览器,就可以显示出来了. jsp是java server page就是在java服务器端的页面,需要通过jdk的编译才可以显示在客户端的浏览器上. 不仅如此,jsp还 ...
- Android开发 - 掌握ConstraintLayout(二)介绍
介绍 发布时间 ConstraintLayout是在2016的Google I/O大会上发布的,经过这么长时间的更新,现在已经非常稳定. 支持Android 2.3(API 9)+ 目前的Androi ...
- Android开发工程师文集-相关控件的讲解,五大布局
前言 大家好,给大家带来Android开发工程师文集-相关控件的讲解,五大布局的概述,希望你们喜欢 TextView控件 TextView控件有哪些属性: android:id->控件的id a ...
- vscode 开发 Java web 急速教程
1.确认在本机已安装 JAVA SDK 2.确认在本机已安装 maven 3.确认在本机已安装 tomcat 下面是我本机相关软件版本: java version "1.8.0_191&qu ...
- LabVIEW(十):数组和簇
一.数组 1.创建数组 (1).前面板右键>“数组.矩阵与簇”>数组. (2).前面板右键>(选择要添加的数组数据类型,比如创建数值数组)数值>将“数值输入控件”拖入数组中. ...
- 谈谈我们对userAgent的看法,为什么爬虫中需要userAgent?
首先打开浏览器,按 F12 进入控制台(Console),然后输入:navigator.userAgent,即可看到 UA.例如: 1 2 Mozilla/5.0 (Windows NT 10.0; ...