ARM64 __create_page_tables分析
span::selection, .CodeMirror-line > span > span::selection { background: #d7d4f0; }.CodeMirror-line::-moz-selection, .CodeMirror-line > span::-moz-selection, .CodeMirror-line > span > span::-moz-selection { background: #d7d4f0; }.cm-searching {background: #ffa; background: rgba(255, 255, 0, .4);}.cm-force-border { padding-right: .1px; }@media print { .CodeMirror div.CodeMirror-cursors {visibility: hidden;}}.cm-tab-wrap-hack:after { content: ""; }span.CodeMirror-selectedtext { background: none; }.CodeMirror-activeline-background, .CodeMirror-selected {transition: visibility 0ms 100ms;}.CodeMirror-blur .CodeMirror-activeline-background, .CodeMirror-blur .CodeMirror-selected {visibility:hidden;}.CodeMirror-blur .CodeMirror-matchingbracket {color:inherit !important;outline:none !important;text-decoration:none !important;}.CodeMirror-sizer {min-height:auto !important;}
-->
li {list-style-type:decimal;}.wiz-editor-body ol.wiz-list-level2 > li {list-style-type:lower-latin;}.wiz-editor-body ol.wiz-list-level3 > li {list-style-type:lower-roman;}.wiz-editor-body blockquote {padding: 0 12px;}.wiz-editor-body blockquote > :first-child {margin-top:0;}.wiz-editor-body blockquote > :last-child {margin-bottom:0;}.wiz-editor-body img {border:0;max-width:100%;height:auto !important;margin:2px 0;}.wiz-editor-body table {border-collapse:collapse;border:1px solid #bbbbbb;}.wiz-editor-body td,.wiz-editor-body th {padding:4px 8px;border-collapse:collapse;border:1px solid #bbbbbb;min-height:28px;word-break:break-word;box-sizing: border-box;}.wiz-hide {display:none !important;}
-->
/*
* Setup the initial page tables. We only setup the barest amount which is
* required to get the kernel running. The following sections are required:
* - identity mapping to enable the MMU (low address, TTBR0)
* - first few MB of the kernel linear mapping to jump to once the MMU has
* been enabled
*/
__create_page_tables:
mov x28, lr
* Invalidate the idmap and swapper page tables to avoid potential
* dirty cache lines being evicted.
*/
adrp x0, idmap_pg_dir
adrp x1, swapper_pg_end
sub x1, x1, x0
bl __inval_dcache_area
/*
* Invalidate the idmap and swapper page tables to avoid potential
* dirty cache lines being evicted.
*/
adrp x0, idmap_pg_dir
adrp x1, swapper_pg_end
sub x1, x1, x0
bl __inval_dcache_area
. = ALIGN(PAGE_SIZE);
idmap_pg_dir = .;
. += IDMAP_DIR_SIZE; #ifdef CONFIG_UNMAP_KERNEL_AT_EL0
tramp_pg_dir = .;
. += PAGE_SIZE;
#endif swapper_pg_dir = .;
. += SWAPPER_DIR_SIZE;
swapper_pg_end = .;
其中IDMAP_DIR_SIZE定义如下:



#include <stdio.h> #define CONFIG_PGTABLE_LEVELS
#define CONFIG_ARM64_PAGE_SHIFT #define PAGE_SHIFT CONFIG_ARM64_PAGE_SHIFT #define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - ) * ( - (n)) + ) #define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT( - CONFIG_PGTABLE_LEVELS) #define EARLY_ENTRIES(vstart, vend, shift) (((vend) >> (shift)) \
- ((vstart) >> (shift)) + ) #define EARLY_PGDS(vstart, vend) (EARLY_ENTRIES(vstart, vend, PGDIR_SHIFT)) #define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT() #define SWAPPER_TABLE_SHIFT PUD_SHIFT #define EARLY_PMDS(vstart, vend) (EARLY_ENTRIES(vstart, vend, SWAPPER_TABLE_SHIFT)) int main(int argc, const char *argv[])
{
unsigned long long a; unsigned long long start = 0xffff000008080000;
unsigned long long end = 0xffff000009536000; a = + EARLY_PGDS(start, end) + EARLY_PMDS(start, end); printf("a: %llu\n", a);
return ;
}
运行结果是3,所以SWAPPER_DIR_SIZE也是12KB,分别存放PGD、PUD和PMD表项,这个计算方法也容易理解,其中1表示存放level0 table需要1页,EARLY_PGDS(start, end)计算映射(start, end)占用了level0 table中几个表项,而每一个level0表项将来都会指向一个level1 table的物理首地址,每个level1 table占一页,所以可以得到存放level1 table一共需要几页,EARLY_PMDS(start, end)用于计算映射(start, end)需要占用的level1 table的表项的总和,因为level1 table的每个表项都会指向一个level2 table的物理首地址,而每个level2 table也占一页,所以可以得到存放level2 table一共需要几页
/*
* Clear the idmap and swapper page tables.
*/
adrp x0, idmap_pg_dir
adrp x1, swapper_pg_end
sub x1, x1, x0
: stp xzr, xzr, [x0], #
stp xzr, xzr, [x0], #
stp xzr, xzr, [x0], #
stp xzr, xzr, [x0], #
subs x1, x1, #
b.ne 1b
将存放转换表的内存清空。
mov x7, SWAPPER_MM_MMUFLAGS // level2的block entry会用到
adrp x0, idmap_pg_dir
adrp x3, __idmap_text_start // __pa(__idmap_text_start)
adrp x5, __idmap_text_end
clz x5, x5
cmp x5, TCR_T0SZ(VA_BITS) // default T0SZ small enough?
b.ge 1f // .. then skip VA range extension
adr_l x6, idmap_t0sz
str x5, [x6]
dmb sy
dc ivac, x6 // Invalidate potentially stale cache line
mov x4, # << (PHYS_MASK_SHIFT - PGDIR_SHIFT)
str_l x4, idmap_ptrs_per_pgd, x5
:
ldr_l x4, idmap_ptrs_per_pgd
mov x5, x3 // __pa(__idmap_text_start)
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
map_memory x0, x1, x3, x6, x7, x3, x4, x10, x11, x12, x13, x14
第23行的宏map_memory实现: 将虚拟地址[x3, x6]映射到(__idmap_text_start当前在物理内存中的地址)~(__idmap_text_end当前在物理内存中的地址),table从idmap_pg_dir当前所在的物理地址处开始存放。结合System.map,可以看到在这个范围内包含下面的符号,目的是保证在开启MMU的后,程序还可以正常运行:
ffff000008bdf000 T __idmap_text_start
ffff000008bdf000 T kimage_vaddr
ffff000008bdf008 T el2_setup
ffff000008bdf054 t set_hcr
ffff000008bdf128 t install_el2_stub
ffff000008bdf17c t set_cpu_boot_mode_flag
ffff000008bdf1a0 T secondary_holding_pen
ffff000008bdf1c4 t pen
ffff000008bdf1d8 T secondary_entry
ffff000008bdf1e4 t secondary_startup
ffff000008bdf1f4 t __secondary_switched
ffff000008bdf228 T __enable_mmu
ffff000008bdf284 t __no_granule_support
ffff000008bdf2a8 t __primary_switch
ffff000008bdf2c8 T cpu_resume
ffff000008bdf2e8 T __cpu_soft_restart
ffff000008bdf328 T cpu_do_resume
ffff000008bdf39c T idmap_cpu_replace_ttbr1
ffff000008bdf3d4 t __idmap_kpti_flag
ffff000008bdf3d8 T idmap_kpti_install_ng_mappings
ffff000008bdf414 t do_pgd
ffff000008bdf42c t next_pgd
ffff000008bdf438 t skip_pgd
ffff000008bdf46c t walk_puds
ffff000008bdf474 t do_pud
ffff000008bdf48c t next_pud
ffff000008bdf498 t skip_pud
ffff000008bdf4a8 t walk_pmds
ffff000008bdf4b0 t do_pmd
ffff000008bdf4c8 t next_pmd
ffff000008bdf4d4 t skip_pmd
ffff000008bdf4e4 t walk_ptes
ffff000008bdf4ec t do_pte
ffff000008bdf50c t skip_pte
ffff000008bdf51c t __idmap_kpti_secondary
ffff000008bdf564 T __cpu_setup
ffff000008bdf5f8 T __idmap_text_end
adrp x0, swapper_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
mov x4, PTRS_PER_PGD
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end) map_memory x0, x1, x5, x6, x7, x3, x4, x10, x11, x12, x13, x14
上面完成的工作是: 将kernel镜像占用的虚拟地址空间[_text, _end]映射到当前kernel镜像当前所在的物理内存地址空间上,table存放到swapper_pg_dir当前所在的物理内存地址处。
ffff000008080000 t _head
ffff000008080000 T _text
ffff000008080040 t pe_header
ffff000008080044 t coff_header
ffff000008080058 t optional_header
ffff000008080070 t extra_header_fields
ffff0000080800f8 t section_table
ffff000008081000 T __exception_text_start
ffff000008081000 T _stext
... ...
ffff000009536000 B _end
ffff000009536000 B swapper_pg_end
到这里,可以得到如下映射关系:
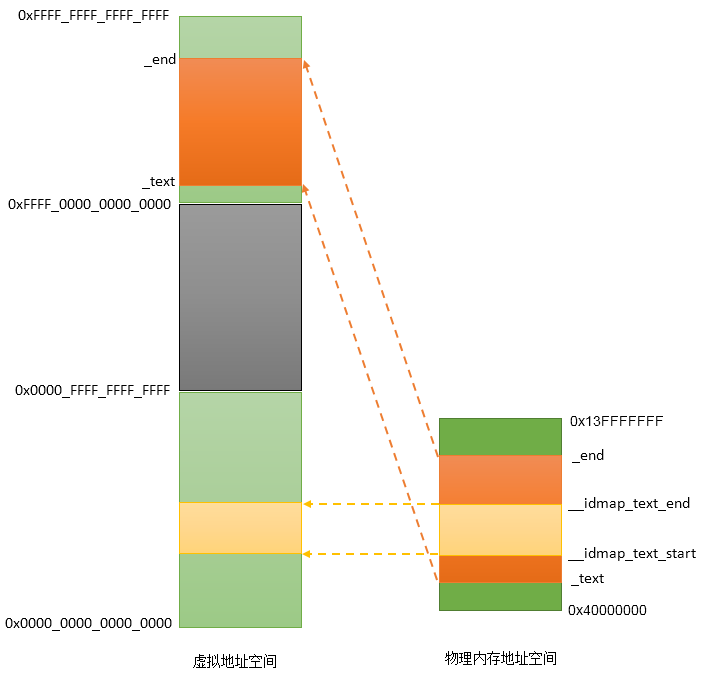
adrp x0, swapper_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement, 如果不支持内核镜像加载地址随机化,x23为0
mov x4, PTRS_PER_PGD // 每个level0 table有一个表项,为1<<
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end) map_memory x0, x1, x5, x6, x7, x3, x4, x10, x11, x12, x13, x14
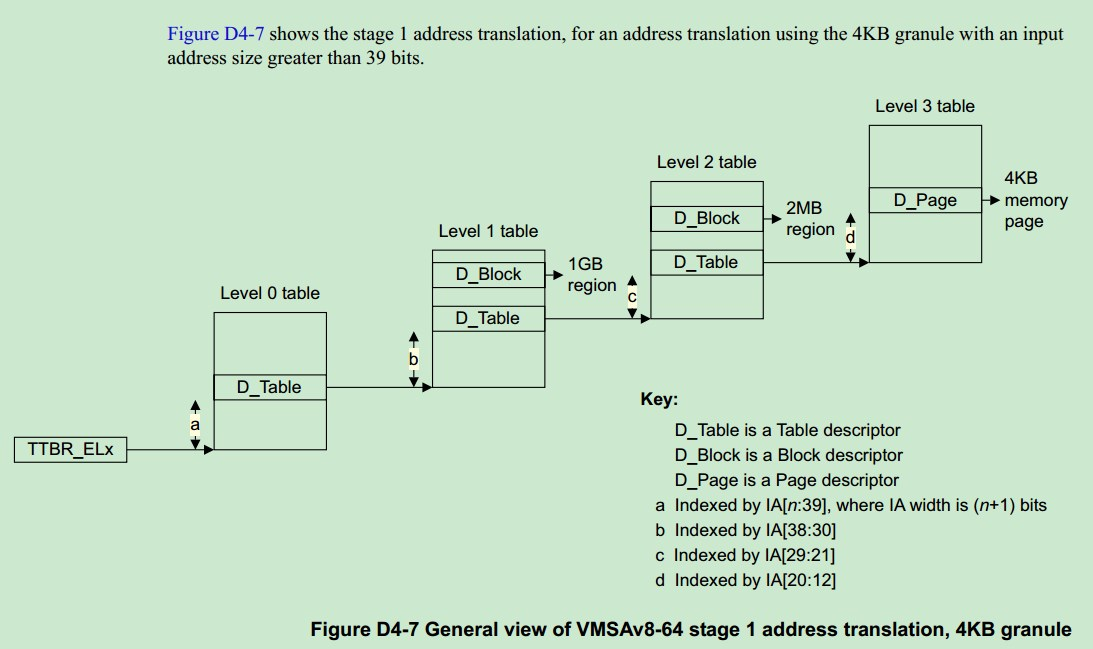
上面的map_memory就负责建立上图中level0到level2的数据结构关系,没有用到level3
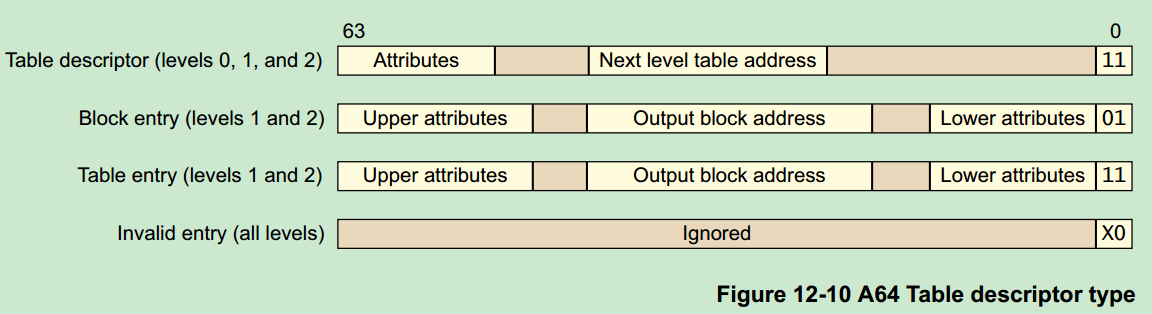
/*
* Map memory for specified virtual address range. Each level of page table needed supports
* multiple entries. If a level requires n entries the next page table level is assumed to be
* formed from n pages.
*
* tbl: location of page table
* rtbl: address to be used for first level page table entry (typically tbl + PAGE_SIZE)
* vstart: start address to map
* vend: end address to map - we map [vstart, vend]
* flags: flags to use to map last level entries
* phys: physical address corresponding to vstart - physical memory is contiguous
* pgds: the number of pgd entries
*
* Temporaries: istart, iend, tmp, count, sv - these need to be different registers
* Preserves: vstart, vend, flags
* Corrupts: tbl, rtbl, istart, iend, tmp, count, sv
*/
.macro map_memory, tbl, rtbl, vstart, vend, flags, phys, pgds, istart, iend, tmp, count, sv
add \rtbl, \tbl, #PAGE_SIZE
mov \sv, \rtbl
mov \count, #
compute_indices \vstart, \vend, #PGDIR_SHIFT, \pgds, \istart, \iend, \count
populate_entries \tbl, \rtbl, \istart, \iend, #PMD_TYPE_TABLE, #PAGE_SIZE, \tmp
mov \tbl, \sv
mov \sv, \rtbl compute_indices \vstart, \vend, #SWAPPER_TABLE_SHIFT, #PTRS_PER_PMD, \istart, \iend, \count
populate_entries \tbl, \rtbl, \istart, \iend, #PMD_TYPE_TABLE, #PAGE_SIZE, \tmp
mov \tbl, \sv compute_indices \vstart, \vend, #SWAPPER_BLOCK_SHIFT, #PTRS_PER_PTE, \istart, \iend, \count
bic \count, \phys, #SWAPPER_BLOCK_SIZE -
populate_entries \tbl, \count, \istart, \iend, \flags, #SWAPPER_BLOCK_SIZE, \tmp
.endm
其中涉及到两个宏compute_indices和populate_entries,前者计算需要占用某个level的表项的索引范围,后者用于填充被占用的那些表项。
/*
* Compute indices of table entries from virtual address range. If multiple entries
* were needed in the previous page table level then the next page table level is assumed
* to be composed of multiple pages. (This effectively scales the end index).
*
* vstart: virtual address of start of range
* vend: virtual address of end of range
* shift: shift used to transform virtual address into index
* ptrs: number of entries in page table
* istart: index in table corresponding to vstart
* iend: index in table corresponding to vend
* count: On entry: how many extra entries were required in previous level, scales
* our end index.
* On exit: returns how many extra entries required for next page table level
*
* Preserves: vstart, vend, shift, ptrs
* Returns: istart, iend, count
*/
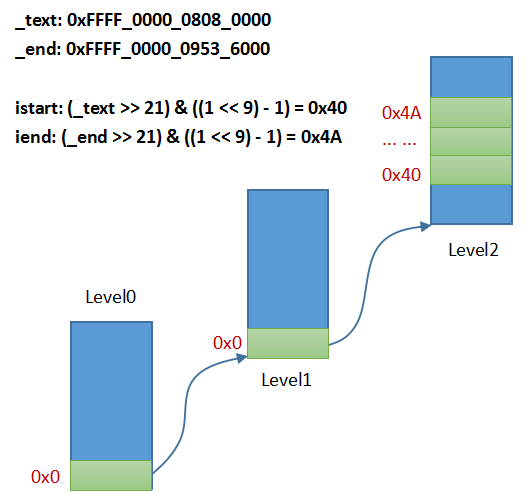
.macro compute_indices, vstart, vend, shift, ptrs, istart, iend, count
lsr \iend, \vend, \shift
mov \istart, \ptrs
sub \istart, \istart, #
and \iend, \iend, \istart // iend = (vend >> shift) & (ptrs - )
mov \istart, \ptrs
mul \istart, \istart, \count
add \iend, \iend, \istart // iend += (count - ) * ptrs
// our entries span multiple tables lsr \istart, \vstart, \shift
mov \count, \ptrs
sub \count, \count, #
and \istart, \istart, \count sub \count, \iend, \istart
.endm
下面是populate_entries的实现:
/*
* Macro to populate page table entries, these entries can be pointers to the next level
* or last level entries pointing to physical memory.
*
* tbl: page table address
* rtbl: pointer to page table or physical memory
* index: start index to write
* eindex: end index to write - [index, eindex] written to
* flags: flags for pagetable entry to or in
* inc: increment to rtbl between each entry
* tmp1: temporary variable
*
* Preserves: tbl, eindex, flags, inc
* Corrupts: index, tmp1
* Returns: rtbl
*/
.macro populate_entries, tbl, rtbl, index, eindex, flags, inc, tmp1
.Lpe\@: phys_to_pte \tmp1, \rtbl
orr \tmp1, \tmp1, \flags // tmp1 = table entry
str \tmp1, [\tbl, \index, lsl #]
add \rtbl, \rtbl, \inc // rtbl = pa next level
add \index, \index, #
cmp \index, \eindex
b.ls .Lpe\@
.endm
void populate_entries(char *tbl, char **rtbl, int index, int eindex,
int flags, int inc, char *tmp1)
{
while (index <= eindex) {
tmp1 = *rtbl;
tmp1 = tmp1 | flags;
*(tbl + index*) = tmp1; *rtbl = *rtbl + inc;
index++;
}
} void compute_indices (uint64_t vstart, uint64_t vend, int shift, int ptrs,
int *istart, int *iend, int *count)
{
*iend = vend >> shift;
*istart = ptrs;
*istart = *istart - ;
*iend = *iend & *istart; // 计算end index *istart = ptrs;
*istart = (*istart) * (*count);
*iend = *iend + *istart; // 由于*count是0,这里end index没变变化 *istart = vstart >> shift;
*count = ptrs;
*count = *count - ;
*istart = *istart & *count; // 计算start index *count = *iend - *istart; // 计算需要的index的数量
} void map_memory(char *tbl, char *rtbl, uint64_t vstart, uint64_t vend, int flags,
uint64_t phys, int pgds, int istart, int iend, int tmp, int count, char *sv)
{
#define PAGE_SIZE (1 << 12) tbl = (char *)malloc(PAGE_SIZE * ); // 用于存放level0~level2的table的缓冲区 rtbl = tbl + PAGE_SIZE; // rtbl指向下一个level的table
sv = rtbl;
count = ; #define PGDIR_SHIFT (39)
#define PMD_TYPE_TABLE (0x3 << 0) // 表示table descriptor
#define PGDS (1 << 9) compute_indices(vstart, vend, PGDIR_SHIFT, PGDS, &istart, &iend, &count);
populate_entries(tbl, &rtbl, istart, iend, PMD_TYPE_TABLE, PAGE_SIZE, tmp); tbl = sv;
sv = rtbl; #define SWAPPER_TABLE_SHIFT (30)
#define PTRS_PER_PMD (1<<9) compute_indices(vstart, vend, SWAPPER_TABLE_SHIFT, PTRS_PER_PMD, &istart, &iend, &count);
populate_entries(tbl, &rtbl, istart, iend, PMD_TYPE_TABLE, PAGE_SIZE, tmp); //table descriptor tbl = sv; #define SWAPPER_BLOCK_SHIFT (21)
#define PTRS_PER_PTE (1 << 9) //
#define SWAPPER_BLOCK_SIZE (1<<21) //2MB
// 这里的flags是SWAPPER_MM_MMUFLAGS,为((<<) | ((<<) | (<<) | (<<))), 类型Block entry compute_indices(vstart, vend, SWAPPER_BLOCK_SHIFT, PTRS_PER_PTE, &istart, &iend, &count);
count = phys ^ (SWAPPER_BLOCK_SIZE - );
populate_entries(tbl, &count, istart, iend, flags, SWAPPER_BLOCK_SIZE, tmp);
}
由于我们编译出来的kernel大概有20.7MB左右,所以用level0 table需要一项(512G),level1 table需要一项(1GB),level2 block需要11个(22MB)。
ARM64 __create_page_tables分析的更多相关文章
- ARM Linux启动代码分析
前言 在学习.分析之前首先要弄明白一个问题:为什么要分析启动代码? 因为启动代码绝大部分都是用汇编语言写的,对于没学过或者不熟悉汇编语言的同学确实有一定难度,但是如果你想真正深入地学习Linux,那么 ...
- arm64 调试环境搭建及 ROP 实战
前言 比赛的一个 arm 64 位的 pwn 题,通过这个题实践了 arm 64 下的 rop 以及调试环境搭建的方式. 题目文件 https://gitee.com/hac425/blog_data ...
- 深入剖析 iOS 性能优化
问题种类 时间复杂度 在集合里数据量小的情况下时间复杂度对于性能的影响看起来微乎其微.但如果某个开发的功能是一个公共功能,无法预料调用者传入数据的量时,这个复杂度的优化显得非常重要了.上图列出了各种情 ...
- ARMv8 Linux内核head.S源码分析
ARMv8Linux内核head.S主要工作内容: 1. 从el2特权级退回到el1 2. 确认处理器类型 3. 计算内核镜像的起始物理地址及物理地址与虚拟地址之间的偏移 4. 验证设备树的地址是否有 ...
- 微信双开是定时炸弹?关于非越狱iOS上微信分身高危插件ImgNaix的分析
作者:蒸米@阿里移动安全 序言 微信作为手机上的第一大应用,有着上亿的用户.并且很多人都不只拥有一个微信帐号,有的微信账号是用于商业的,有的是用于私人的.可惜的是官方版的微信并不支持多开的功能,并且频 ...
- iOS----- Crash 分析(文三)- 符号化崩溃日志
未符号化的崩溃日志就象一本天书,看不懂,更别谈分析崩溃原因了.所以我们在分析日志之前,要把日志翻译成我们可以看得懂的文字.这一步我们称之为符号化. 在iOS Crash分析(文一)中已经提到过符号化的 ...
- 用Reveal分析第三方App的UI
文章出自:听云博客 Reveal简介: 这是个神奇的工具,它能常透彻地分析个App的UI结构. 这个工具包括两部分,部分是在PC上运行的一个独立应用,即Reveal.app,另一部分代码在你要分析的某 ...
- 使用dSYM分析App崩溃日志
前言 我们在开发App过程中,因为连接到控制台,所以遇到问题会很容易找到问题代码.但是对于线上的App出现Crash的时候,我们不可能通过这种方式,也不现实,所以我们只能通过收集Crash信息,来解决 ...
- u-boot启动流程分析(2)_板级(board)部分
转自:http://www.wowotech.net/u-boot/boot_flow_2.html 目录: 1. 前言 2. Generic Board 3. _main 4. global dat ...
随机推荐
- [转]Oh My Zsh,安装,主题配置
https://swp-song.com/2017/08/20/Tools/OhMyZsh%E5%AE%89%E8%A3%85%E5%92%8C%E4%B8%BB%E9%A2%98%E9%85%8D% ...
- 【Android】spannableStringBuilder
EditText: 通常用于显示文字,但有时候也需要在文字中夹杂一些图片,比如QQ中就可以使用表情图片,又比如需要的文字高亮显示等等,如何在android中也做到这样呢? 记得android中有个an ...
- net core体系-网络数据采集(AngleSharp)-1初探
有这么一本Python的书: <<Python 网络数据采集>> 我准备用.NET Core及第三方库实现里面所有的例子. 这是第一部分, 主要使用的是AngleSharp: ...
- Best Reward 拓展kmp
Problem Description After an uphill battle, General Li won a great victory. Now the head of state de ...
- day29 网络编程
网络通信原理: http://www.cnblogs.com/linhaifeng/articles/5937962.html 一.操作系统基础 二.网络通信原理 2.1 互联网的本质就是一系列的网络 ...
- git合并
git 里合并了两个分支以后,是不是两个分支的内容就完全一样了? 不是.看合并到哪个分支,这个分支有两个分支所有的内容.另外一个分支不变. 合并操作( merge )对当前所在分支产生影响. 合并分支 ...
- css3和html5
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 总结mysql的三种外键约束方式
如果表A的主关键字是表B中的字段,则该字段称为表B的外键,表A称为主表,表B称为从表.外键是用来实现参照完整性的,不同的外键约束方式将可以使两张表紧密的结合起来,特别是修改或者删除的级联操作将使得日常 ...
- HDU 4612 Warm up (边双连通分量+缩点+树的直径)
<题目链接> 题目大意:给出一个连通图,问你在这个连通图上加一条边,使该连通图的桥的数量最小,输出最少的桥的数量. 解题分析: 首先,通过Tarjan缩点,将该图缩成一颗树,树上的每个节点 ...
- c#一步一步实现ORM
本篇适合新手了解学习orm.欢迎指正,交流学习. 现有的优秀的orm有很多. EF:特点是高度自动化,缺点是有点重. Nhibnate:缺点是要写很多的配置. drapper:最快的orm.但是自动化 ...