Hadoop之简单文件读写
文件简单写操作:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class writeFile {
public static void main(String[] args) {
try{
Configuration conf=new Configuration();
//如果没有把配置文件加入bin文件夹,那么需要加入下面两行
//conf.set("fs.defaultFS","hdfs://localhost:9000" );
//conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs =FileSystem.get(conf);
byte[] buffer="Hello world!".getBytes();
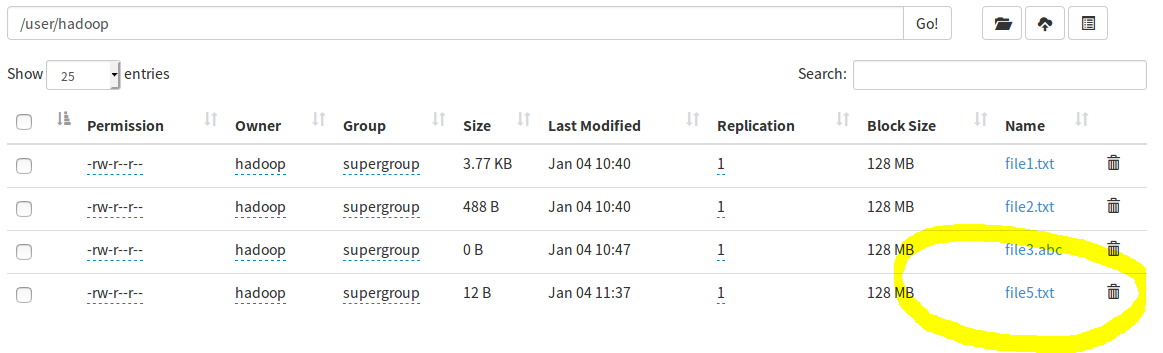
String Filename="hdfs://localhost:9000/user/hadoop/file5.txt"; FSDataOutputStream os=fs.create(new Path(Filename));
os.write(buffer,0,buffer.length); System.out.println("creat "+Filename+" successfully");
os.close();
fs.close();
}
catch(Exception e){
e.printStackTrace();
}
}
}
文件简单读操作:
import java.io.BufferedReader;
import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class readFile {
public static void main(String argsp[]){
try{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000" );
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
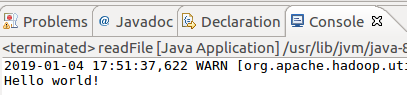
FileSystem fs = FileSystem.get(conf); Path file = new Path("hdfs://localhost:9000/user/hadoop/file5.txt"); FSDataInputStream is = fs.open(file); BufferedReader bd = new BufferedReader(new InputStreamReader(is));
String content = bd.readLine(); System.out.println(content); bd.close();
fs.close();
}
catch(Exception e){
e.printStackTrace();
}
}
}
Hadoop之简单文件读写的更多相关文章
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- Python——函数,模块,简单文件读写
函数(function)定义原则: 最大化代码重用,最小化代码冗余,流程符合思维逻辑,少用递归; 函数的定义方法: def function_name(param_1, param_2): ..... ...
- Python——函数,模块,简单文件读写(python programming)
函数(function)定义原则: 最大化代码重用,最小化代码冗余,流程符合思维逻辑,少用递归; 函数的定义方法: def function_name(param_1, param_2): ..... ...
- Python简单文件读写
''' 用文件存储账户信息 使用列表存储多个账户信息,每个账户为一个字典对象 ''' users=[] #创建一个空列表 users.append({'id':'admin','pwd':'1235@ ...
- Hadoop的文件读写操作流程
以下主要讲解了Hadoop的文件读写操作流程: 读文件 读文件时内部工作机制参看下图: 客户端通过调用FileSystem对象(对应于HDFS文件系统,调用DistributedFileSystem对 ...
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述 1' DFS 分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.该系统架构 ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- ios 简单的plist文件读写操作(Document和NSUserDefaults)
最近遇到ios上文件读写操作的有关知识,记录下来,以便以后查阅,同时分享与大家. 一,简单介绍一下常用的plist文件. 全名是:Property List,属性列表文件,它是一种用来存储串行化后的对 ...
随机推荐
- java学习之路--String类的基本方法
String类常见的功能 获取 1.1 字符串中包含的字符数,也就是获取字符串的长度:int length(); 1.2 根据位置获取某个位置上的字符:char charAt(int index) 1 ...
- GitLab上传项目到新的分支
多人协同开发,GitLab上的group仓库里的master分支作为开发分支(最终从dev提交的代码),dev分支作为每个人的代码测试后合并的分支,每个人需要定期merge request自己的分支到 ...
- 选择结构的三角关系Switch、Case、Default!!!
选择结构的三角关系Switch.Case.Default!!! 今天我们学习选择结构进化章节——Switch结构,他与if有什么区别呢? 相同点: 都是用来处理多分支条件的结构 不同点: switch ...
- python文件派生
import time class Foo: x = 1 def __init__(self, y): self.y = y def __getattr__(self, item): # 没有的情况下 ...
- [No0000D1]WPF—TreeView无限极绑定集合形成树结构
1.如图所示:绑定树效果图 2.前台Xaml代码: <Window x:Class="WpfTest.MainWindow" xmlns="http://schem ...
- c语言实现wc功能
本随笔对网站http://blog.chinaunix.net/uid-22566367-id-381958.html有所借鉴 #include <stdio.h> #define BEG ...
- day5_函数返回值
每个函数都有返回值,如果没有在函数里面指定返回值的话,在python里面函数执行完之后,默认会返回一个None,函数也可以有多个返回值,如果有多个返回值的话,会把返回值都放到一个元组中,返回的是一个元 ...
- 苹果审核被拒,解析奔溃日志.txt转crash文件
1. 桌面新建一个文件夹,用来存放crash相关的东西.取名crash 2.下载苹果官方邮件里给的后缀名为 .txt 的被拒附件(这三个txt格式文件为苹果返回的崩溃日志文件),把这三个文件放在刚新建 ...
- 取数游戏II
传送门 #include <bits/stdc++.h> using namespace std; #define ll long long #define re register #de ...
- Angela启动步骤
1.在web目录下执行 grunt watch (如果不在目录下执行不能识别,当然首先安装node.js) 2.随便改一个文件,会自动重新生成代码(在dest目录下会生成可执行的代码) 3.如果有de ...