python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍;
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
sklearn.preprocessing.scale(X)
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
scaler = sklearn.preprocessing.StandardScaler().fit(train)
scaler.transform(train)
scaler.transform(test)
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
min_max_scaler = sklearn.preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(X_train)
或者
import numpy as np
a = np.random.random((2, 3, 3))
def customMinMaxScaler(X):
return (X - X.min()) / (X.max() - X.min())
np.array([customMinMaxScaler(x) for x in a]) 3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm='l2')
得到:
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)
5. 标签二值化(Label binarization)
lb = sklearn.preprocessing.LabelBinarizer()
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
newdf=pd.get_dummies(df,columns=["gender","title"],dummy_na=True)
7.标签编码(Label encoding)
le = sklearn.preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
#非数值型转化为数值型
le.fit(["paris", "paris", "tokyo", "amsterdam"])
le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])
8.特征中含异常值时
sklearn.preprocessing.robust_scale
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
poly = sklearn.preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)
原始特征: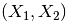
转化后: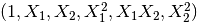
总结
以上就是为大家总结的python中常用的九种预处理方法分享,希望这篇文章对大家学习或者使用python能有一定的帮助,如果有疑问大家可以留言交流。
python中常用的九种数据预处理方法分享的更多相关文章
- python中常用的九种预处理方法
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(Standardization or Mean Removal ...
- iOS中常用的四种数据持久化方法简介
iOS中常用的四种数据持久化方法简介 iOS中的数据持久化方式,基本上有以下四种:属性列表.对象归档.SQLite3和Core Data 1.属性列表涉及到的主要类:NSUserDefaults,一般 ...
- .NET中常用的几种解析JSON方法
一.基本概念 json是什么? JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是一种轻量级的数据交换格式,是存储和交换文本信息的语法. ...
- Android中常用的五种数据存储方式
第一种: 使用SharedPreferences存储数据 适用范围: 保存少量的数据,且这些数据的格式非常简单:字符串型.基本类型的值.比如应用程序的各种配置信息(如是否打开音效.是否使用震动效果.小 ...
- iOS中常用的四种数据持久化技术
iOS中的数据持久化方式,基本上有以下四种:属性列表 对象归档 SQLite3和Core Data 1.属性列表涉及到的主要类:NSUserDefaults,一般 [NSUserDefaults st ...
- JavaScript中常用的几种类型检测方法
javascript中类型检测方法有很多: typeof instanceof Object.prototype.toString constructor duck type 1.typeof 最常见 ...
- iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比
iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比 iphoneiPhoneIPhoneIPHONEIphone数据持久化 对比总结 本篇对IOS中常用的5种数据持久化方法进行简单 ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
随机推荐
- springboot+mybatis+springmvc整合实例
以往的ssm框架整合通常有两种形式,一种是xml形式,一种是注解形式,不管是xml还是注解,基本都会有一大堆xml标签配置,其中有很多重复性的.springboot带给我们的恰恰是“零配置”,&quo ...
- PAT A1117 Eddington Number (25 分)——数学题
British astronomer Eddington liked to ride a bike. It is said that in order to show off his skill, h ...
- python 3.6练习题(仿购物车)
opop = [ ('Iphone', 9800), ('Bike', 800), ('Mac Pro', 12000), #定义商品列表 ('Pyhon book', 120), ('Telas', ...
- java Arrays数组
1.java.util.Arrays 工具类的使用Arrays 类中的常用方法1) toString()打印数组2) equals()比较两个数组是否相同3) copyOf(…)复制指定的数组 (效率 ...
- day86
视图组件 基于以往我们所用的视图函数,我们发现其中冗余的代码比较多,今天就来对其进行封装,争取做一个代码洁癖者 原来我们的视图函数: class Book(APIView): def get(self ...
- linux下service+命令和直接去执行命令的区别,怎么自己建立一个service启动
启动一些程序服务的时候,有时候直接去程序的bin目录下去执行命令,有时候利用service启动. 比如启动mysql服务时,大部分喜欢执行service mysqld start.当然也可以去mysq ...
- CF700E Cool Slogans SAM、线段树合并、树形DP
传送门 在最优的情况下,序列\(s_1,s_2,...,s_k\)中,\(s_i (i \in [2 , k])\)一定会是\(s_{i-1}\)的一个\(border\),即\(s_i\)同时是\( ...
- LOJ564 613的天网 构造
题目传送门 题意:给出一个$N \times N \times N$的方块,你可以在每一个$1 \times 1 \times 1的方块上放上一个摄像头,摄像头的监视范围为6个方向的无限远距离.问最少 ...
- C# 深浅复制 MemberwiseClone
学无止境,精益求精 十年河东,十年河西,莫欺少年穷 学历代表你的过去,能力代表你的现在,学习代表你的将来 最近拜读了大话设计模式:原型模式,该模式主要应用C# 深浅复制来实现的!关于深浅复制大家可参考 ...
- [Deep-Learning-with-Python]GAN图片生成
GAN 由Goodfellow等人于2014年引入的生成对抗网络(GAN)是用于学习图像潜在空间的VAE的替代方案.它们通过强制生成的图像在统计上几乎与真实图像几乎无法区分,从而能够生成相当逼真的合成 ...