Centos7+hadoop2.7.3+jdk1.8
修改主机名
1. 修改主机名 vi /etc/sysconfig/network ,改为 master , slave1 , slave2
2. source /etc/sysconfig/network 让刚才的设置生效
3. 如果不行需要 reboot
4. 在master主机上输入命令:vi /etc/hosts,添加ip地址和主机名
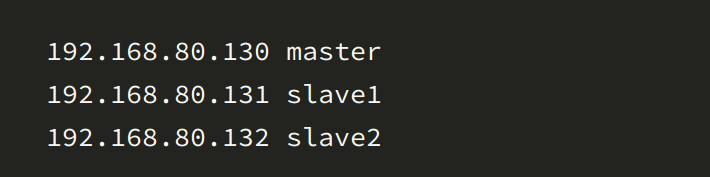
设置host
5. 将修改后的host文件发送到其他主机,进行远程拷贝
scp /etc/hosts root@192.168.80.131:/etc
6. 设置免密码登录
a) ssh-keygen 生成密匙对
b) ssh-copy-id 其他主机(例如:ssh-copy-id slave1)
i. master-->slave1,slave2,master
ii. slave1-->slave1,slave2,master
iii. slave2-->slave1,slave2,master
安装jdk
1. 查看之间是否安装jdk
a) rpm –qa | grep jdk
2. 输入 rpm -e –nodeps 要卸载的软件
3. 安装包如下 在/opt/software/java 下进行解压 tar -xvf
4. 配置环境变量 在/etc/profile下
#set java environment
export JAVA_HOME=/opt/software/java/jdk1.8.0_141
export JRE_HOME=/opt/software/java/jdk1.8.0_141/jre
export CLASSPATH=.:$JRE_HOME/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin

5. 重新加载配置文件source /etc/profile
6. 测试 java -version javac -version
安装hadoop
1. 在/opt/software/hadoop 目录下解压tar -xvf *** 安装包如下
2. 重命名 mv hadoop-2.7.3 hadoop
3. 在hadoop目录下创建目录tmp,logs,hdfs,hdfs/data,hdfs/name

4. 修改配置文件 etc/hadoop/hadoop-env.sh 文件中

etc/hadoop/yarn-env.sh中

5. etc/hadoop/slaves文件下删除原来的内容,加上从节点的名字

6. 配置 etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/software/hadoop/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
配置 etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<!--namenode节点数据存储目录-->
<value>file:/opt/software/hadoop/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!--datanode数据存储目录-->
<value>file:/opt/software/hadoop/hadoop/hdfs/data</value>
</property>
<property>
<!--指定DataNode存储block的副本数量,不大于DataNode的个数就行-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--指定master的http地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<!--指定master的https地址-->
<name>dfs.namenode.secondary.https-address</name>
<value>master:50091</value>
</property>
<property>
<!--必须设置为true,否则就不能通过web
访问hdfs上的文件信息-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
</configuration>
配置 etc/hadoop/yarn-site.xml 文件
<configuration> <property> <!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <!--ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。--> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <!--ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。--> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <!--ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。--> <name>yarn.resourcemanager.resourcetracker.address</name> <value>master:8031</value> </property> <property> <!--ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。--> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <!--用户可通过该地址在浏览器中查看集群各类信息。--> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <!--NodeManager总的可用物理内存。注意,该参数是不可修改的,一旦设置,整个运行过程中不可动态修改。另外,该参数的默认值是8192MB,因此,这个值通过一定要配置。不过,Apache已经正在尝试将该参数做成可动态修改的。--> <name>yarn.nodemanager.resource.memory-mb</name> <value>3072</value> </property> </configuration>
首先修改mapred-site.xml.default为mapred-site.xml
配置 etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
7. 远程将master上的 /opt/SoftWare 的内容拷贝到子节点, -r 表示递归 scp -r /opt/SoftWare root@slave1:/opt/ scp -r /opt/SoftWare root@slave2:/opt/
8. 配置环境变量
export HADOOP_HOME=/opt/software/hadoop/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs export YARN_LOG_DIR=$HADOOP_LOG_DIR export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

9. 远程将master上的 /etc/profile 的内容拷贝到子节点
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
10. 执行全部的source source /etc/profile
11. 同步系统时间
a) 安装ntpdate工具 yum -y install ntp ntpdate
b) 设置与网络时间同步ntpdate cn.pool.ntp.org
c) 系统时间写入硬件时间hwclock -systohc
12. 关闭防火墙
a) systemctl stop firewalld
b) 永久关闭(开机不自启)systemctl disable firewalld
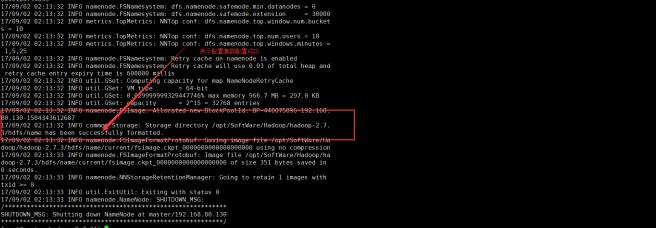
13. 在主节点hadoop下格式化 bin/hdfs namenode -format
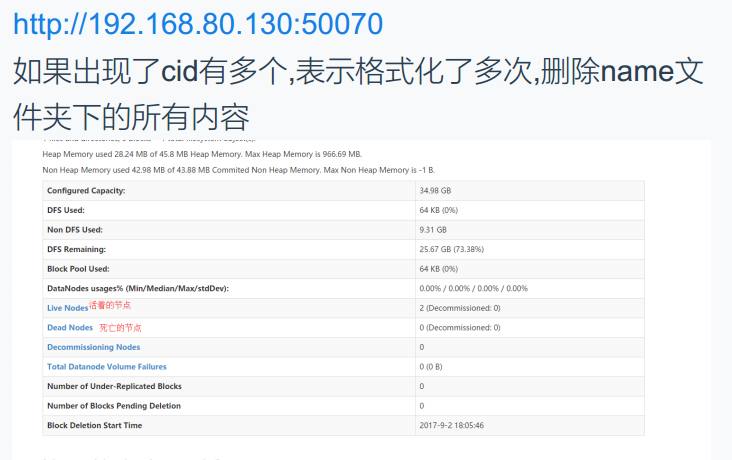
14. 启动集群 start-all.sh
Centos7+hadoop2.7.3+jdk1.8的更多相关文章
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
1下载hadoop 2安装3个虚拟机并实现ssh免密码登录 2.1安装3个机器 2.2检查机器名称 2.3修改/etc/hosts文件 2.4 给3个机器生成秘钥文件 2.5 在hserver1上创建 ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.3)
https://blog.csdn.net/pucao_cug/article/details/71698903 1下载hadoop 2安装3个虚拟机并实现ssh免密码登录 2.1安装3个机器 2.2 ...
- CentOS7+hadoop2.6.4+spark-1.6.1
环境: CentOS7 hadoop2.6.4已安装两个节点:master.slave1 过程: 把下载的scala.spark压缩包拷贝到/usr/hadoop-2.6.4/thirdparty目录 ...
- centos7.0 下安装jdk1.8
centos7.0这里安装jdk1.8采用yum安装方式,非常简单. 1.查看yum库中jdk的版本 [root@localhost ~]# yum search java|grep jdk 2.选择 ...
- <亲测>centos7通过yum安装JDK1.8(实际上是openjdk)
centos7通过yum安装JDK1.8 安装之前先检查一下系统有没有自带open-jdk 命令: rpm -qa |grep java rpm -qa |grep jdk rpm -qa |gr ...
- Linux基础环境_安装配置教程(CentOS7.2 64、JDK1.8、Tomcat8)
Linux基础环境_安装配置教程 (CentOS7.2 64.JDK1.8.Tomcat8) 安装包版本 1) VMawre-workstation版本包 地址: https://my.vmw ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)--------hadoop环境的搭建
Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)------https://blog.csdn.net/pucao_cug/article/details/71698903 ...
- 安装hadoop2.9.2 jdk1.8 centos7
安装JDK1.8 查看JDK1.8的安装 https://www.cnblogs.com/TJ21/p/13208514.html 安装hadoop 上传hadoop 下载hadoop 地址h ...
- 在虚拟机下安装hadoop集成环境(centos7+hadoop-2.6.4+jdk-7u79)
[1]64为win7系统,用virtualbox建立linux虚拟机时,为什么没有64位的选项? 百度 [2]在virtualbox上安装centos7 [3]VirtualBox虚拟机网络环境解析和 ...
随机推荐
- 【转载】Ocelot网关的路由热更新
调用API修改Ocelot的配置文件 May 11, 2018 | netcoreocelot | 410 阅读 Ocelot是一个基于.net core的开源webapi服务网关开源项目,功能比较强 ...
- Django学习笔记之数据库-数据库与模型
MySQL数据库 在网站开发中,数据库是网站的重要组成部分.只有提供数据库,数据才能够动态的展示,而不是在网页中显示一个静态的页面.数据库有很多,比如有SQL Server.Oracle.Postgr ...
- 2013-7-30 802.1X企业级加密
今天做了U9510的企业级加密标杆测试,写了企业级加密标杆设备的操作指南.最后做到server 2003却出了问题,peap能关联,但是TLS怎么都关联不上.用adb shell查看logcat日志, ...
- 6、 (★、※)root that results in a highest tree
问题:对于一棵特定的树,选择合适的根结点,使得树的高度最大. 思路: 先选择一个结点,从该结点开始遍历整棵树,获取能达到的最深的顶点(记为结点集合A): 然后从集合A中任意一个结点出发遍历整棵树,获取 ...
- POI导入工具类
前言 导入的通用方法,包括xls.xlsx的取值方法,非空判断方法,空行判断,处理了手机号读取和日期读取格式问题.这几个方法就可以完成简单读取了,有时间我在优化下. maven依赖 <!-- P ...
- SHFileOperation 解决double-null terminated
void rubyTools::funStrToWstr(string str, wstring& strw) { const char* pData = str.c_str(); int l ...
- Maven CXF wsdl2Java String生成JAXBElement<Xxx> 解决方法
添加要bindingFile的jaxb配置文件,如下: <jaxb:bindings version="2.1" xmlns:jaxb="http://java.s ...
- 拼接html
var html='<tbody>\ <tr class="print-tr-top">\ <td width="50%" col ...
- Azkaban安装及分布式部署(multiple-executor)
参考文章:https://blog.csdn.net/weixin_35852328/article/details/79327996 官网:https://azkaban.readthedocs.i ...
- canvas 2.0
了解 虽然大家都称Canvas为html5的新标签,看起来好像Canvas属于html语言的新知识,但其实Canvas画图是通过javascript来做的.所以,如果你想学习Canvas画图,你必须要 ...