我对于B-树索引的内部结构与索引类型所做的笔记
图 3-1 B-树索引的内部结构
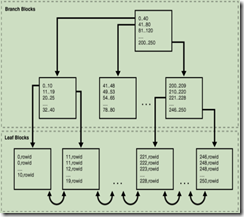
分支块和页块
B-树索引有两种类型的块: 用于查找的分支块和用于存储值的叶块。B-树索引的上层分支块包含指向下层索引块的索引数据。在图 3-1 中,根分支块包含条目 0-40, 指向下一个分支级别中最左边的块。此分支块包含条目如0-10 和 11-19 等。每个这些条目指向包含在该范围内键值的叶块。
叶块包含每个被索引的数据值,和一个相应的用来定位实际行的 rowid。每个条目按 (rowid,键)排序。在一个叶块内,键和 rowid 链接到其左右同级条目。这些叶块本身也双向链接在一起。如图 3-1,最左边的叶块 (0-10) 链接到第二个叶块 (11-19)
索引扫描
在索引扫描中,数据库使用语句指定的索引列,通过遍历索引来检索行。数据库扫描索引,将使用 n个 I/O 就能找到其要查找的值,其中 n 即是 B-树索引的高度。这是数据库索引背后的基本原理.
如果 SQL 语句仅访问被索引的列,那么数据库只需直接从索引中读取值,而不用读取表。如果该语句同时还需要访问除索引列之外的列,那么数据库会使用 rowids 来查找表中的行(这就是我们所说的回表)。通常,为检索表数据,数据库以交替方式先读取索引块,然后读取相应的表块。
完全索引扫描
在完全索引扫描中,数据库顺序读取整个索引。如果在 SQL 语句中的谓词(WHERE 子句) 引用了一个索引列,或者在某些情况下未不指定任何谓词,此时可能使用完全索引扫描。完全扫描可以消除排序,因为数据本身就是基于索引键排过序的.
假设应用程序运行以下查询:
SELECT department_id, last_name, salary
FROM employees
WHERE salary > 5000
ORDER BY department_id, last_name;
此外假定 department_id last_name,和 salary 是一个复合索引键。Oracle 数据库会执行完全索引扫描,按顺序读取 (按部门 ID 和姓氏顺序) 并基于薪金属性进行筛选。通过这种方式,数据库只需扫描一个小于雇员表的数据集,而不用扫描那些未包含在查询中的列,并避免了对该数据进行排序.
快速完全索引扫描
快速完全索引扫描是一种完全索引扫描,数据库并不按特定的顺序读取索引块。数据库仅访问索引本身中的数据,而无需访问表。
当索引包含了查询所需的所有列,且索引键中至少一列具有 NOT NULL 约束时,快速完全索引扫描可以替代全表扫描.
例如,应用程序发出以下查询,不包含 ORDER BY 子句:
SELECT last_name, salary
FROM employees;
如果姓氏和工资是一个复合索引键,那么快速完全索引扫描只需读取索引条目,就可以获取所需的信息:
Baida,2900,rowid
Zlotkey,10500,rowid Zlotkey,10500,rowid
Austin,7200,rowid Austin,7200,rowid
Baer,10000,rowid Baer,10000,rowid
Atkinson,2800,rowid Atkinson,2800,rowid
Austin,4800,rowid Austin,4800,rowid
索引范围扫描是对索引的有序扫描,具有以下特点:
在条件中指定了一个或多个索引前导列。条件指定一个或多个表达式和逻辑 (布尔) 运算符的组合,并返回一个值( TRUE、 FALSE,或UNKNOWN)。
一个索引键可能对应 0 个、1 个或更多个值。
通常,数据库使用索引范围扫描来访问选择性的数据。选择性是查询所选择的数据占总行数的百分比, 0 意味着没有任何行,1 表示所有行。选择性与一个(或多个)查询谓词相关,比如 WHERE last_name LIKE 'A%'。值越接近 0 的谓词越具有选择性,相反,越接近 1 的谓词则越不具有选择性。
例如,用户查询姓氏以 A 开头的雇员。假定 last_name 列已被索引,其索引
条目如下所示:
Abel,rowid
Ande,rowid
Atkinson,rowid
Austin,rowid
Austin,rowid
Baer,rowid
数据库可以使用范围扫描,因为在谓词中指定了 last_name 列,而且每个索引键可能对应多个 rowids。例如有两个雇员名叫 Austin,所以有两个rowids 都与索引键 Austin 相关联.索引范围扫描可以在两边都有边界,比如部门 ID 在 10 至 40 之间的查询,或只在一边有界,比如部门 id 在 40 以上的查询。为扫描索引,数据库将在叶块之间前后移动。例如,对于 ID 在 10 到 40 之间的扫描,将先定位到包含最低键值(大于或等于 10)的第一个索引叶块。然后顺着各个被链接的页结点水平推进,直到它找到一个大于 40 的值为止。
唯一索引扫描
相对于索引范围扫描,唯一索引扫描必须是 有 0 个 或 1 个 rowid 与索引键相关联。当一个谓词使用相等运算符引用了唯一索引键的所有列时,数据库
将执行唯一扫描。只要找到了第一个记录,唯一索引扫描就停止处理,因为不可能有第二个记录满足条件。
作为演示,假定用户运行如下查询:
SELECT *
FROM employees
WHERE employee_id = 5;
假定 employee_id 列是主键,并具有如下的索引条目:
1,rowid
2,rowid
4,rowid
5,rowid
6,rowid
在这种情况下,数据库可以使用唯一索引扫描来定位 rowid,以找到 ID 为 5 的雇员
索引跳跃扫描
索引跳跃扫描使用复合索引的逻辑子索引。数据库“跳跃地”通过单个索引,好像它在多个单独的索引中搜索一样。如果在复合索引前导键列中有少
量不同值,而在非前导键列中有大量不同值,此时使用跳跃扫描是有益的。
当在查询谓词中未指定组合索引的前导列时,数据库可能选择索引跳跃扫描。
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.com';
customers 表中有一列 cust_gender,其值为 M 或 F。假定在列cust_gender 和 cust_email 上存在一个复合索引。示例 3-1 显示了索引条目的一部分。
F,Wolf@company.com,rowid
F,Wolsey@company.com,rowid
F,Wood@company.com,rowid
F,Woodman@company.com,rowid
F,Yang@company.com,rowid
F,Zimmerman@company.com,rowid
M,Abbassi@company.com,rowid
M,Abbey@company.com,rowid
虽然未在 WHERE 子句中指定 cust_gender,数据库可以使用跳跃索引扫描。
在跳跃扫描中,逻辑子索引的数目决定于前导列中的非重复值的数目。在示例 3-1 中,前导列中有两个可能值。数据库在逻辑上将该索引拆分为一个具
有 F 键的子索引和另一个具有 M 键的子索引。
当搜索电子邮件为 Abbey@company.com 的客户的记录时, 数据库首先搜索 F值的子索引,然后搜索 M 值的子索引。从概念上讲,数据库这样处理查询,如下所示:
SELECT * FROM sh.customers WHERE cust_gender = 'F' AND cust_email = 'Abbey@company.com'
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender = 'M' AND cust_email = 'Abbey@company.com';
索引聚簇因子用于测量相对于某个索引值(如雇员姓氏)的行顺序。被索引值的行存储得越有序,则聚簇因子越低。
如果聚簇因子较高,则在大型索引范围扫描过程中,数据库将执行相对较高数目的 I/O。索引条目指向随机表块,因此数据库可能必须一遍又一遍地来回重读索引所指向的同一数据块。在一个单一叶块中的相邻索引条目倾向于指向同一个数据块中的行。
查询索引聚簇因子
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
FROM ALL_INDEXES
WHERE INDEX_NAME IN
('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2
反向键索引
反向键索引是一种 B-树索引,它在物理上反转每个索引键的字节,但保持列顺序不变。例如,如果索引键是 20,,并且在一个标准的 B-树索引中此
键被存为十六进制的两个字节 C1 15, 那么反向键索引会将其存为 15,C1。
反向键解决了在 B-树索引右侧的的叶块争用问题。在 Oracle RAC数据库中的多个实例重复不断地修改同一数据块时,这个问题尤为严重。例如,在订单表中,订单的主键是连续的。在集群中的一个实例添加订单 20,而另一个实例添加订单 21,每个实例都将它的键写入索引右侧的相同叶块。
在一个反向键索引中,对字节顺序反转,会将插入分散到索引中的所有叶块。例如键 20 和 21,本来在一个标准键索引中会相邻,现在存储在相隔很远的独立的块中。这样,顺序插入产生的 I/O 被更均匀地分布了。
因为存储数据时,并没有按照键列排序,因此在某些情况下,反向键格式丧失了执行索引范围扫描查询的能力。例如,如果用户发出一个订单 id 大于20 的查询,但数据库不能从包含此 ID 的块开始扫描并沿着叶块水平推进。
升序和降序索引
对于升序索引,数据库按升序排列的顺序存储数据。默认情况下,字符数据按每个字节中包含的二进制值排序, 数值数据按从小到大排序,日期数据从早到晚排序。
CREATE INDEX emp_deptid_ix ON hr.employees(department_id);
Oracle 数据库对 hr.employees 表按 department_id 列进行排序。从 0 开始,按 department_id 列及相应的 rowid 值的升序顺序加载索引。使用此索引,数据库搜索已排序的 department_id 值,并使用相关联的 rowids 来定位包含所请求的 department_id 值的行。
通过在 CREATE INDEX 语句中指定 DESC 关键字,您可以创建一个降序索引。在这种情况下,索引在指定的一列或多列上按降序顺序存储数据。如果
在图 3-1 中 employees.department_id 列上的索引为降序,则包含 250 的叶块会在树的左侧,而 0 在右侧。降序索引的默认搜索顺序是从最高值到最低值。当要求查询按一些列升序而另一些列降序排序时,降序索引非常有用。假定您在 last_name 列和 department_id 列上创建一个复合索引,如
下所示:
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC);
一个对 hr.employees 用户查询,要求按姓氏以升序顺序 (A 到 Z) 而部门id 以降序 (从高到低)排序,则数据库可以使用此索引检索数据并避免额外的排序步骤。
键压缩
Oracle 数据库可以使用键压缩来压缩 B-树索引或索引组织表中的主键列值的部分。键压缩可以大大减少索引所使用的空间。
一般地,索引键包含两个片断,一个分组片断和一个唯一片断。键压缩将索引键分成两部分,即作为分组片断的前缀条目,和作为唯一或几乎唯一片断的后缀条目。数据库通过在一个索引块中的多个后缀条目之间共享前缀条目来实现压缩。
如果某个键未被定义为具有唯一片断,那么数据库会通过将一个 rowid 附加到分组片断来提供唯一片断
CREATE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );
在 order_mode 和 order_status 列中有许多重复值出现。一个索引块中的条目可能如示例 3-3 中所示。
示例 3-3 订单表中的索引条目
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt
示例 3-3 中,键前缀将包括 order_mode 和 order_status 的串联值。如果此索引按默认键压缩创建,那么重复键前缀(如 online,0 和online,2)将会被压缩。从概念上讲,数据库按如下示例中所示实现压缩:
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt
或者,创建一个压缩索引时,您也可以指定前缀长度。例如,如果指定了前缀长度为 1 ,那么前缀将会是 order_mode,而后缀将会是 order_status,rowid。对于示例 3-3 中的数值,索引会提取重复出现的 online 作为前缀,如下所示:
online
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
3,AAAPvCAAFAAAAFaAAq
3,AAAPvCAAFAAAAFaAAt
对索引中的每个叶块,一个特定前缀最多被存储一次。只有在 B-树索引的叶块中的键会被压缩。在分支块中的键后缀可以被截断,但不会被压缩。
我对于B-树索引的内部结构与索引类型所做的笔记的更多相关文章
- B+树索引和哈希索引的区别——我在想全文搜索引擎为啥不用hash索引而非得使用B+呢?
哈希文件也称为散列文件,是利用哈希存储方式组织的文件,亦称为直接存取文件.它类似于哈希表,即根据文件中关键字的特点,设计一个哈希函数和处理冲突的方法,将记录哈希到存储设备上. 在哈希文件中,是使用一个 ...
- MySQL B+树索引和哈希索引的区别
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BT ...
- B树、B-树、B+树、B*树【转】,mysql索引
B树 即二叉搜索树: 1.所有非叶子结点至多拥有两个儿子(Left和Right): 2.所有结点存储一个关键字: 3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树: 如: B ...
- B+树,B树,聚集索引,非聚集索引
简介: B+树中只有叶子节点会带有指向记录的指针,而B树则所有节点都带有 B+树索引可以分为聚集索引和非聚集索引 mysql使用B+树,其中Myisam是非聚集索引,innoDB是聚集索引 聚簇索引索 ...
- B+树索引和哈希索引的区别[转]
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTRE ...
- B+树原理及mysql的索引分析
转自:http://blog.csdn.net/qq_23217629/article/details/52512041 B+/-Tree原理 B-Tree介绍 B-Tree是一种多路搜索树(并不是二 ...
- MySQL B+树索引和哈希索引的区别(转 JD二面)
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTRE ...
- B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值:当然了,这个前提是,键值都是唯一的.如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到 ...
- Mysql高级操作学习笔记:索引结构、树的区别、索引优缺点、创建索引原则(我们对哪种数据创建索引)、索引分类、Sql性能分析、索引使用、索引失效、索引设计原则
Mysql高级操作 索引概述: 索引是高效获取数据的数据结构 索引结构: B+Tree() Hash(不支持范围查询,精准匹配效率极高) 树的区别: 二叉树:可能产生不平衡,顺序数据可能会出现链表结构 ...
随机推荐
- 【C++】C++中类的基本使用
1.类和成员声明,定义,初始化的基本规则 C++中类的基本模板如下: namespace 空间命名{//可以定义namespace,也可以不定义 class/struct 类名称{ public/pr ...
- 【算法】解析IEEE 754 标准
目录结构: contents structure [-] 浮点数的存储过程 次正规数(Denormalized Number) 零(zero) 非数值(NaN) 无穷大(infinity) 除数为0. ...
- 【Python】 解析Python中的运算符
Python中的运算符相比较于传统的C/C++差别不是很大,主要是一些个别的运算符上的差别.包括:算术.比较.赋值.位.逻辑.成员.身份等.它们的优先级: 符号 说明 ** 指数(最高优先级) ~,+ ...
- 构建自己的 Smart Life 私有云(一)-> 破解涂鸦智能插座
博客搬迁至https://blog.wangjiegulu.com RSS订阅:https://blog.wangjiegulu.com/feed.xml 原文链接:https://blog.wang ...
- python的类和对象(类的静态字段)
转自:http://www.cnblogs.com/Eva-J/p/5044411.html 什么是静态字段 在开始之前,先上图,解释一下什么是类的静态字段(我有的时候会叫它类的静态变量,总之说的都是 ...
- Android PopupWindow 仿微信弹出效果
项目中,我须要PopupWindow的时候特别多,这个东西也特别的好使,所以我今天给大家写一款PopupWindow 仿微信弹出效果.这样大家直接拿到项目里就能够用了! 首先让我们先看效果: 那么我首 ...
- React Native 从入门到原理一
React Native 从入门到原理一 React Native 是最近非常火的一个话题,介绍如何利用 React Native 进行开发的文章和书籍多如牛毛,但面向入门水平并介绍它工作原理的文章却 ...
- [转]剑指offer之Java源代码
一.引言 <剑指offer>可谓是程序猿面试的神书了,在面试中帮了我很多,大部分面试的算法题都会遇到原题或者是类似的题.但是书上的代码都是C版的,我在这里整理了一份Java版的代码供大家学 ...
- Pointer-network的tensorflow实现-1
pointer-network是最近seq2seq比较火的一个分支,在基于深度学习的阅读理解,摘要系统中都被广泛应用. 感兴趣的可以阅读原paper 推荐阅读 https://medium.com/@ ...
- No Ads for Blogs
最近浏览器出问题了还是博客园登录的问题. 每次进入自己博客都要输入密码. 然后进入某一篇博文查看时,底部总会有些垃圾广告. 怎么办呢. 好吧,真抱歉,为了营造良好的阅读环境,只好给你屏蔽掉了. 其实也 ...