001-CPU多级缓存架构
一、基本概念
大致关系: CPU Cache --> 前端总线 FSB (下图中的Bus) --> Memory 内存
CPU 为了更快的执行代码。于是当从内存中读取数据时,并不是只读自己想要的部分。而是读取足够的字节来填入高速缓存行。根据不同的 CPU ,高速缓存行大小不同。如 X86 是 32BYTES ,而 ALPHA 是 64BYTES 。并且始终在第 32 个字节或第 64 个字节处对齐。这样,当 CPU 访问相邻的数据时,就不必每次都从内存中读取,提高了速度。 因为访问内存要比访问高速缓存用的时间多得多。
1.1、总线概念
前端总线(FSB)就是负责将CPU连接到内存的一座桥,前端总线频率则直接影响CPU与内存数据交换速度,如果FSB频率越高,说明这座桥越宽,可以同时通过的车辆越多,这样CPU处理的速度就更快。目前PC机上CPU前端总线频率有533MHz、800MHz、1066MHz、1333MHz、1600MHz等几种,前端总线频率越高,CPU与内存之间的数据传输量越大。
前端总线——Front Side Bus(FSB),是将CPU连接到北桥芯片的总线。选购主板和CPU时,要注意两者搭配问题,一般来说,前端总线是由CPU决定的,如果主板不支持CPU所需要的前端总线,系统就无法工作
1.2、 频率与降频概念
只支持1333内存频率的cpu和主板配1600内存条就会降频。核心数跟ddr2和ddr3没关系,核心数是cpu本身的性质,cpu是四核的就是四核的,是双核的就是双核的。
如果只cpu支持1333,而主板支持1600,那也会降频;cpu支持1600而主板只支持1333那不仅内存会降频,而且发挥不出cpu全部性能。
另外如果是较新的主板cpu,已经采用新的qpi总线,而不是以前的fsb总线。
以前的fsb总线一般是总线为多少就支持多高的内存频率。而qpi总线的cpu集成了内存控制器,5.0
gt/s的cpu可能只支持1333内存频率,但是总线带宽相当于1333内存的内存带宽的两倍,这时候,组成1333双通道,内存速度就会翻倍,相当于2666的内存频率。
1.3、cache line
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。
1.4、cpu内存架构
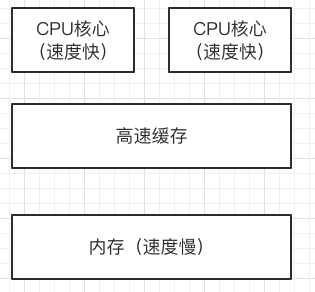
1.5、CPU多级缓存架构-现代CPU多级缓存
高速缓存L1、L2、L3;
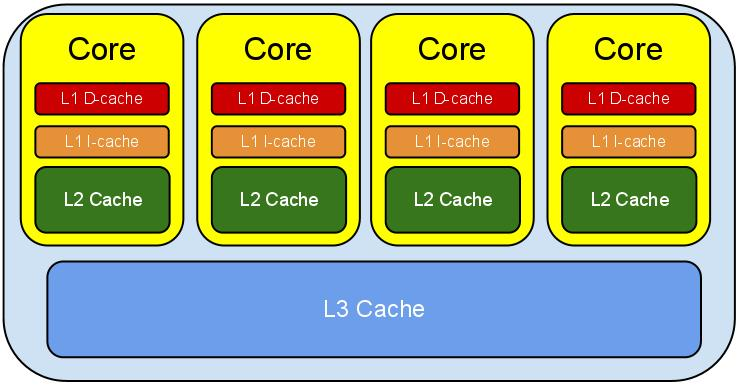
级别越小的缓存,越接近CPU, 意味着速度越快且容量越少。
L1是最接近CPU的,它容量最小,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache);
L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。
L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
当CPU运作时,它首先去L1寻找它所需要的数据,然后去L2,然后去L3。如果三级缓存都没找到它需要的数据,则从内存里获取数据。寻找的路径越长,耗时越长。所以如果要非常频繁的获取某些数据,保证这些数据在L1缓存里。这样速度将非常快。下表表示了CPU到各缓存和内存之间的大概速度:
从CPU到 大约需要的CPU周期 大约需要的时间(单位ns)
寄存器 1 cycle
L1 Cache ~3-4 cycles ~0.5-1 ns
L2 Cache ~10-20 cycles ~3-7 ns
L3 Cache ~40-45 cycles ~15 ns
跨槽传输 ~20 ns
内存 ~120-240 cycles ~60-120ns
另外需要注意的是,L3 Cache和L1,L2 Cache有着本质的区别。,L1和L2 Cache都是每个CPU core独立拥有一个,而L3 Cache是几个Cores共享的,可以认为是一个更小但是更快的内存。
可以通过cpu-z查看或者linux通过命令查看
有了上面对CPU的大概了解,我们来看看缓存行(Cache line)。缓存,是由缓存行组成的。一般一行缓存行有64字节(由上图"64-byte line size"可知)。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
1.6、缓存一致性
试想下面这样一个情况。
1、 CPU1 读取了一个字节,以及它和它相邻的字节被读入 CPU1 的高速缓存。
2、 CPU2 做了上面同样的工作。这样 CPU1 , CPU2 的高速缓存拥有同样的数据。
3、 CPU1 修改了那个字节,被修改后,那个字节被放回 CPU1 的高速缓存行。但是该信息并没有被写入 RAM 。
4、 CPU2 访问该字节,但由于 CPU1 并未将数据写入 RAM ,导致了数据不同步。
为了解决这个问题,芯片设计者制定了一个规则。当一个 CPU 修改高速缓存行中的字节时,计算机中的其它 CPU 会被通知,它们的高速缓存将视为无效。于是,在上面的情况下, CPU2 发现自己的高速缓存中数据已无效, CPU1 将立即把自己的数据写回 RAM ,然后 CPU2 重新读取该数据。 可以看出,高速缓存行在多处理器上会导致一些不利。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多核的Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
注意:
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
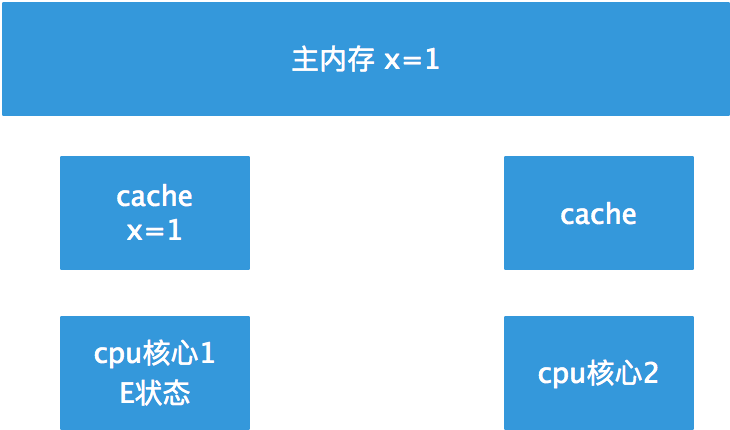
S:shared状态:每个核心的缓存都一样,且与内存一致:

M和I状态:其中一个核心修改了值,那么其他的核心的缓存失效

四钟状态的更新路线图

高效的状态: E, S
低效的状态: I, M
这四种状态,保证CPU内部的缓存数据是一致的,但是,并不能保证是强一致性。
每个cache的控制器不仅知道自己的读写操作,而且也要监听其它cache的读写操作。
理解该图的前置说明:
1.触发事件
| 触发事件 | 描述 |
|---|---|
| 本地读取(Local read) | 本地cache读取本地cache数据 |
| 本地写入(Local write) | 本地cache写入本地cache数据 |
| 远端读取(Remote read) | 其他cache读取本地cache数据 |
| 远端写入(Remote write) | 其他cache写入本地cache数据 |
2.cache分类:
前提:所有的cache共同缓存了主内存中的某一条数据。
本地cache:指当前cpu的cache。
触发cache:触发读写事件的cache。
其他cache:指既除了以上两种之外的cache。
注意:本地的事件触发 本地cache和触发cache为相同。
上图的切换解释:
| 状态 | 触发本地读取 | 触发本地写入 | 触发远端读取 | 触发远端写入 |
|---|---|---|---|---|
| M状态(修改) | 本地cache:M 触发cache:M 其他cache:I |
本地cache:M 触发cache:M 其他cache:I |
本地cache:M→E→S 触发cache:I→S 其他cache:I→S 同步主内存后修改为E独享,同步触发、其他cache后本地、触发、其他cache修改为S共享 |
本地cache:M→E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 同步和读取一样,同步完成后触发cache改为M,本地、其他cache改为I |
| E状态(独享) | 本地cache:E 触发cache:E 其他cache:I |
本地cache:E→M 触发cache:E→M 其他cache:I 本地cache变更为M,其他cache状态应当是I(无效) |
本地cache:E→S 触发cache:I→S 其他cache:I→S 当其他cache要读取该数据时,其他、触发、本地cache都被设置为S(共享) |
本地cache:E→S→I 触发cache:I→S→E→M 其他cache:I→S→I 当触发cache修改本地cache独享数据时时,将本地、触发、其他cache修改为S共享.然后触发cache修改为独享,其他、本地cache修改为I(无效),触发cache再修改为M |
| S状态(共享) | 本地cache:S 触发cache:S 其他cache:S |
本地cache:S→E→M 触发cache:S→E→M 其他cache:S→I 当本地cache修改时,将本地cache修改为E,其他cache修改为I,然后再将本地cache为M状态 |
本地cache:S 触发cache:S 其他cache:S |
本地cache:S→I 触发cache:S→E→M 其他cache:S→I 当触发cache要修改本地共享数据时,触发cache修改为E(独享),本地、其他cache修改为I(无效),触发cache再次修改为M(修改) |
| I状态(无效) | 本地cache:I→S或者I→E 触发cache:I→S或者I →E 其他cache:E、M、I→S、I 本地、触发cache将从I无效修改为S共享或者E独享,其他cache将从E、M、I 变为S或者I |
本地cache:I→S→E→M 触发cache:I→S→E→M 其他cache:M、E、S→S→I |
既然是本cache是I,其他cache操作与它无关 | 既然是本cache是I,其他cache操作与它无关 |
下图示意了,当一个cache line的调整的状态的时候,另外一个cache line 需要调整的状态。
| M | E | S | I | |
|---|---|---|---|---|
| M | × | × | × | √ |
| E | × | × | × | √ |
| S | × | × | √ | √ |
| I | √ | √ | √ | √ |
查看地址:https://www.cnblogs.com/jokerjason/p/9584402.html
3、内存分析
工具:Memory Analyzer Tool,MAT,或者JProfiler
分析代码:
package com.lhx.cloud; /**
* @author lihongxu
* @since 2019/4/5 上午10:39
*/
public class L1CacheMiss {
private static final int RUNS = 10;
private static final int DIMENSION_1 = 1024 * 1024;
private static final int DIMENSION_2 = 6; private static long[][] longs; public static void main(String[] args) throws Exception {
Thread.sleep(10000);
longs = new long[DIMENSION_1][];
for (int i = 0; i < DIMENSION_1; i++) {
longs[i] = new long[DIMENSION_2];
for (int j = 0; j < DIMENSION_2; j++) {
longs[i][j] = 1L;
}
}
System.out.println("starting...."); long sum = 0L;
for (int r = 0; r < RUNS; r++) { final long start = System.nanoTime(); //// slow
// for (int j = 0; j < DIMENSION_2; j++) {
// for (int i = 0; i < DIMENSION_1; i++) {
// sum += longs[i][j];
// }
// } //fast
for (int i = 0; i < DIMENSION_1; i++) {
for (int j = 0; j < DIMENSION_2; j++) {//每次取出6个相加
sum += longs[i][j];
}
} System.out.println((System.nanoTime() - start)/1000000.0); } System.out.println("sum:"+sum);
while (true){
Thread.sleep(1000);
} }
}
64位系统,Java数组对象头固定占16字节(压缩后16,压缩前24,默认压缩),而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度:
每次开始内循环时,从内存抓取的数据块实际上覆盖了longs[i][0]到longs[i][5]的全部数据(刚好64字节)。因此,内循环时所有的数据都在L1缓存可以命中,遍历将非常快。
那么将会造成大量的缓存失效。因为每次从内存抓取的都是同行不同列的数据块(如longs[i][0]到longs[i][5]的全部数据),但循环下一个的目标,却是同列不同行(如longs[0][0]下一个是longs[1][0],造成了longs[0][1]-longs[0][5]无法重复利用)。运行时间的差距如下图,单位是微秒(us):
最后,我们都希望需要的数据都在L1缓存里,但事实上经常事与愿违,所以缓存失效 (Cache Miss)是常有的事,也是我们需要避免的事。
一般来说,缓存失效有三种情况:
1. 第一次访问数据, 在cache中根本不存在这条数据, 所以cache miss, 可以通过prefetch解决。
2. cache冲突, 需要通过补齐来解决(伪共享的产生)。
3. cache满, 一般情况下我们需要减少操作的数据大小, 尽量按数据的物理顺序访问数据。
001-CPU多级缓存架构的更多相关文章
- 并发编程二、CPU多级缓存架构与MESI协议的诞生
前言: 文章内容:线程与进程.线程生命周期.线程中断.线程常见问题总结 本文章内容来源于笔者学习笔记,内容可能与相关书籍内容重合 偏向于知识核心总结,非零基础学习文章,可用于知识的体系建立,核心内容 ...
- Java高并发--CPU多级缓存与Java内存模型
Java高并发--CPU多级缓存与Java内存模型 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 CPU多级缓存 为什么需要CPU缓存:CPU的频率太快,以至于主存跟 ...
- Redis 多级缓存架构和数据库与缓存双写不一致问题
采用三级缓存:nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构 时效性要求非常高的数据:库存 一般来说,显示的库存,都是时效性要求会相对高一些,因为随着商品的不断的交易,库存 ...
- 并发与高并发(三)-CPU多级缓存の乱序执行优化
一.CPU多级缓存-乱序执行优化 处理器或编译器为提高运算速度而做出违背代码原有顺序的优化. 重排序遵循原则as-if-serial as-if-serial语义:不管怎么重排序(编译器和处理器为了提 ...
- cpu多级缓存
CPU cache: CPU的频率太快,主存跟不上,在处理器时钟周期内,CPU需要等待主存,浪费资源.cpu cache的出现,缓解了cpu与主存之间速度不匹配的问题. CPU cache的特性: 1 ...
- 2-2+CPU多级缓存-乱序执行优化
- 2-1 CPU多级缓存-缓存一致性.mkv
- 4. 异步多级缓存架构+nginx数据本地化渲染
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
随机推荐
- docker 命令集
1.提交本地镜像到远程cd to dockerfile directorysudo docker build -t orange5 ./sudo docker psdocker tag 1adec2c ...
- Android设备真实DPI与系统标示DPI——ldpi/mdpi/hdpi/xhdpi/xxhdpi/xxxhdpi
1.设备真实DPI与系统标示DPI 2.drawable允许的标示DPI值 drawable文件的合法名称如下: 3.如何验证 Demo如下,建立不同dpi的drawa ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 解決中文地址Uri.IsWellFormedUriString返回false
數字和大小寫字母都ok,但是中文地址就會有問題 public bool IslocalURL(string url) { if (string.IsNullOrEmpty(url)) { return ...
- 通过JS页面唤醒app(安卓+ios)
var browser = { versions: function () { var u = navigator.userAgent, app = navigator.appVersion; ret ...
- C#学习笔记(36)——事件传值(非常牛逼!)
说明(2018-4-9 23:01:20): 1. 这个真的想了很久,从晚上八点半写完上一篇博客,一直想到现在11点,以为没有办法实现了,结果看到一篇CSDN的文章,虽然没有看明白,但是看到一行代码后 ...
- mac使用minikube
brew install kubectl 需要加代理! minikube start --vm-driver=xhyve --docker-env HTTP_PROXY=http://your-htt ...
- HDFS: The short-circuit local reads feature cannot be used
问题: method:org.apache.hadoop.hdfs.DomainSocketFactory.<init>(DomainSocketFactory.java:69) The ...
- 【Excel】读取固定长文本
'******************************************************************************* ' 固定長形式テキストファイルを読み込 ...
- c# 正则
Regex reg = new Regex("^do(es)(xy)?$"); var result = reg.Match("doesxy"); foreac ...