LR和SVM的区别
一、相同点
第一,LR和SVM都是分类算法(SVM也可以用与回归)
第二,如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
这里要先说明一点,那就是LR也是可以用核函数的。总之,原始的LR和SVM都是线性分类器,这也是为什么通常没人问你决策树和LR什么区别,你说一个非线性分类器和一个线性分类器有什么区别?
第三,LR和SVM都是监督学习算法。
第四,LR和SVM都是判别模型。
这里简单讲解一下判别模型和生成模型的差别:
判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。常见的判别式模型有线性回归模型、线性判别分析、支持向量机SVM、神经网络、boosting、条件随机场等。
举例:要确定一个羊是山羊还是绵羊,用判别模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,即:
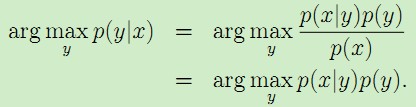
常见的生成式模型有 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA、高斯、混合多项式、专家的混合物、马尔可夫的随机场
举例:利用生成模型是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,在放到绵羊模型中看概率是多少,哪个大就是哪个。
考虑这样一个例子,假设给定动物的若干个特征属性,我们希望通过这些特征学习给定的一个“个体”到底是属于“大象”(y=1)还是“狗”(y=0)
如果采用判别模型的思路,如逻辑回归,我们会根据训练样本数据学习类别分界面,然后对于给定的新样本数据,我们会判断数据落在分界面的哪一侧从而来判断数据究竟是属于“大象”还是属于“狗”。在这个过程中,我们并不会关心,究竟“大象”这个群体有什么特征,“狗”这个群体究竟有什么特征。
现在我们来换一种思路,我们首先观察“大象”群体,我们可以根据“大象”群体特征建立模型,然后再观察“狗”群体特征,然后再建立“狗”的模型。当给定新的未知个体时,我们将该个体分别于“大象”群体和“狗”群体模型进行比较,看这个个体更符合哪个群体模型的特征。
所以分析上面可知,判别模型是直接学习p(y|x) 或者直接从特征空间学习类别标签,生成分类决策面;生成模型是对类别模型进行学习,即学习p(x|y) (每一类别数据的特征模型)和p(y) (别类概率)。如在上面的例子中,对于“大象”群体,特征分布可以表示为p(x|y=1) ,对“狗”群体建立特征模型p(x|y=0) 假设类别概率分布p(y) 是已知的,那么我们可以通过贝叶斯公式,对给定数据特征x 的类别后验概率推导为,
第五,LR和SVM在学术界和工业界都广为人知并且应用广泛。
二、不同点
第一,本质上是其loss function不同
逻辑回归的损失函数:

支持向量机的目标函数:

逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
第二,支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局(远离的点对边界线的确定也起作用,虽然作用会相对小一些)
SVM决策面的样本点只有少数的支持向量,当在支持向量外添加或减少任何样本点对分类决策面没有任何影响:
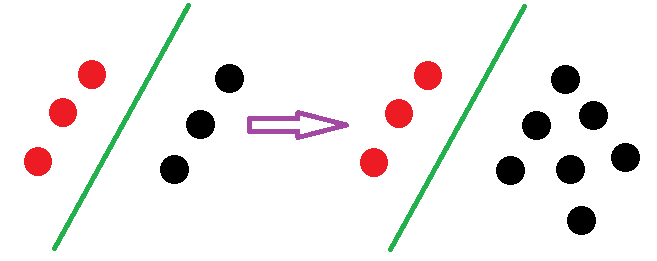
LR中,每个样本点都会影响决策面的结果。用下图进行说明:
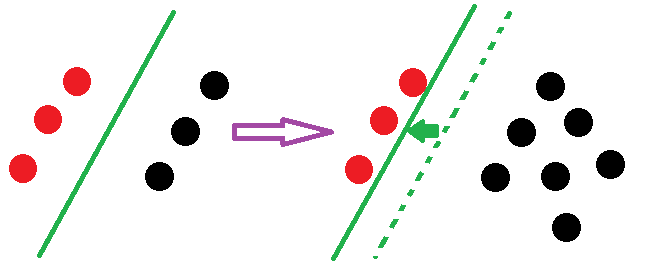
由上得知:线性SVM不直接依赖于数据分布,分类平面不受非支持向量点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing
第三,在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法
这个问题理解起来非常简单。分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。通过上面的第二点不同点可以了解,在计算决策面时,SVM算法里只有少数几个代表支持向量的样本参与了计算,也就是只有少数几个样本需要参与核计算。然而,LR算法里,每个样本点都必须参与决策面的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制
第四,线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响
一个基于概率,一个基于距离!
第五,SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!
所谓结构风险最小化,意思就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,从而达到真实误差的最小化。未达到结构风险最小化的目的,最常用的方法就是添加正则项,SVM的目标函数里居然自带正则项!!!
LR和SVM的区别的更多相关文章
- 机器学习-LR推导及与SVM的区别
之前整理过一篇关于逻辑回归的帖子,但是只是简单介绍了一下了LR的基本思想,面试的时候基本用不上,那么这篇帖子就深入理解一下LR的一些知识,希望能够对面试有一定的帮助. 1.逻辑斯谛分布 介绍逻辑斯谛回 ...
- [笔记]LR和SVM的相同和不同
之前一篇博客中介绍了Logistics Regression的理论原理:http://www.cnblogs.com/bentuwuying/p/6616680.html. 在大大小小的面试过程中,经 ...
- LR与SVM的异同
原文:http://blog.sina.com.cn/s/blog_818f5fde0102vvpy.html 在大大小小的面试过程中,多次被问及这个问题:“请说一下逻辑回归(LR)和支持向量机(SV ...
- LR和SVM的相同和不同
之前一篇博客中介绍了Logistics Regression的理论原理:http://www.cnblogs.com/bentuwuying/p/6616680.html. 在大大小小的面试过程中,经 ...
- 如何选择分类器?LR、SVM、Ensemble、Deep learning
转自:https://www.quora.com/What-are-the-advantages-of-different-classification-algorithms There are a ...
- KNN和SVM的区别和联系
先从两者的相同点来看吧,两者都是比较经典的机器学习分类算法,都属于监督学习算法,都对机器学习的算法选择有着重要的理论依据. 区别: 1 KNN对每个样本都要考虑.SVM是要去找一个函数把达到样本可分. ...
- LR、SVM、RF、GBDT、XGBoost和LightGbm比较
正则化 L1范数 蓝色的是范数的解空间,红色的是损失函数的解空间.L2范数和损失函数的交点处一般在坐标轴上,会使\(\beta=0\),当然并不一定保证交于坐标轴,但是通过实验发现大部分可以得到稀疏解 ...
- LR问题集合
LR如何解决低维不可分 特征映射:通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些.具体方法:核函数,如:高斯核,多项式核等等. 从图模型角度看 ...
- 机器学习常见面试题—支持向量机SVM
前言 总结了2017年找实习时,在头条.腾讯.小米.搜狐.阿里等公司常见的机器学习面试题. 支持向量机SVM 关于min和max交换位置满足的 d* <= p* 的条件并不是KKT条件 Ans: ...
随机推荐
- Linux内核分析第七周总结
第七章 可执行程序的装载 可执行程序的生成 可执行程序的生成: c语言代码--->经过编译器的预处理--->编译成汇编代码--->由汇编器编译成目标代码--->链接成可执行文件 ...
- 小学四则运算APP 第一阶段冲刺
需求分析 1.相关系统分析员向用户初步了解需求,然后用word列出要开发的系统的大功能模块,每个大功能模块有哪些小功能模块,对于有些需求比较明确相关的界面时,在这一步里面可以初步定义好少量的界面.[1 ...
- Visual Studio 2017 社区版的安装与组件修改(C++)
0. 环境描述 需求:用VS2017做C++简易开发. 操作系统:Windows 8.1. 1. 下载 MSDN下载VS2017社区版. https://msdn.itellyou.cn/ 下载后: ...
- Kitematic when login show Error:Tunning socket could not be established
https://cn.bing.com/search?q=tunning+socket+could+not+be+established&qs=n&form=QBRE&sp=- ...
- Hot code replace (HCR)
https://wiki.eclipse.org/FAQ_What_is_hot_code_replace%3F https://zhidao.baidu.com/question/195505558 ...
- [cnblog新闻]历史性时刻:云硬件支出首次高于传统硬件
https://news.cnblogs.com/n/617487/ 据调研公司 IDC 声称,2018 年第三季度云硬件支出占 IT 总收入的 50.9%. 知名调研公司 IDC 声称,面向云的 I ...
- [cnbeta]华为值多少钱,全世界非上市公司中估值最高的巨头
华为值多少钱,全世界非上市公司中估值最高的巨头 https://www.cnbeta.com/articles/tech/808203.htm 小米.美团都曾表达过不想.不急于上市,但没人信,所以 ...
- [代码]Delphi实现窗体内嵌其他应用程序窗体
实现原理是启动一个应用程序,通过ProcessID得到窗体句柄,然后对其设定父窗体句柄为本程序某控件句柄(本例是窗体内一个Panel的句柄),这样就达成了内嵌的效果. 本文实现的是内嵌一个记事本程序, ...
- 激活win10专业版
每180天激活一次
- NOIP2018滚粗记
NOIP2018滚粗记 day 0 上午,说是可以休息,然后睡到快9点起来吃个早饭去了机房.刷了几个板子就十二点了 下午大概就是看别人总结,颓知乎,完全没心思写代码. 晚上不要求,然后在寝室颓了一下, ...