Python高级网络编程系列之终极篇---自己实现一个Web框架
通过前面几个小节的学习,现在我们想要把之前学到的知识点给串联起来,实现一个很小型的Web框架。虽然很小,但是用到的知识点都是比较多的。如Socket编程,装饰器传参在实际项目中如何使用。通过这一节的学习,希望能把我们以前的知识点掌握的更加牢靠!
一、客户端与服务器通信过程
在这里我们以浏览器来说明访问服务器时,会做什么处理!
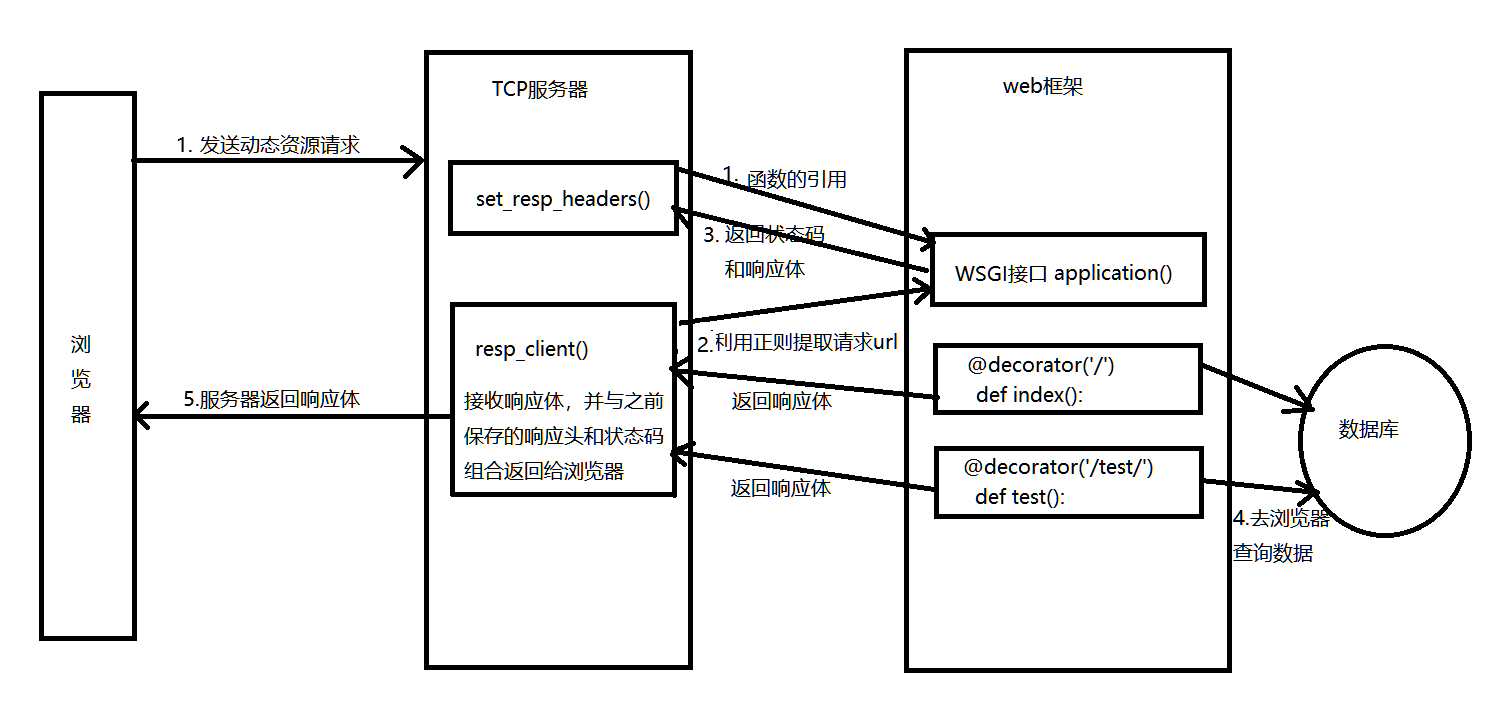
说明:
TCP服务器:
1. 服务器主要是用来处理客户端的连接请求,然后把请求的url,传递给框架来处理具体的逻辑;
2. 服务器中需要定义一个处理响应头和状态码的函数,并作为参数传递给web框架的接口;
3. 服务器与web框架之间的通信主要是通过WSGI协议提供的接口,这样他们各司其职,耦合度很低
web框架:
在框架中需要解决的难题:
如何把url与相应的函数建立起关联?
浏览器发送不同的请求需要被不同的函数截取,并返回响应体。通过装饰器传递参数的方式就可以把url与函数建立对应关系。装饰器中的参数就是用来匹配url的。
二、代码实现
服务器端:
import logging
import socket
import select
import re
import wsgi_web
logging.basicConfig(level=logging.WARNING,
filename='./web框架日志.txt',
filemode='w',
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
class WebServer:
"""创建一个Web服务器"""
def __init__(self):
# 1.创建tcp socket
self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2.设置地址可重用
self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 3.绑定到某个端口
self.tcp_socket.bind(('', 6060))
# 4.设置监听队列
self.tcp_socket.listen(128)
def run(self):
"""运行服务器"""
# 1.设置tcp_socket为非阻塞状态
self.tcp_socket.setblocking(False)
# 2.创建epoll对象,并注册服务器的监听事件
epoll = select.epoll()
epoll.register(self.tcp_socket.fileno(), select.EPOLLIN)
client_dict = dict()
# 3.不断遍历epoll列表,检查fd上有无事件发生
while True:
epoll_list = epoll.poll()
for fd, event in epoll_list:
if fd == self.tcp_socket.fileno():
# 有客户端来连接服务器
client_socket, client_addr = self.tcp_socket.accept()
# 注册客户端的事件
epoll.register(client_socket.fileno(), select.EPOLLIN)
# 客户端与其fd要建立关联
client_dict[client_socket.fileno()] = client_socket
else:
# 说明客户端发送数据过来
# 通过fd来处理客户端的请求
self.response_client(fd, client_dict, epoll)
def response_client(self, client_fd, client_dict, epoll):
"""处理客户端的请求"""
try:
req_heads = client_dict[client_fd].recv(1024).decode('utf-8')
except Exception as e:
logging.warning(e)
if not req_heads:
# 1.关闭客户端
client_dict[client_fd].close()
# 2.从监听队列中移除该客户端
client_dict.popitem()
# 3.取消该客户端的注册事件
epoll.unregister(client_fd)
try:
# print(req_heads.splitlines()[0])
# 1.解析客户端的请求url
match = re.match(r'[^/]+(/[^ ]*)', req_heads.splitlines()[0])
if match:
# 匹配成功
filename = match.group(1)
if filename == '/':
filename = '/index.html'
except Exception as e:
logging.warning(e)
# print('匹配数据出现了错误:{}'.format(e))
# 2.根据文件名去动态加载,然后伪装成静态页面发送
if filename.endswith('.html'):
url_params = dict()
# 1.使用WSGI接口
# 通过不同文件构造一个字典
url_params['filename'] = filename
# print(url_params)
# 定义一个函数传给框架
body = wsgi_web.application(url_params, self.resp_heads)
# 2.拼接数据然后发送给浏览器
# 构造响应头信息
# 空行
# 响应体
resp_head = 'HTTP/1.1 %s\r\n'%self.status_code
for field in self.resp_fields:
# 设置Content-Length的长度
resp_head += '%s:%s\r\n'%(field[0], field[1] if field[0] != 'Content-Length' else len(body.encode('utf-8')))
content = resp_head + '\r\n' + body
client_dict[client_fd].send(content.encode('utf-8'))
else:
# 返回静态数据
try:
f = open('./static%s'%filename, 'rb')
except Exception as e:
# 读取失败
body = 'Sorry! File not found!'
resp_head = 'HTTP/1.1 404 Not Found\r\n'
resp_head += 'Content-Length:%d\r\n'% len(body)
resp_head += '\r\n'
content = resp_head + body
client_dict[client_fd].send(content.encode('utf-8'))
# print('读取文件失败!')
logging.warning(e)
else:
# 读取成功
body = f.read()
resp_head = 'HTTP/1.1 200 OK\r\n'
resp_head += 'Content-Length:%d\r\n' % len(body)
resp_head += '\r\n'
try:
client_dict[client_fd].send(resp_head.encode('utf-8'))
client_dict[client_fd].send(body)
except Exception as e:
logging.warning(e)
def resp_heads(self, status_code, fields):
"""在框架中使用的函数,框架用来返回响应头信息"""
self.status_code = status_code
self.resp_fields = fields
def main():
"""程序入口"""
# 1.初始化服务器
server = WebServer()
# 2.运行服务器
server.run()
if __name__ == '__main__':
main()
框架部分:
# 服务器给数据,返回数据给服务器
import re
from urllib.request import unquote #解码中文,只用在浏览器自动对中文编码
import DBHelper
# 定义空字典,用来存储路径跟对应的函数引用
url_dict = dict()
# start_response框架给服务器传响应头的数据
# environ获取服务器传过来的文件路径
def application(environ, start_response):
"""返回具体展示的界面给服务器"""
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8'),
('Content-Length', '')]) # 返回响应头
# 根据不同的地址进行判断
file_name = environ['filename']
for key, func in url_dict.items():
match = re.match(key, file_name) # 地址跟规则一致
if match:
# 匹配到了
return func(match) # 调用匹配到的函数引用,返回匹配的页面内容
else:
# 说明没找到
return"不好意思,页面走丢了!"
# 装饰器传参,用来完成路由的功能
def route(url_address): # url_address表示页面的路径
"""目的自动添加路径跟匹配的函数到url字典中"""
def set_fun(func):
def call_fun(*args, **kwargs):
return func(*args, **kwargs)
# 根据不同的函数名称去添加到字典中
url_dict[url_address] = call_fun
return call_fun
return set_fun
Python高级网络编程系列之终极篇---自己实现一个Web框架的更多相关文章
- Python高级网络编程系列之第一篇
在上一篇中我们简单的说了一下Python中网络编程的基础知识(相关API就不解释了),其中还有什么细节的知识点没有进行说明,如什么是TCP/IP协议有几种状态,什么是TCP三次握手,什么是TCP四次握 ...
- Python高级网络编程系列之第二篇
在上一篇中,我们深入探讨了TCP/IP协议的11种状态,理解这些状态对我们编写服务器的时候有很大的帮助,但一般写服务器都是使用C/Java语言,因为这些语言对高并发的支持特别好.我们写的这些简单的服务 ...
- Python高级网络编程系列之基础篇
一.Socket简介 1.不同电脑上的进程如何通信? 进程间通信的首要问题是如何找到目标进程,也就是操作系统是如何唯一标识一个进程的! 在一台电脑上是只通过进程号PID,但在网络中是行不通的,因为每台 ...
- Python高级网络编程系列之第三篇
在高级篇二中,我们讲解了5中常用的IO模型,理解这些常用的IO模型,对于编写服务器程序有很大的帮助,可以提高我们的并发速度!因为在网络中通信主要的部分就是IO操作.在这一篇当中我们会重点讲解在第二篇当 ...
- python 基础网络编程2
python 基础网络编程2 前一篇讲了socketserver.py中BaseServer类, 下面介绍下TCPServer和UDPServer class TCPServer(BaseServer ...
- 猫哥网络编程系列:HTTP PEM 万能调试法
注:本文内容较长且细节较多,建议先收藏再阅读,原文将在 Github 上维护与更新. 在 HTTP 接口开发与调试过程中,我们经常遇到以下类似的问题: 为什么本地环境接口可以调用成功,但放到手机上就跑 ...
- 猫哥网络编程系列:详解 BAT 面试题
从产品上线前的接口开发和调试,到上线后的 bug 定位.性能优化,网络编程知识贯穿着一个互联网产品的整个生命周期.不论你是前后端的开发岗位,还是 SQA.运维等其他技术岗位,掌握网络编程知识均是岗位的 ...
- python之网络编程
本地的进程间通信(IPC)有很多种方式,但可以总结为下面4类: 消息传递(管道.FIFO.消息队列) 同步(互斥量.条件变量.读写锁.文件和写记录锁.信号量) 共享内存(匿名的和具名的) 远程过程调用 ...
- 网游中的网络编程系列1:UDP vs. TCP
原文:UDP vs. TCP,作者是Glenn Fiedler,专注于游戏网络编程相关工作多年. 目录 网游中的网络编程系列1:UDP vs. TCP 网游中的网络编程2:发送和接收数据包 网游中的网 ...
随机推荐
- Java 快速排序法 冒泡排序法 选择排序法 插入排序法
1.快速排序的原理: 选择一个关键值作为基准值.比基准值小的都在左边序列(一般是无序的),比基准值大的都在右边(一般是无序的). 从后往前比较,用基准值和最后一个值比较,如果比基准值小的交换位置,如果 ...
- Android开发day-01
http://note.youdao.com/noteshare?id=b7f0d55c1e5eab20bb47e5c58e683611
- java - Jsoup原理
https://blog.csdn.net/xh16319/article/details/28129845 http://www.voidcn.com/article/p-hphczsin-ru.h ...
- hive的本地安装部署,元数据存储到mysql中
要想使用Hive先要有hadoop集群的支持,使用本地把元数据存储在mysql中. mysql要可以远程连接: 可以设置user表,把localhost改为%,所有可连接.记住删除root其他用户,不 ...
- js-QuickStart-base.js
// 1.变量(Variables) var myVariable; myVariable = 'Bob'; // 数据类型 string number boolean array object // ...
- 【工具相关】Web-Sublime Text2新建立文件夹(二)
紧接着上文. 一,打开Sublime Text2. 二,在桌面上新建立一个文件夹,html5. 三,打开html5如图所示.里面有我们刚刚建立好的文件. 四,把html5文件夹拖动到sublime2中 ...
- Django ModelForm 校验数据格式
发现ModelForm很好用,用来做form表单验证效果很好.但是也要注意几点. forms的用法: 使用默认方式:继承forms.Form类,类里面的字段名称一定要和前端HTML里面的form表单里 ...
- Java并发编程(二)同步
在多线程的应用中,两个或者两个以上的线程需要共享对同一个数据的存取.如果两个线程存取相同的对象,并且每一个线程都调用了修改该对象的方法,这种情况通常成为竞争条件. 竞争条件最容易理解的例子就是:比如 ...
- Docker容器服务发现方案
一. 目的 在服务在容器中部署时,外部调用服务需要知道服务接口ip及端口号,这样导致部署时需要配置,从而增加部署的困难.本文档主要介绍如何使用ningx反向代理和consul进行自动化服务发 ...
- 洗礼灵魂,修炼python(38)--面向对象编程(8)—从算术运算符进一步认识魔法方法
上一篇文章了解了魔法方法,相信你已经归魔法方法至少有个概念了,那么今天就进一步的认识魔法方法.说这个之前,大脑里先回忆一下算术操作符. 什么是算术操作符?忘记没有?忘记了的自己倒回去看我前面的博文或者 ...