sklearn逻辑回归
sklearn逻辑回归
logistics回归名字虽然叫回归,但实际是用回归方法解决分类的问题,其形式简洁明了,训练的模型参数还有实际的解释意义,因此在机器学习中非常常见。
理论部分
设数据集有n个独立的特征x,与线性回归的思路一样,先得出一个回归多项式:
\]
但这个函数的值域是\([-\infty,+\infty]\),如果使用符号函数进行分类的话曲线又存在不连续的问题。这个时候,就要有请我们的sigmoid函数登场了,其定义如下:
\]
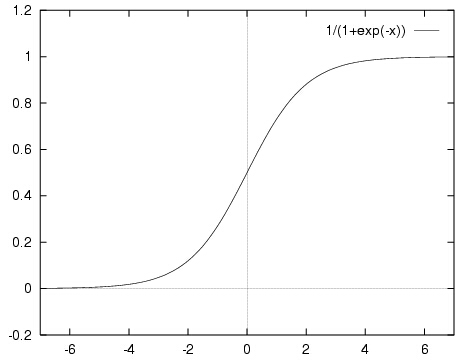
这个函数属于\([0,1]\),而且连续可导,如果把纵坐标看成概率,那么就可以根据某个对象属于某一类的概率来进行分类了。
顺着这样的思路,我们定义几率比(odds ratio):
\]
这里\(p(x)\)表示该属性组合x属于第一类(正类)的概率,对应的\(1-p(x)\)表示该属性组合x属于第二类(反类)的概率。可以解得:
\]
如果模型已经训练好,我们就可以根据w和x来求出\(p(x)\),如果\(p(x)>0.5\)就判断为正类,否则判断为反类。
之后就是训练参数的问题,可以采用极大似然估计的方法估算权重。
理论部分差不多就结束了,值得注意的是,训练出的参数\(w_i\)不光可以分类,还具有实际意义,它表示属性\(x_i\)对于总体对象属于哪一类的影响程度。因此逻辑回归虽然形式简单,但解释力比较强。
sklearn代码实现
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import linear_model
import numpy as np
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类,class=0或1
data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
X = data[['sepal length (cm)','sepal width (cm)']]
Y = data[['class']]
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
#创建回归模型对象
lr = linear_model.LogisticRegression()
lr.fit(X_train, Y_train)
#显示训练结果
print lr.coef_, lr.intercept_
print lr.score(X_test, Y_test) #score是指分类的正确率
#作图2x1
plt.subplot(211)
#区域划分
h = 0.02
x_min, x_max = X.iloc[:, 0].min() - 1, X.iloc[:, 0].max() + 1
y_min, y_max = X.iloc[:, 1].min() - 1, X.iloc[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X.loc[Y['class']==0,'sepal length (cm)']
class1_y = X.loc[Y['class']==0,'sepal width (cm)']
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class1_x = X.loc[Y['class']==1,'sepal length (cm)']
class1_y = X.loc[Y['class']==1,'sepal width (cm)']
l2 = plt.scatter(class1_x,class1_y,color='r',label=iris.target_names[1])
plt.legend(handles = [l1, l2], loc = 'best')
#做出概率分布图sigmoid
plt.subplot(212)
x0 = np.linspace(-5, 5, 200)
#与lr.predict_proba(X)[:,1]等价
plt.plot(x0,1/(1+np.exp(-x0)),linestyle = "-.",color='k')
x1 = np.dot(X[data['class']==0],lr.coef_.T)+lr.intercept_
l3 = plt.scatter(x1,1/(1+np.exp(-x1)),color='b',label=iris.target_names[0])
x2 = np.dot(X[data['class']==1],lr.coef_.T)+lr.intercept_
l4 = plt.scatter(x2,1/(1+np.exp(-x2)),color='r',label=iris.target_names[1])
plt.legend(handles = [l3, l4], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
测试结果
[[ 1.9809081 -3.2648774]] [-0.60409876]
1.0

sklearn逻辑回归的更多相关文章
- 通俗地说逻辑回归【Logistic regression】算法(二)sklearn逻辑回归实战
前情提要: 通俗地说逻辑回归[Logistic regression]算法(一) 逻辑回归模型原理介绍 上一篇主要介绍了逻辑回归中,相对理论化的知识,这次主要是对上篇做一点点补充,以及介绍sklear ...
- sklearn逻辑回归(Logistic Regression,LR)调参指南
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- sklearn逻辑回归(Logistic Regression)类库总结
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_inter ...
- sklearn逻辑回归实战
目录 题目要求 ex2data1.txt处理 方案一:无多项式特征 方案二:引入多项式特征 ex2data2.txt处理 两份数据 ex2data1.txt ex2data2.txt 题目要求 根据学 ...
- sklearn逻辑回归库函数直接拟合数据
from sklearn import model_selection from sklearn.linear_model import LogisticRegression from sklearn ...
- 机器学习入门-概率阈值的逻辑回归对准确度和召回率的影响 lr.predict_proba(获得预测样本的概率值)
1.lr.predict_proba(under_text_x) 获得的是正负的概率值 在sklearn逻辑回归的计算过程中,使用的是大于0.5的是正值,小于0.5的是负值,我们使用使用不同的概率结 ...
- 逻辑回归原理_挑战者飞船事故和乳腺癌案例_Python和R_信用评分卡(AAA推荐)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- sklearn使用——梯度下降及逻辑回归
一:梯度下降: 梯度下降本质上是对极小值的无限逼近.先求得梯度,再取其反方向,以定步长在此方向上走一步,下次计算则从此点开始,一步步接近极小值.需要注意的是步长的取值,如果过小,则需要多次迭代,耗费大 ...
- Sklearn实现逻辑回归
方法与参数 LogisticRegression类的各项参数的含义 class sklearn.linear_model.LogisticRegression(penalty='l2', dual=F ...
随机推荐
- python爬虫实例
import re import requests from bs4 import BeautifulSoup # 主方法 def main(): # 给请求指定一个请求头来模拟chrome浏览器 h ...
- JDK1.7 Update14 HotSpot虚拟机GC收集器
在测试服务器上使用如下命令可以查看当前使用的 GC收集器,当然不止这一个命令可以看到,还有其他一些方式 第三列”=”表示第四列是参数的默认值,而”:=” 表明了参数被用户或者JVM赋值了 [csii@ ...
- 前端:Jquery 处理同一Name的Radio组时,绑定checked属性异常的问题.(已解决)
将: $("input[type=radio][name=optionsContractGroup][value=201]").attr("checked",t ...
- Apache Pulsar——企业级消息订阅系统介绍
Apache Pulsar是一款由雅虎开发的类似于Kafka的企业级消息订阅系统,在2016将其开源,由Apach基金会孵化,现在已经成长为Apache基金会的顶级项目.Pulsar在雅虎内部已经运行 ...
- Codeforces 830D Singer House 动态规划
原文链接https://www.cnblogs.com/zhouzhendong/p/CF830D.html 题解 考虑用 $dp[i][j]$ 表示深度为 $i$ 的树里,有 $j$ 条路径的方案数 ...
- 2018牛客网暑假ACM多校训练赛(第十场)F Rikka with Line Graph 最短路 Floyd
原文链接https://www.cnblogs.com/zhouzhendong/p/NowCoder-2018-Summer-Round10-F.html 题目传送门 - https://www.n ...
- BZOJ3110 [Zjoi2013]K大数查询 树套树 线段树 整体二分 树状数组
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ3110 题意概括 有N个位置,M个操作.操作有两种,每次操作如果是1 a b c的形式表示在第a个位 ...
- JDK自带工具keytool生成ssl证书
前言: 因为公司项目客户要求使用HTTPS的方式来保证数据的安全,所以木有办法研究了下怎么生成ssl证书来使用https以保证数据安全. 百度了不少资料,看到JAVA的JDK自带生成SSL证书的工具: ...
- 事件(Event)(onclick,onchange,onload,onunload,onfocus,onblur,onselect,onmuse)【转载】
ylbtech-Event:事件(Event)对象 事件(Event) HTML 4.0 事件属性 onclick onchange onload onunload onselect onmouse ...
- P1433 吃奶酪 回溯法 优化
题目描述 房间里放着n块奶酪.一只小老鼠要把它们都吃掉,问至少要跑多少距离?老鼠一开始在(0,0)点处. 输入输出格式 输入格式: 第一行一个数n (n<=15) 接下来每行2个实数,表示第i块 ...