单向LSTM笔记, LSTM做minist数据集分类
单向LSTM笔记, LSTM做minist数据集分类
先介绍下torch.nn.LSTM()这个API
1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入的数据size为[batch_size, input_size])
2. hidden_size: 确定了隐含状态hidden_state的维度. 可以简单的看成: 构造了一个权重, 隐含状态
3 . num_layers: 叠加的层数。如图所示num_layers为 3
4. batch_first: 输入数据的size为[batch_size, time_step, input_size]还是[time_step, batch_size, input_size]
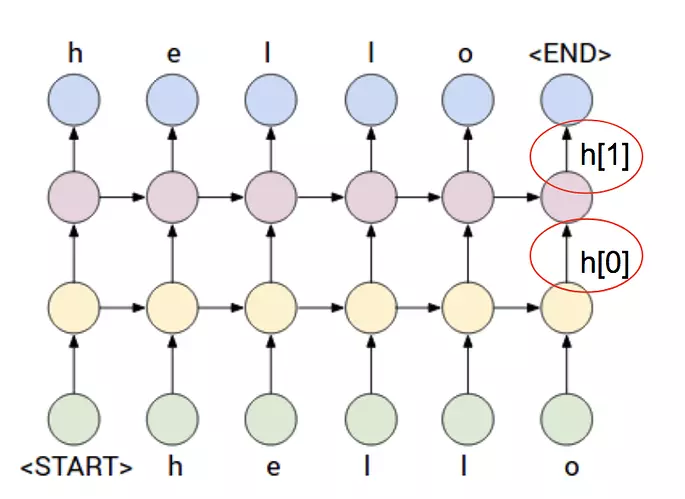
使用单向LSTM对MNIST进行分类,我是在pytorch0.4.1坂本上运行的。
########################## pytorch 用LSTM做minist数据分类 ##################
##########################################################################
import torch
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
import numpy as np BATCH_SIZE = 50 class RNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.rnn = torch.nn.LSTM(
input_size=28,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out = torch.nn.Linear(in_features=64, out_features=10) def forward(self, x):
# 一下关于shape的注释只针对单向
# output: [batch_size, time_step, hidden_size]
# h_n: [num_layers,batch_size, hidden_size] # 虽然LSTM的batch_first为True,但是h_n/c_n的第一维还是num_layers
# c_n: 同h_n
output, (h_n, c_n) = self.rnn(x)
#print(output.size())
# output_in_last_timestep=output[:,-1,:] # 也是可以的
output_in_last_timestep = h_n[-1, :, :]
# print(output_in_last_timestep.equal(output[:,-1,:])) # ture
x = self.out(output_in_last_timestep)
return x if __name__ == "__main__":
# 1. 加载数据
training_dataset = torchvision.datasets.MNIST("./mnist", train=True,
transform=torchvision.transforms.ToTensor(), download=True)
dataloader = Data.DataLoader(dataset=training_dataset,
batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
# showSample(dataloader)
test_data = torchvision.datasets.MNIST(root="./mnist", train=False,
transform=torchvision.transforms.ToTensor(), download=False)
test_dataloader = Data.DataLoader(
dataset=test_data, batch_size=1000, shuffle=False, num_workers=2)
testdata_iter = iter(test_dataloader)
test_x, test_y = testdata_iter.next()
test_x = test_x.view(-1, 28, 28)
# 2. 网络搭建
net = RNN()
# 3. 训练
# 3. 网络的训练(和之前CNN训练的代码基本一样)
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
loss_F = torch.nn.CrossEntropyLoss()
for epoch in range(3): # 数据集只迭代一次
for step, input_data in enumerate(dataloader):
x, y = input_data
pred = net(x.view(-1, 28, 28))
loss = loss_F(pred,y) # 计算loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 49: # 每50步,计算精度
with torch.no_grad():
test_pred = net(test_x)
prob = torch.nn.functional.softmax(test_pred, dim=1)
pred_cls = torch.argmax(prob, dim=1)
acc = (pred_cls == test_y).sum().numpy() / pred_cls.size()[0]
print(f"{epoch}-{step}: accuracy:{acc}")
由上面代码可以看到输出为:output,(h_n,c_n)=self.rnn(x),解释下代码中的第28行。
output: 如果num_layer为3,则output只记录最后一层 --------- 第三层的输出。
- 对应图中向上的h_t
- 其size根据
batch_first而不同。可能是[batch_size, time_step, hidden_size]或[time_step, batch_size, hidden_size]
h_n: 各个层的最后一个时步的隐含状态
h.- size为
[num_layers,batch_size, hidden_size] - 对应图中向右的h_t. 可以看出对于单层单向的LSTM, 其
h_n最后一层输出h_n[-1,:,:],和output最后一个时步的输出output[:,-1,:]相等。在示例代码中print(h_n[-1,:,:].equal(output[:,-1,:]))会打印True
- size为
c_n: 各个层的最后一个时步的隐含状态
C- c_n可以看成另一个隐含状态,size和
h_n相同
- c_n可以看成另一个隐含状态,size和
我运行了3个epoch效果如下:
0-49: accuracy:0.3
0-99: accuracy:0.596
0-149: accuracy:0.697
0-199: accuracy:0.734
0-249: accuracy:0.769
0-299: accuracy:0.782
0-349: accuracy:0.751
0-399: accuracy:0.843
0-449: accuracy:0.859
0-499: accuracy:0.87
0-549: accuracy:0.857
0-599: accuracy:0.89
0-649: accuracy:0.88
0-699: accuracy:0.883
0-749: accuracy:0.905
0-799: accuracy:0.905
0-849: accuracy:0.902
0-899: accuracy:0.901
0-949: accuracy:0.908
0-999: accuracy:0.921
0-1049: accuracy:0.917
0-1099: accuracy:0.906
0-1149: accuracy:0.941
0-1199: accuracy:0.935
1-49: accuracy:0.935
1-99: accuracy:0.936
1-149: accuracy:0.941
1-199: accuracy:0.923
1-249: accuracy:0.94
1-299: accuracy:0.936
1-349: accuracy:0.941
1-399: accuracy:0.948
1-449: accuracy:0.937
1-499: accuracy:0.939
1-549: accuracy:0.949
1-599: accuracy:0.949
1-649: accuracy:0.953
1-699: accuracy:0.947
1-749: accuracy:0.918
1-799: accuracy:0.944
1-849: accuracy:0.957
1-899: accuracy:0.959
1-949: accuracy:0.947
1-999: accuracy:0.944
1-1049: accuracy:0.961
1-1099: accuracy:0.964
1-1149: accuracy:0.961
1-1199: accuracy:0.952
2-49: accuracy:0.95
2-99: accuracy:0.952
2-149: accuracy:0.957
2-199: accuracy:0.945
2-249: accuracy:0.957
2-299: accuracy:0.953
2-349: accuracy:0.956
2-399: accuracy:0.942
2-449: accuracy:0.946
2-499: accuracy:0.962
2-549: accuracy:0.956
2-599: accuracy:0.957
2-649: accuracy:0.953
2-699: accuracy:0.958
2-749: accuracy:0.963
2-799: accuracy:0.959
2-849: accuracy:0.954
2-899: accuracy:0.961
2-949: accuracy:0.959
2-999: accuracy:0.961
2-1049: accuracy:0.962
2-1099: accuracy:0.958
2-1149: accuracy:0.955
2-1199: accuracy:0.964
主要参考:https://www.jianshu.com/p/043083d114d4
单向LSTM笔记, LSTM做minist数据集分类的更多相关文章
- TensorFlow笔记三:从Minist数据集出发 两种经典训练方法
Minist数据集:MNIST_data 包含四个数据文件 一.方法一:经典方法 tf.matmul(X,w)+b import tensorflow as tf import numpy as np ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- 用CNN及MLP等方法识别minist数据集
用CNN及MLP等方法识别minist数据集 2017年02月13日 21:13:09 hnsywangxin 阅读数:1124更多 个人分类: 深度学习.keras.tensorflow.cnn ...
- Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = ...
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- BP算法在minist数据集上的简单实现
BP算法在minist上的简单实现 数据:http://yann.lecun.com/exdb/mnist/ 参考:blog,blog2,blog3,tensorflow 推导:http://www. ...
随机推荐
- Rookey.Frame企业级极速开发框架
项目详细介绍 Rookey.Frame是一套基于.NET MVC + easyui的企业级极速开发框架,支持简单逻辑模块零代码编程.支持工作流(BPM).支持二次开发,具有高扩展性.高复用性.高伸缩性 ...
- 2016-06-18 exshop第四天
昨天本来想完成用asset-pipeline替换掉resource插件的工作,但由于进行了对spring security插件的文档解读,同时面试了4个人,每个人耗费了30分钟,并且公司下午4:30组 ...
- mongodb中投票节点作用
投票节点 并不含有 复制集中的数据集副本,且也 无法 升职为主节点.投票节点的存在是为了使复制集中的节点数量为奇数,这样保证在进行投票的时候不会出现票数相同的情况.如果添加了一个节点后,总节点数为偶数 ...
- Zabbix监控Low level discovery实时监控网站URL状态
今天我们来聊一聊Low level discovery这个功能,我们为什么要用到loe level discovery这个功能呢? 很多时候,在使用zabbix监控一些东西,需要对类似于Itens进行 ...
- php 操作数据库
$datetoday = date('Y-m-d'); $datetime = $thedate; $data_info = $data; $db = array( 'dsn' => 'mysq ...
- Codeforces Round #487 (Div. 2) 跌分有感
又掉分了 这次的笑话多了. 首先,由于CF昨天的比赛太早了,忘记了有个ER,比赛开始半个小时才发现. 于是只能今天了. 嗯哈. 今天这场也算挺早的. 嗯嗯,首先打开A题. 草草看了一遍题意,以为不是自 ...
- HDU2853 Assignment KM
原文链接http://www.cnblogs.com/zhouzhendong/p/8284105.html 题目传送门 - HDU2853 题意概括 (来自谷歌翻译) 题解 这是一道好题. 我们首先 ...
- asp.net core 使用docker默认端口修改
默认端口是80 在dockerfile文件中修改 ENV ASPNETCORE_URLS http://+:80 ------------------------------------------- ...
- HTML—xhtml和html5
一.什么是XHTML? XHTML指的是可扩展超文本标记语言: XHTML与HTML 4.01几乎是相同的: XHTML是更严格跟纯净的HTML版本: XHTML是以XML应用的方式定义的HTML: ...
- 15行Python 仿百度搜索引擎
开发工具:PyCharm 开发环境:python3.6 + flask + requests 开发流程: 1. 启动一个web服务 from flask import Flask app = Flas ...