"Linux内核分析"第六周实验报告
张文俊 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
1、进程的描述
进程控制块PCB——task_struct
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符(即task_struct)提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大
Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING
进程的标示pid
所有进程链表struct list_head tasks;
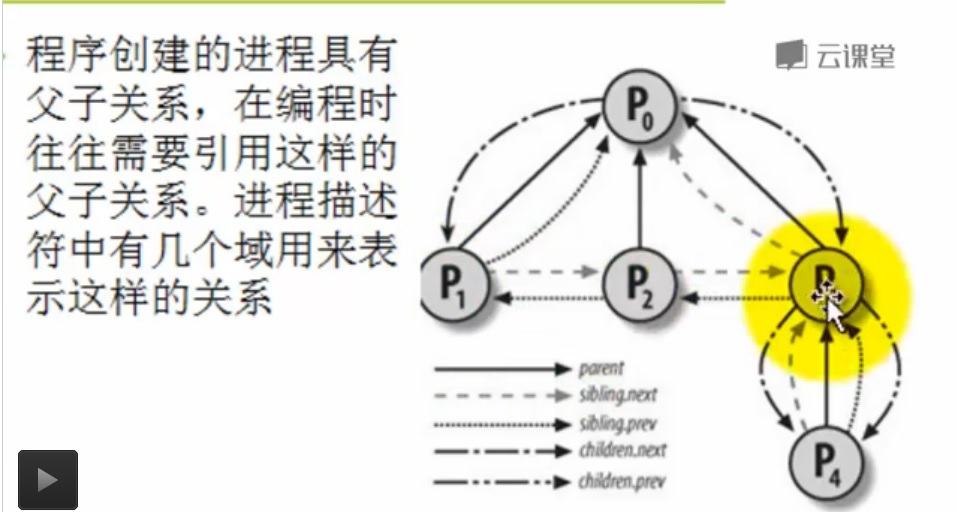
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈
内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够了
struct thread_struct thread;//CPU-specific state of this task
父子进程关系管理:
这是CPU状态,在进程上下文切换的过程中,起到关键作用:

2、进程的创建
进程的创建概览和fork一个进程的用户态代码

以fork一个子进程的代码为例:
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- int main(int argc, char * argv[])
- {
- int pid;
- /* fork another process */
- pid = fork();
- if (pid < 0)
- {
- /* error occurred */
- fprintf(stderr,"Fork Failed!");
- exit(-1);
- }
- else if (pid == 0)
- {
- /* child process */
- printf("This is Child Process!\n");
- }
- else
- {
- /* parent process */
- printf("This is Parent Process!\n");
- /* parent will wait for the child to complete*/
- wait(NULL);
- printf("Child Complete!\n");
- }
- }
可用fork系统调用在父进程和子进程各返回一次。在fork之后,这段代码实际上就变成了两个进程。
理解进程创建过程复杂代码的方法
系统调用回顾:
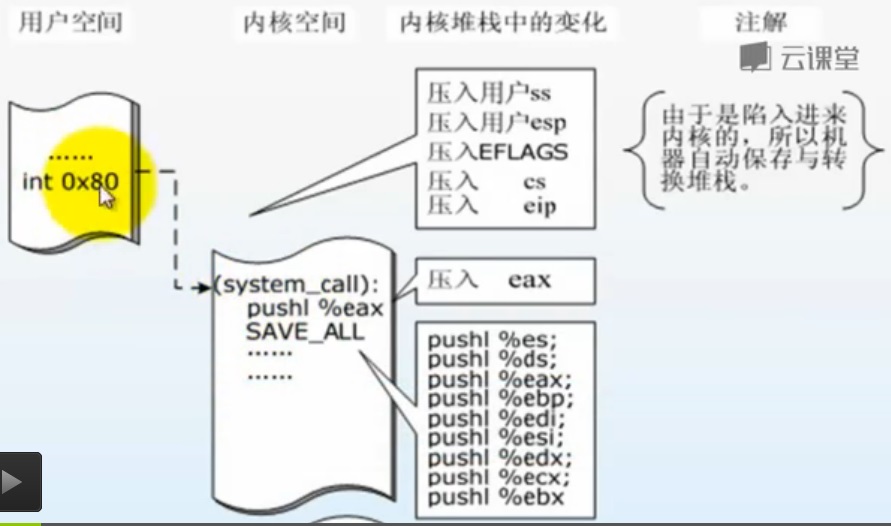
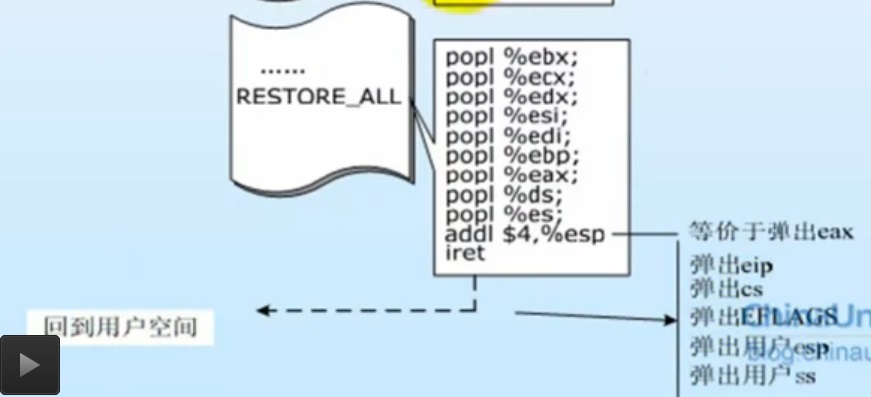

创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
复制一个PCB——task_struct
- err = arch_dup_task_struct(tsk, orig);
要给新进程分配一个新的内核堆栈
- ti = alloc_thread_info_node(tsk, node);
- tsk->stack = ti;
- setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?
这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
- *childregs = *current_pt_regs(); //复制内核堆栈
- childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
- p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
- p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
浏览进程创建过程相关的关键代码

以上为复制数据结构部分代码,dup_task_struct。这段代码相对简单,就是将src其中内容赋值给dst。
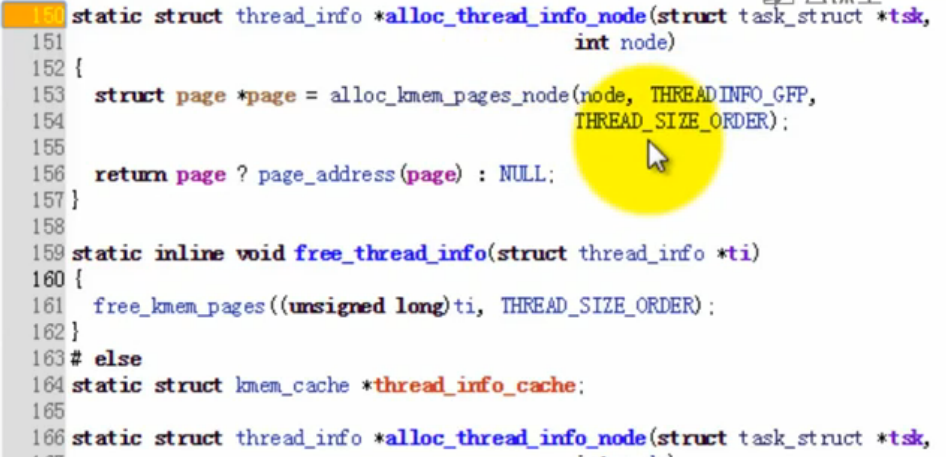
以上为alloc调用,它功能就是生成了两个页面。
重点还是看copy_thread的功能,pt_regs获取了pid指向的堆栈内信息,比如栈底等内容。
这是父进程对已有堆栈数据的copy,拷贝内核堆栈数据和指定新进程的第一条指令地址。
因为子进程的返回值为0,所以copy时还需要修改一下内核栈内压入的。
子进程是从哪里开始执行的?

子进程是从这个位置开始执行的,就是fork返回值被得到的时候。
对pt_regs内容进行查看,可以看到其中包含int指令和SAVE_ALL压到内核栈的内容。只复制了i32的相关内容。

从entry_32中,可以找到ret_from_fork的函数代码部分。
会跳到syscall_exit部分继续执行。正常返回到用户态。
使用gdb跟踪创建新进程的过程
如果用实验楼环境,首先需要rm menu -rf 删除原先menu 然后clone一份新的。
然后进入menu后,mv test_fork.c test.c,把test.c覆盖掉。
然后make rootfs,编译出来。

可以发现fork被进入到menu里。
然后使用gdb调试,使用-s -S。
然后设置断点:b sys_clone 和 b do_fork 和 b dup_task_struct 和 b copy_process 和 b copy_thread 和 b ret_from_fork
然后进行n单步调试。

可以看到子进程执行的起点。
3、总结
linux 系统创建进程都是用 fork() 系统调用创建子进程。
由 fork() 系统调用创建的新进程被称为子进程。
该函数被调用一次,但返回两次。
如果 fork()进程调用成功,两次返回的区别是子进程的返回值是0,而父进程的返回值则是新子进程的进程号。
"Linux内核分析"第六周实验报告的更多相关文章
- 《Linux内核分析》第二周学习报告
<Linux内核分析>第二周学习报告 ——操作系统是如何工作的 姓名:王玮怡 学号:20135116 第一节 函数调用堆栈 一.三个法宝 二.深入理解函数调用堆栈 三.参数传递与局部变量 ...
- LINUX内核分析第六周学习总结——进程的描述和进程的创建
LINUX内核分析第六周学习总结——进程的描述和进程的创建 张忻(原创作品转载请注明出处) <Linux内核分析>MOOC课程http://mooc.study.163.com/cours ...
- LINUX内核分析第六周学习总结——进程的描述与创建
LINUX内核分析第六周学习总结--进程的描述与创建 标签(空格分隔): 20135321余佳源 余佳源 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc ...
- linux内核分析第六周学习笔记
LINUX内核分析第六周学习总结 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程 http://mooc.study.163.c ...
- Linux内核分析第六周学习笔记——分析Linux内核创建一个新进程的过程
Linux内核分析第六周学习笔记--分析Linux内核创建一个新进程的过程 zl + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/U ...
- linux内核分析 第六周
一.进程的描述 为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息. 1.进程控制块PCB--task_struct 进程状态 进程打开的文件 进程优先级信息 2. ...
- Linux内核分析第六周学习总结:进程的描述和进程的创建
韩玉琪 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.进程的描述 ...
- 《Linux内核分析》第一周学习报告
第一周:计算机是如何工作的 姓名:王玮怡 学号:20135116 第一节 存储程序计算机工作模型(冯诺依曼体系结构) IP指向的内存地址,取指令执行,完成后,IP值自加一,取下一条指令再执行. AP ...
- Linux内核分析——第六周学习笔记20135308
第六周 进程的描述和进程的创建 一.进程描述符task_struct数据结构 1.操作系统三大功能 进程管理 内存管理 文件系统 2.进程控制块PCB——task_struct 也叫进程描述符,为了管 ...
随机推荐
- 计算机基础-BIOS
BIOS--硬件和软件的纽带(Basic Input Output System) 1.含义:基本的输入输出系统,它是一组固化到计算机内主板上的一个ROM存储芯片上的程序 2.性质:它保存着计算机最重 ...
- [Eclipse+PyDev]ImportError: DLL load failed:找不到指定的模块 解决方案
1. 环境 Eclipse 4.4.2 Python 3.5 Window 8.1 2. 问题 在代码中import numpy时,提示 " ImportError: DLL load fa ...
- css固定背景图位置 实现屏幕滚动时 显示背景图不同区域
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 如何用jquery实现实时监控浏览器宽度
如何用jquery实现实时监控浏览器宽度 2013-06-05 14:36匿名 | 浏览 3121 次 $(window).width();这代码只能获取浏览器刷新时的那一刻的宽度,如何才能达到实时获 ...
- sahrepoint 上传到文档库
sharepoint学习笔记汇总 http://blog.csdn.net/qq873113580/article/details/20390149 /// <summary&g ...
- PHP 用 fsockopen()、fputs() 来请求一个 URL,不要求返回
项目需要,场景如下: 某个条件下需要调用接口发送多个请求执行脚本,但是由于每个请求下的脚本执行时间在半个小时左右,所以 就放弃返回执行结果,只要求能秒发送所以就可以. 代码如下: /** * 发起异步 ...
- ES6生成器函数generator
ES6生成器函数generator generator是ES6新增的一个特殊函数,通过 function* 声明,函数体内通过 yield 来指明函数的暂停点,该函数返回一个迭代器,并且函数执行到 y ...
- 【Codeforces 17E】Palisection
Codeforces 17 E 题意:给一个串,求其中回文子串交叉的对数. 思路1:用哈希解决.首先求出每个点左右最长的回文串(要分奇数长度和偶数长度),然后记录经过每个点的回文串的个数,以及它们是在 ...
- jmeter(十一)JDBC Request之Query Type
工作中遇到这样一个问题: 需要准备10W条测试数据,利用jmeter中的JDBC Request向数据库中批量插入这些数据(只要主键不重复就可以,利用函数助手中的Random将主键的ID末尾五位数随机 ...
- rook 入门理解
参考:https://my.oschina.net/u/2306127/blog/1830356?from=timeline 1.Rook通过一个操作器(operator)完成后续操作,只需要定义需要 ...