Hadoop JVM调整解决 MapReduce 作业超时问题
MR汇总报错
在mr程序跑job时,reduce到一个点就卡住直到超时时间反馈超时再重试,一般都失败,如下图:
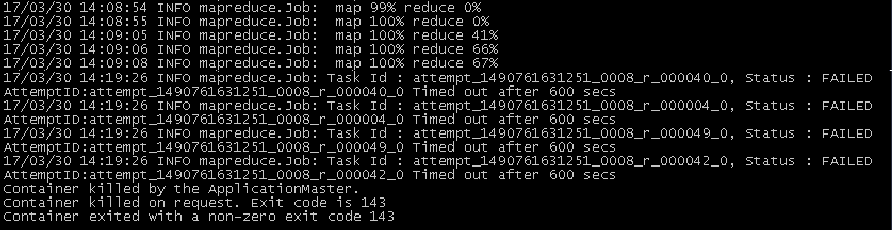
超时时间是在配置文件的默认配置:
这里的提示是Container killed by the ApplicationMaster,并没有具体参数提示。查找一些资料后发现,需要调整opts的值mapreduce.reduce.java.opts,默认4G,调试为6G测试,即值为"-Djava.net.preferIPv4Stack=true -Xmx6442450944" ,报错如下:
Container [pid=7830,containerID=container_1397098636321_27548_01_000297] is running beyond physical memory limits. Current usage: 2.1 GB of 2 GB physical memory used; 2.7 GB of 4.2 GB virtual memory used. Killing container.
这里的错误就比较明显了,物理内存不够,虚拟内存还可以(默认情况下:虚拟内存是物理内存的2.1倍)。这里是在reduce阶段有问题,所以需要调整reduce运行时的物理内存,mapreduce.reduce.memory.mb这个参数默认值为4G,调整为6144 (即6G)后,执行mr作业,正常结束。
总结了如下相关jvm设置:
参数 默认值 描述
yarn.scheduler.minimum-allocation-mb 1024 每个container请求的最低jvm配置,单位m。如果请求的内存小于该值,那么会重新设置为该值。
yarn.scheduler.maximum-allocation-mb 8192 每个container请求的最高jvm配置,单位m。如果大于该值,会被重新设置。
yarn.nodemanager.resource.memory-mb 8192 每个nodemanager节点准备最高内存配置,单位m
mapreduce.{map,reduce}.memory.mb 1024 设置运行map/reduce container的内存大小,单位m
mapreduce.{map,reduce}.java.opts -Xmx 设置执行map/reduce任务的JVM参数,值小于上一行设置的值,是在container中建立的jvm堆内存
mapreduce.map.memory.mb = (1~2倍) * yarn.scheduler.minimum-allocation-mb
mapreduce.reduce.memory.mb = (1~4倍) * yarn.scheduler.minimum-allocation-mb
总结:最终运行参数给定的jvm堆大小必须小于参数指定的map和reduce的memory大小,最好为70%以下。
Hadoop JVM调整解决 MapReduce 作业超时问题的更多相关文章
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop(六)MapReduce的入门与运行原理
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架: Mapreduce核心功能是将用 ...
- 高阶MapReduce_1_链接多个MapReduce作业
链接MapReduce作业 1. 顺序链接MapReduce作业 顺序链接MapReduce作业就是将多个MapReduce作业作为生成的一个自己主动化运行序列,将上一个MapReduce作 ...
- hadoop(四)MapReduce
如果将 Hadoop 比做一头大象,那么 MapReduce 就是那头大象的电脑.MapReduce 是 Hadoop 核心编程模型.在 Hadoop 中,数据处理核心就是 MapReduce 程序设 ...
随机推荐
- C. Alyona and mex
http://codeforces.com/contest/740/problem/C 构造思维题. 第一直觉就是区间长度+1的最小值就是答案. 然而不知道怎么去构造这个序列. 其实就是每个区间,都要 ...
- 前端之CSS创建的样式
CSS即层叠样式表,在创建时有以下几种样式: 1.内联样式(行内样式.行间样式): <标记 style=“属性:属性值:”></标记> 2.内部样式(嵌入式样式): <s ...
- web前端工程师入门须知
本文是写给那些想要入门web前端工程的初学者,高手请路过,也欢迎高手们拍砖. 先说下web前端工程师的价值,目前web产品交互越来越复杂,用户使用体验和网站前端性能优化这些都得靠web前端工程师去做w ...
- EXCEL Skills Commonly Used
1. 判断某一列中的数据是否在另一列中 http://jingyan.baidu.com/article/358570f67fd4b0ce4724fc29.html 2. 快速删除excel中的空格( ...
- Codeforces Round #539 (Div. 2) C. Sasha and a Bit of Relax(前缀异或和)
转载自:https://blog.csdn.net/Charles_Zaqdt/article/details/87522917 题目链接:https://codeforces.com/contest ...
- Python3简明教程(十四)—— Collections模块
collections 是 Python 内建的一个集合模块,提供了许多有用的集合类. 在这个实验我们会学习 Collections 模块.这个模块实现了一些很好的数据结构,它们能帮助你解决各种实际问 ...
- jeecms
===标签=== <!-- 显示一级栏目对应的二级栏目 --> <!-- [@cms_channel_list parentId=c.id] [#if tag_list?size&g ...
- JVM 内存区域方面的面试题
https://mp.weixin.qq.com/s/TpCElutqVSt7PAzjrGz12w 写在前面(常见面试题) 基本问题 •介绍下 Java 内存区域(运行时数据区)•Java 对象的创建 ...
- Hbase数据库简介
Hbase是基于Hadoop下分布式存储 数据库,列式存储.(https://www.imooc.com/video/17202) 动态的增加列,不像关系数据库需要提前定义好列. 关系数据库 ...
- Activiti6简明教程
一.为什么选择Activiti 工作流引擎对比 二.核心7大接口.28张表 7大接口 (一)7大接口 RepositoryService:提供一系列管理流程部署和流程定义的API. RuntimeSe ...