6-7 adaboost分类器1
如何利用特征来区分目标,进行阈值判决。adaboost分类器它的优点在于前一个基本分类器分出的样本,在下一个分类器中会得到加强。加强后全体的样本那么再次进行整个训练。加强后的全体样本再次被用来训练下一个基本的分类器。
我们正确的样本它的系数逐渐地减小,而我们的负样本得到了加强。这就是adaboost它的优点。它的优点就是能够自适应这种过程。它能够把每一次检测中出错的负样本进行加强,那么再把整个结果算到下一个基本的分类器中。那么一轮一轮不停地循环。所以这里还有一个问题,叫循环的终止条件或者叫训练的终止条件。迭代的最大次数也就是我们循环的最大次数,如果最大次数大于某一个值,那么这个时候迭代终止。第二,每一次迭代完之后它有一个检测概率,比如说这一次训练完之后,三个苹果已经检测出来,而香蕉检测出来的是错误的。那么这个时候正确的检测概率就是75%。所以它有一个最小的检测概率。如果当这个训练过程大于这个最小的检测概率,那么整个训练就结束。这是训练的终止条件。
分类器的结构。就是我们训练完之后如何来用这个分类器。opencv自带的人脸识别的adaboost训练分类器它的文件结构。
Haar特征计算完之后,需要对Haar特征进行阈值判决。因此它实际上就是一个个的判决过程。有的时候通过一级分类器并不能把这个目标给区分出来。多级级联,每一级都通过这个阈值判决。两级分类器的阈值,分别是T1和T2。
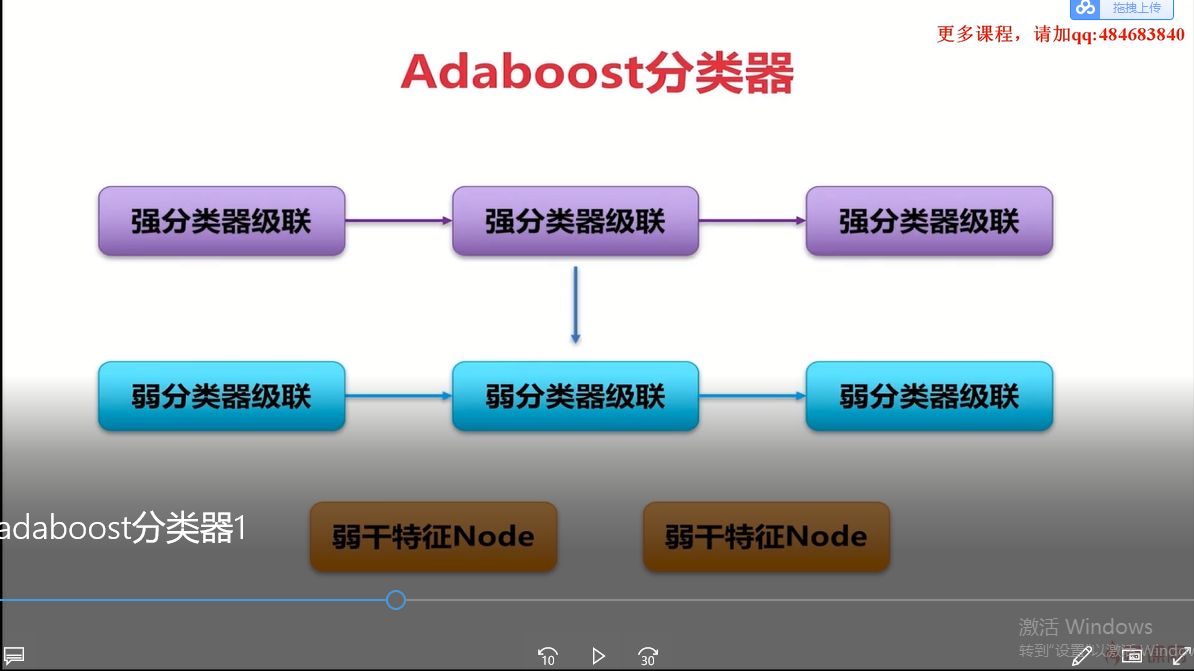
每一个强分类器它会计算出一个独立的特征点。使用这个独立的特征来对每一个强分类器进行阈值判决。每一个强分类器也有一个自己的阈值判决。
这是3个强分类器级联以及三个强分类器它的阈值。三个强分类器全部通过之后,那么就认为是我们的目标。三个强分类器只要有任何一个不通过,那么这个时候它就认为是非苹果。所以这是强分类器的概念。那么这个阈值如何得到呢?阈值就是通过我们刚刚的训练。每一级训练的话它会产生一系列的阈值。训练的数据就来源于我们之前的样本。终止条件可以通过for循环循环次数或者是误差概率小于一定的值的时候,就会终止当前的循环。
可以看到,一个级联的adaboost分类器,它是由若干个强分类器组成。其实每一个强分类器,它又由若干个弱分类器组成。一个强分类器又可以分解成为若干个弱分类器。而一个弱分类器又可以分解成为若干个Node结点。所以它是层层的结点结构,总共有三层结构。
强分类器它的作用是用来判决当前的阈值与当前的特征是否吻合来达到目标判决的效果。弱分类器的作用是用来计算强分类器的特征。注意,这里有个本质的区别,强分类器是通过强分类器中计算的结果,然后阈值进行判决,最后得到当前的目标是否是苹果。而弱分类器它的作用是来计算强分类器的特征。所以当前的强分类器它的x1、x2、x3特征,是由弱分类器计算得到。
在opencv中,一个弱分类器最高支持三个Haar特征。而在三个Haar特征中,每一个Haar特征构成了一个Node结点。所以三个Haar特征分别对应的是3个Node结点。每一个特征都看做是一个结点。
每一个Node结点对应一个Haar特征,这是我们的最底层。opencv中,最多规定有3个Haar特征。所以最多有3个Node结点。每一个Node结点计算出来的Haar特征,与当前的Node结点的阈值进行比较判决。无论是大于它还是小于它,都会得到一个z1。z1就是我们经过计算得到的Node结点。
如果当前我们的Z值与某一个阈值判决明显进行比较,这个时候就会计算出一个y值。y1、y2、y3表明的是弱分类器的计算特征。
强分类器再和强分类器的阈值判决明显进行比较。如果连续通过三个强分类器的阈值判决明显,那么我们就认为是目标。我们目标就是要判决出苹果。
- #haar 1 什么是haar? 特征 = 像素 运算 -》结果 (具体值 向量 矩阵 多维)
- # 2 如何利用特征 区分目标? 阈值判决
- # 3 得到判决? 机器学习
- # 1 特征 2 判决 3 得到判决
- # 公式推导 1 -2
- # 特征 = 整个区域*权重1 + 黑色*权重2 = (黑+白) * 1 +黑* (-2) =
- # = 黑+白-2黑 = 白-黑
- # 1 haar模板 上下 左右 image size 模板 size 100*100 10*10 100次 step = 10
- # 1 100*100 2 10*10 3 step 10 4 模板1
- # 模板 滑动 缩放 10*10 11*11 20级
- # 举例 10808720 step2 10*10
- # 计算量 = 14模板*20缩放* (1080/2*720/2) * (100点+- ) = 50-100亿
- # (50-100) *15 = 1000亿次
- # A 1 B 1 2 C 1 3 D 1 2 3 4
- # 4 = A-B-C+D = 1+1+2+3+4-1-2-1-3 = 4 (3+-)
- #haar + adaboost face
- # 苹果 苹果 苹果 香蕉
- # 0.1 0.1 0.1 0.5
- # 训练终止条件: 1 for count 2 p
- # 1 分类器的结构 2 adaboost 计算过程 3 xml 文件结构
- # haar> T1 and haar>T2 2个强分类器15-20
- # 1 分类器的结构
- # 3个强分类器 1 x1(特征) t1 2 x2(特征) t2 3 x3(特征) t3
- # x1>t1 and x2>t2 and x3>t3 目标-》苹果
- # 作用: 判决
- # 弱分类器结构
- # 作用: 计算强分类器特征x1 x2 x3
- # x2 = sum(y1,y2,y3)
- # y1 弱分类器特征
- # node
- # 3个haar-》node
- # 1node haar1 > nodeT1 z1 = a1
- # 1node haar1 < nodeT1 z1 = a2
- # Z = sum(z1,z2,z3)>T y1 = AA
- # Z = sum(z1,z2,z3)<T y1 = BB
- # haar->Node z1 z2 z3 Z = sum(z1,z2,z3)
- # Z>T y1 y2 y3
- # x = sum(y1,y2,y3) > T1 obj
6-7 adaboost分类器1的更多相关文章
- 使用OpenCV训练Haar like+Adaboost分类器的常见问题
<FAQ:OpenCV Haartraining>——使用OpenCV训练Haar like+Adaboost分类器的常见问题 最近使用OpenCV训练Haar like+Adaboost ...
- OpenCV学习记录(二):自己训练haar特征的adaboost分类器进行人脸识别 标签: 脸部识别opencv 2017-07-03 21:38 26人阅读
上一篇文章中介绍了如何使用OpenCV自带的haar分类器进行人脸识别(点我打开). 这次我试着自己去训练一个haar分类器,前后花了两天,最后总算是训练完了.不过效果并不是特别理想,由于我是在自己的 ...
- 6-8 adaboost分类器2
重点分析了Adaboost它的分类结构,以及如何使用Adaboost.这一节课讲解Adaboost分类器它训练的步骤以及训练好之后的XML文件的文件结构.所以这节课的核心是Adaboost分类器它的训 ...
- 关于adaboost分类器
我花了将近一周的时间,才算搞懂了adaboost的原理.这根骨头终究还是被我啃下来了. Adaboost是boosting系的解决方案,类似的是bagging系,bagging系是另外一个话题,还没有 ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 【原】训练自己haar-like特征分类器并识别物体(2)
在上一篇文章中,我介绍了<训练自己的haar-like特征分类器并识别物体>的前两个步骤: 1.准备训练样本图片,包括正例及反例样本 2.生成样本描述文件 3.训练样本 4.目标识别 == ...
- Real Adaboost总结
Real Adaboost分类器是对经典Adaboost分类器的扩展和提升,经典Adaboost分类器的每个弱分类器仅输出{1,0}或{+1,-1},分类能力较弱,Real Adaboost的每个弱分 ...
随机推荐
- Windows Server 远程桌面报错:No Remote Desktop License Servers Available
问题描述: 在用远程桌面访问Window Server服务器时,出现如下错误: The remote session was disconnected because there are no Rem ...
- HttpServletRequest接口是怎么实现的
request只是规范中的一个名称而已.不是SUN提供的,这是由各个不同的Servlet提供商编写的,SUN只是规定这个类要实现HttpServletRequest接口,并且规定了各个方法的用途,但具 ...
- flask可以通过缓存模板或者页面达到性能提升
flask可通过插件flask-cache缓存页面,或者把模板缓存到memcache里,增加访问速度. 前提是:页面不是频繁变化的.如果你的访问量很大的话,哪怕缓存一两分钟也会大大的提高性能的 Fla ...
- Linux驱动基础开发
Linux 内核配置机制(make menuconfig.Kconfig.makefile)讲解 前面我们介绍模块编程的时候介绍了驱动进入内核有两种方式:模块和直接编译进内核,并介绍了模块的一种编译方 ...
- 带您了解Oracle层次查询
http://database.51cto.com/art/201010/231539.htm Oracle层次查询(connect by )是结构化查询中用到的,下面就为您介绍Oracle层次查询的 ...
- 基于源码学习-fighting
今天逛着逛着,看到个培训网站,点进去和客服人员聊了一下.接着,看了看他们的培训课程,想了解一下 嵌入式开发的. (人就是要放空自己,把自己当做什么都不会,当着个婴儿[小学生]一般认真,要学什么知识就是 ...
- QVector的内存分配策略
我们都知道 STL std::vector 作为动态数组在所分配的内存被填满时.假设继续加入数据,std::vector 会另外申请一个大小当前容量两倍的区域(假设 n > size 则申请 n ...
- react jsx 数组变量的写法
1.通过 map 方法 var students = ["张三然","李慧思","赵思然","孙力气","王萌 ...
- linked-list-cycle-ii——链表,找出开始循环节点
Given a linked list, return the node where the cycle begins. If there is no cycle, returnnull. Follo ...
- android学习笔记三--Activity 布局
1.线性布局 标签 :<LinearLayout></LinearLayout> 方向:android:orientation, 垂直:vertical 水平:Horizont ...