深度学习--RNN,LSTM
一、RNN
1、定义
递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)。时间递归神经网络的神经元间连接构成矩阵,而结构递归神经网络利用相似的神经网络结构递归构造更为复杂的深度网络。RNN一般指代时间递归神经网络。
2、recurrent neural network原理

上面的图片是一个简单的RNN结构模块。Xt表示输入数据,A表示正在处理数据,ht表示输出数据。循环可以使这些信息从当前一部传递到下一步。具体展开之后为右边的结构。通过展开我们简单的认为我们写出了全部的序列。其中循环神经网络对应的公式如下:
- xt表示的是t时刻的输入,xt可以是一个one-hot向量。
- st是t时刻的隐层状态,它是记忆网络。st是基于前一时刻隐层和当前时刻输入的计算,st=f(Wst−1+Uxt)st=f(Wst−1+Uxt),其中f函数通常是非线性的,如ReLU或者tanh。其中第一个初始化状态s0记为0
- ot表示t时刻的输出,例如,如果我们想预测句子a的下一个词,它将会是一个词汇表中的概率向量,ot=softmax(Vst)ot=softmax(Vst)
其中有几点注意事项:
- 你可以将隐层状态st认为是网络的记忆。st可以捕获之前所有时刻发生的信息。输出 ot的计算仅仅依赖于时刻t的记忆。上面已经简略提到,实际中这个过程有些复杂,因为 ot通常不能获取之前过长时刻的信息
- 不像传统的深度神经网络,在不同的层使用不同的参数,循环神经网络在所有步骤中共享参数(U、V、W)。这个反映一个事实,我们在每一步上执行相同的任务,仅仅是输入不同。这个机制极大减少了我们需要学习的参数的数量;
- 上图在每一步都有输出,但是根据任务的不同,这个并不是必须的。例如,当预测一个句子的情感时,我们可能仅仅关注最后的输出,而不是每个词的情感。相似地,我们在每一步中可能也不需要输入。循环神经网络最大的特点就是隐层状态,它可以捕获一个序列的一些信息;
同一层前一个神经元的输出可以作为下一个神经圆的输入,这就是RNN与全连接网络的区别,下图为一个全连接网络,可以看到全连接网络的同一层之间是没有联系的。

3、几种常见的应用
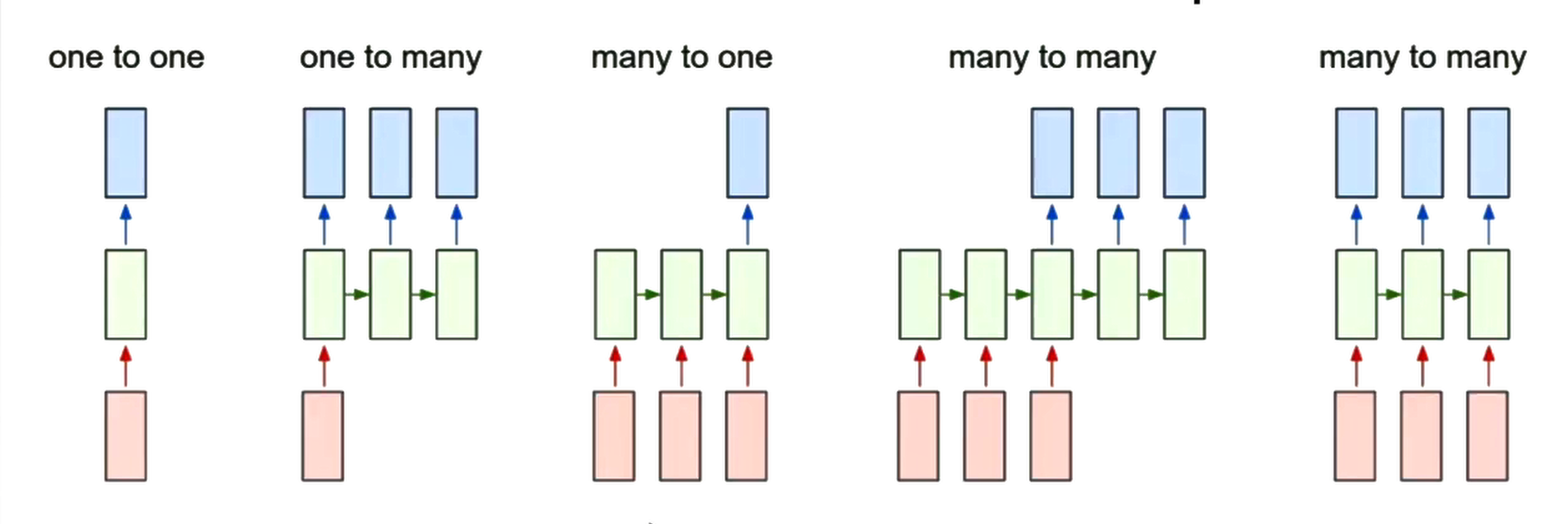
- one to many:输入一幅图片生成一个描述这个图片的句子
- many to one:输入一段句子判断情感,或者输入一段视频,判断视频的行为
- many to many:对于视频中的每一段都做出决策,或者机器翻译
4、长期依赖(Long-Term Dependencies)问题
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
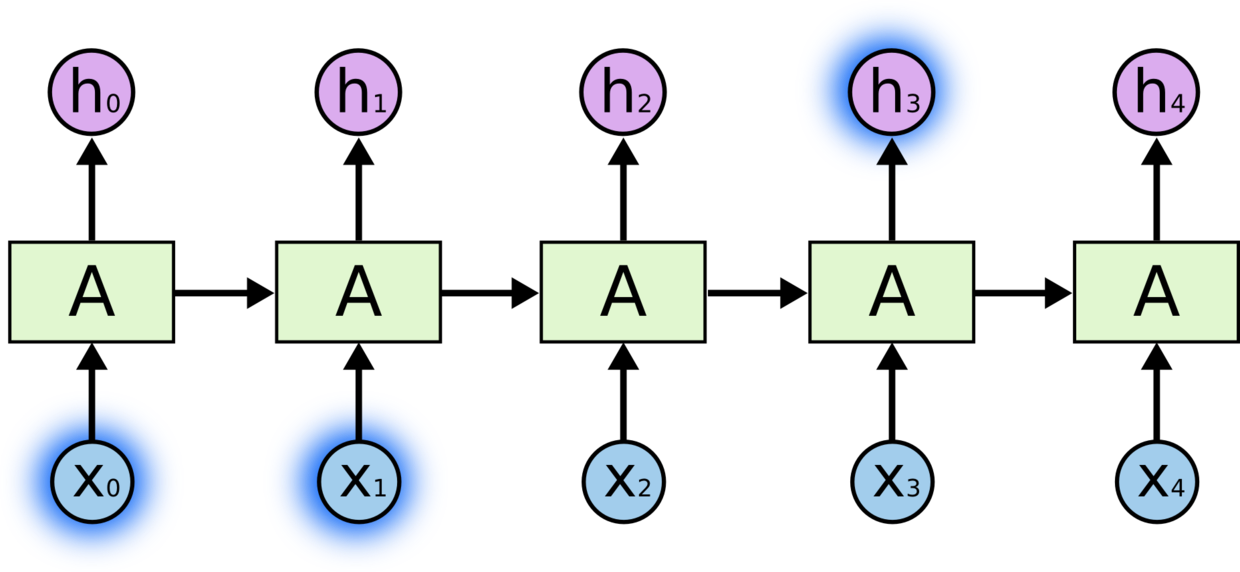
不太长的相关信息和位置间隔
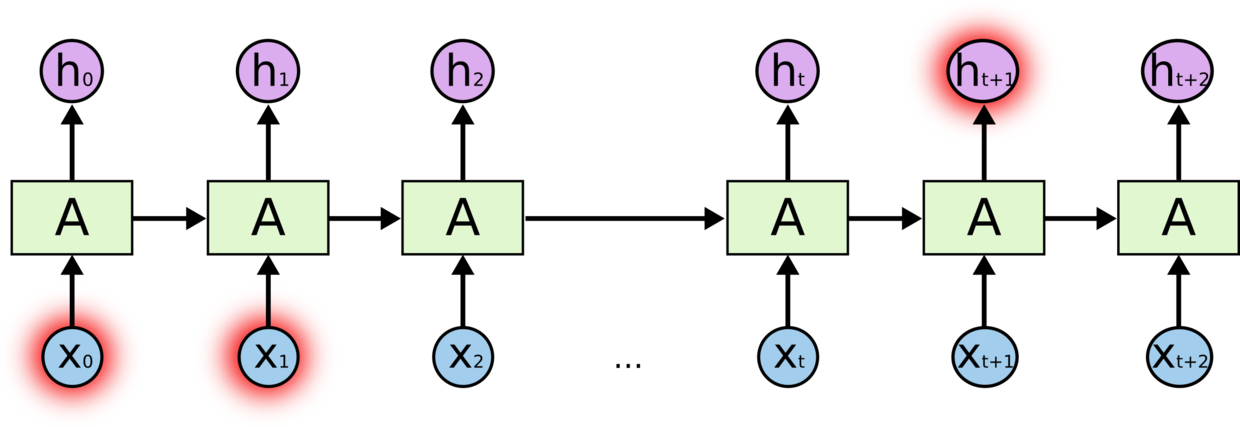
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France... I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,由于有梯度消失的问题,X0和X1对ht+1的影响会越来越小,RNN 会丧失学习到连接如此远的信息的能力。
二、LSTM
1、定义
long short term memory,即我们所称呼的LSTM,是为了解决长期以来问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。
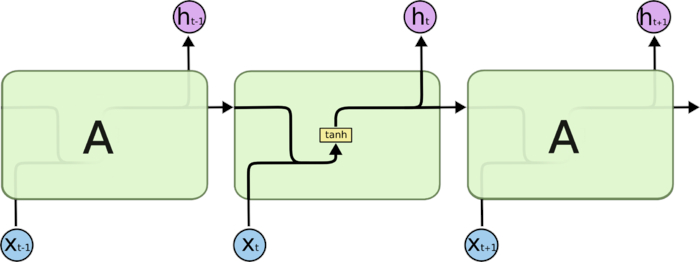
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互
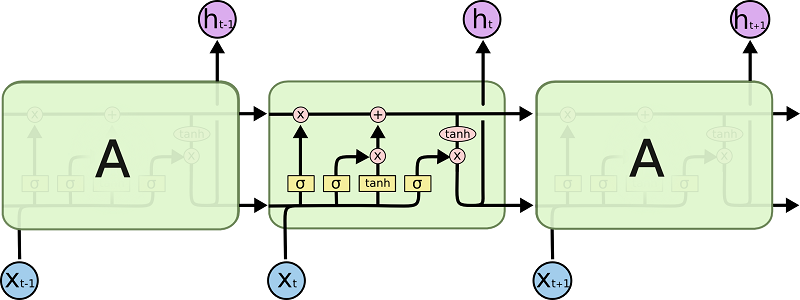
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
2、LSTM核心思想
LSTM的关键在于细胞的状态整个(绿色的图表示的是一个cell),和穿过细胞的那条水平线。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
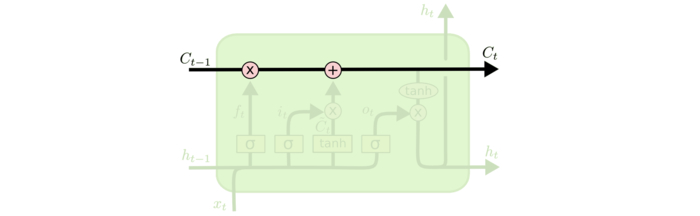
若只有上面的那条水平线是没办法实现添加或者删除信息的。而是通过一种叫做 门(gates) 的结构来实现的。
门 可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层 和一个逐点相乘的操作来实现的。

sigmoid 层输出(是一个向量)的每个元素都是一个在 0 和 1 之间的实数,表示让对应信息通过的权重(或者占比)。比如, 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”。
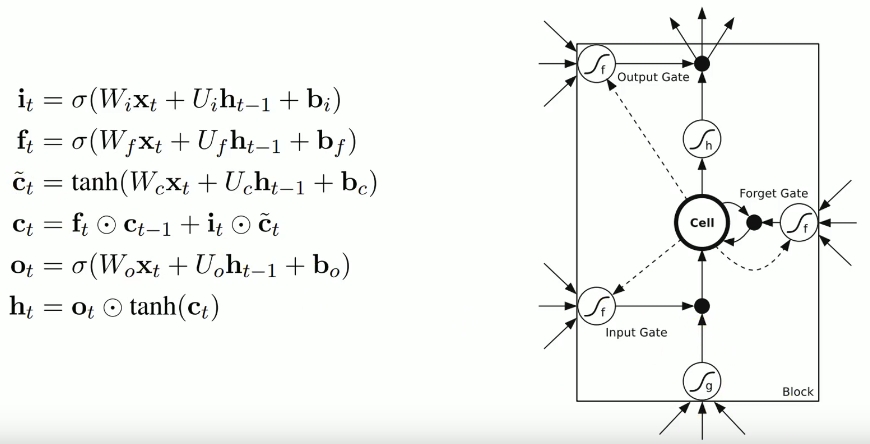
LSTM通过三个这样的本结构来实现信息的保护和控制。这三个门分别输入门、遗忘门和输出门。
现在我们就开始通过三个门逐步的了解LSTM的原理
遗忘门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取ht−1和xt,输出一个在 0到 1之间的数值给每个在细胞状态 Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
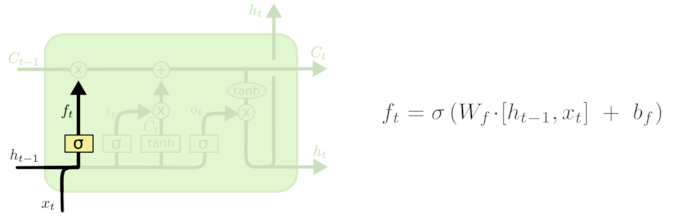
其中ht−1表示的是上一个cell的输出,xt表示的是当前细胞的输入。σ表示sigmod函数。
输入门
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个 步骤:首先,一个叫做“input gate layer ”的 sigmoid 层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是备选的用来更新的内容,Ĉ t。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。
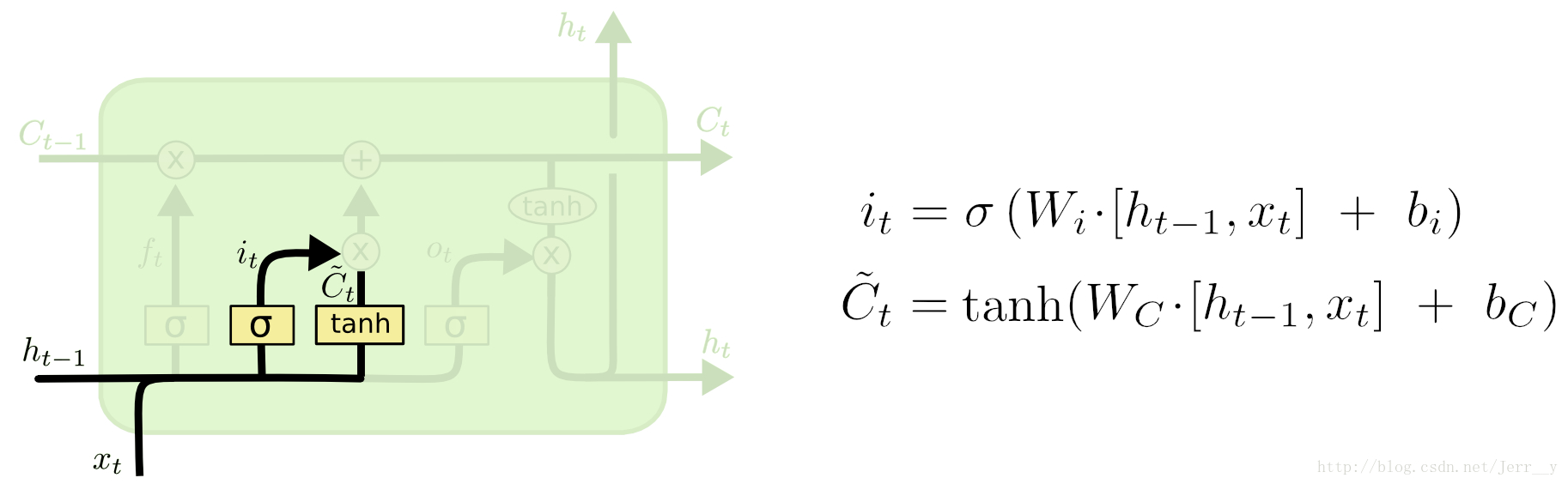
现在是更新旧细胞状态的时间了,Ct−1更新为Ct。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it∗C̃ t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。

输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
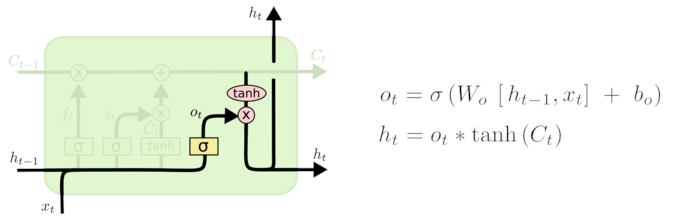
也有如下图的画法。
深度学习--RNN,LSTM的更多相关文章
- 深度学习|基于LSTM网络的黄金期货价格预测--转载
深度学习|基于LSTM网络的黄金期货价格预测 前些天看到一位大佬的深度学习的推文,内容很适用于实战,争得原作者转载同意后,转发给大家.之后会介绍LSTM的理论知识. 我把code先放在我github上 ...
- TensorFlow (RNN)深度学习 双向LSTM(BiLSTM)+CRF 实现 sequence labeling 序列标注问题 源码下载
http://blog.csdn.net/scotfield_msn/article/details/60339415 在TensorFlow (RNN)深度学习下 双向LSTM(BiLSTM)+CR ...
- 深度学习RNN实现股票预测实战(附数据、代码)
背景知识 最近再看一些量化交易相关的材料,偶然在网上看到了一个关于用RNN实现股票预测的文章,出于好奇心把文章中介绍的代码在本地跑了一遍,发现可以work.于是就花了两个晚上的时间学习了下代码,顺便把 ...
- 深度学习——RNN
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 原理 RNN.LSTM ...
- [深度学习]理解RNN, GRU, LSTM 网络
Recurrent Neural Networks(RNN) 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义 ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
- 深度学习:浅谈RNN、LSTM+Kreas实现与应用
主要针对RNN与LSTM的结构及其原理进行详细的介绍,了解什么是RNN,RNN的1对N.N对1的结构,什么是LSTM,以及LSTM中的三门(input.ouput.forget),后续将利用深度学习框 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 深度学习入门: CNN与LSTM(RNN)
1. 理解深度学习与CNN: 台湾李宏毅教授的入门视频<一天搞懂深度学习>:https://www.bilibili.com/video/av16543434/ 其中对CNN算法的矩阵卷积 ...
随机推荐
- grunt管理js/css
1.安装node 2.npm安装 3.运行grunt,可能遇到下面的问题 可以运行npm install -g grunt 然后再运行grunt 可以看到已经压缩成功了:
- Javascript设计模式理论与实战:观察者模式
观察者模式主要应用于对象之间一对多的依赖关系,当一个对象发生改变时,多个对该对象有依赖的其他对象也会跟着做出相应改变,这就非常适合用观察者模式来实现.使用观察者模式可以根据需要增加或删除对象,解决一对 ...
- 构建NetCore应用框架之实战篇(六):BitAdminCore框架架构小结
本篇承接上篇内容,如果你不小心点击进来,建议从第一篇开始完整阅读,文章内容继承性连贯性. 构建NetCore应用框架之实战篇系列 一.小结 1.前面已经完成框架的第一个功能,本篇做个小结. 2.直接上 ...
- (C#)调用Webservice,提示远程服务器返回错误(500)内部服务器错误
因为工作需要调用WebService接口,查了下资料,发现添加服务引用可以直接调用websevice 参考地址:https://www.cnblogs.com/peterpc/p/4628441.ht ...
- SQL Server2008 R2 数据库镜像实施手册(双机)
一.配置主备机 1. 服务器基本信息 主机名称为:HOST_A,IP地址为:192.168.1.155 备机名称为:HOST_B,IP地址为:192.168.1.156 二.主备实例互通 实现互通可以 ...
- 删除 iptables nat 规则
原文:https://www.cnblogs.com/hixiaowei/p/8954161.html 删除FORWARD 规则: iptables -nL FORWARD --line-number ...
- linux parallel rsync 拷贝N多文件
先来个对比图看一下, 左边图是普通 rsync 目录拷贝, 右边图是借助 parallel 工具并发起了多个 rsync centos6.5安装 parallel #!/bin/bash # Inst ...
- mysql enterprise backup入门使用
**************************************************************--1.全备******************************** ...
- 小型Http服务器
HTTP又叫做超文本传输协议,现如今用的最多的版本是1.1版本.HTTP有如下的特点: 支持客户/服务器模式(C/S或B/S) 简单快速:基于请求和响应,请求只需传送请求方法和请求路径 灵活:HTTP ...
- elasticsearch 分片(Shards)的理解
分片重要性 Es中所有数据均衡的存储在集群中各个节点的分片中,会影响ES的性能.安全和稳定性, 所以很有必要了解一下它. 分片是什么? 简单来讲就是咱们在ES中所有数据的文件块,也是数据的最小单元块, ...