Java内存模型Cookbook
前言
这是一篇用于说明在JSR-133中制定的新Java内存模型(JMM)的非官方指南。
这篇指南提供了在最简单的背景下各种规则存在的原因,而不是这些规则在指令重排、多核处理器屏障指令和原子操作等方面对编译器和JVM所造成的影响。
它还包括了一系列遵循JSR-133的指南。
本指南是“非官方”的文档,因为它还包括特定处理器性能和规范的解释,我们不能保证所有的解释都是正确的,此外,处理器的规范和实现也可能会随时改变。
(一)指令重排
1,指令重排
对于编译器的编写者来说,Java内存模型(JMM)主要是由禁止指令重排的规则所组成的,
其中包括了字段(包括数组中的元素)的存取指令和监视器(锁)的控制指令。
2,Volatile与监视器
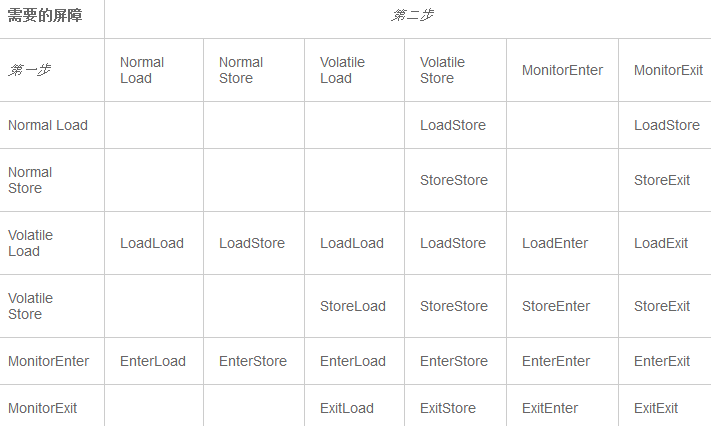
JMM中关于volatile和监视器主要的规则可以被看作一个矩阵。
这个矩阵的单元格表示在一些特定的后续关联指令的情况下,指令不能被重排。
下面的表格并不是JMM规范包含的,而是一个用来观察JMM模型对编译器和运行系统造成的主要影响的工具。

(ps:上表只是内存屏障造成的效果而非排序的定义)
关于上面这个表格一些术语的说明:
Normal Load指令包括:对非volatile字段的读取,getfield,getstatic和array load;
Normal Store指令包括:对非volatile字段的存储,putfield,putstatic和array store;
Volatile load指令包括:对多线程环境的volatile变量的读取,getfield,getstatic;
Volatile store指令包括:对多线程环境的volatile变量的存储,putfield,putstatic;
MonitorEnters指令(包括进入同步块synchronized方法)是用于多线程环境的锁对象;
MonitorExits指令(包括离开同步块synchronized方法)是用于多线程环境的锁对象。
在JMM中,Normal Load指令与Normal store指令的规则是一致的,类似的还有Volatile load指令与MonitorEnter指令,
以及Volatile store指令与MonitorExit指令,因此这几对指令的单元格在上面表格里都合并在了一起(但是在后面部分的表格中,会在有需要的时候展开)。
在这个小节中,我们仅仅考虑那些被当作原子单元的可读可写的变量,
也就是说那些没有位域(bit fields),非对齐访问(unaligned accesses)或者超过平台最大字长(word size)的访问。
任意数量的指令操作都可被表示成这个表格中的第一个操作或者第二个操作。
例如在单元格[Normal Store, Volatile Store]中,有一个No,就表示任何非volatile字段的store指令操作不能与后面任何一个Volatile store指令重排,
如果出现任何这样的重排会使多线程程序的运行发生变化。
(PS:可以理解成:第一,第二操作是前后关系而非相邻关系)
JSR-133规范规定上述关于volatile和监视器的规则仅仅适用于可能会被多线程访问的变量或对象。
因此,如果一个编译器可以最终证明(往往是需要很大的努力)一个锁只被单线程访问,那么这个锁就可以被去除。
与之类似的,一个volatile变量只被单线程访问也可以被当作是普通的变量。
还有进一步更细粒度的分析与优化,例如:那些被证明在一段时间内对多线程不可访问的字段。
(ps: 单线程保证了数据依赖的有序性,所以不需要锁和volatile屏障)
在上表中,空白的单元格代表在不违反Java的基本语义下的重排是允许的(详细可参考JLS中的说明)。
例如,即使上表中没有说明,但是也不能对同一个内存地址上的load指令和之后紧跟着的store指令进行重排。(ps:即数据依赖)
但是你可以对两个不同的内存地址上的load和store指令进行重排,而且往往在很多编译器转换和优化中会这么做。 这其中就包括了一些往往不认为是指令重排的例子,例如:(ps:不是很明白下面这个例子)
重用一个基于已经加载的字段的计算后的值而不是像一次指令重排那样去重新加载并且重新计算。
然而,JMM规范允许编译器经过一些转换后消除这些可以避免的依赖,使其可以支持指令重排。
在任何的情况下,即使是程序员错误的使用了同步读取,指令重排的结果也必须达到最基本的Java安全要求。
所有的显式字段都必须不是被设定成0或null这样的预构造值,就是被其他线程设值。
这通常必须把所有存储在堆内存里的对象在其被构造函数使用前进行归零操作,并且从来不对归零store指令进行重排。(ps: 初始值,不重排序)
一种比较好的方式是在垃圾回收中对回收的内存进行归零操作。
可以参考JSR-133规范中其他情况下的一些关于安全保证的规则。
这里描述的规则和属性都是适用于读取Java环境中的字段。
在实际的应用中,这些都可能会另外与读取内部的一些记账字段和数据交互,例如对象头,GC表和动态生成的代码。
3,Final 字段
Final字段的load和store指令相对于有锁的或者volatile字段来说,就跟Normal load和Normal store的存取是一样的,但是需要加入两条附加的指令重排规则:
3,1,如果在构造函数中有一条final字段的store指令,同时这个字段是一个引用,
那么它将不能与构造函数外后续可以让持有这个final字段的对象被其他线程访问的指令重排。
(ps:所谓构造函数外,即构造函数内部的对象传递给一个引用而这个引用是可以被其他线程获取操作的)
例如:你不能重排下列语句:
x.finalField = v;
... ;
sharedRef = x;
这条规则会在下列情况下生效,例如当你内联一个构造函数时,正如“…”的部分表示这个构造函数的逻辑边界那样。
你不能把这个构造函数中的对于这个final字段的store指令移动到构造函数外的一条store指令后面,因为这可能会使这个对象对其他线程可见。
(正如你将在下面看到的,这样的操作可能还需要声明一个内存屏障)。
类似的,你不能把下面的前两条指令(1,2)与第三条指令(3)进行重排:
1,x.afield = ;
2,x.finalField = v;
... ;
3,sharedRef = x;
(ps: 说明final字段的写也具有volatile写的特性,那么1和2是不能交互位置的;是不是没final字段的变量,1,2和3会重排序)
PS:
final的使用让,final字段先被赋值,然后才将字段所属对象传递给共享变量
3,2,一个final字段的load指令不能与包含该字段的对象的初始化load指令进行重排。
在下面这种情况下,这条规则就会生效:
x = shareRef;
… ;
i = x.finalField;
由于这两条指令是依赖的,编译器将不会对这样的指令进行重排。但是,这条规则会对某些处理器有影响。(ps:这对处理器什么影响,没有说明?)
(ps:为什么不说3.1是依赖呢,3.1和3.2的区别是:1是,首先x的final字段被赋值,再把x传递出去;2是,首先x被赋值,再获取x中的final字段值)
上述规则,要求对于带有final字段的对象的load本身是synchronized,volatile,final或者来自类似的load指令,
从而确保java程序员对与final字段的正确使用,并最终使构造函数中初始化的store指令和构造函数外的store指令排序。
(二)内存屏障
编译器和处理器必须同时遵守重排规则。
由于单核处理器能确保与“顺序执行”相同的一致性,所以在单核处理器上并不需要专门做什么处理,就可以保证正确的执行顺序。
但在多核处理器上通常需要使用内存屏障指令来确保这种一致性。
即使编译器优化掉了一个字段访问(例如,因为一个读入的值未被使用),这种情况下还是需要产生内存屏障,就好像这个访问仍然需要保护。
(可以参考下面的优化掉内存屏障的章节)。
内存屏障仅仅与内存模型中“获取”、“释放”这些高层次概念有间接的关系。
内存屏障并不是“同步屏障”,内存屏障也与在一些垃圾回收机制中“写屏障(write barriers)”的概念无关。
内存屏障指令仅仅直接控制CPU与其缓存之间,CPU与其准备将数据写入主存或者写入等待读取、预测指令执行的缓冲中的写缓冲之间的相互操作。
这些操作可能导致缓冲、主内存和其他处理器做进一步的交互。
但在JAVA内存模型规范中,没有强制处理器之间的交互方式,只要数据最终变为全局可用,就是说在所有处理器中可见,并当这些数据可见时可以获取它们。
1,内存屏障的种类
几乎所有的处理器至少支持一种粗粒度的屏障指令,通常被称为“栅栏(Fence)”,
它保证在栅栏前初始化的load和store指令,能够严格有序的在栅栏后的load和store指令之前执行。
无论在何种处理器上,这几乎都是最耗时的操作之一(与原子指令差不多,甚至更消耗资源),所以大部分处理器支持更细粒度的屏障指令。
内存屏障的一个特性是将它们运用于内存之间的访问。
尽管在一些处理器上有一些名为屏障的指令,但是正确的/最好的屏障使用取决于内存访问的类型。
下面是一些屏障指令的通常分类,正好它们可以对应上常用处理器上的特定指令(有时这些指令不会导致操作)。
1,1,LoadLoad 屏障
序列:Load1,Loadload,Load2
确保Load1所要读入的数据能够在被Load2和后续的load指令访问前读入。
通常能执行预加载指令或/和支持乱序处理的处理器中需要显式声明Loadload屏障,因为在这些处理器中正在等待的加载指令能够绕过正在等待存储的指令。
而对于总是能保证处理顺序的处理器上,设置该屏障相当于无操作。
1,2,StoreStore 屏障
序列:Store1,StoreStore,Store2
确保Store1的数据在Store2以及后续Store指令操作相关数据之前对其它处理器可见(例如向主存刷新数据)。
通常情况下,如果处理器不能保证从写缓冲或/和缓存向其它处理器和主存中按顺序刷新数据,那么它需要使用StoreStore屏障。
1,3,LoadStore 屏障
序列: Load1; LoadStore; Store2
确保Load1的数据在Store2和后续Store指令被刷新之前读取。
在等待Store指令可以越过loads指令的乱序处理器上需要使用LoadStore屏障。
1,4,StoreLoad Barriers
序列: Store1; StoreLoad; Load2
确保Store1的数据在被Load2和后续的Load指令读取之前对其他处理器可见。
StoreLoad屏障可以防止一个后续的load指令 不正确的使用了Store1的数据,而不是另一个处理器在相同内存位置写入一个新数据。 正因为如此,所以在下面所讨论的处理器为了在屏障前读取同样内存位置存过的数据,必须使用一个StoreLoad屏障将存储指令和后续的加载指令分开。
Storeload屏障在几乎所有的现代多处理器中都需要使用,但通常它的开销也是最昂贵的。
它们昂贵的部分原因是它们必须关闭通常的略过缓存直接从写缓冲区读取数据的机制。
这可能通过让一个缓冲区进行充分刷新(flush),以及其他延迟的方式来实现。
在下面讨论的所有处理器中,执行StoreLoad的指令也会同时获得其他三种屏障的效果。
所以StoreLoad可以作为最通用的(但通常也是最耗性能)的一种Fence。(这是经验得出的结论,并不是必然)。
反之不成立,为了达到StoreLoad的效果而组合使用其他屏障并不常见。
下表显示这些屏障如何符合JSR-133排序规则。

另外,特殊的final字段规则在下列代码中需要一个StoreStore屏障
x.finalField = v;
StoreStore;
sharedRef = x;
如下例子解释如何放置屏障:
class X {
int a, b;
volatile int v, u;
void f() {
int i, j;
i = a;// load a
j = b;// load b
i = v;// load v
// LoadLoad
j = u;// load u
// LoadStore
a = i;// store a
b = j;// store b
// StoreStore
v = i;// store v
// StoreStore
u = j;// store u
// StoreLoad
i = u;// load u
// LoadLoad
// LoadStore
j = b;// load b
a = i;// store a
}
}
(ps:对于普通读写,是load还是store对于volatile变量排序规则是一样的。)
2,数据依赖和屏障
一些处理器为了保证依赖指令的交互次序需要使用LoadLoad和LoadStore屏障。
在一些(大部分)处理器中,一个load指令或者一个依赖于之前加载值的store指令被处理器排序,并不需要一个显式的屏障。
2,1,这通常发生于两种情况,
间接取值(indirection):
Load x;
Load x.field
条件控制(control)
Load x;
if (predicate(x))
Load or Store y;
但特别的是不遵循间接排序的处理器,需要为final字段设置屏障,使它能通过共享引用访问最初的引用。
x = sharedRef;
… ;
LoadLoad; (这里为什么不是写读屏障,或许上面存在该屏障了(省略号的部分))
i = x.finalField;
相反的,如下讨论,确定遵循数据依赖的处理器,提供了几个优化掉LoadLoad和LoadStore屏障指令的机会。
(尽管如此,在任何处理器上,对于StoreLoad屏障不会自动清除依赖关系)。
3,与原子指令交互
屏障在不同处理器上还需要与MonitorEnter和MonitorExit实现交互。
锁或者解锁通常必须使用原子条件更新操作CompareAndSwap(CAS)指令或者LoadLinked/StoreConditional (LL/SC),
就如执行一个volatile store之后紧跟volatile load的语义一样。
CAS或者LL/SC能够满足最小功能,一些处理器还提供其他的原子操作(如,一个无条件交换),这在某些时候它可以替代或者与原子条件更新操作结合使用。
在所有处理器中,原子操作可以避免在正被读取/更新的内存位置进行写后读(read-after-write)。
(否则标准的循环直到成功的结构体(loop-until-success )没有办法正常工作)。
但处理器在是否为原子操作提供比隐式的StoreLoad更一般的屏障特性上表现不同。
一些处理器上这些指令可以为MonitorEnter/Exit原生的生成屏障;其它的处理器中一部分或者全部屏障必须显式的指定。
为了分清这些影响,我们必须把Volatiles和Monitors分开:
另外,特殊的final字段规则需要一个StoreLoad屏障。
x.finalField = v;
StoreStore;
sharedRef = x;
在这张表里,”Enter”与”Load”相同,”Exit”与”Store”相同,除非被原子指令的使用和特性覆盖。特别是:
1,EnterLoad 在进入任何需要执行Load指令的同步块/方法时都需要。
这与LoadLoad相同,除非在MonitorEnter时候使用了原子指令并且它本身提供一个至少有LoadLoad属性的屏障,如果是这种情况,相当于没有操作。
2,StoreExit在退出任何执行store指令的同步方法块时候都需要。
这与StoreStore一致,除非MonitorExit使用原子操作,并且提供了一个至少有StoreStore属性的屏障,如果是这种情况,相当于没有操作。
3,ExitEnter和StoreLoad一样,除非MonitorExit使用了原子指令,并且/或者MonitorEnter至少提供一种屏障,该屏障具有StoreLoad的属性,如果是这种情况,相当于没有操作。
在编译时不起作用或者导致处理器上不产生操作的指令比较特殊。
例如,当没有交替的load和store指令时,EnterEnter用于分离嵌套的MonitorEnter。下面这个例子说明如何使用这些指令类型:
class X {
int a;
volatile int v;
void f() {
int i;
synchronized (this) { // enter EnterLoad EnterStore
i = a;// load a
a = i;// store a
}// LoadExit StoreExit exit ExitEnter
synchronized (this) {// enter ExitEnter
synchronized (this) {// enter
}// EnterExit exit
}// ExitExit exit ExitEnter ExitLoad
i = v;// load v
synchronized (this) {// LoadEnter enter
} // exit ExitEnter ExitStore
v = i; // store v
synchronized (this) { // StoreEnter enter
} // EnterExit exit
}
}
Java层次的对原子条件更新的操作将在JDK1.5中发布(JSR-166),
因此编译器需要发布相应的代码,综合使用上表中使用MonitorEnter和MonitorExit的方式,
——从语义上说,有时在实践中,这些Java中的原子更新操作,就如同他们都被锁所包围一样。
(三)多处理器
本文总结了在多处理器(MPs)中常用的的处理器列表,处理器相关的信息都可以从链接指向的文档中得到(一些网站需要通过注册才能得到相应的手册)。
当然,这不是一个完全详细的列表,但已经包括了我所知道的在当前或者将来Java实现中所使用的多核处理器。
下面所述的关于处理器的列表和内容也不一定权威。
我只是总结一下我所阅读过的文档,但是这些文档也有可能是被我误解了,一些参考手册也没有把Java内存模型(JMM)相关的内容阐述清楚,所以请协助我把本文变得更准确。
一些很好地讲述了跟内存屏障(barriers)相关的硬件信息和机器(machines)相关的特性的资料并没有在本文中列出来,
如《Hans Boehm的原子操作库(Hans Boehm’s atomic_ops library)》, 《Linux内核源码(Linux Kernel Source)》, 和 《Linux可扩展性研究计划(Linux Scalability Effort)》。
Linux内核中所需的内存屏障与这里讨论的是非常一致的,它已被移植到大多数处理器中。
不同处理器所支持的潜在内存模型的相关描述,可以查阅Sarita Adve et al, Recent Advances in Memory Consistency Models for Hardware Shared-Memory Systems
和 Sarita Adve and Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial.
sparc-TSO
Ultrasparc 1, 2, 3 (sparcv9)都支持全存储顺序模式(TSO:Total Store Orde),Ultra3s只支持全存储顺序模式(TSO:Total Store Orde)。
(Ultra1/2的RMO(Relax Memory Order)模式由于不再使用可以被忽略了)相关内容可进一步查看 UltraSPARC III Cu User’s Manual
和 The SPARC Architecture Manual, Version 9。
x86 (和 x64)
英特尔486+,AMD以及其他的处理器。
在2005到2009年有很多规范出现,但当前的规范都几乎跟TSO一致,主要的区别在于支持不同的缓存模式,和极端情况下的处理(如不对齐的访问和特殊形式的指令)。
可进一步查看The IA-32 Intel Architecture Software Developers Manuals: System Programming Guide 和 AMD Architecture Programmer’s Manual Programming。
ia64
安腾处理器。可进一步查看 Intel Itanium Architecture Software Developer’s Manual, Volume 2: System Architecture。
ppc (POWER)
尽管所有的版本都有相同的基本内存模型,但是一些内存屏障指令的名字和定义会随着时间变化而变化。
下表中所列的是从Power4开始的版本;可以查阅架构手册获得更多细节。
查看 MPC603e RISC Microprocessor Users Manual, MPC7410/MPC7400 RISC Microprocessor Users Manual,
Book II of PowerPC Architecture Book, PowerPC Microprocessor Family: Software reference manual, Book E- Enhanced PowerPC Architecture,
EREF: A Reference for Motorola Book E and the e500 Core。
关于内存屏障的讨论请查看IBM article on power4 barriers, 和 IBM article on powerpc barriers.
arm
arm版本7以上。请查看 ARM processor specifications alpha 21264x和其他所以版本。请查看Alpha Architecture Handbook
pa-risc
HP pa-risc实现。请查看pa-risc 2.0 Architecture手册。
下面是这些处理器所支持的屏障和原子操作:

说明:
- 尽管上面一些单元格中所列的屏障指令比实际需要的特性更强,但可能是最廉价的方式获得所需要的效果。
- 上面所列的屏障指令主要是为正常的程序内存的使用而设计的,IO和系统任务就没有必要用特别形式/模式的缓存和内存。举例来说,在x86 SPO中,StoreStore屏障指令(“sfence”)需要写合并(WC)缓存模式,其目的是用在系统级的块传输等地方。操作系统为程序和数据使用写回(Writeback)模式,这就不需要StoreStore屏障了。
- 在x86中,任何lock前缀的指令都可以用作一个StoreLoad屏障。(在Linux内核中使用的形式是无操作的lock指令,如addl $0,0(%%esp)。)。除非必须需要使用像CAS这样lock前缀的指令,否则使用支持SSE2扩展版本(如奔腾4及其后续版本)的mfence指令似乎是一个更好的方案。cpuid指令也是可以用的,但是比较慢。
- 在ia64平台上,LoadStore,LoadLoad和StoreStore屏障被合并成特殊形式的load和store指令–它们不再是一些单独的指令。ld.acq就是(load;LoadLoad+LoadStore)和st.rel就是(LoadStore+StoreStore;store)。这两个都不提供StoreLoad屏障–因此你需要一个单独的mf屏障指令。
- 在ARM和ppc平台中,就有可能通过non-fence-based指令序列取代load fences。这些序列和以及他们应用的案例在Cambridge Relaxed Memory Concurrency Group著作中都有描述。
- sparc membar指令不但支持所有的4种屏障模式,而且还支持组合模式。但是StoreLoad模式需要在TSO中。在一些UltraSparcs中,不管任何模式下membar指令总是能让StoreLoad生效。
- 在与这些流指令有关的情况中,X86处理器支持”streaming SIMD” SSE2扩展只需要LoadLoad ‘lfence’
- 虽然PA-RISC规范并不强制规定,但所有HP PA-RISC的实现都是顺序一致,因此没有内存屏障指令。
- 唯一的在pa-risc上的原始原子操作(atomic primitive)是ldcw, 一种test-and-set的形式,通过它你可以使用一些技术建立原子条件更新(atomic conditional updates),这些技术在 HP white paper on spinlocks中可以找到.
- 在不同的字段宽度(field width,包括4个字节和8个字节版本)里,CAS和LL/SC在不同的处理器上会使用多种形式。
- 在sparc和x86处理器中,CAS有隐式的前后全StoreLoad屏障。sparcv9架构手册描述了CAS不需要post-StoreLoad屏障特性,但是芯片手册表明它确实在ultrasparcs中存在这个特性。
- 只有在内存区域进行加载和存储(loaded/stored)时,ppc和alpha, LL/SC才会有隐式的屏障,但它不再有更通用的屏障特性。
- 在内存区域中进行加载或存储时, ia64 cmpxchg指令也会有隐式的屏障,但还会额外加上可选的.acq(post-LoadLoad+LoadStore)或者.rel(pre-StoreStore+LoadStore)修改指令。cmpxchg.acq形式可用于MonitorEnter,cmpxchg.rel可用于MonitorExit。在上述的情况中,exits和enters在没有被确定匹配的情况下,就需要ExitEnter(StoreLoad)屏障。
- Sparc,x86和ia64平台支持unconditional-exchange (swap, xchg). Sparc ldstub是一个one-byte test-and-set。 ia64 fetchadd返回前一个值并把它加上去。在x86平台,一些指令(如add-to-memory)能够使用lock前缀的指令执行原子操作。
(四)指南(Recipes)
单处理器(Uniprocessors)
如果能保证正在生成的代码只会运行在单个处理器上,那就可以跳过本节的其余部分。
因为单处理器保持着明显的顺序一致性,除非对象内存以某种方式与可异步访问的IO内存共享,否则永远都不需要插入屏障指令。
采用了特殊映射的java.nio buffers可能会出现这种情况,但也许只会影响内部的JVM支持代码,而不会影响Java代码。
而且,可以想象,如果上下文切换时不要求充分的同步,那就需要使用一些特殊的屏障了。
(ps:单核可能共享变量的缓存也是共享的,那么就不会存在一致性问题了;解密内存屏障)
插入屏障(Inserting Barriers)
当程序执行时碰到了不同类型的存取,就需要屏障指令。
几乎无法找到一个“最理想”位置,能将屏障执行总次数降到最小。
编译器不知道指定的load或store指令是先于还是后于需要一个屏障操作的另一个load或store指令;如,当volatile store后面是一个return时。
最简单保守的策略是为任一给定的load,store,lock或unlock生成代码时,都假设该类型的存取需要“最重量级”的屏障:
- 在每条volatile store指令之前插入一个StoreStore屏障。(在ia64平台上,必须将该屏障及大多数屏障合并成相应的load或store指令。)
- 如果一个类包含final字段,在该类每个构造器的全部store指令之后,return指令之前插入一个StoreStore屏障。
- 在每条volatile store指令之后插入一条StoreLoad屏障。注意,虽然也可以在每条volatile load指令之前插入一个StoreLoad屏障,但对于使用volatile的典型程序来说则会更慢,因为读操作会大大超过写操作。或者,如果可以的话,将volatile store实现成一条原子指令(例如x86平台上的XCHG),就可以省略这个屏障操作。如果原子指令比StoreLoad屏障成本低,这种方式就更高效。
- 在每条volatile load指令之后插入LoadLoad和LoadStore屏障。在持有数据依赖顺序的处理器上,如果下一条存取指令依赖于volatile load出来的值,就不需要插入屏障。特别是,在load一个volatile引用之后,如果后续指令是null检查或load此引用所指对象中的某个字段,此时就无需屏障。
- 在每条MonitorEnter指令之前或在每条MonitorExit指令之后插入一个ExitEnter屏障。(根据上面的讨论,如果MonitorExit或MonitorEnter使用了相当于StoreLoad屏障的原子指令,ExitEnter可以是个空操作(no-op)。其余步骤中,其它涉及Enter和Exit的屏障也是如此。)
- 在每条MonitorEnter指令之后插入EnterLoad和EnterStore屏障。
- 在每条MonitorExit指令之前插入StoreExit和LoadExit屏障。
- 如果在未内置支持间接load顺序的处理器上,可在final字段的每条load指令之前插入一个LoadLoad屏障。(此邮件列表和linux数据依赖屏障的描述中讨论了一些替代策略。)
这些屏障中的有一些通常会简化成空操作。
实际上,大部分都会简化成空操作,只不过在不同的处理器和锁模式下使用了不同的方式。
最简单的例子,在x86或sparc-TSO平台上使用CAS实现锁,仅相当于在volatile store后面放了一个StoreLoad屏障。
移除屏障(Removing Barriers)
上面的保守策略对有些程序来说也许还能接受。
volatile的主要性能问题出在与store指令相关的StoreLoad屏障上。
这些应当是相对罕见的 —— 将volatile主要用于避免并发程序里读操作中锁的使用,仅当读操作大大超过写操作才会有问题。
但是至少能在以下几个方面改进这种策略:
- 移除冗余的屏障。可以根据前面章节的表格内容来消除屏障:
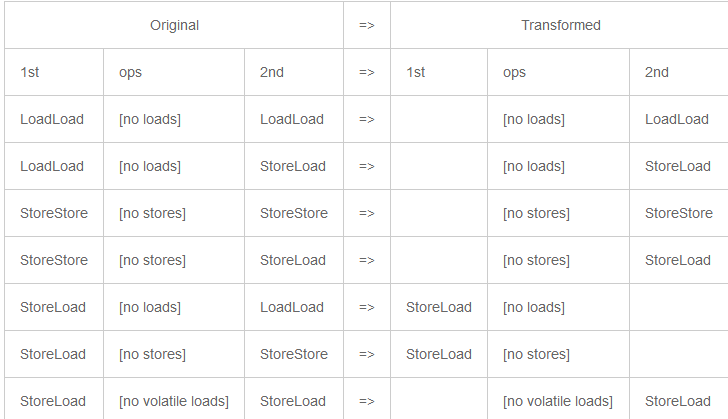
类似的屏障消除也可用于锁的交互,但要依赖于锁的实现方式。 使用循环,调用以及分支来实现这一切就留给读者作为练习。:-)
- 重排代码(在允许的范围内)以更进一步移除LoadLoad和LoadStore屏障,这些屏障因处理器维持着数据依赖顺序而不再需要。
- 移动指令流中屏障的位置以提高调度(scheduling)效率,只要在该屏障被需要的时间内最终仍会在某处执行即可。
- 移除那些没有多线程依赖而不需要的屏障;例如,某个volatile变量被证实只会对单个线程可见。而且,如果能证明线程仅能对某些特定字段执行store指令或仅能执行load指令,则可以移除这里面使用的屏障。但是所有这些通常都需要作大量的分析。
杂记(Miscellany)
JSR-133也讨论了在更为特殊的情况下可能需要屏障的其它几个问题:
- Thread.start()需要屏障来确保该已启动的线程能看到在调用的时刻对调用者可见的所有store的内容。相反,Thread.join()需要屏障来确保调用者能看到正在终止的线程所store的内容。实现Thread.start()和Thread.join()时需要同步,这些屏障通常是通过这些同步来产生的。
- static final初始化需要StoreStore屏障,遵守Java类加载和初始化规则的那些机制需要这些屏障。
- 确保默认的0/null初始字段值时通常需要屏障、同步和/或垃圾收集器里的底层缓存控制。
- 在构造器之外或静态初始化器之外神秘设置System.in, System.out和System.err的JVM私有例程需要特别注意,因为它们是JMM final字段规则的遗留的例外情况。
- 类似地,JVM内部反序列化设置final字段的代码通常需要一个StoreStore屏障。
- 终结方法可能需要屏障(垃圾收集器里)来确保Object.finalize中的代码能看到某个对象不再被引用之前store到该对象所有字段的值。这通常是通过同步来确保的,这些同步用于在reference队列中添加和删除reference。
- 调用JNI例程以及从JNI例程中返回可能需要屏障,尽管这看起来是实现方面的一些问题。
- 大多数处理器都设计有其它专用于IO和OS操作的同步指令。它们不会直接影响JMM的这些问题,但有可能与IO,类加载以及动态代码的生成紧密相关。
Java内存模型Cookbook的更多相关文章
- Java内存模型分析
在学习Java内存模型之前,先了解一下线程通信机制. 1.线程通信机制 在并发编程中,线程之间相互交换信息就是线程通信.目前有两种机制:内存共享与消息传递. 1.1.共享内存 Java采用的就是共享内 ...
- JMM(java内存模型)
What is a memory model, anyway? In multiprocessorsystems, processors generally have one or more laye ...
- 深入理解Java内存模型——volatile
volatile的特性 当我们声明共享变量为volatile后,对这个变量的读/写将会非常特别. 理解volatile特性的一个好方法是:把对volatile变量的单个读/写,看成是使用同一个监视器锁 ...
- 【java】java内存模型 (1)--基础
并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来交换信息.在命令式编程中,线程之间的通信 ...
- 《深入理解Java内存模型》读书总结(转-总结很好)
概要 文章是<深入理解Java内容模型>读书笔记,该书总共包括了3部分的知识. 第1部分,基本概念 包括“并发.同步.主内存.本地内存.重排序.内存屏障.happens before规则. ...
- 深入理解JMM(Java内存模型) --(一)
并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来交换信息.在命令式编程中,线程之间的通信 ...
- 深入理解JMM(Java内存模型) --(六)final
与前面介绍的锁和volatile相比较,对final域的读和写更像是普通的变量访问.对于final域,编译器和处理器要遵守两个重排序规则: 在构造函数内对一个final域的写入,与随后把这个被构造对象 ...
- 深入理解JMM(Java内存模型) --(四)volatile
volatile的特性 当我们声明共享变量为volatile后,对这个变量的读/写将会很特别.理解volatile特性的一个好方法是:把对volatile变量的单个读/写,看成是使用同一个监视器锁对这 ...
- 深入理解JMM(Java内存模型) --(三)顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.Java内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代码 ...
随机推荐
- IE8以下支持css3 border-radius渲染方法
这两天在做个集团网站,web前端妹子技术水平不咋样,写个web和wap 真够费劲的,对之前流行的H5和css3 响应式看来不太会用,扔给我一个半成品~~·非说各种canvas和border-radiu ...
- shiro 实现 用户 a 操作b 的权限 ,用户 b 能够及时获知。b不需要退出登陆 。 关闭鉴权缓存,或者不配置缓存
<bean id="myRealm" class="com.diancai.util.MyRealm"> <property name=&qu ...
- css3新增功能
CSS3新增功能 1 CSS3选择器详解 1.1 基础选择器 通配选择器* 元素选择器E ID选择器#id CLASS选择器.class 群组选择器select1,selectN 1.2 层次选择器 ...
- kbmMWEncodeEscapes 中汉字编码的问题及解决办法
kbmMWEncodeEscapes 是kbmmw 里面的一个函数,用来对URL 中的汉字进行编码,例如 http://127.0.0.1/getname?name=春节,由于'春节'是汉字,浏览器向 ...
- Docker 技巧:删除 Docker 容器和镜像
默认安装完 docker 后,每次执行 docker 都需要运行 sudo 命令,非常浪费时间影响效率.如果不跟 sudo,直接执行 docker images 命令会有如下问题: Get http: ...
- C语言程序设计50例(一)(经典收藏)
[程序1]题目:有1.2.3.4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?1.程序分析:可填在百位.十位.个位的数字都是1.2.3.4.组成所有的排列后再去 掉不满足条件的排列. # ...
- AirplaceLogger源代码解析
将源代码添加进Eclipse中,右键-->Import-->Existing Projects into Workspace-->选择AirplaceLogger源代码文件夹即可导入 ...
- Content-Type,内容类型
Content-Type,内容类型,一般是指网页中存在的Content-Type,ContentType属性指定请求和响应的HTTP内容类型.如果未指定 ContentType,默认为text/htm ...
- (最小生成树) Borg Maze -- POJ -- 3026
链接: http://poj.org/problem?id=3026 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=82831#probl ...
- (匹配 最小路径覆盖)Air Raid --hdu --1151
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1151 http://acm.hust.edu.cn/vjudge/contest/view.action ...