关于Python Profilers性能分析器
1. 介绍性能分析器
作者:btchenguang
profiler是一个程序,用来描述运行时的程序性能,并且从不同方面提供统计数据加以表述。Python中含有3个模块提供这样的功能,分别是cProfile, profile和pstats。这些分析器提供的是对Python程序的确定性分析。同时也提供一系列的报表生成工具,允许用户快速地检查分析结果。
Python标准库提供了3个不同的性能分析器:
- cProfile,推荐给大部分的用户,是C的一个扩展应用,因为其合理的运行开销,所以适合分析运行时间较长的。是基于lsprof。
- profile,一个纯python模块,它的接口和cProfile一致。在分析程序时,增加了很大的运行开销。如果你想扩展profiler的功能,可以试着继承这个模块
- hotshot, 一个试验性的c模块,关注减少分析时的运行开销,但是是以需要更长的数据后处理的次数为代价。不过这个模块不再被维护,也有可能在新的python版本中被弃用。
2. 使用方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
def foo(): sum = 0 for i in range(10000): sum += i sumA = bar() sumB = bar() return sum def bar(): sum = 0 for i in range(100000): sum += i return sum if __name__ == "__main__": import cProfile #直接把分析结果打印到控制台 cProfile.run("foo()") #把分析结果保存到文件中,不过内容可读性差...需要调用pstats模块分析结果 cProfile.run("foo()", "result") #还可以直接使用命令行进行操作 #>python -m cProfile myscript.py -o result import pstats #创建Stats对象 p = pstats.Stats("result") #这一行的效果和直接运行cProfile.run("foo()")的显示效果是一样的 p.strip_dirs().sort_stats(-1).print_stats() #strip_dirs():从所有模块名中去掉无关的路径信息 #sort_stats():把打印信息按照标准的module/name/line字符串进行排序 #print_stats():打印出所有分析信息 #按照函数名排序 p.strip_dirs().sort_stats("name").print_stats() #按照在一个函数中累积的运行时间进行排序 #print_stats(3):只打印前3行函数的信息,参数还可为小数,表示前百分之几的函数信息 p.strip_dirs().sort_stats("cumulative").print_stats(3) #还有一种用法 p.sort_stats('time', 'cum').print_stats(.5, 'foo') #先按time排序,再按cumulative时间排序,然后打倒出前50%中含有函数信息 #如果想知道有哪些函数调用了bar,可使用 p.print_callers(0.5, "bar") #同理,查看foo()函数中调用了哪些函数 p.print_callees("foo") |
以上是profile以及pstats模块的简单应用.
3.分析结果图解
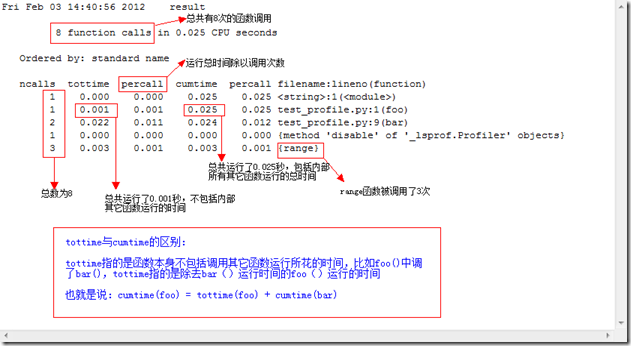
4. 什么是确定性性能分析(Deterministic Profiling)
确定性性能分析指的是反映所有的函数调用,返回,和异常事件的执行所用的时间,以及它们之间的时间间隔。相比之下,统计性性能分析指的是取样有效的程序指令,然后推导出所需要的时间,后者花费比较少的开销,但是给出的结果不够精确。
在Python中,因为其是解释性语言,所以在执行程序的时候,会加入解释器的执行,这部分的执行是不需要进行性能分析的。Python自动为每一个事件提供一个hook,来定位需要分析的代码。除此之外,因为Python解释型语言的本质往往需要在执行程序的时候加入很多其它的开销,而确定性性能分析只会加入一点点处理开销。这样一来,确定性性能分析其实开销不大,还可以提供丰富的统计信息。
函数调用次数的统计能够被用于确定程序中的bug,比如一个不符合常理的次数,明显偏多之类的,还可以用来确定可能的内联函数。函数内部运行时间的统计可被用来确定”hot loops”,那些需要运行时间过长,需要优化的部分;累积时间的统计可被用来确定比较高层次的错误,比如算法选择上的错误。Python的性能分析可以允许直接比较算法的递归实现与迭代实现的。
关于Python Profilers性能分析器的更多相关文章
- python——关于Python Profilers性能分析器
1. 介绍性能分析器 profiler是一个程序,用来描述运行时的程序性能,并且从不同方面提供统计数据加以表述.Python中含有3个模块提供这样的功能,分别是cProfile, profile和ps ...
- [python] - profilers性能分析器
1. 性能分析器: profile, hotshot, cProfile 2. 作用: 测试函数的执行时间 每次脚本执行的总时间
- Python的Profilers性能分析器
关于Python Profilers性能分析器 关于性能分析,python有专门的文档,可查看:http://docs.python.org/library/profile.html?highligh ...
- [转] Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- Python代码性能优化技巧
摘要:代码优化能够让程序运行更快,可以提高程序的执行效率等,对于一名软件开发人员来说,如何优化代码,从哪里入手进行优化?这些都是他们十分关心的问题.本文着重讲了如何优化Python代码,看完一定会让你 ...
- Python 代码性能优化技巧(转)
原文:Python 代码性能优化技巧 Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化. ...
- Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- guider – 全系统Linux性能分析器
Guider是一个免费且开源的,功能强大的全系统性能分析工具,主要以Python for Linux 操作系统编写. 它旨在衡量系统资源使用量并跟踪系统行为,从而使其可以有效分析系统性能问题或进行性能 ...
- 英特尔® 图形性能分析器 2019 R1 版本
了解并下载全新英特尔® 图形性能分析器 2019 R1 版本.新版本新增了 DX11 和 Vulkan 多帧流捕获模式,可以在“帧和图形跟踪分析器”中分析 Vulkan 应用.此外,帧分析器还添加了 ...
随机推荐
- ashx误删后,未能创建类型
描述 今天,因为临时有事儿,需要去一趟其他城市,项目比较赶.所以只能在车上继续敲代码,倒霉的触摸板让我误删一个ashx一般处理程序.好死不死的这个文件的代码还很长. 我的做法是[垃圾桶]→[还原]→V ...
- phpcm nginx 伪静态文件
rewrite ^/show-([0-9]+)-([0-9]+)-([0-9]+).html /index.php?m=content&c=index&a=show&catid ...
- 【leetcode 简单】 第一百一十二题 重复的子字符串
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成.给定的字符串只含有小写英文字母,并且长度不超过10000. 示例 1: 输入: "abab" 输出: True 解释 ...
- 浏览器断点调试js
说了一些 Chrome 开发者工具的技巧,其实并没有涉及到开发者工具最核心的功能之一:断点调试.断点可以让程序运行到某一行的时候,把程序的整个运行状态进行冻结.你可以清晰地看到到这一行的所有的作用域变 ...
- UNIX环境高级编程 第14章 高级I/O
这一章涉及很多概念和函数,包括:非阻塞I/O.记录锁.I/O复用.异步I/O.readv和writev函数以及内存映射. 非阻塞I/O 在Unix中,可以将系统调用分为两种,一种是“低速”系统调用,另 ...
- UNIX网络编程 第4章 基本TCP套接字编程
本章的几个函数在很大程度上展示了面向对象与面向过程的不同之处.
- Servlet笔记2--模拟Servlet本质、第一个Servlet程序、将响应结果输出到浏览器中
以下代码均非IDE开发,所以都不规范,仅供参考 模拟Servlet本质: 模拟Servlet接口: /* SUN公司制定的JavaEE规范:Servlet规范 Servlet接口是Servlet规范中 ...
- Cesium entity click
var url = 'http://202.107.245.51:81/user/dev/api/v2/sql?rows_per_page=40&page=0&sort_order=a ...
- Java Dom对XML的解析和修改操作
与Dom4J和JDom对XML的操作类似,JDK提供的JavaDom解析器用起来一样方便,在解析XML方面Java DOM甚至更甚前两者一筹!其不足之处在于对XML的增删改比较繁琐,特开篇介绍... ...
- vs2010,vs2012注释快捷键
注释:VS2010是(Ctrl+E,C),VS2012是(Ctrl+K, Ctrl+C) 反注释:VS2010是(Ctrl+E,U),VS2012是(Ctrl+K, Ctrl+U)