机器学习实战(一)k-近邻算法
转载请注明源出处:http://www.cnblogs.com/lighten/p/7593656.html
1.原理
本章介绍机器学习实战的第一个算法——k近邻算法(k Nearest Neighbor),也称为kNN。说到机器学习,一般都认为是很复杂,很高深的内容,但实际上其学习门栏并不算高,具备基本的高等数学知识(包括线性代数,概率论)就可以了,甚至一些算法高中生就能够理解了。kNN算法就是一个原理很好理解的算法,不需要多好的数学功底,这是一个分类算法(另一个大类是回归),属于监督学习的范畴(还有非监督学习,监督学习需要注有标记的训练集)。
首先,分类顾名思义就是给同一种事物分成不同的种类,比如人分成男人、女人,书分为工具书,教科书,漫画书等。要对一个事物分类,要有分类的依据,即你为什么这样划分,有时候划分的依据十分准确比如男女按性别,但很多时候是由多个因素来决定划分到哪一个类别,而不同的分类某一单一的因素又可能存在交集,这些因素在机器学习中被称之为特征,特征的选择对算法的准确率也是有影响的。个体用一组特征数据来进行描述,这样计算机处理就成了可能,分类算法所要做的就是判断这个个体所给出的特征属于哪一个类别。方法有很多,kNN采取了一个最简单的方法来判断:判断其与已知分类的训练集数据的差异,差异最小的前k个训练集个体大部分处于哪个分类该输入个体就被认作是哪个分类。
这个原理很好理解,比如判断男女,特征只有身高,体重。通常来说男人都比女人要高和重,即便女人要高,体重也比同等级的男人大部分会轻。所以对于一个输入个体来说,在已知身高、体重的情况下,求其与训练集样本的身高、体重差异,找到训练集中差异最小的k个个体,这k个个体如果大部分是男人,则输入样本就是男人,否则则是女人。选择差异最小的k个个体也就是为了避免小部分不同寻常的样本,因为男人都比女人要高和重也只是大部分情况,这样选择k个的权重,可信度就较高了。差异计算一般采用欧式距离,即各个特征相减,求平方和,开根号:
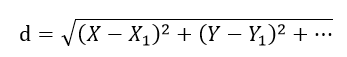
上图就是差异的定义了,这样挑选出K个最小的训练集,已知这些训练集的分类,选择K个训练集大部分所属的分类就是新输入个体的分类了。
2.问题及优缺点
kNN算法的原理简单易懂,但是在实现过程中也是有些问题需要解决的。首先我们需要关注d的计算,kNN选择的是d最小的k个训练集个体,所以d的结果合理性是很重要的。但是由该公式可以很明显的看出,d的大小很可能受到某一单一的特征影响。试想一下如果X的取值范围在1~10,Y的取值范围在1000~10000,那么d的大小严重受到Y特征的影响,那么X的作用就几乎没有了。解决该问题的方法就是将数值归一化,意思就是不管X还是Y,按照合理的放缩方法,使他们落在同一个范围区间,一般就选择0~1之间了。这个放缩方法也并不难得出,公式如下:
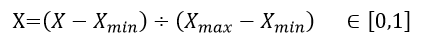
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高、空间复杂度高
从kNN的实现上也能看出来,其计算代价较高,每个个体都需要和所有的训练集个体进行比较,而且kNN算法无法获得指定分类的一般性特征,因此其不适合大量的训练集。
3.代码
下面代码出自《机器学习实战》一书,原书中所有代码例子可以在网站:这里。进行下载。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
机器学习实战(一)k-近邻算法的更多相关文章
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》-k近邻算法
目录 K-近邻算法 k-近邻算法概述 解析和导入数据 使用 Python 导入数据 实施 kNN 分类算法 测试分类器 使用 k-近邻算法改进约会网站的配对效果 收集数据 准备数据:使用 Python ...
- 《机器学习实战》——K近邻算法
三要素:距离度量.k值选择.分类决策 原理: (1) 输入点A,输入已知分类的数据集data (2) 求A与数据集中每个点的距离,归一化,并排序,选择距离最近的前K个点 (3) K个点进行投票,票数最 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习:1.K近邻算法
1.简单案例:预测男女,根据身高,体重,鞋码 import numpy as np import matplotlib import sklearn from skleran.neighbors im ...
- 机器学习实战笔记-2-kNN近邻算法
# k-近邻算法(kNN) 本质是(提取样本集中特征最相似数据(最近邻)的k个分类标签). K-近邻算法的优缺点 例 优点:精度高,对异常值不敏感,无数据输入假定: 缺点:计算复杂度高,空间复杂度高: ...
随机推荐
- python-optparse模块给脚本增加参数选项
import optparse parser = optparse.OptionParser('[-] Usage %prog '+ '-H <RHOST[s]> -l [-p -F ]' ...
- docker 命令介绍
查看镜像 docker images: 列出imagesdocker images -a :列出所有的images(包含历史)docker images --tree :显示镜像的所有层(layer) ...
- 20155225 2016-2017-2 《Java程序设计》第九周学习总结
20155225 2016-2017-2 <Java程序设计>第九周学习总结 教材学习内容总结 JDBC入门 了解JDBC架构 使用JDBC API JDBC是用于执行SQL的解决方案,开 ...
- HDU1551&&HDU1064 Cable master 2017-05-11 17:50 38人阅读 评论(0) 收藏
Cable master Time Limit: ...
- Docker搭建 MySQL 主从复制
为什么选 Docker 搭建主从复制需要两个以上的MySQL, 使用 Docker 非常方便.如果以前没用过,找个简单的文档看看,熟悉一下命令. 搭建过程 1.下载镜像 docker pull mys ...
- Python学习-2.安装IDE
Python安装包中已经包含了一个IDE了,叫IDLE,可以在Python的安装目录内找到路径为 ./Lib/idlelib/idle.bat 或者可以在开始菜单中找到. 但是这个IDE功能很弱,缺少 ...
- Global.asax和HttpModule的执行顺序
Application_Start-->用户自定义的HttpModule-->Application_BeginRequest (注册->调用) 看到Init方法(在用户自定义的 ...
- DropDownList切换选择,服务器控件Repeater未更新
将EnableViewState属性设置为false,这样禁止服务器控件使用视图状态,也就是禁止发送给浏览器HEML中的缓存副本, 每次都会使用新数据. 一旦页面的控件很多,频繁的传递控件状态值对网络 ...
- 创建/读取/删除Session对象
//创建Session对象 Session["userName"] = "顾德博";//保存,这里可以存储任意类型的数据,包括对象.集合等 Session.Ti ...
- C# 调用微信接口的代码
调用微信接口前需要准备的内容. 1.微信公众平台的appid 2.微信公众平台的secret 3..获取tokenid 4.获取ticket 5.生成签名的随机串 6.生成签名的时间戳 7.生成签名 ...