kafka系列 -- 多线程消费者实现
看了一下kafka,然后写了消费Kafka数据的代码。感觉自己功力还是不够。
- 不能随心所欲地操作数据,数据结构没学好,spark的RDD操作没学好。
- 不能很好地组织代码结构,设计模式没学好,面向对象思想理解不够成熟。
消费程序特点
- 用队列来存储要消费的数据。
- 用队列来存储要提交的offest,然后处理线程将其给回消费者提交。
- 每个分区开一个处理线程来处理数据,分区与处理器的映射放在map中。
- 当处理到一定的数量或者距离上一次处理一定的时间间隔后, 由poll线程进行提交offset。
不好的地方:
- 每次处理的数据太少,而且每个数据都进行判断其分区是否已经有处理线程在处理了。
- 获取topic不太优雅。
流程图
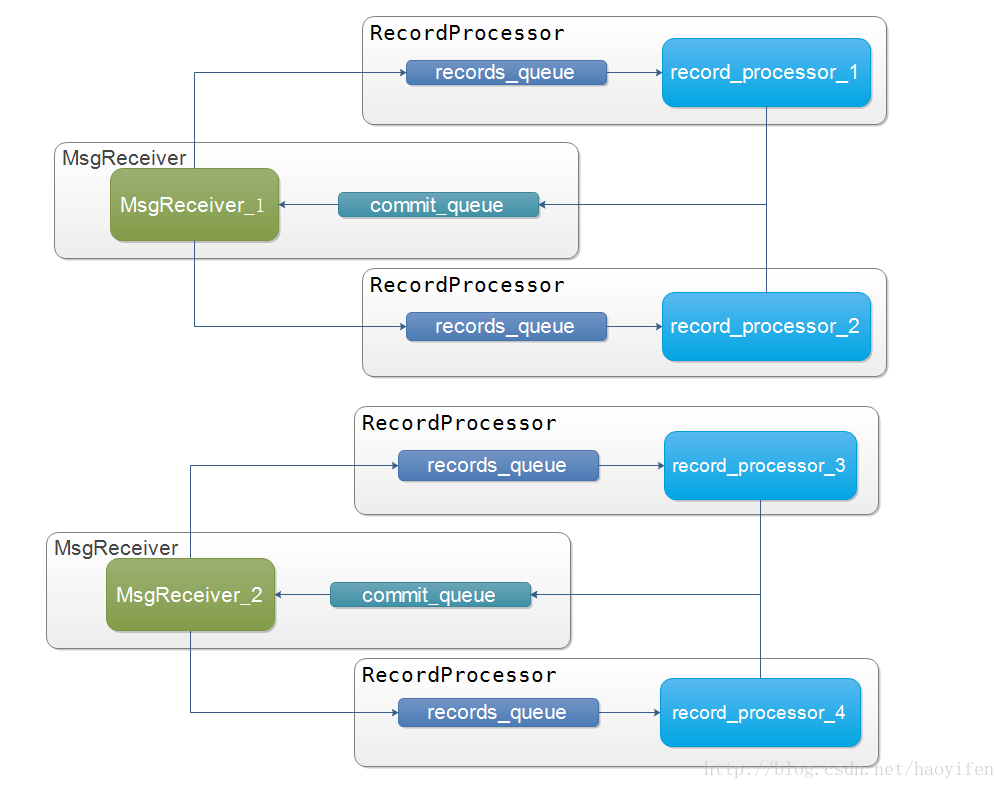
下面是多线程消费者实现:
1. 管理程序
/**
* 负责启动消费者线程MsgReceiver, 保存消费者线程MsgReceiver, 保存处理任务和线程RecordProcessor, 以及销毁这些线程
* Created by stillcoolme on 2018/10/12.
*/
public class KafkaMultiProcessorMain {
private static final Logger logger = LoggerFactory.getLogger(KafkaMultiProcessorMain.class);
// 消费者参数
private Properties consumerProps = new Properties();
// kafka消费者参数
Map<String, Object> consumerConfig;
//存放topic的配置
Map<String, Object> topicConfig;
//订阅的topic
private String alarmTopic;
//消费者线程数组
private Thread[] threads;
//保存处理任务和线程的map
ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks = new ConcurrentHashMap<>();
ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads = new ConcurrentHashMap<>();
public void setAlarmTopic(String alarmTopic) {
this.alarmTopic = alarmTopic;
}
public static void main(String[] args) {
KafkaMultiProcessorMain kafkaMultiProcessor = new KafkaMultiProcessorMain();
//这样设置topic不够优雅啊!!!
kafkaMultiProcessor.setAlarmTopic("picrecord");
kafkaMultiProcessor.init(null);
}
private void init(String consumerPropPath) {
getConsumerProps(consumerPropPath);
consumerConfig = getConsumerConfig();
int threadsNum = 3;
logger.info("create " + threadsNum + " threads to consume kafka warn msg");
threads = new Thread[threadsNum];
for (int i = 0; i < threadsNum; i++) {
MsgReceiver msgReceiver = new MsgReceiver(consumerConfig, alarmTopic, recordProcessorTasks, recordProcessorThreads);
Thread thread = new Thread(msgReceiver);
threads[i] = thread;
}
for (int i = 0; i < threadsNum; i++) {
threads[i].start();
}
logger.info("finish creating" + threadsNum + " threads to consume kafka warn msg");
}
//销毁启动的线程
public void destroy() {
closeRecordProcessThreads();
closeKafkaConsumer();
}
private void closeRecordProcessThreads() {
logger.debug("start to interrupt record process threads");
for (Map.Entry<TopicPartition, Thread> entry : recordProcessorThreads.entrySet()) {
Thread thread = entry.getValue();
thread.interrupt();
}
logger.debug("finish interrupting record process threads");
}
private void closeKafkaConsumer() {
logger.debug("start to interrupt kafka consumer threads");
//使用interrupt中断线程, 在线程的执行方法中已经设置了响应中断信号
for (int i = 0; i < threads.length; i++) {
threads[i].interrupt();
}
logger.debug("finish interrupting consumer threads");
}
private Map<String,Object> getConsumerConfig() {
return ImmutableMap.<String, Object>builder()
.put("bootstrap.servers", consumerProps.getProperty("bootstrap.servers"))
.put("group.id", "group.id")
.put("enable.auto.commit", "false")
.put("session.timeout.ms", "30000")
.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
.put("max.poll.records", 1000)
.build();
}
/**
* 获取消费者参数
*
* @param proPath
*/
private void getConsumerProps(String proPath) {
InputStream inStream = null;
try {
if (StringUtils.isNotEmpty(proPath)) {
inStream = new FileInputStream(proPath);
} else {
inStream = this.getClass().getClassLoader().getResourceAsStream("consumer.properties");
}
consumerProps.load(inStream);
} catch (IOException e) {
logger.error("读取consumer配置文件失败:" + e.getMessage(), e);
} finally {
if (null != inStream) {
try {
inStream.close();
} catch (IOException e) {
logger.error("读取consumer配置文件失败:" + e.getMessage(), e);
}
}
}
}
}
2. 消费者任务 MsgReceiver
/**
* 负责调用 RecordProcessor进行数据处理
* Created by zhangjianhua on 2018/10/12.
*/
public class MsgReceiver implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(MsgReceiver.class);
private BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue = new LinkedBlockingQueue<>();
private ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads;
private ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks;
private String alarmTopic;
private Map<String, Object> consumerConfig;
public MsgReceiver(Map<String, Object> consumerConfig, String alarmTopic,
ConcurrentHashMap<TopicPartition, RecordProcessor> recordProcessorTasks,
ConcurrentHashMap<TopicPartition, Thread> recordProcessorThreads) {
this.consumerConfig = consumerConfig;
this.alarmTopic = alarmTopic;
this.recordProcessorTasks = recordProcessorTasks;
this.recordProcessorThreads = recordProcessorThreads;
}
@Override
public void run() {
//kafka Consumer是非线程安全的,所以需要每个线程建立一个consumer
KafkaConsumer kafkaConsumer = new KafkaConsumer(consumerConfig);
kafkaConsumer.subscribe(Arrays.asList(alarmTopic));
try{
while (!Thread.currentThread().isInterrupted()) {
try {
//看commitQueue里面是非有需要提交的offest, 这样查看好频繁啊!!!
//查看该消费者是否有需要提交的偏移信息, 使用非阻塞读取
Map<TopicPartition, OffsetAndMetadata> offestToCommit = commitQueue.poll();
if (offestToCommit != null) {
logger.info(Thread.currentThread().getName() + "commit offset: " + offestToCommit);
kafkaConsumer.commitAsync();
}
//最多轮询1000ms
ConsumerRecords<String, String> records = kafkaConsumer.poll(1000);
if (records.count() > 0) {
logger.info("poll records size: " + records.count());
}
for (ConsumerRecord record : records) {
String topic = record.topic();
int partition = record.partition();
TopicPartition topicPartition = new TopicPartition(topic, partition);
RecordProcessor processTask = recordProcessorTasks.get(topicPartition);
//每条消息都去检查
//如果当前分区还没有开始消费, 则就没有消费任务在map中
if (processTask == null) {
//生成新的处理任务和线程, 然后将其放入对应的map中进行保存
processTask = new RecordProcessor(commitQueue);
recordProcessorTasks.put(topicPartition, processTask);
Thread processTaskThread = new Thread(processTask);
processTaskThread.setName("Thread-for " + topicPartition.toString());
logger.info("start processor Thread: " + processTaskThread.getName());
processTaskThread.start();
recordProcessorThreads.put(topicPartition, processTaskThread);
}
//有 processor 可以处理该分区的 record了
processTask.addRecordToQueue(record);
}
} catch (Exception e) {
e.printStackTrace();
logger.warn("MsgReceiver exception " + e + " ignore it");
}
}
} finally {
kafkaConsumer.close();
}
}
}
3. 消息处理任务 RecordProcessor
public class RecordProcessor implements Runnable{
private static Logger logger = LoggerFactory.getLogger(RecordProcessor.class);
//保存MsgReceiver线程发送过来的消息
private BlockingQueue<ConsumerRecord<String, String>> queue = new LinkedBlockingQueue<>();
//用于向consumer线程提交消费偏移的队列
private BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue;
//上一次提交时间
private LocalDateTime lastTime = LocalDateTime.now();
//消费了20条数据, 就进行一次提交
private long commitLength = 20L;
//距离上一次提交多久, 就提交一次
private Duration commitTime = Duration.standardSeconds(2);
//当前该线程消费的数据条数
private int completeTask = 0;
//保存上一条消费的数据
private ConsumerRecord<String, String> lastUncommittedRecord;
public RecordProcessor(BlockingQueue<Map<TopicPartition, OffsetAndMetadata>> commitQueue) {
this.commitQueue = commitQueue;
}
@Override
public void run() {
while(!Thread.interrupted()){
ConsumerRecord<String, String> record = null;
try {
record = queue.poll(100, TimeUnit.MICROSECONDS);
if (record != null) {
process(record);
//完成任务数加1
this.completeTask++;
//保存上一条处理记录
lastUncommittedRecord = record;
}
//提交偏移给queue中
commitTOQueue();
} catch (InterruptedException e) {
//线程被interrupt,直接退出
logger.info(Thread.currentThread() + "is interrupted");
}
}
}
//将当前的消费偏移量放到queue中, 由MsgReceiver进行提交
private void commitTOQueue() {
if(lastUncommittedRecord == null){
return;
}
//如果消费了设定的条数, 比如又消费了commitLength消息
boolean arrivedCommitLength = this.completeTask % commitLength == 0;
//获取当前时间, 看是否已经到了需要提交的时间
LocalDateTime currentTime = LocalDateTime.now();
boolean arrivedTime = currentTime.isAfter(lastTime.plus(commitTime));
if(arrivedCommitLength || arrivedTime){
lastTime = currentTime;
long offset = lastUncommittedRecord.offset();
int partition = lastUncommittedRecord.partition();
String topic = lastUncommittedRecord.topic();
TopicPartition topicPartition = new TopicPartition(topic, partition);
logger.info("partition: " + topicPartition + " submit offset: " + (offset + 1L) + " to consumer task");
Map<TopicPartition, OffsetAndMetadata> map = Collections.singletonMap(topicPartition, new OffsetAndMetadata(offset + 1L));
commitQueue.add(map);
//置空
lastUncommittedRecord = null;
}
}
//consumer线程向处理线程的队列中添加record
public void addRecordToQueue(ConsumerRecord<String, String> record) {
try {
queue.put(record);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void process(ConsumerRecord<String, String> record) {
//具体业务逻辑
//System.out.println(record);
}
}
改进
- 对处理程序RecordProcessor进行抽象,抽象出BasePropessor父类。以后业务需求需要不同的处理程序RecordProcessor就可以灵活改变了。
- 反射来构建RecordProcessor??在配置文件配置具体要new的RecordProcessor类路径,然后在创建MsgReceiver的时候传递进去。
参考
- Kafka Consumer多线程实例 : 如这篇文章所说的维护了多个worker来做具体业务处理,这篇文章用的是ThreadPoolExecutor线程池。
kafka系列 -- 多线程消费者实现的更多相关文章
- Kafka 系列(四)—— Kafka 消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- Kafka系列2:深入理解Kafka消费者
Kafka系列2:深入理解Kafka消费者 上篇聊了Kafka概况,包含了Kafka的基本概念.设计原理,以及设计核心.本篇单独聊聊Kafka的消费者,包括如下内容: 生产者是如何生产消息 如何创建生 ...
- 【原创】Kafka Consumer多线程实例
Kafka 0.9版本开始推出了Java版本的consumer,优化了coordinator的设计以及摆脱了对zookeeper的依赖.社区最近也在探讨正式用这套consumer API替换Scala ...
- Apache Kafka 0.9消费者客户端
当Kafka最初创建时,它与Scala生产者和消费者客户端一起运送.随着时间的推移,我们开始意识到这些API的许多限制.例如,我们有一个“高级”消费者API,它支持消费者组并处理故障转移,但不支持许多 ...
- kafka系列之(3)——Coordinator与offset管理和Consumer Rebalance
from:http://www.jianshu.com/p/5aa8776868bb kafka系列之(3)——Coordinator与offset管理和Consumer Rebalance 时之结绳 ...
- Kafka系列一之架构介绍和安装
Kafka架构介绍和安装 写在前面 还是那句话,当你学习一个新的东西之前,你总得知道这个东西是什么?这个东西可以用来做什么?然后你才会去学习它,使用它.简单来说,kafka既是一个消息队列,如今,它也 ...
- Kafka系列1:Kafka概况
Kafka系列1:Kafka概况 Kafka是当前分布式系统中最流行的消息中间件之一,凭借着其高吞吐量的设计,在日志收集系统和消息系统的应用场景中深得开发者喜爱.本篇就聊聊Kafka相关的一些知识点. ...
- kafka生产者和消费者api的简单使用
kafka生产者和消费者api的简单使用 一.背景 二.需要实现的功能 1.生产者实现功能 1.KafkaProducer线程安全的,可以在多线程中使用. 2.消息发送的key和value的序列化 3 ...
- 从零开始实现lmax-Disruptor队列(三)多线程消费者WorkerPool原理解析
MyDisruptor V3版本介绍 在v2版本的MyDisruptor实现多消费者.消费者组间依赖功能后.按照计划,v3版本的MyDisruptor需要支持多线程消费者的功能. 由于该文属于系列博客 ...
随机推荐
- FireDACQuery FDQuery New
FDQuery FDQuery1->ChangeCount;也有UpdatesPending属性 FDQuery1->ApplyUpdates() ExecSQL('select * fr ...
- 前端-jQuery的ajax方法
https://www.cnblogs.com/majj/p/9134922.html 0.什么是ajax AJAX = 异步的javascript和XML(Asynchronous Javascri ...
- 19 网络编程--Socket 套接字方法
1.Socket(也称套接字)介绍 socket这个东东干的事情,就是帮你把tcp/ip协议层的各种数据封装啦.数据发送.接收等通过代码已经给你封装好了 ,你只需要调用几行代码,就可以给别的机器发消息 ...
- JSTL标签库学习记录2-fmt
fmt的标签为辅助性功能标签 设置编码 <fmt:requestEncoding value=""> 国际化相关 <fmt:setLocale value=&qu ...
- Life is in the little things --- Spreading wildly on Facebook
这是在FaceBook上疯传的一组图 简笔画的图画的不算精细 但却狠狠地击中许多人的心灵 有时候生活中简单的一件小事, 恰恰是使得你的人生变得更有意义的一件大事! 别人总告诉你 人生是这样的 ▼ ...
- Python环境配置, atom-python配置
环境变量 路径 在window下配置环境变量,配置到文件夹级就可以了: D:\program\python3 编码 因为windows默认的编码是ASIIC,所以使用atom时候中文是乱码,需要在环境 ...
- 重学Java
Java web 的课程告一段落了 现在我觉得我应该重新学习一下 Java基础 先分享下昨天学习递归后写的两个短短的代码 1.求5的阶乘 package test; public class fiv ...
- go递归函数如何传递数组切片slice
数组切片slice这个东西看起来很美好,真正用起来会发现有诸多的不爽. 第一,数组.数组切片混淆不清,使用方式完全一样,有时候一些特性又完全不一样,搞不清原理很容易误使用. 第二,数组切片的appen ...
- 微擎系统 微信支付 get_brand_wcpay_request:fail
支付授权目录问题,有一个是域名加app的
- cmd 字符串截取
@echo off set "url=www.mzwu.com" echo 1.字符串截取 echo %url:~4,4% echo %url:~4,-4% echo %url:~ ...