caffe下训练时遇到的一些问题汇总
1、报错:“db_lmdb.hpp:14] Check failed:mdb_status ==0(112 vs.0)磁盘空间不足。”
这问题是由于lmdb在windows下无法使用lmdb的库,所以要改成leveldb。
但是要注意:由于backend默认的是lmdb,所以你每一次用到生成的图片leveldb数据的时候,都要把“--backend=leveldb”带上。如转换图片格式时:
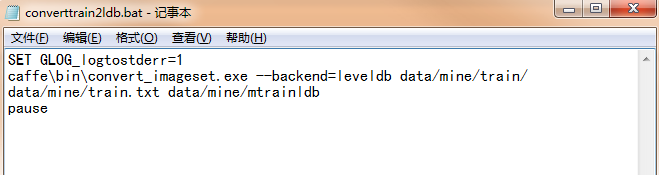
又如计算图像的均值时:
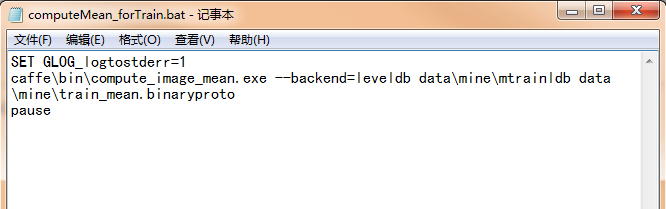
还有在.prototxt中
data_param {
source: "./mysample_val_leveldb"
batch_size:
backend: LEVELDB //这个也要改掉的,原来是LMDB
}
2、caffe下使用“bvlc_reference_caffenet”模型进行训练时,出现了“Check failed:data_”
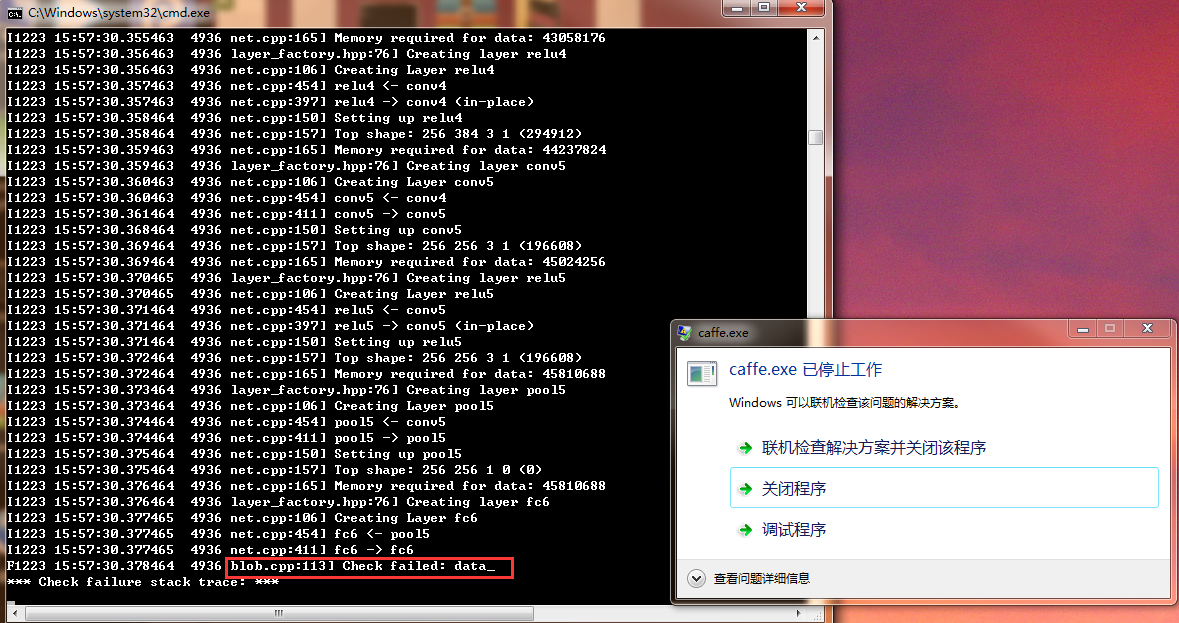
这个问题是由于训练样本的图像尺寸太小了,以至于到pool5池化层的时候输入的尺寸已经小于kernel的大小了,进而下一步输入编程了0x0,因此会报错。
解决的方法是要么在归一化图像尺寸时足够大(小于64*64好像就不行了),要么换用另一种模型(如果图像本身就小,放大图像会丢失图像特征,此时可尝试使用Cifar10模型)
3、caffe训练时遇到loss一直居高不下时:
http://blog.sina.com.cn/s/blog_141f234870102w941.html
我利用caffe训练一个基于AlexNet的三分类分类器,将train_val.prototxt的全连接输出层的输出类别数目改为3,训练一直不收敛,loss很高;当把输出改成4或1000(>3)的时候,网络可以收敛。也就是caffenet结构的输出层的类别数一定要大于我训练集的类别数才可以收敛!后来查了半天才发现原因,让我泪奔。。。
原来我把图像类型的label设置成1,2,3,改成0,1,2后,最后全连接层的输出改为3就OK了。
待更新...!
caffe下训练时遇到的一些问题汇总的更多相关文章
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 记录:测试本机下使用 GPU 训练时不会导致内存溢出的最大参数数目
本机使用的 GPU 是 GeForce 840M,2G 显存,本机内存 8G. 试验时,使用 vgg 网络,调整 vgg 网络中的参数,使得使用对应的 batch_size 时不会提示内存溢出.使用的 ...
- CAFFE中训练与使用阶段网络设计的不同
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS), 在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY). 但是当我们真正要使 ...
- caffe 如何训练自己的数据图片
申明:此教程加工于caffe 如何训练自己的数据图片 一.准备数据 有条件的同学,可以去imagenet的官网http://www.image-net.org/download-images,下载im ...
- Windows平台上Caffe的训练与学习方法(以数据库CIFAR-10为例)
Windows平台上Caffe的训练与学习方法(以数据库CIFAR-10为例) 在完成winodws平台上的caffe环境的搭建之后,亟待掌握的就是如何在caffe中进行训练与学习,下面将进行简单的介 ...
- DenseNet算法详解——思路就是highway,DneseNet在训练时十分消耗内存
论文笔记:Densely Connected Convolutional Networks(DenseNet模型详解) 2017年09月28日 11:58:49 阅读数:1814 [ 转载自http: ...
- caffe 下一些参数的设置
weight_decay防止过拟合的参数,使用方式:1 样本越多,该值越小2 模型参数越多,该值越大一般建议值:weight_decay: 0.0005 lr_mult,decay_mult关于偏置与 ...
- faster r-cnn 在CPU配置下训练自己的数据
因为没有GPU,所以在CPU下训练自己的数据,中间遇到了各种各样的坑,还好没有放弃,特以此文记录此过程. 1.在CPU下配置faster r-cnn,参考博客:http://blog.csdn.net ...
- caffe绘制训练过程的loss和accuracy曲线
转自:http://blog.csdn.net/u013078356/article/details/51154847 在caffe的训练过程中,大家难免想图形化自己的训练数据,以便更好的展示结果.如 ...
随机推荐
- 动画的使用—Drawable Animation
Drawable Animation可以称为帧动画,因为它是通过每次播放一帧Drawable资源实现的. Drawable Animation算不上真正意义上的动画,因为它的内部实现是通过定时发送消息 ...
- iOS小知识点(UI部分)
1. 父视图通过Tag来找到UIView UIView *targetView = [superView viewWithTag:10];//只在当前视图以及subviews中找,不能再孙子中找. 2 ...
- 五种开源协议(GPL,LGPL,BSD,MIT,Apache)
什么是许可协议? 什么是许可,当你为你的产品签发许可,你是在出让自己的权利,不过,你仍然拥有版权和专利(如果申请了的话),许可的目的是,向使用你产品的人提供 一定的权限. 不管产品是免费向公众分发,还 ...
- MFC 文件遍历
对文件的操作MFC提供了CFileFind 类,运用此类,我们可以轻松的多文件进行操作 假设我们删除当前目录下所有jpg格式的图片: CFileFind finder; CFile fp; bool ...
- php集成动态口令认证
这篇文章主要为大家详细介绍了php集成动态口令认证,动态口令采用一次一密.用过密码作废的方式来提高安全性能,感兴趣的小伙伴们可以参考一下 大多数系统目前均使用的静态密码进行身份认证登录,但由于静态密码 ...
- Maven随记
如何保持依赖的多个jar保持版本一致 在引入依赖的时候常常需要依赖多个独立的模块, 譬如Spring的content, aop等等, 为了保持版本一致, 可以设置<spring.version& ...
- 红米3 TWRP-3.0.2(android_6.0.1_r72分支)中文版Recovery更新于20161018
TWRP3.0.2更新简介 TWRP是TeamWin团队https://github.com/TeamWin/Team-Win-Recovery-Project的开源项目,也是Omnirom系统默认的 ...
- bzoj4498: 魔法的碰撞
首先,如果排列确定,那么就可以组合学解决了,不过排列数很多,显然不能枚举. 我们发现如果区间不能重叠的话,总长度减去所有区间长度就是能用的多余格子数. 然而相邻区间可以重叠较小区间一半的长度,因此这些 ...
- Android实现透明式状态栏
Android实现透明式状态栏 1. 修改style样式 2. 创建values-v19文件夹 3. 在这个文件夹下创建style.xml 4. 对activity_main.xml进行修改 移 ...
- 【原】理解javascript中的this
最近的文章基本都是总结javascript基础内容的,因为我觉得这些东西很重要.而且很多时候你觉得你理解了,其实并没有你自认为的那么理解.十月份没怎么写文章,因为国庆出去玩的比较久,心变野了,现在是时 ...