四. python网络编程
第八章.网络基础知识
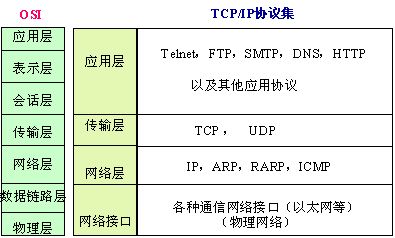
1. TCP/IP协议介绍
1.TCP/IP概念
TCP/IP: Transmission Control Protocol/Internet Protocol的简写,中译名为传输控制协议/因特网互联协议,又名网络通讯协议,是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。TCP/IP 定义了电子设备如何连入因特网,以及数据如何在它们之间传输的标准。协议采用了4层的层级结构,每一层都呼叫它的下一层所提供的协议来完成自己的需求。通俗而言:TCP负责发现传输的问题,一有问题就发出信号,要求重新传输,直到所有数据安全正确地传输到目的地。而IP是给因特网的每一台联网设备规定一个地址。
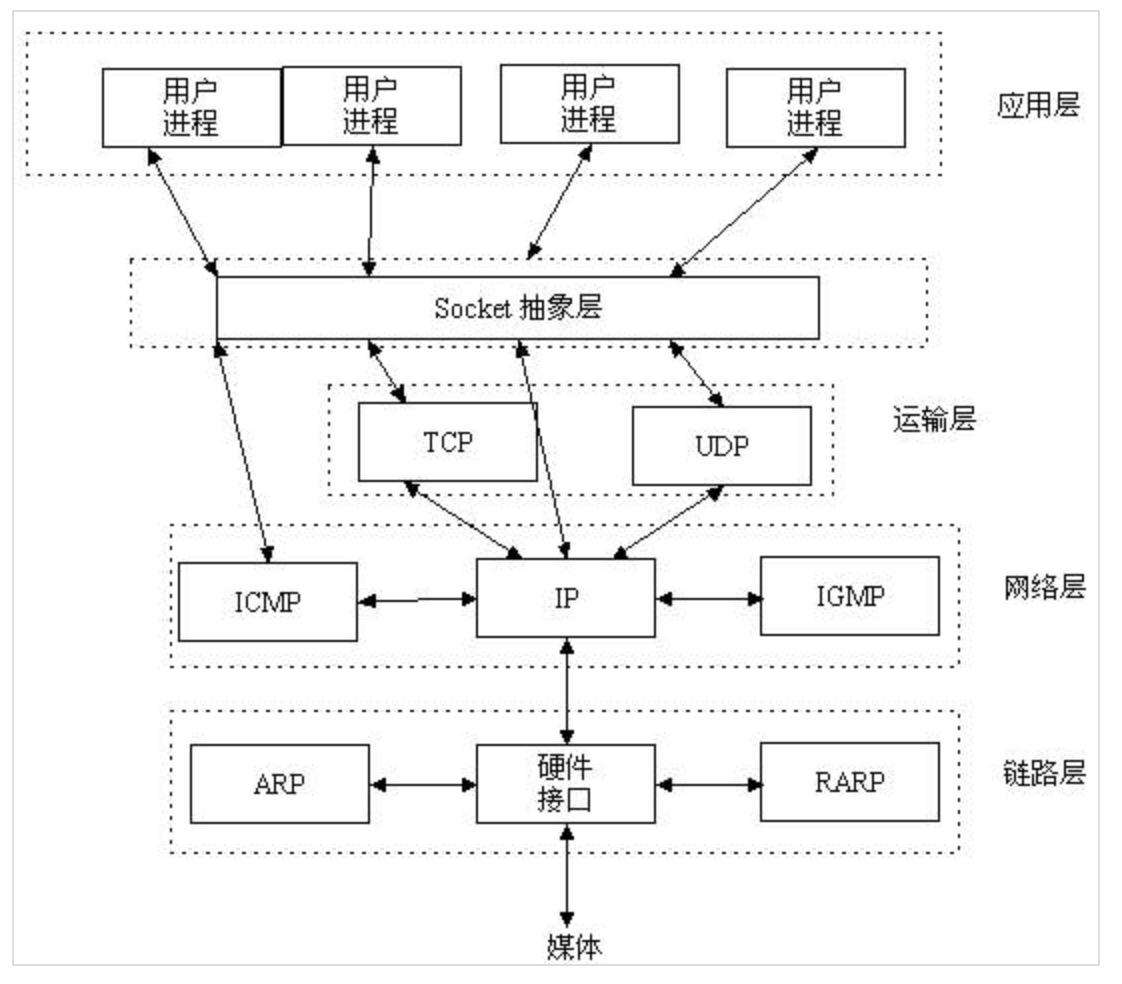
2. socket概念
socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求。
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,对于文件用【打开】【读写】【关闭】模式来操作。socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)
socket和file的区别:
- file模块是针对某个指定文件进行【打开】【读写】【关闭】
- socket模块是针对 服务器端 和 客户端Socket 进行【打开】【读写】【关闭】
3. OSI七层模型与 TCP/IP协议分层图
2.socket编程
1. socke通信模型图

2. 基本语法类型
例1
- # -*- coding:utf-8 -*-
- # Author: Raymond
- import socket
- server = socket.socket()
- server.bind(('localhost',6969)) #绑定要监听的端口
- server.listen() #监听上面bind绑定的端口
- print("我要开始等电话了....")
- conn,addr = server.accept() #等待电话打进来
- print("电话来了")
- data = conn.recv(1024)
- print("服务端收到的信息",data)
- conn.send(data.upper()) #或修改为conn.send(b"hello client!")
- server.close()
服务端示例(一)
- # -*- coding:utf-8 -*-
- # Author: Raymond
- import socket
- client = socket.socket() #声明socket类型,同时生成socket连接对象
- client.connect(('localhost',6969))
- client.send(b"hello world!") #或修改为client.send(b"hello server!")
- data = client.recv(1024)
- print("客户端收到的信息:",data)
- client.close()
客户端示例(一)
例2
- # server code
- import socket
- ip_port = ('localhost', 9999)
- s = socket.socket() # 买手机
- s.bind(ip_port) # 买手机卡
- s.listen(5) # 开机,5个链接数挂起排队
- conn,addr = s.accept() #等待电话;conn表示一个客户端与服务器的一条通信链路
- while True:
- try:
- recv_data = conn.recv(1024) # 收消息,客户端发空消息,服务端recv会被阻塞,无法接受消息
- if str(recv_data,encoding='utf-8') == 'exit':
- break
- print(str(recv_data,encoding='utf-8'),type(recv_data))
- send_data = recv_data.upper() # 发消息
- conn.send(send_data)
- except Exception:
- break
- conn.close() # 挂电话
服务端示例(二)
- # client code
- import socket
- ip_port = ('localhost',9999)
- s = socket.socket() # 买手机
- s.connect(ip_port) # 拨号
- while True:
- send_data = input(">>:").strip() # 输入消息内容
- if len(send_data) == 0:
- continue
- s.send(bytes(send_data,encoding='utf-8')) # 发消息,python 3.x 必须以字节码发送
- if send_data == 'exit':
- break
- recv_data = s.recv(1024)
- # 收消息
- print(str(recv_data,encoding='utf-8')) # 打印bytes字节码
- s.close() # 挂电话
- 客户端示例(二)
客户端示例(二)
3. socket常用方法
更多功能
|
参数一:地址簇 socket.AF_INET IPv4(默认) socket.AF_UNIX 只能够用于单一的Unix系统进程间通信 参数二:类型 socket.SOCK_STREAM 流式socket , for TCP (默认) socket.SOCK_RAW 原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。 参数三:协议 0 (默认)与特定的地址家族相关的协议,如果是 0 ,则系统就会根据地址格式和套接类别,自动选择一个合适的协议
UDP Demo |
sk.bind(address)
s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。
sk.listen(backlog)
开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。
backlog等于5,表示内核已经接到了连接请求,但服务器还没有调用accept进行处理的连接个数最大为5
这个值不能无限大,因为要在内核中维护连接队列
sk.setblocking(bool)
是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
sk.accept()
接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。
接收TCP 客户的连接(阻塞式)等待连接的到来
sk.connect(address)
连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
sk.connect_ex(address)
同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061
sk.close()
关闭套接字
sk.recv(bufsize[,flag])
接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。
sk.recvfrom(bufsize[.flag])
与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
sk.send(string[,flag])
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。即:可能未将指定内容全部发送。
sk.sendall(string[,flag])
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
内部通过递归调用send,将所有内容发送出去。
sk.sendto(string[,flag],address)
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
sk.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如 client 连接最多等待5s )
sk.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
sk.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
sk.fileno()
套接字的文件描述符
- # 服务端
- import socket
- ip_port = ('127.0.0.1',9999)
- sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
- sk.bind(ip_port)
- while True:
- data,(host,port) = sk.recvfrom(1024)
- print(data,host,port)
- sk.sendto(bytes('ok', encoding='utf-8'), (host,port))
- #客户端
- import socket
- ip_port = ('127.0.0.1',9999)
- sk = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
- while True:
- inp = input('数据:').strip()
- if inp == 'exit':
- break
- sk.sendto(bytes(inp, encoding='utf-8'),ip_port)
- data = sk.recvfrom(1024)
- print(data)
- sk.close()
UDP
实例:智能机器人
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import socket
- ip_port = ('127.0.0.1',8888)
- sk = socket.socket()
- sk.bind(ip_port)
- sk.listen(5)
- while True:
- conn,address = sk.accept()
- conn.sendall('欢迎致电 10086,请输入1xxx,0转人工服务.')
- Flag = True
- while Flag:
- data = conn.recv(1024)
- if data == 'exit':
- Flag = False
- elif data == '':
- conn.sendall('通过可能会被录音.balabala一大推')
- else:
- conn.sendall('请重新输入.')
- conn.close()
服务端
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import socket
- ip_port = ('127.0.0.1',8005)
- sk = socket.socket()
- sk.connect(ip_port)
- sk.settimeout(5)
- while True:
- data = sk.recv(1024)
- print 'receive:',data
- inp = raw_input('please input:')
- sk.sendall(inp)
- if inp == 'exit':
- break
- sk.close()
客户端
3. socket简单ssh交互
- 基于python 3.x版本的socket智能手法字节码,python 2.x可以收发字符串
- socket中循环输入功能只在客户端退出就可以了。
- socket编程中accept()和recv()是阻塞的。(基于链接正常)
- listen(n) n代表:能挂起的链接数;如果n = 1,代表可以链接一个,挂起一个,第三个拒绝
- 服务端出现端口冲突,修改监听端口号
- 以太网协议传送最大的包为1500字节。(工业标准1024-8192字节)
- import socket
- import subprocess
- ip_port = ('localhost', 9999)
- s = socket.socket() # 买手机
- s.bind(ip_port) # 买手机卡
- s.listen(5) # 开机,5个链接数挂起排队
- conn,addr = s.accept() # 等待电话;conn表示一个客户端与服务器的一条通信链路
- while True:
- try:
- recv_data = conn.recv(1024) # 收消息,客户端发空消息,服务端recv会被阻塞,无法接受消息
- if str(recv_data,encoding='utf-8') == 'exit':
- break
- print(str(recv_data,encoding='utf-8'),type(recv_data))
- p = subprocess.Popen(str(recv_data,encoding='utf-8'),shell=True,stdout=subprocess.PIPE)
- res = p.stdout.read() # 返回系统命令的标准输出结果
- send_data = str(res,encoding='gbk')
- print(send_data)
- # send_data = recv_data.upper() # 发消息
- conn.send(bytes(send_data,encoding='utf-8'))
- except Exception:
- break
- conn.close() # 挂电话
SSH服务端
- import socket
- ip_port = ('localhost',9999)
- s = socket.socket() # 买手机
- s.connect(ip_port) # 拨号
- while True:
- send_data = input(">>:").strip() # 输入消息内容
- if len(send_data) == 0:
- continue
- s.send(bytes(send_data,encoding='utf-8')) # 发消息,python 3.x 必须以字节码发送
- if send_data == 'exit':
- break
- recv_data = s.recv(1024)
- # 收消息
- print(str(recv_data,encoding='utf-8')) # 打印bytes字节码
- s.close() # 挂电话
SSH客户端
4. socket粘包解决
粘包概念:客户端发发一条命令,服务端返回一部分结果,剩余部分丢失,丢失部分会出现在下一条命令返回的结果中
- # 粘包问题 需调试
- import socket
- import subprocess
- ip_port = ('localhost', 9999)
- s = socket.socket()
- s.bind(ip_port)
- s.listen(5)
- while True: # 用来重复接收新的链接
- conn, addr = s.accept() # 接收客户端链接请求,返回conn(相当于一个特定链接),addr是客户端ip+port
- while True: # 用来基于一个链接重复收发消息
- try: # 捕捉客户端异常关闭错误
- recv_data = conn.recv(1024) # 收消息,阻塞
- if len(recv_data) == 0:break # 客户端退出,服务端将收到空消息
- p = subprocess.Popen(str(recv_data,encoding='utf-8'),shell=True,stdout=subprocess.PIPE) # 执行系统命令
- res = p.stdout.read()
- if len(res) == 0:
- send_data = 'cmd_error'
- else:
- send_data = str(res,encoding='gbk') # windows平台命令的标准输出为GBK编码,需要转换
- send_data = bytes(send_data,encoding='utf-8')
- # 解决粘包问题
- ready_tag = 'Ready|%s' %len(send_data)
- conn.send(bytes(ready_tag,encoding='utf-8'))
- feedback = conn.recv(1024) # start
- feedback = str(feedback,encoding='utf-8')
- if feedback.startswith('Start'):
- conn.send(send_data) # 发送命令的执行结果
- except Exception:
- break
- conn.close()
粘包服务端
- # 粘包问题
- import socket
- ip_port = ('localhost',9999)
- s = socket.socket()
- s.connect(ip_port)
- while True:
- send_data = input(">>:").strip()
- if len(send_data) == 0:continue
- s.send(bytes(send_data,encoding='utf-8'))
- if send_data == 'exit':break
- # 解决粘包问题
- ready_tag = s.recv(1024)
- ready_tag = str(ready_tag,encoding='utf-8')
- if ready_tag.startswith('Ready'):
- msg_size = int(ready_tag.split('|')[-1])
- start_tag = 'Start'
- s.send(bytes(start_tag,encoding='utf-8'))
- recv_size = 0
- recv_msg = b''
- while recv_size < msg_size:
- recv_data = s.recv(1024)
- recv_msg += recv_data
- recv_size += len(recv_data)
- print('MSG SIZE %s RECEV SIZE %s' %(msg_size,recv_size))
- # 收消息
- print(str(recv_data,encoding='utf-8'))
- s.close()
粘包客户端
5. socketServer介绍
6. 实现多并发命令执行
7. 实现文件上传下载
8. python吊炸天的小知识之作用域
- python中无块级作用域,代码块中定义的变量可在任意地方使用
- python中以函数为作用域,函数中的变量不可在函数外使用
- python中有作用域链,由内向外找,直到找不到报错
- 在函数未执行前,作用域以及链已确定
- 小知识之作用域
- #############################################################################
- # 代码块
- if 1==1:
- name = 'alex'
- print(name)
- 输出结果:alex
- ############################################################################
- # 函数
- def func():
- name = 'alex'
- func()
- print(name)
- 输出结果:alex
- #############################################################################
- # 作用域一
- name = 'alex'
- def f1():
- name = 'a'
- def f2():
- name = 'b'
- print(name)
- f2()
- f1()
- 输出结果:b
- #############################################################################
- # 作用域二
- name = 'alex'
- def f1():
- print(name)
- def f2():
- name = 'eric'
- f1()
- f2()
- 输出结果:alex
- #############################################################################
- # 作用域三
- name = 'alex'
- def f1():
- print(name)
- def f2():
- name = 'eric'
- return f1
- ret = f2()
- ret()
- 输出结果:alex
作用域
9. python吊炸天的小知识之面试题
- #小知识之面试题
- #############################################################################
- li = [x+100 for x in range(10)]
- print(li)
- 输出结果:[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
- #-------------------------------------------------------------------------------
- li = [x+100 for x in range(10) if x>6]
- print(li)
- 输出结果:[107, 108, 109]
- -------------------------------------------------------------------------------
- li = [lambda :x for x in range(10)]
- r = li[0]()
- print(r)
- 输出结果:9
- -------------------------------------------------------------------------------
- li = []
- for i in range(10):
- def f1():
- return i
- li.append(f1) # # li是列表,内部元素是相同功能的函数
- # print(i)
- print(li[0]())
- print(li[1]())
- 输出结果;
- 9
- 9
- -------------------------------------------------------------------------------
- li = []
- for i in range(10):
- def f1(x=i): # 本质看是否执行此行代码,执行了就可以取到值,不执行就取不到值。本行执行了。
- return x
- li.append(f1) # # li是列表,内部元素是相同功能的函数
- # print(i)
- print(li[0]())
- print(li[1]())
- print(li[2]())
- 输出结果:
- 0
- 1
- 2
10. I/O多路复用实现伪并发
I/O多路复用:监听socket内部对象是否发生变化
- # I/O多路复用概述:用来监听socket对象内部是否变化了
- import socket
- import select
- sk = socket.socket()
- sk.bind(('127.0.0.1',9999))
- sk.listen(5)
- while True:
- rlist,w,e = select.select([sk],[],[],1) # select()内部监听socket对象,循环等1秒;无连接,一直循环下去;
- print(rlist) # sk,sk1,sk2其中哪个变化,则r返回哪个值
- # r = [sk,] # r获取socket对象列表,可判断是否有新连接
- # r = [sk1,]
- # r = [sk1,sk2] # 这两个同时连接,返回两个值
- for r in rlist:
- print(r) # r获取socket对象列表,可判断是否有新链接
- conn,addrs = r.accept() # 接收客户端链接,Conn也是socket对象
- conn.sendall(bytes('hello',encoding='utf-8'))
- 无限循环输出结果:
- [<socket.socket fd=396, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9999)>]
- <socket.socket fd=396, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 9999)>
服务端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',9999,))
- data = sk.recv(1024)
- print(data)
- while True:
- input('>>>')
- sk.close()
客户端
I/O多路复用:伪并发实例
- # I/O多路复用伪并发实例
- import socket
- import select
- sk = socket.socket()
- sk.bind(('127.0.0.1',9999))
- sk.listen(5)
- inputs = [sk,]
- while True:
- rlist,w,e = select.select([sk],[],[],1)
- print(len(inputs),len(rlist))
- for r in rlist:
- if r == sk: # 新客户端来连接
- print(r)
- conn,addrs = r.accept()
- inputs.append(conn) # 此处将新连接客户端添加到inputs列表中
- conn.sendall(bytes('hello', encoding='utf-8'))
- else:
- r.recv(1024)
服务端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',9999,))
- data = sk.recv(1024)
- print(data)
- while True:
- input('>>>')
- sk.close()
客户端
I/O多路复用:连接的客户端断开后,服务端进行抛出异常处理,并移除断开的客户端
- # 连接的客户端断开后,服务端进行抛出异常处理,并移除断开的客户端
- import socket
- import select
- sk = socket.socket()
- sk.bind(('127.0.0.1',9999))
- sk.listen(5)
- inputs = [sk,]
- while True:
- rlist,w,e = select.select([sk],[],[],1)
- print(len(inputs),len(rlist))
- for r in rlist:
- if r == sk: # 新客户端来连接
- print(r)
- conn,addrs = r.accept()
- inputs.append(conn) # 此处将新连接客户端添加到inputs列表中
- conn.sendall(bytes('hello', encoding='utf-8'))
- else:
- print('==============') # 有人给我发消息了
- try:
- ret = r.recv(1024)
- if not ret:
- raise Exception('断开连接') # 主动抛出异常
- except Exception as e:
- inputs.remove(r) # 如果客户端突发断开连接,此处则移除断掉的客户端
服务端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',9999,))
- data = sk.recv(1024)
- print(data)
- while True:
- input('>>>')
- sk.close()
客户端
I/O多路复用:读写分离(客户端发消息,服务端回发消息)
- # I/O多路复用之读写分离(客户端发消息,服务端回发消息)
- import socket
- import select
- sk = socket.socket()
- sk.bind(('127.0.0.1',9999))
- sk.listen(5)
- inputs = [sk,]
- outputs = []
- while True:
- rlist,wlist,e = select.select(inputs,outputs,[],1) # outputs表示所有客户端给服务端发的消息,outputs==wlist
- print(len(inputs),len(rlist),len(outputs),len(wlist))
- for r in rlist:
- if r == sk: # 新客户端来连接
- print(r)
- conn,addrs = r.accept()
- inputs.append(conn) # 此处将新连接客户端添加到inputs列表中
- conn.sendall(bytes('hello', encoding='utf-8'))
- else:
- print('==============') # 有人给我发消息了
- try:
- ret = r.recv(1024)
- r.sendall(ret)
- if not ret:
- raise Exception('断开连接') # 主动抛出异常
- else:
- outputs.append(r)
- except Exception as e:
- inputs.remove(r) # 如果客户端突发断开连接,此处则移除断掉的客户端
- for w in wlist: # 所有给我发消息的客户端
- w.sendall(bytes('response',encoding='utf-8'))
- outputs.remove(w)
服务端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',9998,))
- data = sk.recv(1024)
- print(data)
- while True:
- inp = input('>>>')
- sk.sendall(bytes(inp,encoding='utf-8')) # 客户端发消息,服务端回发消息
- print(sk.recv(1024))
- sk.close()
客户端
I/O多路复用:读写分离(客户端发一条消息,服务端回发:客户端消息+服务端消息)
- # I/O多路复用之读写分离(客户端发一条消息,服务端回发:客户端消息+服务端消息) 需调试!!!
- import socket
- import select
- sk = socket.socket()
- sk.bind(('127.0.0.1',9998))
- sk.listen(5)
- inputs = [sk,]
- outputs = []
- message = {}
- '''
- message = {
- 张三:[msg1,msg2]
- 李四:[msg1,msg2]
- }
- '''
- while True:
- rlist,wlist,elist = select.select(inputs,outputs,[sk,],1) # outputs表示所有客户端给服务端发的消息,outputs==wlist;第三个参数sk也是socket对象,内部会检测sk内部发生错误,会把sk赋值给elist
- print(len(inputs),len(rlist),len(outputs),len(wlist))
- for r in rlist:
- if r == sk: # 新客户端来连接
- print(r)
- conn,addrs = r.accept()
- inputs.append(conn) # 此处将新连接客户端添加到inputs列表中
- message[conn] = [] # 客户端来连接则把conn对象当作key值放入消息字典中,然后在存入空列表中
- conn.sendall(bytes('hello', encoding='utf-8'))
- else:
- print('==============') # 有人给我发消息了
- try:
- ret = r.recv(1024)
- r.sendall(ret)
- if not ret:
- raise Exception('断开连接') # 主动抛出异常
- else:
- outputs.append(r)
- message[r].append(ret) # 把客户端发的消息放到ret列表里
- except Exception as e:
- inputs.remove(r) # 如果客户端突发断开连接,此处则移除断掉的客户端
- del message[r]
- for w in wlist: # 所有给我发消息的客户端
- msg = message[w].pop()
- resp = msg + bytes('response',encoding='utf-8')
- w.sendall(resp)
- outputs.remove(w)
服务端
- import socket
- sk = socket.socket()
- sk.connect(('127.0.0.1',9998,))
- data = sk.recv(1024)
- print(data)
- while True:
- inp = input('>>>')
- sk.sendall(bytes(inp,encoding='utf-8')) # 客户端发消息,服务端回发消息
- print(sk.recv(1024))
- sk.close()
客户端
11. 初识多线程
12. socket源码剖析
13. 线程进程概述
- 一个python应用程序,可以有多个进程和多个线程
- 默认为单进程和单线程(效率低)
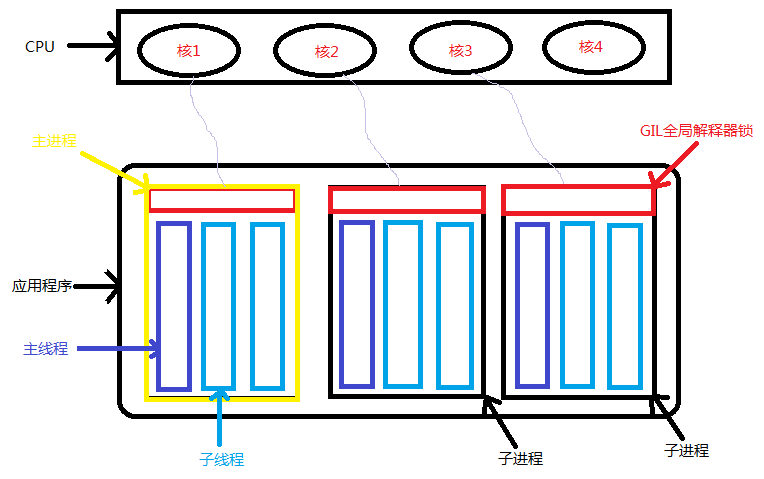
- 多线程上面有一个GIL(全局解释器锁),给进程起到屏障作用,进程里的多线程同一时间只能有一个线程工作,不能同时被CPU调度工作。(java,c#里没有GIL功能)
- python多线程应用场景:1. I/O操作不占用CPU(音频,视频,显卡都交给驱动去工作),适合用多线程提高并发效率;2. 计算型操作占用CPU,适合用多进程提高并发效率,每个进程可利用多核CPU同时进行并行计算。
- I/O密集型操作:用多线程; 计算型操作:用多进程
进程、线程与GIL关系原理图如下所示:
14. 线程基本使用
- # 线程基本使用
- import time
- def f1(arg): # f1()表示一个单进程,单线程应用程序
- time.sleep(5)
- print(arg) # f1()默认为主线程,t表示新创建的子线程
- # f1表示主线程,下面的t表示创建的子线程,创建好线程,等待CPU调度工作,不代表当前线程会被立即执行
- import threading # 导入线程模块
- t = threading.Thread(target=f1,args=(123,)) # 此处创建一个子线程,target=f1表示执行f1函数,并传参数args给f1(arg)
- # t.setDaemon(True) # 参数为True时,表示主线程不等待子线程执行完毕直接输出end;则整个程序执行完毕;False则表示主线程执行完后,继续等待子线程执行完毕
- t.start()
- t.join(2) # 表示主线程执行到此处,等待子线程执行完毕后,再继续执行下面的代码;参数(2)表示主线程运行到此处最多等待2秒
- print('end')
- # 仔细阅读socketserver源码(与其他语言原理一样)
- # 仔细阅读saltstack源码 ,提高能力
第九章.线程、进程、协程和缓存的基本使用
1. 本章内容概要
- 线程:1.基本使用;2.生产者消费者模型(队列);3自定义线程池(2.x没有此概念;3.x还不完善)
- 进程:1.基本使用;2.本身提供的进程池
- 协程:两个模块 greenlet和gevent
- 缓存:python操作的两个缓存 memcached和redis
- rabbitMQ
- MySQL
2. 创建线程的两种方式
- # 创建线程的两种方式
- #第一种
- import threading
- def f1(arg):
- print(arg)
- t = threading.Thread(target=f1,args=(,))
- t.start() # 创建好线程,等待CPU调用
- t.run() # CPU调度线程工作时,会去执行t.run()方法,该方法再去触发线程工作
- # -------------------------------------------------------------------------------
- # 自定义类创建线程并去执行
- # 第二种方法
- import threading
- class MyThread(threading.Thread):
- def __init__(self,func,args): # 当前类的构造方法
- self.func = func
- self.args = args
- super(MyThread,self).__init__() # 执行父类的构造方法
- def run(self): # run()方法里可实现任意功能
- self.func(self.args)
- def f2():
- print(arg)
- obj = MyThread(f2,)
- obj.start()
3. 先进先出队列的使用
- import queue
- q = queue.Queue(10) # 创建一个先进先出队列,参数表示最多放10个数据
- q.put(11) # 依次把数据11,22,33放入队列
- q.put(22)
- q.put(33)
- print(q.qsize()) # 输出队列元素个数,检测队列真实个数
- print(q.get()) # 从队列取数据
- print(q.get())
- print(q.get())
- 输出结果:
- 3
- 11
- 22
- 33
- -----------------------------------------------------------------------------------------
- import queue
- q = queue.Queue(10) # 创建一个先进先出队列,参数表示最多放10个数据
- q.put(11) # 依次把数据11,22,33放入队列
- q.put(22)
- q.put(23)
- q.put(24)
- q.put(25)
- print(q.qsize()) # 输出队列元素个数,检测队列真实个数
- q.put(33,timeout=2) # timeout表示超时时间,等2秒如果队列有位置加入,无位置则报错
- q.put(34,block=False) # 此处不再阻塞,直接报错
- print(q.get()) # 从队列取数据
- print(q.get())
- print(q.get())
- # print(q.get(block=False)) # 不再阻塞等待取数据,直接报错
- # -----------------------------------------------------------------------------------------
- import queue
- q = queue.Queue()
- q.put(123)
- q.put(456)
- q.get()
- q.get()
- q.task_done() # 去除元素后,告诉队列当前任务已完成
- # q.join() # 表示如果队列任务没有完成,则等待
- print('end')
- # task_done()与join() 一般联合使用,当队列任务执行完毕,不再阻塞
4. 其他队列介绍
queue.Queue() # 先进先出队列
queue.LifoQueue() # 后进先出队列
queue.PriorityQueue() # 优先级队列
queue.deque() #双向队列
- # 后进先出队列
- import queue
- q = queue.LifoQueue()
- q.put(123)
- q.put(456)
- print(q.get())
- print(q.get())
- 输出结果:
- 456
- 123
后进先出队列
- # 优先级队列 (0-n,优先级由高到低)
- import queue
- q = queue.PriorityQueue()
- q.put((1,'a'))
- q.put((0,'b'))
- q.put((2,'c'))
- print(q.get())
- 输出结果:(0, 'b')
优先级队列
- # 双向队列
- import queue
- q = queue.deque()
- q.append(123) # 放数据
- q.append(456)
- q.appendleft(789) # 左边放数据
- print(q.pop()) # 取数据
- print(q.popleft()) # 左边取数据
- 输出结果:
- 456
- 789
双向队列
5. 生产者消费者模型
- # 生产消费者模型
- import queue
- import threading
- import time
- q = queue.Queue() # 创建空队列
- def productor(arg): # 买票订单处理,加入队列
- q.put(str(arg)+'-票')
- def consumer(arg) # 服务器后台卖票处理请求
- while True:
- print(arg,q.get())
- time.sleep(2) # 等待2秒后继续处理
- for i in range(300): # 创建新的300个买票者
- t = threading.Thread(target=productor,args=(i,))
- t.start()
- for j in range(3): # 创建3个卖票者循环处理请求,每次可并发处理3个请求,
- t = threading.Thread(target=consumer,args=(j,))
- t.start()
6. 线程锁
- # 线程锁
- import threading
- import time
- NUM = 10
- def func(lo):
- global NUM
- lo.acquire() # 上锁,表示同一时刻只允许一个线程来操作
- NUM -= 1
- time.sleep(2)
- print(NUM)
- lo.release() # 开锁
- # lock = threading.Lock() # 单层锁
- lock = threading.RLock() # 多层锁
- for i in range(10):
- t = threading.Thread(target=func,args=(lock,))
- t.start()
7. 信号量以及事件
- # 信号量以及事件
- # 事件:表示把线程全部锁上,再一次性放开工作,相当于红绿灯,线程是车辆
- import threading
- def func(i,e):
- print(i)
- e.wait() # 全部线程停止到这里,这里检测是什么灯;默认是红灯
- print(i+100)
- event = threading.Event()
- for i in range(10):
- t = threading.Thread(target=func,args=(i,event))
- t.start()
- event.clear() # 表示全部停止,设置成红灯
- inp = input('>>>:')
- if inp == "":
- event.set() # 表示把上面停止的线程放行,设置成绿灯
- 输出结果:
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- >>>:1
- 102
- 104
- 109
- 106
- 105
- 100
- 103
- 107
- 101
- 108
8. 条件以及定时器
- # 条件以及定时器
- # 第一种条件锁,线程等待输入条件,才能调用工作
- import threading
- def condition():
- ret = False
- r = input('>>>')
- if r == 'true':
- ret = True
- else:
- ret = False
- return ret
- def func(i,con):
- print(i)
- con.acquire()
- con.wait()
- print(i+100)
- con.release()
- c = threading.Condition()
- for i in range(10):
- t = threading.Thread(target=func,args=(i,c,))
- t.start()
- while True: # 主线程
- inp = input('>>>') # 输入几,就放出几个线程
- if inp == 'q':
- break
- c.acquire()
- c.notify(int(inp))
- c.release()
- 输出结果:
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- >>>1
- >>>100
- 2
- >>>101
- 102
- 3
- >>>103
- 105
- 104
- # ###########################################################################################
- # 当满足某个条件时,才让线程一个一个出去
- import threading
- def condition():
- ret = False
- r = input('>>>')
- if r == 'true':
- ret = True
- else:
- ret = False
- return ret
- def func(i,con):
- print(i)
- con.acquire()
- con.wait_for(condition) # 等待某个条件成立,才执行。否则一直等待
- print(i+100)
- con.release()
- c = threading.Condition()
- for i in range(10):
- t = threading.Thread(target=func,args=(i,c,))
- t.start()
- 输出结果:
- 0
- >>>1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- true
- >>>101
- >>>true
- 102
- >>>false
- >>>
条件
- # 定时器
- from threading import Timer
- def hello():
- print("hello,world")
- t = Timer(2,hello) # 延迟2秒后执行hello()函数
- t.start()
- print('end') # 此处立即打印后,再延迟2秒输出上面函数结果
定时器
9. 自定义线程池
- 设置一个容器(有最大个数限制),创建队列放线程;
- 添加令牌,取一个,少一个;
- 无线程时等待
- 线程执行完毕,交还线程;
- # 流程:1.定义一个容器(最大个数);2.取一个,少一个;3.无线程时等待;4. 线程执行完毕,交还线程;
- # # 自定义线程池,每5个线程执行一次
- import threading
- import queue
- import time
- class Threadpool():
- def __init__(self,maxsize=5): # 创建线程池,maxsize表示线程池最多有多少个线程
- self.maxsize = maxsize
- self._q = queue.Queue(maxsize) # 队列此刻为空,最多放了5个元素,元素为类
- for i in range(maxsize):
- self._q.put(threading.Thread) # 表示把一个类名逐个放入线程池
- def get_thread(self):
- return self._q.get() # 获取线程,取一个线程类,上面线程池少一个
- def add_thread(self):
- self._q.put(threading.Thread) # 线程少一个时,又增加一个
- pool = Threadpool(5) # 创建线程池,最大个数为5个线程可以使用
- def task(arg,p): # 获取pool传递的参数,
- print(arg)
- time.sleep(1)
- p.add_thread() # 表示任务执行完,再增加一个,这样会每5个任务并发执行一次
- for i in range(100): # 创建100个任务
- t = pool.get_thread() # 从线程池获取一个线程类
- obj = t(target=task,args=(i,pool)) # 获取一个线程对象,加pool参数,传递到task函数的参数p.
- obj.start() # 执行
自定义线程池任务执行
10. 进程基本操作
- # 进程基本操作
- # 多进程适用于linux
- from multiprocessing import Process
- from multiprocessing import Array
- from multiprocessing import Manager # 特殊的字典
- import multiprocessing
- # from multiprocessing import queues # 特殊队列,能够让进程间数据共享;只能在linux运行
- import threading
- import time
- def foo(i,arg):
- arg[i] = i+100
- for item in arg:
- print(item)
- print('=======================')
- if __name__ == "__main__":
- li = Array('i',10) # 这种方法不常用
- for i in range(10):
- p = Process(target=foo,args=(i,li))
- p.start()
- 输出结果:
- 0
- 0
- 0
- 103
- 0
- 0
- 0
- 0
- 0
- 0
- == == == == == == == == == == == =
- 0
- 0
- 102
- 103
- 0
- 0
- 0
- 0
- 0
- 0
- == == == == == == == == == == == =
- 100
- 0
- 102
- 103
- 0
- 0
- 0
- 0
- 0
- 0
- == == == == == == == == == == == =
- 100
- 0
- 102
- 103
- 104
- 0
- 0
- 0
- 0
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 0
- 0
- 0
- 0
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 0
- 106
- 0
- 0
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 0
- 106
- 107
- 0
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 0
- 106
- 107
- 108
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 0
- == == == == == == == == == == == =
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- == == == == == == == == == == == =
进程间数据共享一
- from multiprocessing import Process
- from multiprocessing import Array
- from multiprocessing import Manager # 特殊的字典
- import multiprocessing
- # from multiprocessing import queues # 特殊队列,能够让进程间数据共享;只能在linux运行
- import threading
- import time
- def foo(i, arg):
- print('say hi',i)
- arg[i] = i + 100
- print(arg.values())
- if __name__ == "__main__":
- # li = Array('i', 10) # 这种方法不常用
- obj = Manager()
- li = obj.dict() # 常用方法
- for i in range(10):
- p = Process(target=foo, args=(i, li))
- # p.daemon = True
- p.start()
- p.join()
- print('end')
- 输出结果:
- say hi 0
- [100]
- say hi 1
- [100, 101]
- say hi 2
- [100, 101, 102]
- say hi 3
- [100, 101, 102, 103]
- say hi 4
- [100, 101, 102, 103, 104]
- say hi 5
- [100, 101, 102, 103, 104, 105]
- say hi 6
- [100, 101, 102, 103, 104, 105, 106]
- say hi 7
- [100, 101, 102, 103, 104, 105, 106, 107]
- say hi 8
- [100, 101, 102, 103, 104, 105, 106, 107, 108]
- say hi 9
- [100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
- end
进程间数据共享二
11. 进程锁
- # 进程锁,所有的进程同时去执行同一任务
- from multiprocessing import Process,queues
- from multiprocessing import Array
- from multiprocessing import RLock,Lock,Condition,Semaphore
- import multiprocessing
- import time
- def foo(i,lis):
- lis[0] = lis[0] - 1
- time.sleep(1)
- print('say hi',lis[0])
- if __name__ == "__main__":
- li = Array('i',1)
- li[0] = 10
- for i in range(10):
- p = Process(target=foo,args=(i,li)) # 创建10个进程,每个进程都去执行foo方法
- p.start()
- 输出结果:
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- say hi 0
- # ###########################################################################################
- # 创建进程锁,所有的进程逐个去执行同一任务
- from multiprocessing import Process,queues
- from multiprocessing import Array
- from multiprocessing import RLock,Lock,Condition,Semaphore
- import multiprocessing
- import time
- def foo(i,lis,lc): # lc参数是接收下面线程中lock的参数
- lc.acquire() # 加锁
- lis[0] = lis[0] - 1
- time.sleep(1)
- print('say hi',lis[0])
- lc.release() # 释放锁
- if __name__ == "__main__":
- li = Array('i',1)
- li[0] = 10
- lock = RLock() # 创建进程锁,并传递给下面的lock参数
- for i in range(10):
- p = Process(target=foo,args=(i,li,lock)) # 创建10个进程,每个进程都去执行foo方法
- p.start()
- 输出结果:
- say hi 9
- say hi 8
- say hi 7
- say hi 6
- say hi 5
- say hi 4
- say hi 3
- say hi 2
- say hi 1
- say hi 0
12. 线程池
- 进程池
- from multiprocessing import Pool # 导入进程池
- import time
- def f1(arg):
- time.sleep(1)
- print(arg)
- if __name__ == "__main__":
- pool = Pool(5) # 创建只有5个进程的池
- for i in range(10): # 30个任务
- pool.apply(func=f1,args=(i,)) # 每个进程去执行f1
- 输出结果:
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- # 进程池
- from multiprocessing import Pool # 导入进程池
- import time
- def f1(arg):
- time.sleep(1)
- print(arg)
- if __name__ == "__main__":
- pool = Pool(5) # 创建只有5个进程的池
- for i in range(10): # 30个任务
- pool.apply(func=f1,args=(i,)) # 每个进程去执行f1
- pool.apply_async(func=f1,args=(i,)) # apply表示去进程池取进程并执行串行操作
- print('end')
- pool.close() # 表示所有的30个任务执行完毕才执行下面任务
- time.sleep(1)
- # pool.terminet() # 立即终止任务执行
- pool.join() #进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
- 输出结果:
- 0
- 0
- 1
- 1
- 2
- 3
- 2
- 4
- 3
- 4
- 5
- 6
- 5
- 7
- 6
- 8
- 7
- 8
- 9
- end
- 9
13. 协程的介绍
- # 协程
- # 原理:利用一个线程,分解一个线程成为多个“微线程”(程序级别在做,与操作系统无关)
- # greenlet #本质上实现协程功能
- # gevent # 内部封装了底层功能greenlet,gevent是高级功能;是协程(高性能),是人为创建,只限I/O请求
- from greenlet import greenlet
- def test1():
- print(12)
- gr2.switch() # 切换作用
- print(34)
- gr2.switch()
- def test2():
- print(56)
- gr1.switch()
- print(78)
- gr1 = greenlet(test1)
- gr2 = greenlet(test2)
- gr1.switch()
- 输出结果:
- 12
- 56
- 34
- 78
- 协程切换操作
协程切换操作一
- import gevent
- def foo():
- print('Running in foo')
- gevent.sleep(0) # 切换作用
- print('Explicit context switch to foo again')
- def bar():
- print('Explicit context to bar')
- gevent.sleep(0)
- print('Implicit context switch back to bar')
- gevent.joinall([ # 表示要执行下面两个协程
- gevent.spawn(foo),
- gevent.spawn(bar),
- ])
- 输出结果:
- Running in foo
- Explicit context to bar
- Explicit context switch to foo again
- Implicit context switch back to bar
协程切换操作二
- # 协程发送http请求实例:一个线程并发发送3个http请求
- #
- from gevent import monkey;monkey.patch_all() # 特殊socket请求发送后返回状态
- import gevent # 协程
- import requests
- def func(url):
- print('GET: %s' % url)
- resp = requests.get(url)
- data = resp.text
- print('%d bytes receivd from %s' % (len(data),url))
- gevent.joinall([
- gevent.spawn(func,'http://www.python.org/'),
- gevent.spawn(func,'http://www.yahoo.com/'),
- gevent.spawn(func,'http://www.cnblogs.com'),
- gevent.spawn(func,'http://www.baidu.com'),
- ])
协程发送http请求
14. Python操作memcached和redis模块介绍
memcached支持类型:
K-->"字符串"
redis支持类型:
K-->"字符串" 字符串
K-->[11,22,33,22] 列表
K-->{"k" : xxx} 字典
K-->[11,22,33] 集合
K-->[(11,1),(12,2),(13,3)] 排序集合
支持持久化功能
python操作mencached和redis需2个条件:
1.服务端安装所需软件
2.本地安装其对应模块(本质通过ssh或端口)
15. Memcached以及redis操作介绍
一. Memcached
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
Memcached安装和基本使用
Memcached安装:
- wget http://memcached.org/latest
- tar -zxvf memcached-1.x.x.tar.gz
- cd memcached-1.x.x
- ./configure && make && make test && sudo make install
- PS:依赖libevent
- yum install libevent-devel
- apt-get install libevent-dev
启动Memcached
- memcached -d -m 10 -u root -l 10.211.55.4 -p 12000 -c 256 -P /tmp/memcached.pid
- 参数说明:
- -d 是启动一个守护进程
- -m 是分配给Memcache使用的内存数量,单位是MB
- -u 是运行Memcache的用户
- -l 是监听的服务器IP地址
- -p 是设置Memcache监听的端口,最好是1024以上的端口
- -c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定
- -P 是设置保存Memcache的pid文件
Memcached命令
- 存储命令: set/add/replace/append/prepend/cas
- 获取命令: get/gets
- 其他命令: delete/stats..
Python操作Memcached
安装API
- python操作Memcached使用Python-memcached模块
- 下载安装:https://pypi.python.org/pypi/python-memcached
1、第一次操作
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- mc.set("foo", "bar")
- ret = mc.get('foo')
- print ret
Ps:debug = True 表示运行出现错误时,现实错误信息,上线后移除该参数。
2、天生支持集群
python-memcached模块原生支持集群操作,其原理是在内存维护一个主机列表,且集群中主机的权重值和主机在列表中重复出现的次数成正比
- 主机 权重
- 1.1.1.1 1
- 1.1.1.2 2
- 1.1.1.3 1
- 那么在内存中主机列表为:
- host_list = ["1.1.1.1", "1.1.1.2", "1.1.1.2", "1.1.1.3", ]
如果用户根据如果要在内存中创建一个键值对(如:k1 = "v1"),那么要执行一下步骤:
- 根据算法将 k1 转换成一个数字
- 将数字和主机列表长度求余数,得到一个值 N( 0 <= N < 列表长度 )
- 在主机列表中根据 第2步得到的值为索引获取主机,例如:host_list[N]
- 连接 将第3步中获取的主机,将 k1 = "v1" 放置在该服务器的内存中
代码实现如下:
- mc = memcache.Client([('1.1.1.1:12000', 1), ('1.1.1.2:12000', 2), ('1.1.1.3:12000', 1)], debug=True)
- mc.set('k1', 'v1')
3、add
添加一条键值对,如果已经存在的 key,重复执行add操作异常
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- mc.add('k1', 'v1')
- # mc.add('k1', 'v2') # 报错,对已经存在的key重复添加,失败!!!
4、replace
replace 修改某个key的值,如果key不存在,则异常
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- # 如果memcache中存在kkkk,则替换成功,否则一场
- mc.replace('kkkk','999')
5、set 和 set_multi
set 设置一个键值对,如果key不存在,则创建,如果key存在,则修改
set_multi 设置多个键值对,如果key不存在,则创建,如果key存在,则修改
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- mc.set('key0', 'wupeiqi')
- mc.set_multi({'key1': 'val1', 'key2': 'val2'})
6、delete 和 delete_multi
delete 在Memcached中删除指定的一个键值对
delete_multi 在Memcached中删除指定的多个键值对
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- mc.delete('key0')
- mc.delete_multi(['key1', 'key2'])
7、get 和 get_multi
get 获取一个键值对
get_multi 获取多一个键值对
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- val = mc.get('key0')
- item_dict = mc.get_multi(["key1", "key2", "key3"])
8、append 和 prepend
append 修改指定key的值,在该值 后面 追加内容
prepend 修改指定key的值,在该值 前面 插入内容
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- # k1 = "v1"
- mc.append('k1', 'after')
- # k1 = "v1after"
- mc.prepend('k1', 'before')
- # k1 = "beforev1after"
9、decr 和 incr
incr 自增,将Memcached中的某一个值增加 N ( N默认为1 )
decr 自减,将Memcached中的某一个值减少 N ( N默认为1 )
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True)
- mc.set('k1', '777')
- mc.incr('k1')
- # k1 = 778
- mc.incr('k1', 10)
- # k1 = 788
- mc.decr('k1')
- # k1 = 787
- mc.decr('k1', 10)
- # k1 = 777
10、gets 和 cas
如商城商品剩余个数,假设改值保存在memcache中,product_count = 900
A用户刷新页面从memcache中读取到product_count = 900
B用户刷新页面从memcache中读取到product_count = 900
如果A、B用户均购买商品
A用户修改商品剩余个数 product_count=899
B用户修改商品剩余个数 product_count=899
如此一来缓存内的数据便不在正确,两个用户购买商品后,商品剩余还是 899
如果使用python的set和get来操作以上过程,那么程序就会如上述所示情况!
如果想要避免此情况的发生,只要使用 gets 和 cas 即可,如:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import memcache
- mc = memcache.Client(['10.211.55.4:12000'], debug=True, cache_cas=True)
- v = mc.gets('product_count')
- # ...
- # 如果有人在gets之后和cas之前修改了product_count,那么,下面的设置将会执行失败,剖出异常,从而避免非正常数据的产生
- mc.cas('product_count', "899")
Ps:本质上每次执行gets时,会从memcache中获取一个自增的数字,通过cas去修改gets的值时,会携带之前获取的自增值和memcache中的自增值进行比较,如果相等,则可以提交,如果不想等,那表示在gets和cas执行之间,又有其他人执行了gets(获取了缓冲的指定值), 如此一来有可能出现非正常数据,则不允许修改。
二. redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
- 1. 使用Redis有哪些好处?
- (1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
- (2) 支持丰富数据类型,支持string,list,set,sorted set,hash
- (3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- (4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
- 2. redis相比memcached有哪些优势?
- (1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
- (2) redis的速度比memcached快很多
- (3) redis可以持久化其数据
- 3. redis常见性能问题和解决方案:
- (1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
- (2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
- (3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
- (4) 尽量避免在压力很大的主库上增加从库
- (5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
- 这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
- 4. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
- 相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
- voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
- 5. Memcache与Redis的区别都有哪些?
- 1)、存储方式
- Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
- Redis有部份存在硬盘上,这样能保证数据的持久性。
- 2)、数据支持类型
- Memcache对数据类型支持相对简单。
- Redis有复杂的数据类型。
- 3),value大小
- redis最大可以达到1GB,而memcache只有1MB
- 6. Redis 常见的性能问题都有哪些?如何解决?
- 1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
- 2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
- 4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
- 7, redis 最适合的场景
- Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
- 如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
- 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- 、Redis支持数据的备份,即master-slave模式的数据备份。
- 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- (1)、会话缓存(Session Cache)
- 最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
- 幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
- (2)、全页缓存(FPC)
- 除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
- 再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
- 此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
- (3)、队列
- Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
- 如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
- (4),排行榜/计数器
- Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
- 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
- ZRANGE user_scores 0 10 WITHSCORES
- Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
- (5)、发布/订阅
- 最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
- Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
redis优势及应用场景
- Redis安装和基本使用
- wget http://download.redis.io/releases/redis-3.0.6.tar.gz
- tar xzf redis-3.0.6.tar.gz
- cd redis-3.0.6
- make
启动服务端
- src/redis-server
启动客户端
- src/redis-cli
- redis> set foo bar
- OK
- redis> get foo
- "bar"
- Python操作Redis
- sudo pip install redis
- or
- sudo easy_install redis
- or
- 源码安装
- 详见:https://github.com/WoLpH/redis-py
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import redis
- r = redis.Redis(host='10.211.55.4', port=6379)
- r.set('foo', 'Bar')
- print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import redis
- pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
- r = redis.Redis(connection_pool=pool)
- r.set('foo', 'Bar')
- print r.get('foo')
3、操作
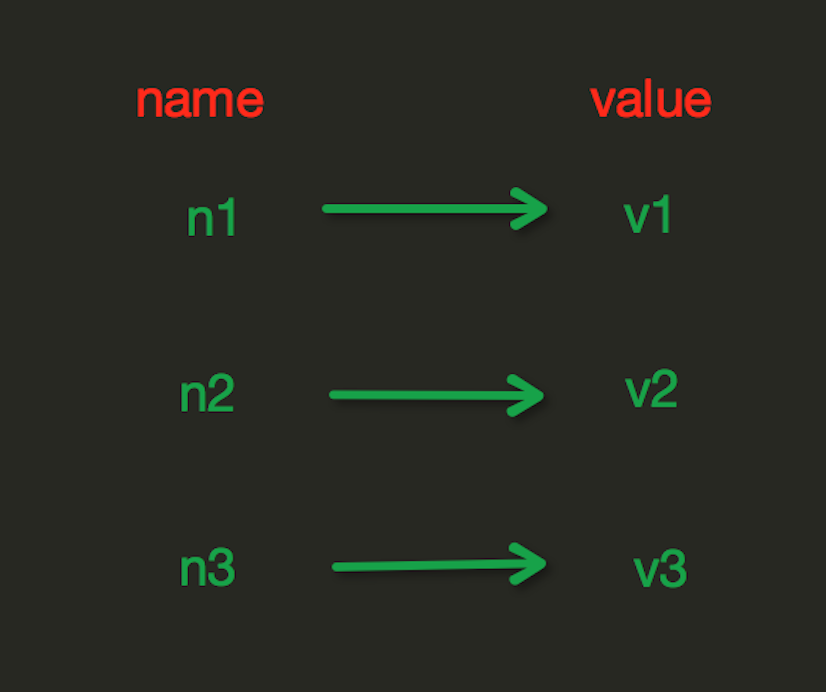
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
|
set(name, value, ex=None, px=None, nx=False, xx=False)
setnx(name, value)
setex(name, value, time)
mset(*args, **kwargs)
get(name)
mget(keys, *args)
getset(name, value)
getrange(key, start, end)
setrange(name, offset, value)
setbit(name, offset, value)
getbit(name, offset)
bitcount(key, start=None, end=None)
bitop(operation, dest, *keys)
strlen(name)
incr(self, name, amount=1)
incrbyfloat(self, name, amount=1.0)
decr(self, name, amount=1)
append(key, value)
|
Hash操作,redis中Hash在内存中的存储格式如下图:

|
hset(name, key, value)
hmset(name, mapping)
hget(name,key)
hmget(name, keys, *args)
hgetall(name)
hlen(name)
hkeys(name)
hvals(name)
hexists(name, key)
hdel(name,*keys)
hincrby(name, key, amount=1)
hincrbyfloat(name, key, amount=1.0)
hscan(name, cursor=0, match=None, count=None)
hscan_iter(name, match=None, count=None)
|
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
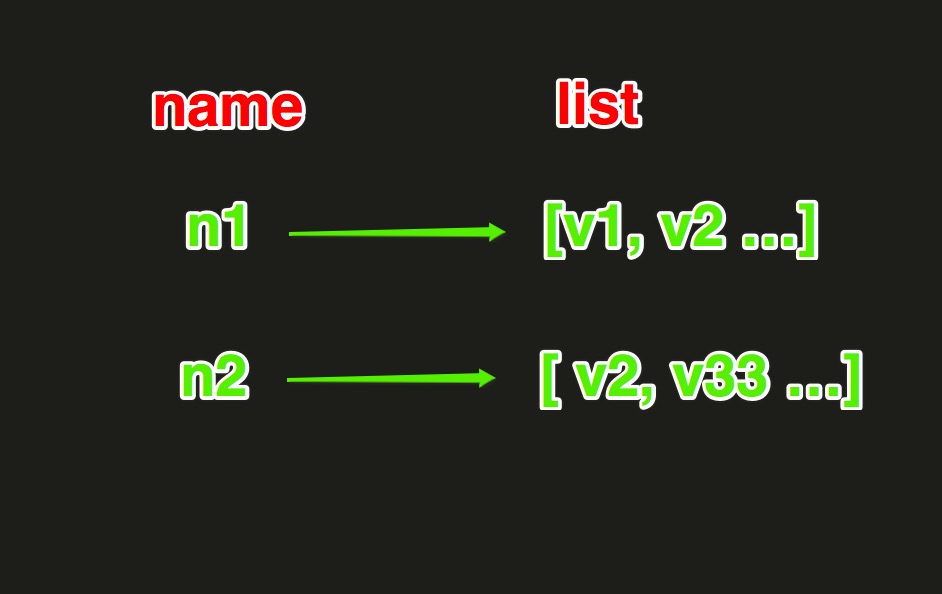
|
lpush(name,values)
llen(name)
linsert(name, where, refvalue, value))
r.lset(name, index, value)
r.lrem(name, value, num)
lpop(name)
lindex(name, index)
lrange(name, start, end)
ltrim(name, start, end)
rpoplpush(src, dst)
blpop(keys, timeout)
brpoplpush(src, dst, timeout=0)
自定义增量迭代
Set操作,Set集合就是不允许重复的列表 sadd(name,values)
scard(name)
sdiff(keys, *args)
sdiffstore(dest, keys, *args)
sinter(keys, *args)
sinterstore(dest, keys, *args)
sismember(name, value)
smembers(name)
smove(src, dst, value)
spop(name)
srandmember(name, numbers)
srem(name, values)
sunion(keys, *args)
sunionstore(dest,keys, *args)
sscan(name, cursor=0, match=None, count=None)
|
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
|
zadd(name, *args, **kwargs)
zcard(name)
zcount(name, min, max)
zincrby(name, value, amount)
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
zrank(name, value)
zrangebylex(name, min, max, start=None, num=None)
zrem(name, values)
zremrangebyrank(name, min, max)
zremrangebyscore(name, min, max)
zremrangebylex(name, min, max)
zscore(name, value)
zinterstore(dest, keys, aggregate=None)
zunionstore(dest, keys, aggregate=None)
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
|
其他常用操作
|
delete(*names)
exists(name)
keys(pattern='*')
rename(src, dst)
move(name, db))
randomkey()
type(name)
scan(cursor=0, match=None, count=None)
|
4、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import redis
- pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
- r = redis.Redis(connection_pool=pool)
- # pipe = r.pipeline(transaction=False)
- pipe = r.pipeline(transaction=True)
- pipe.multi()
- pipe.set('name', 'alex')
- pipe.set('role', 'sb')
- pipe.execute()
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import redis
- conn = redis.Redis(host='192.168.1.41',port=6379)
- conn.set('count',1000)
- with conn.pipeline() as pipe:
- # 先监视,自己的值没有被修改过
- conn.watch('count')
- # 事务开始
- pipe.multi()
- old_count = conn.get('count')
- count = int(old_count)
- if count > 0: # 有库存
- pipe.set('count', count - 1)
- # 执行,把所有命令一次性推送过去
- pipe.execute()
实现计数器
5、发布订阅

发布者:服务器
订阅者:Dashboad和数据处理
Demo如下:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import redis
- class RedisHelper:
- def __init__(self):
- self.__conn = redis.Redis(host='10.211.55.4')
- self.chan_sub = 'fm104.5'
- self.chan_pub = 'fm104.5'
- def public(self, msg):
- self.__conn.publish(self.chan_pub, msg)
- return True
- def subscribe(self):
- pub = self.__conn.pubsub()
- pub.subscribe(self.chan_sub)
- pub.parse_response()
- return pub
RedisHelper
订阅者:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- from monitor.RedisHelper import RedisHelper
- obj = RedisHelper()
- redis_sub = obj.subscribe()
- while True:
- msg= redis_sub.parse_response()
- print msg
发布者:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- from monitor.RedisHelper import RedisHelper
- obj = RedisHelper()
- obj.public('hello')
6. sentinel
redis重的sentinel主要用于在redis主从复制中,如果master顾上,则自动将slave替换成master
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- from redis.sentinel import Sentinel
- # 连接哨兵服务器(主机名也可以用域名)
- sentinel = Sentinel([('10.211.55.20', 26379),
- ('10.211.55.20', 26380),
- ],
- socket_timeout=0.5)
- # # 获取主服务器地址
- # master = sentinel.discover_master('mymaster')
- # print(master)
- #
- # # # 获取从服务器地址
- # slave = sentinel.discover_slaves('mymaster')
- # print(slave)
- #
- #
- # # # 获取主服务器进行写入
- # master = sentinel.master_for('mymaster')
- # master.set('foo', 'bar')
- # # # # 获取从服务器进行读取(默认是round-roubin)
- # slave = sentinel.slave_for('mymaster', password='redis_auth_pass')
- # r_ret = slave.get('foo')
- # print(r_ret)
更多参见:https://github.com/andymccurdy/redis-py/
http://doc.redisfans.com/
16. 线程池重点讲解
17. 上下文管理
18. redis知识拾遗之发布订阅
第十章.rabbitMQ、MySQL 、SQLAlchemy和Paramiko的基本使用
1. 初识rabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
RabbitMQ安装
- 安装配置epel源
- $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
- 安装erlang
- $ yum -y install erlang
- 安装RabbitMQ
- $ yum -y install rabbitmq-server
注意:service rabbitmq-server start/stop
安装API
- pip install pika
- or
- easy_install pika
- or
- 源码
- https://pypi.python.org/pypi/pika
使用API操作RabbitMQ
基于Queue实现生产者消费者模型
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import Queue
- import threading
- message = Queue.Queue(10)
- def producer(i):
- while True:
- message.put(i)
- def consumer(i):
- while True:
- msg = message.get()
- for i in range(12):
- t = threading.Thread(target=producer, args=(i,))
- t.start()
- for i in range(10):
- t = threading.Thread(target=consumer, args=(i,))
- t.start()
2. rabbitMQ的使用
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
- #!/usr/bin/env python
- import pika
- # ######################### 生产者 #########################
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.queue_declare(queue='hello')
- channel.basic_publish(exchange='',
- routing_key='hello',
- body='Hello World!')
- print(" [x] Sent 'Hello World!'")
- connection.close()
- # ########################## 消费者 ##########################
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.queue_declare(queue='hello')
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % body)
- channel.basic_consume(callback,
- queue='hello',
- no_ack=True)
- print(' [*] Waiting for messages. To exit press CTRL+C')
- channel.start_consuming()
1、acknowledgment 消息不丢失
no-ack = False,如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
- import pika
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='10.211.55.4'))
- channel = connection.channel()
- channel.queue_declare(queue='hello')
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % body)
- import time
- time.sleep(10)
- print 'ok'
- ch.basic_ack(delivery_tag = method.delivery_tag)
- channel.basic_consume(callback,
- queue='hello',
- no_ack=False)
- print(' [*] Waiting for messages. To exit press CTRL+C')
- channel.start_consuming()
- 消费者
消费者
2、durable 消息不丢失
- #!/usr/bin/env python
- import pika
- connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
- channel = connection.channel()
- # make message persistent
- channel.queue_declare(queue='hello', durable=True)
- channel.basic_publish(exchange='',
- routing_key='hello',
- body='Hello World!',
- properties=pika.BasicProperties(
- delivery_mode=2, # make message persistent
- ))
- print(" [x] Sent 'Hello World!'")
- connection.close()
- 生产者
生产者
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import pika
- connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
- channel = connection.channel()
- # make message persistent
- channel.queue_declare(queue='hello', durable=True)
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % body)
- import time
- time.sleep(10)
- print 'ok'
- ch.basic_ack(delivery_tag = method.delivery_tag)
- channel.basic_consume(callback,
- queue='hello',
- no_ack=False)
- print(' [*] Waiting for messages. To exit press CTRL+C')
- channel.start_consuming()
- 消费者
消费者
3、消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- import pika
- connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
- channel = connection.channel()
- # make message persistent
- channel.queue_declare(queue='hello')
- def callback(ch, method, properties, body):
- print(" [x] Received %r" % body)
- import time
- time.sleep(10)
- print 'ok'
- ch.basic_ack(delivery_tag = method.delivery_tag)
- channel.basic_qos(prefetch_count=1)
- channel.basic_consume(callback,
- queue='hello',
- no_ack=False)
- print(' [*] Waiting for messages. To exit press CTRL+C')
- channel.start_consuming()
- 消费者
消费者
4、发布订阅

发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
- #!/usr/bin/env python
- import pika
- import sys
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='logs',
- type='fanout')
- message = ' '.join(sys.argv[1:]) or "info: Hello World!"
- channel.basic_publish(exchange='logs',
- routing_key='',
- body=message)
- print(" [x] Sent %r" % message)
- connection.close()
- 发布者
发布者
- #!/usr/bin/env python
- import pika
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='logs',
- type='fanout')
- result = channel.queue_declare(exclusive=True)
- queue_name = result.method.queue
- channel.queue_bind(exchange='logs',
- queue=queue_name)
- print(' [*] Waiting for logs. To exit press CTRL+C')
- def callback(ch, method, properties, body):
- print(" [x] %r" % body)
- channel.basic_consume(callback,
- queue=queue_name,
- no_ack=True)
- channel.start_consuming()
- 订阅者
订阅者
5、关键字发送

exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
- #!/usr/bin/env python
- import pika
- import sys
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='direct_logs',
- type='direct')
- result = channel.queue_declare(exclusive=True)
- queue_name = result.method.queue
- severities = sys.argv[1:]
- if not severities:
- sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
- sys.exit(1)
- for severity in severities:
- channel.queue_bind(exchange='direct_logs',
- queue=queue_name,
- routing_key=severity)
- print(' [*] Waiting for logs. To exit press CTRL+C')
- def callback(ch, method, properties, body):
- print(" [x] %r:%r" % (method.routing_key, body))
- channel.basic_consume(callback,
- queue=queue_name,
- no_ack=True)
- channel.start_consuming()
- 消费者
消费者
- #!/usr/bin/env python
- import pika
- import sys
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='direct_logs',
- type='direct')
- severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
- message = ' '.join(sys.argv[2:]) or 'Hello World!'
- channel.basic_publish(exchange='direct_logs',
- routing_key=severity,
- body=message)
- print(" [x] Sent %r:%r" % (severity, message))
- connection.close()
- 生产者
生产者
6、模糊匹配

exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
- 发送者路由值 队列中
- old.boy.python old.* -- 不匹配
- old.boy.python old.# -- 匹配
- #!/usr/bin/env python
- import pika
- import sys
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='topic_logs',
- type='topic')
- result = channel.queue_declare(exclusive=True)
- queue_name = result.method.queue
- binding_keys = sys.argv[1:]
- if not binding_keys:
- sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
- sys.exit(1)
- for binding_key in binding_keys:
- channel.queue_bind(exchange='topic_logs',
- queue=queue_name,
- routing_key=binding_key)
- print(' [*] Waiting for logs. To exit press CTRL+C')
- def callback(ch, method, properties, body):
- print(" [x] %r:%r" % (method.routing_key, body))
- channel.basic_consume(callback,
- queue=queue_name,
- no_ack=True)
- channel.start_consuming()
- 消费者
消费者
- #!/usr/bin/env python
- import pika
- import sys
- connection = pika.BlockingConnection(pika.ConnectionParameters(
- host='localhost'))
- channel = connection.channel()
- channel.exchange_declare(exchange='topic_logs',
- type='topic')
- routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
- message = ' '.join(sys.argv[2:]) or 'Hello World!'
- channel.basic_publish(exchange='topic_logs',
- routing_key=routing_key,
- body=message)
- print(" [x] Sent %r:%r" % (routing_key, message))
- connection.close()
- 生产者
生产者
注意:
- sudo rabbitmqctl add_user alex 123
- # 设置用户为administrator角色
- sudo rabbitmqctl set_user_tags alex administrator
- # 设置权限
- sudo rabbitmqctl set_permissions -p "/" alex '.''.''.'
- # 然后重启rabbiMQ服务
- sudo /etc/init.d/rabbitmq-server restart
- # 然后可以使用刚才的用户远程连接rabbitmq server了。
- ------------------------------
- credentials = pika.PlainCredentials("alex","")
- connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.14.47',credentials=credentials))
3. MySQL介绍
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
想要使用MySQL来存储并操作数据,则需要做几件事情:
a. 安装MySQL服务端
b. 安装MySQL客户端
b. 【客户端】连接【服务端】
c. 【客户端】发送命令给【服务端MySQL】服务的接受命令并执行相应操作(增删改查等)
- 下载
- http://dev.mysql.com/downloads/mysql/
- 安装
- windows:
- 点点点
- Linux:
- yum install mysql-server
- Mac:
- 点点点
Window版本
1、下载
- MySQL Community Server 5.7.16
- http://dev.mysql.com/downloads/mysql/
2、解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64
3、初始化
MySQL解压后的 bin 目录下有一大堆的可执行文件,执行如下命令初始化数据:
- cd c:\mysql-5.7.16-winx64\bin
- mysqld --initialize-insecure
4、启动MySQL服务
执行命令从而启动MySQL服务
- # 进入可执行文件目录
- cd c:\mysql-5.7.16-winx64\bin
- # 启动MySQL服务
- mysqld
5、启动MySQL客户端并连接MySQL服务
由于初始化时使用的【mysqld --initialize-insecure】命令,其默认未给root账户设置密码
- # 进入可执行文件目录
- cd c:\mysql-5.7.16-winx64\bin
- # 连接MySQL服务器
- mysql -u root -p
- # 提示请输入密码,直接回车
输入回车,见下图表示安装成功:

到此为止,MySQL服务端已经安装成功并且客户端已经可以连接上,以后再操作MySQL时,只需要重复上述4、5步骤即可。但是,在4、5步骤中重复的进入可执行文件目录比较繁琐,如想日后操作简便,可以做如下操作。
|
a. 添加环境变量 将MySQL可执行文件添加到环境变量中,从而执行执行命令即可
如此一来,以后再启动服务并连接时,仅需:
b. 将MySQL服务制作成windows服务 上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题:
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
|
Linux版本
安装:
- yum install mysql-server
服务端启动
- mysql.server start
客户端连接
- 连接:
- mysql -h host -u user -p
- 常见错误:
- ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2), it means that the MySQL server daemon (Unix) or service (Windows) is not running.
- 退出:
- QUIT 或者 Control+D
4. MySQL数据库及表操作
1、显示数据库
- SHOW DATABASES;
默认数据库:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据
2、创建数据库
- # utf-8
- CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
- # gbk
- CREATE DATABASE 数据库名称 DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
3、使用数据库
- USE db_name;
显示当前使用的数据库中所有表:SHOW TABLES;
4、用户管理
- 创建用户
- create user '用户名'@'IP地址' identified by '密码';
- 删除用户
- drop user '用户名'@'IP地址';
- 修改用户
- rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';;
- 修改密码
- set password for '用户名'@'IP地址' = Password('新密码')
- PS:用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作(不建议)
5、授权管理
- show grants for '用户'@'IP地址' -- 查看权限
- grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权
- revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限
- all privileges 除grant外的所有权限
- select 仅查权限
- select,insert 查和插入权限
- ...
- usage 无访问权限
- alter 使用alter table
- alter routine 使用alter procedure和drop procedure
- create 使用create table
- create routine 使用create procedure
- create temporary tables 使用create temporary tables
- create user 使用create user、drop user、rename user和revoke all privileges
- create view 使用create view
- delete 使用delete
- drop 使用drop table
- execute 使用call和存储过程
- file 使用select into outfile 和 load data infile
- grant option 使用grant 和 revoke
- index 使用index
- insert 使用insert
- lock tables 使用lock table
- process 使用show full processlist
- select 使用select
- show databases 使用show databases
- show view 使用show view
- update 使用update
- reload 使用flush
- shutdown 使用mysqladmin shutdown(关闭MySQL)
- super
四. python网络编程的更多相关文章
Python 网络编程 上一篇博客介绍了socket的基本概念以及实现了简单的TCP和UDP的客户端.服务器程序,本篇博客主要对socket编程进行更深入的讲解 一.简化版ssh实现 这是一个极其简单 ...
python网络编程——IO多路复用之epoll 1.内核EPOLL模型讲解 此部分参考http://blog.csdn.net/mango_song/article/details/4264 ...
python网络编程基础(线程与进程.并行与并发.同步与异步.阻塞与非阻塞.CPU密集型与IO密集型) 目录 线程与进程 并行与并发 同步与异步 阻塞与非阻塞 CPU密集型与IO密集型 线程与进程 进 ...
1 IO多路复用的概念 原生socket客户端在与服务端建立连接时,即服务端调用accept方法时是阻塞的,同时服务端和客户端在收发数据(调用recv.send.sendall)时也是阻塞的.原生so ...
一.基于TCP协议的socket套接字编程 1.套接字工作流程 先从服务器端说起.服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客 ...
在学习socket之前,我们先复习下相关的网络知识. OSI七层模型:应用层,表示层,会话层,传输层,网络层,数据链路层,物理层.OSI七层模型是由国际标准化组织ISO定义的网络的基本结构,不仅包括一 ...
python网络编程01 /C/S架构|B/S架构.网络通信原理.五层协议.七层协议简述.端口映射技术 目录 python网络编程01 /C/S架构|B/S架构.网络通信原理.五层协议.七层协议简述. ...
Python网络编程之网络基础 目录 Python网络编程之网络基础 1. 计算机网络发展 1.1. OSI七层模型 1.2. 七层模型传输数据过程 2. TCP/IP协议栈 2.1 TCP/IP和O ...
Python 网络编程 socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. ...
随机推荐
题意: 现在 m个考生人需要坐在有n个座位的圆桌上. 你需要安排位置,使得任意两个考生之间相距至少k个位置. 桌子有编号,考生a和b交换位置视作一种方案,问有多少方案,mod 1e9+7. (0 &l ...
1247 排排站 USACO 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题解 题目描述 Description FJ的N头奶牛有一些共同 ...
目录:[Swift]Xcode实际操作 本文将演示MarkMan的使用. 在界面开发过程中,最终的效果和设计稿难免有些出入, 通常是颜色.位置.尺寸方面的偏差,使用MarkMan助你领会设计师的意图. ...
目录:[Swift]Xcode实际操作 本文将演示如何截取屏幕画面,并将截取图片,存入系统相册. 在项目导航区,打开视图控制器的代码文件[ViewController.swift] import UI ...
这是分布式集群环境下,如何实现session共享系列的第五篇.在上一篇:分布式集群环境下,如何实现session共享四(部署项目测试)中,针对nginx不同的负载均衡策略:轮询.ip_hash方式,测 ...
centos6需要修改两处:一处是/etc/sysconfig/network,另一处是/etc/hosts,只修改任一处会导致系统启动异常.首先切换到root用户. /etc/sysconfig/n ...
#include "cstdio" #include "math.h" #include "cstring" #define mod 100 ...
#include <iostream> #include <cstdio> #include <cstring> using namespace std; #def ...
本文参考博客:https://blog.csdn.net/u013473691/article/details/52353923 关于@Configuration和@Bean参考博客:https:// ...
某些应用程序资源是独占的,因为有且只有一个此类型的资源.例如,通过数据库句柄到数据库的连接是独占的.您希望在应用程序中共享数据库句柄,因为在保持连接打开或关闭时,它是一种开销,在获取单个页面的过程中更 ...