MySQL的索引知识
一、什么是索引。
索引是用来加速查询的技术的选择之一,在通常情况下,造成查询速度差异 的因素就是索引是否使用得当。当我们没有对数据表的某一字段段或者多个 字段添加索引时,实际上执行的全表扫描操作,效率很低。而如果我们为某 些字段添加索引,mysql在执行搜索时便可以通过扫描索引,然后再找出索 引对应的值,从而提高效率。
二、索引的类型
实际上索引的类型不多,以下只是针对个人以前遇到的索引概念的解释,有 可能某个索引有多种称呼,只是取决于你用哪个角度去描述它。
B树索引:采用B-trees数据结构存储索引,比如PRIMARY KEY,UNIQUE,INDEX。Hash索引:将一个散列函数应用于每一个列值,最终的散列值都会被存入索引,用于执行查找。R树索引:采用R-trees数据结构存储索引,比如Spatial index。(空间数据类型的索引)- 全文索引
(FULLTEXT INDEX):一般在CHAR,VARCHAR或者TEXT列上创建此索引。可用来代替like ‘%xx%’实现模糊查询。 - 前缀索引:只对一个列或者多个列的前几个字符或者字节索引。
- 唯一索引:只对一个列创建索引。
- 多列索引:对多个列创建索引。在多列索引中必须注意最左前缀这个原则。比如对于
(col1,col2,col3)这三列进行索引时,只有(col1),(col1,col2),(col1,col2,col3)才能进行索引搜索。
注意(col1,col3)也不能进行索引。 - 聚簇索引:每个
InnoDB表都有一个特殊的索引称为聚簇索引,一般来说,当为一个表定义一个PRIMAY KEY时,InnoDB就会使用它作为聚簇索引。如果没有定义PRIMARY KEY时,MySQL就会查找第一个非空的UNIQUE index作为聚簇索引。如果以上两种情况都不满足的话,InnoDB内部会在表的每一行产生一个隐藏的并且名为GEN_CLUST_INDEX的聚簇索引。这个聚簇索引是一个六个字节长度的行ID字段,ID值随着新行的插入而单调增长。实际上,除了聚簇索引,其他索引都称为二级索引。在InnoDB中,二级索引的每一行(将索引假设为行方便理解,实际上索引的存储方式取决于具体的存储引擎)中都包含着一个PRIMARY KEY列,InnoDB使用PRIMARY KEY这一列的列值在聚簇索引中查找相对应的数据(可以将聚簇 索引理解为中间值),从而最后得到最终的结果集。聚簇索引的数据分布如下图:(图来自《高性能MySQL》)
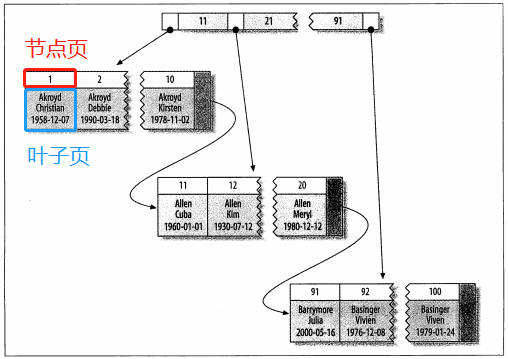
上图中,节点页存放是索引(对应着二级索引的PRIMARY KEY),叶子页存放着所对应的数据,节点页和叶子页这个整体就称为聚簇索引,由此可见,聚簇索引更像是一种数据存储结构。 - 覆盖索引:当查询的结果集可以通过所创建的索引查找出来时,这个索引就称为覆盖索引。
下面举个例子:

对于上面这个表,当执行下面的语句时,就会使用覆盖索引查询。

因为我们在创建表的时候对last_name、first_name创建了多列索引,并且在查询的时候只查询这两列的结果,因此MySQL会使用覆盖索引查询数据,这也意味着MySQL不会对实际的数据行进行查询,因为所需结果已经可以从索引中查找出来了。
另外可以看一下下面的SQL语句:
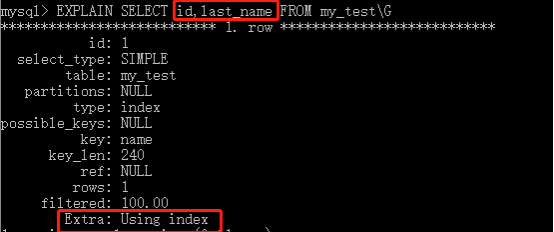
在上面的SQL语句中,我们想查询id和last_name的值,而id是主键,last_name是多列索引中的最左索引,但是此时的查询依旧使用覆盖索引查询。原因在于id实际是作为聚簇索引的,而多列索引自然就是二级索引了,上面提到,二级索引都包含着一列PRIMARY KEY列,而列值就是聚簇索引的索引值,因此此时MySQL可以直接使用覆盖索引中查找出对应的结果集。
三、B树索引和Hash索引的比较
InnoDB存储引擎和MyISAM存储引擎都只支持B树索引(实际上InnoDB还支持自适应的hash索引,只是不能人为创建),MEMORY存储引擎默认使用hash索引,但它也支持B树索引。- 在使用
<、<=、=、>=、>、<>、!=和BETWEEN运算符,进行精确比较或者范围比较时,使用B树索引会带来高效。如果匹配模式是以一个纯字符串,而不是一个通配符作为开头的,那么B树索引还可以用在使用like进行模式匹配的操作里。
下面举个例子:

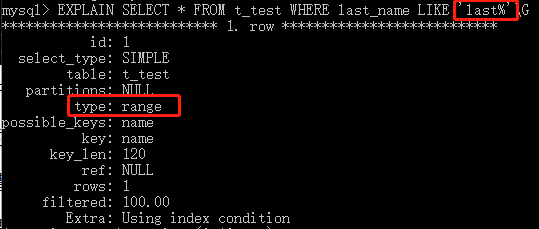
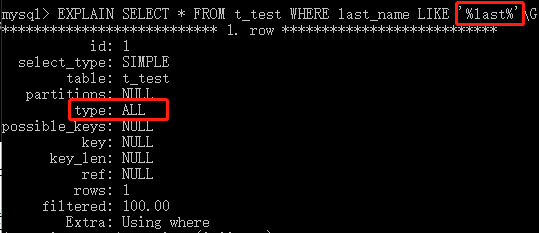
- 对于
hash索引,在使用运算符=或者<=>(安全等于的意思,当比较的值含有null值的时候,来返回一个布尔值)完成精确(这里说精确是因为hash索引是用一个hash函数对整个列值hash,而不是某几个字符或者字节)匹配的比较操作里,散列索引的速度非常快。

四、索引的挑选
- 一般对于出现在
WHERE子句中的列、连接子句中的列、或者出现在ORDER BY或GROUP BY子句中的列创建索引是比较好的。 - 尽量索引短小值。应尽量选用较小的数据类型。比如值的长度不超过
25个字符,那么就不要用CHAR(200),其他数据类型同理。特别是InnoDB表来说,因为它使用的是聚簇索引,如果主键过长的话,会导致二级索引占用的存储空间过大。 - 索引字符串值的前缀。当对字符串列进行索引时,应当尽可能指定前缀长度。比如某一个列的前N个字符足够唯一的话,那么就可以不用为整列进行索引。
五、索引的代价
索引确实可以加快检索速度,但是它同时也降低了索引列的插入、删除和更新值的速度,因为写入一个行不仅是写入一个数据行,还要更改索引。表的索引越多,需要做出的更改就越多,平均性能下降得也就越多。并且当所创建的索引过多时,mysql查询优化器在选择使用哪种索引方案时,也会降低一定的效率。其次,索引也会占用磁盘空间,多个索引会占据更大的空间。与没有索引相比,使用索引很快便达到表的大小极限。
六、创建索引
- 使用
CREATE TABLE创建索引(index_name可选)

- 使用ALTER TABLE为已有表创建索引(index_name可选)

- 使用CREATE INDEX创建索引(index_name不可省略)
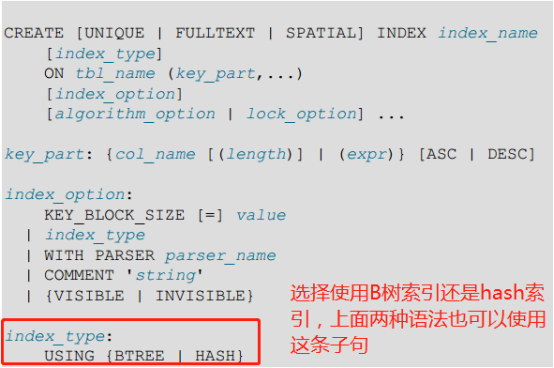
如果某个索引列在索引时使用了PRIMARY KEY或SPATIAL,则它必须为NOT NULL的。其他索引列允许包含NULL值。
如果想要限制某个索引,让它只包含唯一值,那么可以把这个索引创建为PRIMARY KEY或UNIQUE索引。 这两种索引很像,主要区别有一下两点: - 每个表只能包含一个
PRIMARY KEY。因为PRIMARY KEY的名字总是为PRIMARY,而同一个表不允许有两个同名的索引。可以在一个表里放置多个UNIQUE索引。 PRIMARY KEY不可以包含NULL值,而UNIQUE索引可以。如果某个UNIQUE索引包含了NULL值,那么它就可以包含多个NULL值。因为NULL值不会与任何值相等,包括它本身。
七、删除索引
最后,我们可以通过DROP INDEX或ALTER TABLE语句来删除索引
- 通过DROP INDEX删除索引

- 通过
DROP INDEX删除索引

八、[PRIMARY|UNIQUE]KEY与[UNIQUE]INDEX的关系
首先来看一下MySQL创建表的语句:(图来自《MySQL官方文档》,图太大所以省略了一部分)

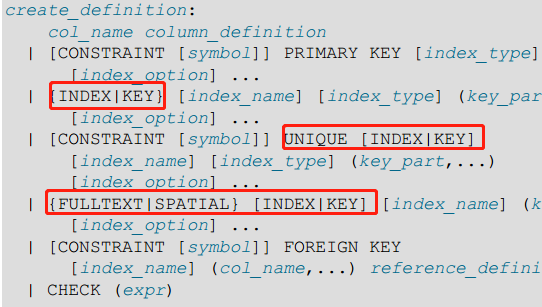
从上图可以看出,实际上INDEX和KEY是同义词,之所以同时存在主要是为了与其他数据库系统做兼容,另外还有以下两个结论。
PRIMARY KEY与UNIQUE[INDEX|KEY]很相似,具体区别可以查看上面的内容。INDEX和KEY允许出现相同的列值,但是UNIQUE[INDEX|KEY]不允许出现相同的列值。(记住NULL != NULL)
九、参考资料
- MySQL 8.0官方文档
- 《高性能MySQL》第三版
- 《MySQL技术内幕》第五版
- https://stackoverflow.com/questions/707874/differences-between-index-primary-unique-fulltext-in-mysql
MySQL的索引知识的更多相关文章
- MySQL索引知识学习笔记
目录 一.索引的概念 二.索引分类 三.索引用法 四 .索引架构简介 五.索引适用的情况 六.索引不适用的情况 继我的上篇博客:Oracle索引知识学习笔记,再记录一篇MySQL的索引知识学习笔记,本 ...
- MySQL中索引的基础知识
本文是关于MySQL中索引的基础知识.主要讲了索引的意义与原理.创建与删除的操作.并未涉及到索引的数据结构.高性能策略等. 一.概述 1.索引的意义:用于提高数据库检索数据的效率,提高数据库性能. 数 ...
- mysql索引知识简单记录
简介 今天记录下索引基础知识 1.mysql单表最多支持多少个索引,索引总长度为多少? 索引是在存储引擎中实现的,因此每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型. ...
- 数据库索引知识到MySQL InnoDB
前言 本文聊聊数据库中的索引,涉及索引基础数据结构,分类.以及使用索引的缺点. 索引就像一本书的目录,商场里面各个楼层指示图,让我们不需要自己无目的的找,而是能够很快的找到自己想要的. 1. 索引的基 ...
- MySQL 索引知识总结
将 mysql 的索引以书本的索引类比比较贴切,要找到一个关键字为xxx 的条目,首先翻到索引中查找有哪些页码涉及到,无疑就缩小了范围.在这个小范围内再寻找符合条件的数据,效率就会提高许多. mysq ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- 手把手教你mysql(十)索引
手把手教你mysql(十)索引 一:索引的引入 索引定义:索引是由数据库表中一列或者多列组合而成,其作用是提高对表中数据的查询速度. 类似于图书的目录,方便快速定位,寻找指定的内容,如一本1000页的 ...
- B+Tree原理及mysql的索引分析
一.索引的本质 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构.提取句子主干,就可以得到索引的本质:索引是数据结构. 我们知道,数据库查询是数据库的最主要功能之 ...
- MySQL学习----索引的使用
一.什么是索引?为什么要建立索引? 索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的 ...
随机推荐
- APP为什么会被打回来??
APP的设置界面, 按钮使用了类似iPhone的操作方式以及icon的圆角设计 -> 重新设计 APP的年龄设置太低 -> 改年龄 APP里有实物奖励 -> 免责声明, ...
- 用C#编写计算器
零有点问题,而且目前只能做一些简单的运算,+.-.*./.平方.开根号 希望有大佬指正我的错误 感谢 using System;using System.Collections.Generic;usi ...
- 初学Java web(转)
转自 http://www.oschina.net/question/12_52027 OSCHINA 软件库有一个分类——Web框架,该分类中包含多种编程语言的将近500个项目. Web框架是开发者 ...
- C - Brackets
#include <iostream> #include <algorithm> #include <cstring> #include <cstdio> ...
- [题解](gcd/lcm)luogu_P1072_Hankson的趣味题(NOIP2009)
连续三次不开longlong导致wa!!! 不开longlong一时爽,一会提交火葬场!!! OI千万条,longlong第一条 乘法不longlong,提交两行泪 暴力luogu就能过了???打好暴 ...
- 深度学习环境搭建(Ubuntu16.04+GTX1080Ti+CUDA8.0+Cudnn6.0+TensorFlow+Caffe2(Pytorch))
OS System:Ubuntu16.04 GPU Device:GTX1080Ti Softwares:CUDA8.0.Cudnn6.0.TensorFlow(1.4.0).Caffe2(1.0.0 ...
- css未知宽度水平居中整理
1.text-align 兼容性很好 .wp {text-align: center;} .test {display: inline;} <ul class="wp"> ...
- B. Apple Tree 暴力 + 数学
http://codeforces.com/problemset/problem/348/B 注意到如果顶点的数值确定了,那么它分下去的个数也就确定了,那么可以暴力枚举顶点的数值. 顶点的数值是和LC ...
- python转换已转义的字符串
python转换已转义的字符串 有时我们可能会获取得以下这样的字符串: >>> a = '{\\"name\\":\\"michael\\"} ...
- session 跟 cookie 关系
面试经验: 谈到Session的时候就侃Session和Cookie的关系:Cookie中的SessionId. 和别人对比说自己懂这个原理而给工作带来的方便之处. 客户第一次发送请求给服务器,此 ...