JVM(一)虚拟机内存划分
Java内存区域
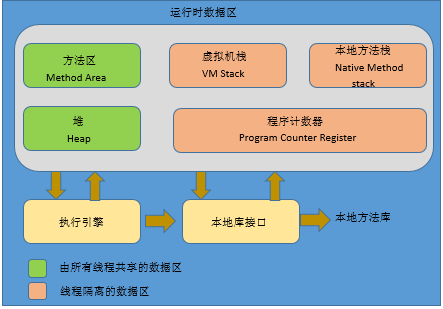
线程私有数据区域:虚拟机栈,本地方法栈,程序计数器
线程共享数据区域:方法区,堆
程序计数器:当前线程所执行的字节码的行号指示器,JVM通过这个字节码解释器改变计数器的值,以选择下一条需要执行的字节指令码。分支,循环,跳转,异常处理,线程恢复等操作都依赖顺序计数器来完成(JVM执行指令的逻辑控制器)。
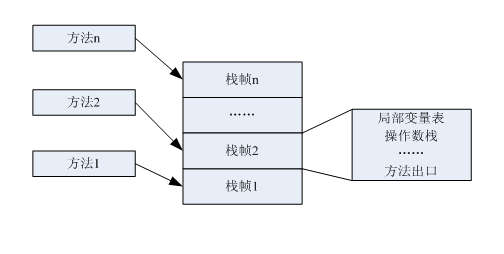
虚拟机栈:虚拟机栈是线程独立的,也就是说每个线程有自己私有的虚拟机栈,它的生命周期是与线程同步。虚拟机栈是Java方法执行的内存模型, 线程的每个方法在执行的同时都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法的调用到执行结束,就对应着一个栈帧入栈出栈的过程。栈帧的入栈出栈规则为先进后出,后进先出。
本地方法栈:与虚拟机栈类似,本地方法栈为虚拟机使用到的Native方法服务。HotSpot虚拟机把本地方法栈与虚拟机栈合二为一。
方法区:方法区为线程共享区域,它用于存储已被虚拟机加载的类信息,常量,静态变量,即编译器编译后的代码数据。Java虚拟机规范把方法区描述为堆的一部分,但是他有个名字叫做Non-Heap(非堆)。HotSpHot虚拟机也把他叫做永久代-Permanent Generation。因为HotSpot虚拟机把GC扩展到了方法区,或者说使用永久代实现方法区,这样HotSpot的垃圾收集器就可以像管理Java堆内存一样管理这部分内存。
运行常量池:为方法区的一部分,class文件除了有类的版本,字段,方法,接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分在类被加载后进入方法区的运行时常量池中存放。
堆:Java堆是线程共享数据区,用于存放对象实例,几乎所有的对象都是在堆上分配。此部分是虚拟机管理的最大一块内存,在虚拟机启动时被创建。垃圾收集器主要是管理堆这部分区域。
以下摘自:http://blog.csdn.net/xyw591238/article/details/51888273
(1)内存分配的策略
按照编译原理的观点,程序运行时的内存分配有三种策略,分别是静态的,栈式的,和堆式的.
静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编 译时就可以给他们分配固定的内存空间.这种分配策略要求程序代码中不允许有可变数据结构(比如可变数组)的存在,也不允许有嵌套或者递归的结构出现,因为 它们都会导致编译程序无法计算准确的存储空间需求.(方法区)
栈式存储分配也可称为动态存储分配,是由一个类似于堆栈的运行栈来实现的.和静态存 储分配相反,在栈式存储方案中,程序对数据区的需求在编译时是完全未知的,只有到运行的时候才能够知道,但是规定在运行中进入一个程序模块时,必须知道该 程序模块所需的数据区大小才能够为其分配内存.和我们在数据结构所熟知的栈一样,栈式存储分配按照先进后出的原则进行分配。
静态存储分配要求在编译时能知道所有变量的存储要求,栈式存储分配要求在过程的入口 处必须知道所有的存储要求,而堆式存储分配则专门负责在编译时或运行时模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例.堆 由大片的可利用块或空闲块组成,堆中的内存可以按照任意顺序分配和释放.
(2)JVM中的堆和栈
JVM是基于堆栈的虚拟机.JVM为每个新创建的线程都分配一个堆栈.也就是说,对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。堆栈以帧为单位保存线程的状态。JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作。
我们知道,某个线程正在执行的方法称为此线程的当前方法.我们可能不知道,当前方法使用的帧称为当前帧。当线程激活一个Java方法,JVM就会在线程的 Java堆栈里新压入一个帧。这个帧自然成为了当前帧.在此方法执行期间,这个帧将用来保存参数,局部变量,中间计算过程和其他数据.这个帧在这里和编译 原理中的活动纪录的概念是差不多的.
从Java的这种分配机制来看,堆栈又可以这样理解:堆栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的线程 共享.跟C/C++不同,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也 就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
tatic、final修饰符、内部类和Java内存分配
static修饰符
static修饰符能够与属性、方法和内部类一起使用,表示静态的。类中的静态变量和静态方法能够与类名一起使用,不需要创建一个类的对象来访问该类的静态成员,所以,static修饰的变量又称作“类变量”。
static属性的内存分配
一个类中,一个static变量只会有一个内存空间,虽然有多个类实例,但这些类实例中的这个static变量会共享同一个内存空间。
static的变量是在类装载的时候就会被初始化,即,只要类被装载,不管是否使用了static变量,都会被初始化。
static的基本规则
·一个类的静态方法只能访问静态属性
·一个类的静态方法不能直接调用非静态方法
·如访问控制权限允许,static属性和方法可以使用类名加“.”的方式调用,也可以使用实例加“.”的方式调用
·静态方法中不存在当前对象,因而不能使用this,也不能使用super
·静态方法不能被非静态方法覆盖
·构造方法不允许声明为static的
注,非静态变量只限于实例,并只能通过实例引用被访问。
静态初始器——静态块
静态初始器是一个存在与类中方法外面的静态块,仅仅在类装载的时候执行一次,通常用来初始化静态的类属性。
final修饰符
在Java声明类、属性和方法时,可以使用关键字final来修饰,final所标记的成分具有终态的特征,表示最终的意思。
final的具体规则
·final标记的类不能被继承
·final标记的方法不能被子类重写
·final标记的变量(成员变量或局部变量)即成为常量,只能赋值一次
·final标记的成员变量必须在声明的同时赋值,如果在声明的时候没有赋值,那么只有一次赋值的机会,而且只能在构造方法中显式赋值,然后才能使用
·final标记的局部变量可以只声明不赋值,然后再进行一次性的赋值
·final一般用于标记那些通用性的功能、实现方式或取值不能随意被改变的成分,以避免被误用
如果将引用类型(即,任何类的类型)的变量标记为final,那么,该变量不能指向任何其它对象,但可以改变对象的内容,因为只有引用本身是final的。
内部类
在一个类(或方法、语句块)的内部定义另一个类,后者称为内部类,有时也称为嵌套类。
内部类的特点
·内部类可以体现逻辑上的从属关系,同时对于其它类可以控制内部类对外不可见等
·外部类的成员变量作用域是整个外部类,包括内部类,但外部类不能访问内部类的private成员
·逻辑上相关的类可以在一起,可以有效地实现信息隐藏
·内部类可以直接访问外部类的成员,可以用此实现多继承
·编译后,内部类也被编译为单独的类,名称为outclass$inclass的形式
内部类可以分为四种
·类级:成员式,有static修饰
·对象级:成员式,普通,无static修饰
·本地内部类:局部式
·匿名级:局部式
成员式内部类的基本规则
·可以有各种修饰符,可以用4种权限、static、final、abstract定义
·若有static限定,就为类级,否则为对象级。类级可以通过外部类直接访问,对象级需要先生成外部的对象后才能访问
·内外部类不能同名
·非静态内部类中不能声明任何static成员
·内部类可以互相调用
成员式内部类的访问
内部类访问外层类对象的成员时,语法为:
外层类名.this.属性
使用内部类时,由外部类对象加“.new”操作符调用内部类的构造方法,创建内部类的对象。
在另一个外部类中使用非静态内部类中定义的方法时,要先创建外部类的对象,再创建与外部类相关的内部类的对象,再调用内部类的方法。
static内部类相当于其外部类的static成分,它的对象与外部类对象间不存在依赖关系,因此可以直接创建。
由于内部类可以直接访问其外部类的成分,因此,当内部类与其外部类中存在同名属性或方法时,也将导致命名冲突。所以,在多层调用时要指明。
本地类是定义在代码块中的类,只在定义它们的代码块中可见。
本地类有以下几个重要特性:
·仅在定义了它们的代码块中可见
·可以使用定义它们的代码块中的任何本地final变量(注:本地类(也可以是局部内部类/匿名内部类等等)使用外部类的变量,原意是希 望这个变量在本地类中的对象和在外部类中的这个变量对象是一致的,但如果这个变量不是final定义,它有可能在外部被修改,从而导致内外部类的变量对象 状态不一致,因此,这类变量必须在外部类中加final前缀定义)
·本地类不可以是static的,里边也不能定义static成员
·本地类不可以用public、private、protected修饰,只能使用缺省的
·本地类可以是abstract的
匿名内部类是本地内部类的一种特殊形式,即,没有类名的内部类,而且具体的类实现会写在这个内部类里。
匿名类的规则
·匿名类没有构造方法
·匿名类不能定义静态的成员
·匿名类不能用4种权限、static、final、abstract修饰
·只可以创建一个匿名类实例
Java的内存分配
Java程序运行时的内存结构分成:方法区、栈内存、堆内存、本地方法栈几种。
方法区存放装载的类数据信息,包括:
·基本信息:每个类的全限定名、每个类的直接超类的全限定名、该类是类还是接口、该类型的访问修饰符、直接超接口的全限定名的有序列表。
·每个已装载类的详细信息:运行时常量池、字段信息、方法信息、静态变量、到类classloader的引用、到类class的引用。
栈内存
Java栈内存由局部变量区、操作数栈、帧数据区组成,以帧的形式存放本地方法的调用状态(包括方法调用的参数、局部变量、中间结果……)。
堆内存
堆内存用来存放由new创建的对象和数组。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
本地方法栈内存
Java通过Java本地接口JNI(JavaNative Interface)来调用其它语言编写的程序,在Java里面用native修饰符来描述一个方法是本地方法。
String的内存分配
String是一个特殊的包装类数据,由于String类的值不可变性,当String变量需要经常变换其值时,应该考虑使用StringBuffer或StringBuilder类,以提高程序效率。
Java内存分配、管理小结
转自: http://legend26.blog.163.com/blog/static/13659026020101122103954365/
首先是概念层面的几个问题:
- Java中运行时内存结构有哪几种?
- Java中为什么要设计堆栈分离?
- Java多线程中是如何实现数据共享的?
- Java反射的基础是什么?
然后是运用层面:
- 引用类型变量和对象的区别?
- 什么情况下用局部变量,什么情况下用成员变量?
数组如何初始化?声明一个数组的过程中,如何分配内存? - 声明基本类型数组和声明引用类型的数组,初始化时,内存分配机制有什么区?
- 在什么情况下,我们的方法设计为静态化,为什么
Java中运行时内存结构
1.1 方法区:
方法区是系统分配的一个内存逻辑区域,是JVM在装载类文件时,用于存储类型信息的(类的描述信息)。
方法区存放的信息包括:
1.1.1类的基本信息:
- 每个类的全限定名
- 每个类的直接超类的全限定名(可约束类型转换)
- 该类是类还是接口
- 该类型的访问修饰符
- 直接超接口的全限定名的有序列表
1.1.2已装载类的详细信息:
运行时常量池:
在方法区中,每个类型都对应一个常量池,存放该类型所用到的所有常量,常量池中存储了诸如文字字符串、final变量值、类名和方法名常量。它们以数组形式通过索引被访问,是外部调用与类联系及类型对象化的桥梁。(存的可能是个普通的字符串,然后经过常量池解析,则变成指向某个类的引用)
- 字段信息:
字段信息存放类中声明的每一个字段的信息,包括字段的名、类型、修饰符。
字段名称指的是类或接口的实例变量或类变量,字段的描述符是一个指示字段的类型的字符串,如private A a=null;则a为字段名,A为描述符,private为修饰符
- 方法信息:
类中声明的每一个方法的信息,包括方法名、返回值类型、参数类型、修饰符、异常、方法的字节码。
(在编译的时候,就已经将方法的局部变量、操作数栈大小等确定并存放在字节码中,在装载的时候,随着类一起装入方法区。)
| 在运行时,JVM从常量池中获得符号引用,然后在运行时解析成引用项的实际地址,最后通过常量池中的全限定名、方法和字段描述符,把当前类或接口中的代码与其它类或接口中的代码联系起来。 |
- 静态变量:
这个没什么好说的,就是类变量,类的所有实例都共享,我们只需知道,在方法区有个静态区,静态区专门存放静态变量和静态块。
- 到类classloader的引用:到该类的类装载器的引用。
- 到类class的引用:虚拟机为每一个被装载的类型创建一个class实例,用来代表这个被装载的类。
由此我们可以知道反射的基础:
| 在装载类的时候,加入方法区中的所有信息,最后都会形成Class类的实例,代表这个被装载的类。方法区中的所有的信息,都是可以通过这个Class类对象反射得到。我们知道对象是类的实例,类是相同结构的对象的一种抽象。同类的各个对象之间,其实是拥有相同的结构(属性),拥有相同的功能(方法),各个对象的区别只在于属性值的不同。 同样的,我们所有的类,其实都是Class类的实例,他们都拥有相同的结构-----Field数组、Method数组。而各个类中的属性都是Field属性的一个具体属性值,方法都是Method属性的一个具体属性值。 |
在运行时,JVM从常量池中获得符号引用,然后在运行时解析成引用项的实际地址,最后通过常量池中的全限定名、方法和字段描述符,把当前类或接口中的代码与其它类或接口中的代码联系起来。
1.2 Java栈
JVM栈是程序运行时单位,决定了程序如何执行,或者说数据如何处理。
在Java中,一个线程就会有一个线程的JVM栈与之对应,因为不过的线程执行逻辑显然不同,因此都需要一个独立的JVM栈来存放该线程的执行逻辑。
对方法的调用:
Java栈内存,以帧的形式存放本地方法的调用状态,包括方法调用的参数、局部变量、中间结果等(方法都是以方法帧的形式存放在方法区的),每调用一个方法就将对应该方法的方法帧压入Java栈,成为当前方法帧。当调用结束(返回)时,就弹出该帧。
这意味着:
在方法中定义的一些基本类型的变量和引用变量都在方法的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后(方法执行完成后),Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作它用。--------同时,因为变量被释放,该变量对应的对象,也就失去了引用,也就变成了可以被gc对象回收的垃圾。
因此我们可以知道成员变量与局部变量的区别:
| 局部变量,在方法内部声明,当该方法运行完时,内存即被释放。 成员变量,只要该对象还在,哪怕某一个方法运行完了,还是存在。 从系统的角度来说,声明局部变量有利于内存空间的更高效利用(方法运行完即回收)。 成员变量可用于各个方法间进行数据共享。 |
Java 栈内存的组成:
局部变量区、操作数栈、帧数据区组成。
(1):局部变量区为一个以字为单位的数组,每个数组元素对应一个局部变量的 值。调用方法时,将方法的局部变量组成一个数组,通过索引来访问。若为非静态方法,则加入一个隐含的引用参数this,该参数指向调用这个方法的对象。而 静态方法则没有this参数。因此,对象无法调用静态方法。
由此,我们可以知道,方法什么时候设计为静态,什么时候为非静态?
| 前面已经说过,对象是类的一个实例,各个对象结构相同,只是属性不同。 而静态方法是对象无法调用的。 所以,静态方法适合那些工具类中的工具方法,这些类只是用来实现一些功能,也不需要产生对象,通过设置对象的属性来得到各个不同的个体。 |
(2):操作数栈也是一个数组,但是通过栈操作来访问。所谓操作数是那些被指令操作的数据。当需要对参数操作时如a=b+c,就将即将被操作的参数压栈,如将b 和c 压栈,然后由操作指令将它们弹出,并执行操作。虚拟机将操作数栈作为工作区。
(3):帧数据区处理常量池解析,异常处理等
1.3 java堆
java的堆是一个运行时的数据区,用来存储数据的单元,存放通过new关键字新建的对象和数组,对象从中分配内存。
在堆中声明的对象,是不能直接访问的,必须通过在栈中声明的指向该引用的变量来调用。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
由此我们可以知道,引用类型变量和对象的区别:
|
声明的对象是在堆内存中初始化的, 真正用来存储数据的。不能直接访问。 引用类型变量是保存在栈当中的,一个用来引用堆中对象的符号而已(指针)。 |
堆与栈的比较:
JAVA堆与栈都是用来存放数据的,那么他们之间到底有什么差异呢?既然栈也能存放数据,为什么还要设计堆呢?
1.从存放数据的角度:
前面我们已经说明:
栈中存放的是基本类型的变量or引用类型的变量
堆中存放的是对象or数组对象.
在栈中,引用变量的大小为32位,基本类型为1-8个字节。
但是对象的大小和数组的大小是动态的,这也决定了堆中数据的动态性,因为它是在运行时动态分配内存的,生存期也不必在编译时确定,Java 的垃圾收集器会自动收走这些不再使用的数据。
2.从数据共享的角度:
1).在单个线程类,栈中的数据可共享
例如我们定义:
- int a=3;
- int b=3;
int a=3; int b=3;
编 译器先处理int a = 3;首先它会在栈中创建一个变量为a 的引用,然后查找栈中是否有3 这个值,如果没找到,就将3 存放进来,然后将a 指向3。接着处理int b = 3;在创建完b 的引用变量后,因为在栈中已经有3这个值,便将b 直接指向3。这样,就出现了a 与b 同时均指向3的情况。
而如果我们定义:
- Integer a=new Integer(3);//(1)
- Integer b=new Integer(3);//(2)
Integer a=new Integer(3);//(1) Integer b=new Integer(3);//(2)
这个时候执行过程为:在执行(1)时,首先在栈中创建一个变量a,然后在堆内存中实例化一个对象,并且将变量a指向这个实例化的对象。在执行(2)时,过程类似,此时,在堆内存中,会有两个Integer类型的对象。
2).在进程的各个线程之间,数据的共享通过堆来实现
例:那么,在多线程开发中,我们的数据共享又是怎么实现的呢?
如图所示,堆中的数据是所有线程栈所共享的,我们可以通过参数传递,将一个堆中的数据传入各个栈的工作内存中,从而实现多个线程间的数据共享
(多个进程间的数据共享则需要通过网络传输了。)
3.从程序设计的的角度:
从软件设计的角度看,JVM栈代表了处理逻辑,而JVM堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
4.值传递和引用传递的真相
有了以上关于栈和堆的种种了解后,我们很容易就可以知道值传递和引用传递的真相:
|
1.程序运行永远都是在JVM栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。 但是传引用的错觉是如何造成的呢? 在运行JVM栈中,基本类型和引用的处理是一样的,都是传值,所以,如果是传引用的方法调用,也同时可以理解为“传引用值”的传值调用,即引用的处理跟基本类型是完全一样的。 但是当进入被调用方法时,被传递的这个引用的值,被程序解释(或者查找)到JVM堆中的对象,这个时候才对应到真正的对象。 如果此时进行修改,修改的是引用对应的对象,而不是引用本身,即:修改的是JVM堆中的数据。所以这个修改是可以保持的了。 |
最后:
从某种意义上来说对象都是由基本类型组成的。
| 可以把一个对象看作为一棵树,对象的属性如果还是对象,则还是一颗树(即非叶子节点),基本类型则为树的叶子节点。程序参数传递时,被传递的值本身都是不能进行修改的,但是,如果这个值是一个非叶子节点(即一个对象引用),则可以修改这个节点下面的所有内容。 |
其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。
面向对象的引入,只是改变了我们对待问题的思考方式,而更接近于自然方式的思考。
当我们把对象拆开,其实对象的属性就是数据,存放在JVM堆中;而对象的行为(方法),就是运行逻辑,放在JVM栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。
JVM(一)虚拟机内存划分的更多相关文章
- java 虚拟机内存划分,类加载过程以及对象的初始化
涉及关键词: 虚拟机运行时内存 java内存划分 类加载顺序 类加载时机 类加载步骤 对象初始化顺序 构造代码块顺序 构造方法 顺序 内存区域 java内存图 堆 方法区 虚拟机栈 本地 ...
- 深入理解java虚拟机(一)虚拟机内存划分
Java虚拟机在执行Java程序时,会把它管理的内存划分为若干个不同的数据区.这些区域有不同的特性,起不同的作用.它们有各自的创建时间,销毁时间.有的区域随着进程的启动而创建,随着进程结束而销毁,有的 ...
- Java虚拟机内存划分
Java虚拟机在执行Java程序时,会把它管理的内存划分为若干个不同的数据区.这些区域有不同的特性,起不同的作用.它们有各自的创建时间,销毁时间.有的区域随着进程的启动而创建,随着进程结束而销毁,有的 ...
- 深入理解Java虚拟机 - 虚拟机内存划分
在内存管理方面,Java相对于C和C++的区别在于Java具有内存动态分配以及垃圾收集技术,但平时我们很少去关注JVM的内存结构以及GC,在出现内存泄露或溢出方面的问题,排查工作将变得异常艰难. ...
- (转)java 虚拟机内存划分
深入理解java虚拟机(一):java内存区域(内存结构划分)深入理解java虚拟机(二):java内存溢出实战 深入理解java虚拟机(三):String.intern()-字符串常量池深入理解j ...
- JVM探秘1--JVM内存运行时区域划分
Java程序员一般不需要太关注内存,因为操作内存的权力都交给了Java虚拟机,但是Java程序员必须需要了解JVM是如何使用内存的,否则一旦内存出现泄漏或事溢出的话,就会一筹莫展不知道从哪去入手排查问 ...
- JAVA虚拟机运行时内存划分--运行时数据区域
Java虚拟机在执行java程序时会把内存划分为以下几个不同的数据区域: java虚拟机内存划分(运行时)1.线程私有的: 程序计数器(Program Counter Register):可以看作当前 ...
- Java运行时内存划分与垃圾回收--以及类加载机制基础
----JVM运行时内存划分----不同的区域存储的内容不同,职责因为不同1.方法区:被线程共享,存储被JVM加载的类的信息,常量,静态变量等2.运行时常量池:属于方法区的一部分,存放编译时期产生的字 ...
- JVM内存划分
JVM内存划分吗? 前言: 大家都知道虚拟机,都知道JVM,其实这些都是基于sun公司[oracle公司]的HotSpot虚拟机,当然本篇博文也是以sun公司为基础.还有其他的虚拟机,常见的就有JRo ...
随机推荐
- cenos7 修改hostname
hostnamectl set-hostname Linuxidc 如何在CentOS 7上修改主机名 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵 ...
- C语言序列点问题总结(大多数高等教育C语言教学课程的漏洞)
C语言序列点总结 2013年11月21于浙大华家池 C 语言副作用: (side effect)是指对数据对象或者文件的修改. 例如,语句 v = 99;的副作用是把 v 的值修改成 99. C语言序 ...
- go的timer定时器实现
示例如下: package main import ( "fmt" "time" ) func testTimer1() { go func() { fmt.P ...
- 多媒体开发之---h264中 的RTP PAYLOAD 格式
H.264 视频 RTP 负载格式 1. 网络抽象层单元类型 (NALU) NALU 头由一个字节组成, 它的语法如下: +---------------+ |0|1|2|3|4|5|6|7 ...
- Android OkHttp的Cookie自己主动化管理
Android中在使用OkHttp这个库的时候.有时候须要持久化Cookie,那么怎么实现呢.OkHttp的内部源代码过于复杂,不进行深究.这里仅仅看当中的HttpEngineer里面的部分源代码,在 ...
- 【转】一步一步带你反编译apk,并教你修改smali和重新打包
一.工具介绍: 1.apktool:aapt.exe,apktool.bat,apktool.jar;三个在同一目录结合使用,用来反编译apk,apk重新打包: 2.dex2jar:该工具作用是将cl ...
- Encoding::CompatibilityError: incompatible character encodings: GBK and UTF-8
直接grunt serve读的css是.tmp/css/main.css 而这个文件不通过build生成出来是这样: /* Encoding::CompatibilityError: incompat ...
- 如何学习CCIE
想想自己拖了这么久,也没考试,也没积极去做实验,心里也有怨念,其实一直是方法不对,今天心里产生共鸣,后悔当初太年轻. 转载地址:http://bbs.hh010.com/thread-467553-1 ...
- 【题解】Codeforces 961G Partitions
[题解]Codeforces 961G Partitions cf961G 好题啊哭了,但是如果没有不小心看了一下pdf后面一页的提示根本想不到 题意 已知\(U=\{w_i\}\),求: \[ \s ...
- 如何使用doctrine:migrations:migrate
doctrine:migrations:migrate: 可以生成数据库表 当新建完实体之后需要执行 doctrine:migrations:diff 更新差异到db 然后就ok了,这时候你的app/ ...