2.1-2.2 HBase数据存储
一、HBase数据检索流程
一篇介绍HBase数据读写流程的解析的博文:http://hbasefly.com/2016/12/21/hbase-getorscan/?wsfatm=uqvhl3
1、命名空间
- ##查看命名空间
- hbase(main):001:0> list_namespace
- NAMESPACE
- 2019-05-21 13:31:59,854 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- default
- hbase
- ##查看命名空间下的表
- hbase(main):003:0> list_namespace_tables 'hbase'
- TABLE
- meta
- namespace
- 2 row(s) in 0.0260 seconds
- ##查看某个命名空间下的表数据
- hbase(main):004:0> scan 'hbase:meta'
2、数据检索流程
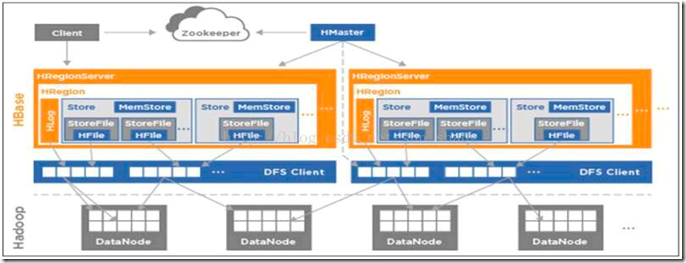
- #####
- 由图可以看出,存储模块主要包括了ZooKeeper集群、HMaster、HRegionServer。
- ZooKeeper: Hbase是强依赖于ZooKeeper,我们读或写一个表的数据,都会优先访问ZooKeeper。
- 通常是集群中单独的3/5台服务器。
- HMaster通常是Hadoop集群中的一台或两台(backup-Master)。
- HRegionServer通常是Hadoop集群中的部分或全部, HRegionServer通常和datanode部署在同一台服务器上,比如datanode是10个HRegionServer可以是10个或小于10个;
- ##client--->server
- 1、客户端首先会根据配置文件中zookeeper地址连接zookeeper,并读取/<hbase-rootdir>/meta-region-server节点信息,该节点信息存储HBase元数据(hbase:meta)表所在的RegionServer地址以及访问端口等信息。用户可以通过zookeeper命令(get /<hbase-rootdir>/meta-region-server)查看该节点信息。
- 2、根据hbase:meta所在RegionServer的访问信息,客户端会将该元数据表加载到本地并进行缓存。然后在表中确定待检索rowkey所在的RegionServer信息。
- 3、根据数据所在RegionServer的访问信息,客户端会向该RegionServer发送真正的数据读取请求。服务器端接收到该请求之后需要进行复杂的处理,具体的处理流程将会是这个专题的重点。
- 通过上述对客户端以及HBase系统的交互分析,可以基本明确两点:
- 1、客户端只需要配置zookeeper的访问地址以及根目录,就可以进行正常的读写请求。不需要配置集群的RegionServer地址列表。
- 2、客户端会将hbase:meta元数据表缓存在本地,因此上述步骤中前两步只会在客户端第一次请求的时候发生,之后所有请求都直接从缓存中加载元数据。如果集群发生某些变化导致hbase:meta元数据更改,客户端再根据本地元数据表请求的时候就会发生异常,此时客户端需要重新加载一份最新的元数据表到本地。
2.1-2.2 HBase数据存储的更多相关文章
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- HBase 数据存储结构
在HBase中, 从逻辑上来讲数据大概就长这样: 单从图中的逻辑模型来看, HBase 和 MySQL 的区别就是: 将不同的列归属与同一个列族下 支持多版本数据 这看着感觉也没有那么太大的区别呀, ...
- HBase数据存储
HRegionServer  HBase的数据文件都存储在HDFS上,格式主要有两种: - HFile:HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制文件,实际上Sto ...
- hbase数据加盐(Salting)存储与协处理器查询数据的方法
转自: https://blog.csdn.net/finad01/article/details/45952781 ----------------------------------------- ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
转自:http://www.infoq.com/cn/articles/trillion-log-and-data-storage-query-techniques?utm_source=infoq& ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- 大数据存储利器 - Hbase 基础图解
由于疫情原因在家办公,导致很长一段时间没有更新内容,这次终于带来一篇干货,是一篇关于 Hbase架构原理 的分享. Hbase 作为实时存储框架在大数据业务下承担着举足轻重的地位,可以说目前绝大多数大 ...
随机推荐
- 显示和隐藏Mac隐藏文件的命令
显示Mac隐藏文件的命令:defaults write com.apple.finder AppleShowAllFiles -bool true 隐藏Mac隐藏文件的命令:defaults writ ...
- sql quer
SELECT (SELECT COUNT (sysid) FROM FwInvConsumable WHERE parentref = g.sysid AND (ns.state = 'Invento ...
- caffe训练自己的图片进行分类预测--windows平台
caffe训练自己的图片进行分类预测 标签: caffe预测 2017-03-08 21:17 273人阅读 评论(0) 收藏 举报 分类: caffe之旅(4) 版权声明:本文为博主原创文章,未 ...
- bootstrap-table自己配置
function initTable(){ var methodNameSearch=$("#methodNameSearch").val(); var requestUrl = ...
- PythonCookBook笔记——迭代器与生成器
迭代器与生成器 迭代是Python最强大的功能之一,虽然看起来迭代只是处理序列中元素的一种方法,但不仅仅如此. 手动遍历迭代器 想遍历但不想使用for循环. 使用next()方法并在代码中捕获Stop ...
- VS重置命令:devenv.exe/resetuserdata
VS命令行下执行下面的命令: devenv.exe/resetuserdata
- 【BZOJ1528】[POI2005]sam-Toy Cars 贪心
[BZOJ1528][POI2005]sam-Toy Cars Description Jasio 是一个三岁的小男孩,他最喜欢玩玩具了,他有n 个不同的玩具,它们都被放在了很高的架子上所以Jasio ...
- EasyHLS实现将IPCamera摄像机的RTSP转HLS直播输出
EasyHLS EasyHLS是EasyDarwin开源流媒体团队开发的一款HLS打包库,接口非常简单,只需要传入打包的文件名.切片存放的目录.单个切片时长以及切片数等参数,EasyHLS库就能轻松将 ...
- VLC RTP Over TCP
在RTSP协议请求数据时,让VLC以TCP的方式获取服务器发来的RTP数据 不为别的,下次回复直接用博客链接就能回复大家了! 操作:工具 -> 首选项 然后: 搞定! ------------- ...
- 2018-11-13-常用模块1 (time random os sys)
1.时间模块 time 2.随机数模块 random 3.与操作系统交互模块 os 4.系统模块 sys 在我们真正开始学习之前我们先解决下面几个问题,打好学习模块的小基础,以便更好的学习模块. (1 ...