requests中文页面乱码解决方案【转】
requests中文页面乱码解决方案!
请给作者点赞 --> 原文链接
Python中文乱码,是一个很大的坑,自己不知道在这里遇到多少问题了。还好通过自己不断的总结,现在遇到乱码的情况越来越少,就算出现,一般也能快速解决问题。这个问题,我七月就解决了,今天总结出来,和朋友一起分享。
最近写过好几个爬虫,熟悉了下Python requests库的用法,这个库真的Python的官方api接口好用多了。美中不足的是:这个库好像对中文的支持不是很友好,有些页面会出现乱码,然后换成urllib后,问题就没有了。由于requests库最终使用的是urllib3作为底层传输适配器,requests只是把urllib3库读取的原始进行人性化的处理,所以问题requests库本身上!于是决定阅读库源码,解决该中文乱码问题;一方面,也是希望加强自己对HTTP协议、Python的理解。
先是按照api接口,一行行阅读代码,尝试了解问题出在哪里!真个过程进展比较慢,我大概花了5天左右的时间,通读了该库的源代码。阅读代码过程中,有不懂的地方,就自己打印日志信息,以帮助理解。
最后我是这样发现问题所在的!

>>> req = requests.get('http://www.jd.com')
>>> req
<Response [200]>
>>> print req.text[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-×ÛºÏÍø¹ºÊ×Ñ¡-ÕýÆ·µÍ¼Û¡¢Æ·ÖÊ
# 这里出现了乱码
>>> dir(req)
['__attrs__', '__bool__', '__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__getstate__', '__hash__', '__init__', '__iter__', '__module__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']
req有content属性,还有text属性,我们看看content属性:
>>> print req.content[:100]
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-؛ºЍ닗ѡ-ֽƷµͼۡ¢Ʒ
>>>
>>>
>>> print req.content.decode('gbk')[:100]
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!</
## 由于该页面时gbk编码的,而Linux是utf-8编码,所以打印肯定是乱码,我们先进行解码。就能正确显示了。
可是,text属性,按照此种方式,并不可行!
>>> print req.text[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-×ÛºÏÍø¹ºÊ×Ñ¡-ÕýÆ·µÍ¼Û¡¢Æ·ÖÊ
>>> print req.text.decode('gbk')[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 60-63: ordinal not in range(128)
# 对text属性进行解码,就会出现错误。
让我们来看看,这两个属性的源码:
# /requests/models.py
@property
def content(self):
"""Content of the response, in bytes.""" if self._content is False:
# Read the contents.
try:
if self._content_consumed:
raise RuntimeError(
'The content for this response was already consumed') if self.status_code == 0:
self._content = None
else:
self._content = bytes().join(self.iter_content(CONTENT_CHUNK_SIZE)) or bytes() except AttributeError:
self._content = None self._content_consumed = True
# don't need to release the connection; that's been handled by urllib3
# since we exhausted the data.
return self._content
# requests/models.py
@property
def text(self):
"""Content of the response, in unicode. If Response.encoding is None, encoding will be guessed using
``chardet``. The encoding of the response content is determined based solely on HTTP
headers, following RFC 2616 to the letter. If you can take advantage of
non-HTTP knowledge to make a better guess at the encoding, you should
set ``r.encoding`` appropriately before accessing this property.
""" # Try charset from content-type
content = None
encoding = self.encoding if not self.content:
return str('') # Fallback to auto-detected encoding.
if self.encoding is None:
encoding = self.apparent_encoding # Decode unicode from given encoding.
try:
content = str(self.content, encoding, errors='replace')
except (LookupError, TypeError):
# A LookupError is raised if the encoding was not found which could
# indicate a misspelling or similar mistake.
#
# A TypeError can be raised if encoding is None
#
# So we try blindly encoding.
content = str(self.content, errors='replace') return content
看看注和源码知道,content是urllib3读取回来的原始字节码,而text不过是尝试对content通过编码方式解码为unicode。jd.com 页面为gbk编码,问题就出在这里。
>>> req.apparent_encoding;req.encoding'GB2312'
'ISO-8859-1'
这里的两种编码方式和页面编码方式不一致,而content却还尝试用错误的编码方式进行解码。肯定会出现问题!
我们来看看,req的两种编码方式是怎么获取的:
# rquests/models.py
@property
def apparent_encoding(self):
"""The apparent encoding, provided by the chardet library"""
return chardet.detect(self.content)['encoding']
顺便说一下:chardet库监测编码不一定是完全对的,只有一定的可信度。比如jd.com页面,编码是gbk,但是检测出来却是GB2312,虽然这两种编码是兼容的,但是用GB2312区解码gbk编码的网页字节串是会有运行时错误的!
获取encoding的代码在这里:
# requests/adapters.py
def build_response(self, req, resp):
"""Builds a :class:`Response <requests.Response>` object from a urllib3
response. This should not be called from user code, and is only exposed
for use when subclassing the
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>` :param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
:param resp: The urllib3 response object.
"""
response = Response() # Fallback to None if there's no status_code, for whatever reason.
response.status_code = getattr(resp, 'status', None) # Make headers case-insensitive.
response.headers = CaseInsensitiveDict(getattr(resp, 'headers', {})) # Set encoding.
response.encoding = get_encoding_from_headers(response.headers)
# .......
通过get_encoding_from_headers(response.headers)函数获取编码,我们再来看看这个函数!
# requests/utils.py
def get_encoding_from_headers(headers):
"""Returns encodings from given HTTP Header Dict. :param headers: dictionary to extract encoding from.
""" content_type = headers.get('content-type') if not content_type:
return None content_type, params = cgi.parse_header(content_type) if 'charset' in params:
return params['charset'].strip("'\"") if 'text' in content_type:
return 'ISO-8859-1'
发现了吗?程序只通过http响应首部获取编码,假如响应中,没有指定charset, 那么直接返回'ISO-8859-1'。
我们尝试进行抓包,看看http响应内容是什么:
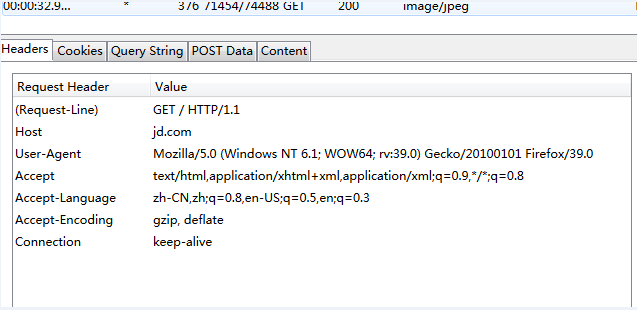
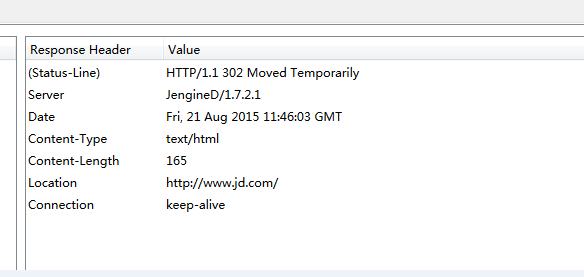
可以看到,reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中)。所有该函数就直接返回'ISO-8859-1'。
可能大家会问:作者为什么要默认这样处理呢?这是一个bug吗?其实,作者是严格http协议标准写这个库的,《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
解决方案:
找到了问题所在,我们现在有两种方式解决该问题。
1. 修改get_encoding_from_headers函数,通过正则匹配,来检测页面编码。由于现在的页面都在HTML代码中指定了charset,所以通过正则式匹配的编码方式是完全正确的。
2. 由于content是HTTP相应的原始字节串,所以我们需要直接可以通过使用它。把content按照页面编码方式解码为unicode!
requests中文页面乱码解决方案【转】的更多相关文章
- Python HTTP库requests中文页面乱码解决方案!
http://www.cnblogs.com/bitpeng/p/4748872.html Python中文乱码,是一个很大的坑,自己不知道在这里遇到多少问题了.还好通过自己不断的总结,现在遇到乱码的 ...
- css中文字体乱码解决方案
css中文字体乱码解决方案:把css编码和html页面编码统一起来.如果html页面是utf-8.css.js也统一成utf-8编码.还有一个避免中文乱码的办法就是把中文字体写成英文来表示 css中文 ...
- asp.net——地址栏传递中文参数乱码解决方案
地址栏传递中文参数乱码解决方案: 很多人在使用地址栏传递参数的时候都会遇到一个麻烦的问题(参数为中文时乱码了),那要怎么解决呢? 其实解决这个问题也不怎么难,无非就是给要传递的中文参数一个编码解码的过 ...
- g++编译后中文显示乱码解决方案(c++)
g++编译后中文显示乱码解决方案 环境:Windows 10 专业版 GCC版本:5.3.0 测试代码: 1 #include <iostream> 2 using namespace ...
- Hive中文注释乱码解决方案(2)
本文来自网易云社区 作者:王潘安 执行阶段 launchTask 回到Driver类的runInternal方法,看以下执行过程.在runInternal方法中,执行过程调用了execute方法 ...
- linux系统挂载U盘,中文文件名乱码解决方案
本人(壮壮熊)所用系统:ubuntu 12.4 今天在使用mount指令挂在硬盘时,出现令人头疼的中文文件名乱码. 问题: 使用mount /dev/sdb1 /media指令挂在第二颗硬盘的第一个分 ...
- Linux 解决 firefox 中文页面乱码问题
1.由于 firefox 默认是允许网页自己选择字体,在 Linux 上便会出现部分网站的乱码情况.因此可以取消允许页面自己选择字体这个选项便能解决部分乱码情况.
- ANSI转UTF-8中文无乱码解决方案
近期做的项目需要使用Doxygen生成文档,由于前期代码不是本人完成,他使用的是ANSI格式的文件,后来我用Notepad++写其他文件时,默认保存为UTF-8 无BOM编码格式,因此整个项目文件中既 ...
- Intellij IDEA 导入 eclipese项目之后,中文注释乱码解决方案
首先,看导入后整个IJ界面: 可以看到注释是乱码,要解决问题就跟我开始做吧,看右下角有个"UTF-8",点一下选择"GBk",选择"Reload&qu ...
随机推荐
- DB2去重的几种方法
有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略. 例如下表:table1 用户办理套餐的记 ...
- SQLServer 索引的使用情况
—在优化查询SQL语句,查看索引使用情况SQL语句: select db_name(database_id) as N'数据库名称', object_name(a.object_id) as N'表名 ...
- chrome浏览器表单自动填充默认样式-autofill
Chrome会在客户登陆过某网站之后, 会自动记住密码 当你下次再次进入该网站的时候, 可以自由的选择登陆的账号, Chrome会为你自动填充密码. 而你无需再输入密码 这本身是一个很好的功能, 但是 ...
- 19.CentOS7下PostgreSQL安装过程
CentOS7下PostgreSQL安装过程 装包 sudo yum install postgresql-server postgresql-contrib 说明: 这种方式直接明了,其他方法也可以 ...
- 在Magento中用MySQL模拟队列发送电子邮件
1. 需求 顾客在网站上购买特定商品并且这些商品的总金额超过特定金额后,使用email给顾客发送一个优惠券:假如某件商品已经降价了,则此商品的金额不计算在目标总金额内: 2. 需求分析 ①发送优惠券的 ...
- 【收藏】这么多WEB组件(CSS),攒一个网站够了吧?
简言 总是喜欢简单又精致的东西,美的不繁复也不张扬.这是闷骚程序员的癖好么?闲来无事,把收集到的部分WEB组件整理汇总一下,攒一个逼格高一点的网站够了吧? 1 表单(form)相关 1.1 输入框(i ...
- strlen()与mb_strlen()的作用分别是什么
strlen和mb_strlen都是用于截取字符串的,其中strlen只针对单字节编码字符 如果是多字节编码字符 如gbk和utf8 使用strlen会出现乱码 此时可以使用mb_strlen(),专 ...
- JS 获取 今日、昨日、本周、本月、本季度、本年、上月、上周、上季度、去年
/** * 日期范围工具类 */ var dateRangeUtil = (function () { /*** * 获得当前时间 */ this.getCurrentDate = function ...
- RING3到RING0
当我在说跳转时,说的什么? CPU有很多指令,不是所有的指令都能够随时用,比如 ltr指令就不是随便什么时候能用,在保护模式下,如果你不安规则来执行指令,CPU就会抛出异常,比如你在INTEL手册上就 ...
- windows安装ipython
一.安装python2.71.下载地址https://www.python.org/downloads/2.安装后修改本地变量-右击电脑-属性-高级系统设置-环境变量-用户变量-新建-变量名:path ...