数据结构与算法(C/C++版)【绪论/线性表】
声明:数据结构与算法系列博文参考了《天勤高分笔记》、《王道复习指导》、C语言中文网。非商业用途,仅为学习笔记总结!
第一章《绪论》
一、基本概念及入门常识
////(一)数据结构的基本概念和术语////
. 数据
数据是信息的载体,是描述客观事物属性的数、字符以及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。
. 数据元素
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。一个数据元素可由若干个数据项组成,数据项是构成数据元素的不可分割的最小单位。例如,学生记录就是一个数据元素,它由学号、姓名、性别等数据项组成。
注意:不要混淆数据、数据元素、数据项之间的概念,也要注意和数据库中的相关术语进行区别:如数据记录、数据字段等概念。
. 数据对象
数据对象是具有相同性质的数据元素的集合,是数据的一个子集。例如,整数数据对象是集合 N= {,±, 士2, ...}。
. 数据类型
数据类型是一个值的集合和定义在此集合上一组操作的总称。
) 原子类型:其值不可再分的数据类型。
) 结构类型:其值可以再分解为若千成分(分量)的数据类型。
) 抽象数据类型:抽象数据组织和与之相关的操作。
. 抽象数据类型 抽象数据类型(ADT)是指一个数学模型以及定义在该模型上的一组操作。抽象数据类型的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关,即不论其内部结构如何变化,只要它的数学特性不变,都不影响其外部的使用。通常用(数据对象、 数据关系、基本操作集)这样的三元组来表示抽象数据类型。
. 数据结构
在任何问题中,数据元素都不是孤立存在的,而是在它们之间存在着某种关系,这种数据元素相互之间的关系称为结构(structure)。数据结构是相互之间存在一种或多种特定关系的数据元素的集合。数据结构包括三方面的内容:逻辑结构、存储结构和数据的运算。数据的逻辑结构和存储结构是密不可分的两个方面,一个算法的设计取决于所选定的逻辑结构,而算法的实现依赖于所釆用的存储结构。 ////(二)数据结构三要素:数据逻辑结构、数据存储结构和数据的运算////
. 数据的逻辑结构
逻辑结构是指数据元素之间的逻辑关系,即从逻辑关系上描述数据。它与数据的存储无关,是独立于计算机的。数据的逻辑结构分为线性结构和非线性结构,线性表是典型的线性结构;集合、树和图是典型的非线性结构。数据的逻辑结构分类
集合结构中的数据元素之间除了 “同属于一个集合”的关系外,别无其他关系。
线性结构结构中的数据元素之间只存在一对一的关系。
树形结构结构中的数据元素之间存在一对多的关系。
图状结构或网状结构结构中的数据元素之间存在多对多的关系。 . 数据的存储结构
存储结构是指数据结构在计算机中的表示(又称映像),也称物理结构。它包括数据元素的表示和关系的表示。数据的存储结构是逻辑结构用计算机语言的实现,它依赖于计算机语言。数据的存储结构主要有:顺序存储、链式存储、索引存储和散列存储。
) 顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元里,元素之间的关系由存储单元的邻接关系来体现。其优点是可以实现随机存取,每个元素占用最少的存储空间;缺点是只能使用相邻的一整块存储单元,因此可能产生较多的外部碎片。
) 链接存储:不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针表示元素之间的逻辑关系。其优点是不会出现碎片现象,充分利用所有存储单元;缺点是每个元素因存储指针而占用额外的存储空间,并且只能实现顺序存取。
) 索引存储:在存储元素信息的同时,还建立附加的索引表。索引表中的每一项称为索引项,索引项的一般形式是:(关键字,地址)。其优点是检索速度快;缺点是增加了附加的索引表,会占用较多的存储空间。另外,在增加和删除数据时要修改索引表,因而会花费较多的时间。
) 散列存储:根据元素的关键字直接计算出该元素的存储地址,又称为Hash存储。其优点是检索、增加和删除结点的操作都很快;缺点是如果散列函数不好可能出现元素存储单元的冲突,而解决冲突会增加时间和空间开销。
. 数据的运算 施加在数据上的运算包括运算的定义和实现。运算的定义是针对逻辑结构的,指出运算的功能;运算的实现是针对存储结构的,指出运算的具体操作步骤。 ////(三)算法的基本概念及特性(有穷性、确定性、可行性、输入和输出)////
算法(algorithm)是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作。此外,一个算法还具有下列5个重要特性:
) 有穷性
一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间内完成。
) 确定性
算法中每一条指令必须有确切的含义,读者理解时不会产生二义性。即对于相同的输入只能得出相同的输出。
) 可行性
一个算法是可行的,即算法中描述的操作都是吋以逋过已经实现的基本运算执行有限次来实现的。
) 输入
一个算法有零个或多个的输入,这些输入取自于某个特定的对象的集合。
) 输出
一个算法有一个或多个的输出,这些输出是同输入有着某种特定关系的量。 通常设计一个“好”的算法应考虑达到以下目标:
正确性:算法应当能够正确地解决求解问题。
可读性:算法应当具有良好的可读性,以助于人们理解。
健壮性:当输入非法数据时,算法也能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。
效率与低存储量需求:效率是指算法执行的时间,存储量需求是指算法执行过程中所需要的最大存储空间,这两者都与问题的规模有关。
////算法效率度量:时间复杂度和空间复杂度////
算法效率的度量是通过时间复杂度和空间复杂度来描述的。
时间复杂度
一个语句的频度是指该语句在算法中被重复执行的次数。算法中所有语句的频度之和记作T(n),它是该算法问题规模n的函数,时间复杂度主要分析T(n)的数量级。算法中的基本运算(最深层循环内的语句)的频度与T(n)同数量级,所以通常釆用算法中基本运算的频度 f(n)来分析算法的时间复杂度。因此,算法的时间复杂度也记为:
T(n)=O(f(n))
上式中“O”的含义是T(n)的数量级,其严格的数学定义是:若T(n)和f(n)是定义在正整数集合上的两个函数,则存在正常数C和n0,使得当n>=n0时,都满足0 <= T(n) <= C * f(n)。
注意:取f(n)中随n增长最快的项将其系数置为1作为时间复杂度的度量。例如,fi(n) = a * n3 + b * n2 + c * n,则其时间复杂度为O(n3)。
算法的时间复杂度不仅依赖于问题的规模n,也取决于待输入数据的性质(如输入数据元素的初始状态)。 例如:在数组A[...n-]中,查找给定值K的算法大致如下:
i=n-;
while( i>= && (A[i]!=k) )
i--; // 语句(3)
return i; 此算法中的语句()(基本运算)的频度不仅与问题规模n有关,还与输入实例中A 的各元素取值及K的取值有关:
若A中没有与K相等的元素,则语句()的频度 f(n)=n。
若A的最后一个元素等于K,则语句()的频度f(n)是常数0。
最坏时间复杂度是指在最坏情况下,算法的时间复杂度。
平均时间复杂度是指所有可能输入实例在等概率出现的情况下,算法的期望运行时间。
最好时间复杂度是指在最好情况下,算法的时间复杂度。
一般总是考虑在最坏情况下的时间复杂度,以保证算法的运行时间不会比它更长。
在分析一个程序的时间复杂性时,有以下两条规则:
a) 加法规则
T(n) = T1(n) + T2(n) = O(f(n)) + O(g(n)) = O(max(f(n), g(n)))
b) 乘法规则
T(n) = T1(n) * T2(n) = O(f(n)) * O(g(n)) = O( f(n) * g(n) )
常见的渐近时间复杂度有:
O()<O(log2n)<O(n)<O(nlog2n)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
空间复杂度
算法的空间复杂度S(n),定义为该算法所耗费的存储空间,它是问题规模n的函数。渐近空间复杂度也常简称为空间复杂度,记作S(n)=O(g(n))。
一个上机程序除了需要存储空间来存放本身所用指令、常数、变量和输入数据外,也需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的辅助空间,若输入数据所占空间只取决于问题本身,和算法无关,则只需分析除输入和程序之外的额外空间。
算法原地工作是指算法所需辅助空间是常量,即O()。
#侃大山(密集恐惧症者慎入)0.0
第二章《线性表》
一、概述
线性表:具有相同特性数据元素的有限序列
---相同特性:把同一类事物归类,方便批量处理
---有限:表中元素个数为n,n有限大,n可以为0
---序列:表中元素排成一列,体现了一对一的逻辑特性(每个元素有且仅有一个前驱和一个后继)
逻辑结构:只有一个表头元素,只有一个表尾元素,表头元素没有前驱,表尾元素没有后继,除表头表尾之后的其他元素只有一个前驱,也只有一个后继。
存储结构:①顺序存储结构(顺序表);②链式存储结构(单链表、双链表、单循环链表、双循环链表)
①顺序存储结构:利用数组的连续存储空间顺序存放线性表的各元素,每个结点包含所储存元素的信息。
②链式存储结构:不要求逻辑上相邻的两个元素物理上也相邻;通过“链”建立起数据元素之间的逻辑关系。每个结点不仅包含所储存元素的信息,还包含元素之间的逻辑关系信息;比如可以通过前驱结点中的地址信息找到后继结点的位置。
特征对比:
1.在顺序表中插入和删除元素可能会导致移动大量元素的连带操作(表尾位置除外),而链表不会;
2.在单链表中找到任意一个结点的位置不想顺序表那么简单,因为顺序表支持随机存取(存取),而单链表不支持;
3.为了弥补上一天单链表的不足,开发了双链表、循环单链表和循环双链表等存储结构,这些存储结构可以在仅知道链表中任意一个结点地址的情况下的推测其余 所有结点的地址,但仍然不支持随机存取。
4.有时候还会给链表定义一个额外的指针,最常见的表尾指针,它指向链表中最后一个结点。可以借助它来提高某些常见操作的执行效率
5.线性表采用顺序存储结构,必须占用一片连续的存储单元,而采用链式存储结构则不需要这样。
6.从整体来看,一般顺序表存储空间利用率低于链表;而从单个存储单元来看,顺序表存储空间利用率要高于链表。
线性表的基本操作
一个数据结构的基本操作是指其最核心、最基本的操作。其他较复杂的操作可以通过调用其基本操作来实现。线性表的主要操作如下:
①InitList(&L):初始化表。构造一个空的线性表。
②Length(L):求表长度。返回线性表L的长度,即L中数据元素的个数。
③LocateElem(L, e):按值查找操作。在表L中查找具有给定关键字值的元素。
④GetElem(L, i):按位查找操作。获取表L中第i个位置的元素的值。
⑤ListInsert(&L, i, e):插入操作。在表L中第i个位置上插入指定元素。
⑥ListDelete(&L, i, &e):删除操作。删除表L中第i个位置的元素。
⑦PrintList(L):输出操作。按前后顺序输出线性表L的所有元素值。
⑧Empty(L):判空操作。若L为空表,则返回true,否则返回false。
⑨DestroyList(&L):销毁操作。销毁线性表,并释放线性表L所占用的内存空间。
二、线性表的操作
(1)顺序表

1、顺序表的结构体定义
#define maxSize 50 //定义线性表的最大长度
typedef struct
{
int data[maxSize]; //顺序表的元素(这里我们假设是int类型,也可能为其他类型)
int length; //顺序表的当前长度
}Sqlist; //顺序表的类型定义
2、顺序表的操作
①初始化
viod InitList(Sqlist &L)
{
L.length=;
}
②按值查找元素
//要求:用e获取P位置上的元素
int GetElem(Sqlist L,int p,int &e) //e本身要发生变化,所以用引用型&e(从没有元素到有元素)
{
if(p<||p>L.length-)
return ;
e=L.data[p];
return ;
}
③按序号位置查找元素
//要求:查找元素e的序号
int LocateElem(Sqlist L,int e)
{
int i;
for(i=;i<L.length;i++)
if(e==L.data[i])
return i;
return -;
}
④插入元素
//要求:插入元素e
int ListInsert(Sqlist &L,int p,int e) //L本身要发生变化,所以用引用型&L
{
int i;
if(p<||p>L.length||L.length==max.Size) //位置错误或者已经达到最大允许值,插入失败
return ;
for(i=L.length-;i>=p;--i)
L.data[i+]==L.data[i]; //采用先移动最右边的元素;若先移动最左边,右边的元素会被覆盖
L.data[p]=e; //将e赋值给p位置(成为p位置上的新元素)
++(L.length); //表内多了一个元素e,表长自增1
return -;
}
⑤删除元素
//要求:删除元素p,并把删除的元素赋值给e
int ListDelete(Sqlist &L,int p,int &e) //L、e本身要发生变化,所以用引用型&L,&e
{
int i;
if(p<||p>L.length-)
return ; //将p位置上的元素赋值给e
e=L.data[p];
for(i=p;i<L.length-;++i)
L.data[i]==L.data[i+]; //被删除元素右边的所有元素都往左边移动一个位置
--(L.length);
return ; //表内多了一个元素e,表长自减1
}
(2)单链表
概念:在每个结点中除了包含数据域外,还包含一个指针域,用以指向其后继结点;这两部分信息组成数据元素的存储结构,称之为“结点”。n个结点通过指针域相互链接,组成一个链表。

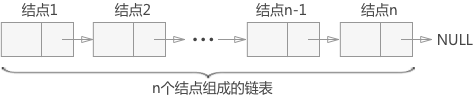
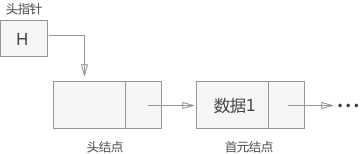
①带头结点:头指针head指向头结点,头结点的值域不含任何信息,从头结点的后继结点开始存储数据信息;头指针始终不等于NULL,当head->next等于NULL的时候,链表为空。
②不带头结点:头指针head直接指向开始结点;当head等于NULL的时候,链表为空
区分头指针和头结点:不论链表是否带头结点,头指针都指向链表中第一个结点;而带头结点的链表中头结点是第一个结点,只作为链表存在的标志,一般不储存信息。
注:暂时默认操作的链表都带头结点,以后有时间再回头总结不带头结点的相关操作。。。
<1>单链表结点定义
typedef struct LNode
{
int data;
struct LNode *next;
}LNode;
<2>查找结点
①按序号查找结点
在单链表中从第一个结点出发,顺指针next域逐个往下搜索,直到找到第i个结点为止,否则返回最后一个结点指针域NULL。
LNode GetElem(LNode *C,int i)
LNode GetElem(LNode *C,int i)
{
//本算法取出单链表C(带头结点,L为头结点)中第i个位置的结点指针
int j=; //计数,初始为1
LNode *p; //定义指针p(指向结点)
p= C; //指针P指向头结点C(因为此时头结点也是终端结点)
if(i==)
return L; //若i等于0,则返回头结点
if(i<)
return NULL; //若 i 无效,则返回 NULL
while( p && j<i ) //从第1个结点开始找,查找第i个结点
{
p=p->next;
j++;
}
return p; //返回第i个结点的指针,如果i大于表长,p=NULL,直接返回p即可
} 时间复杂度:按序号查找操作的时间复杂度为O(n)
②按值查找表结点
从单链表第一个结点开始,由前往后依次比较表中各结点数据域的值,若某结点数据域的值等于给定值e,则返回该结点的指针。若整个单链表中没有这样的结点,则返回NULL。
LNode *LocateElem (LinkList L, ElemType e) {
//本算法查找单链表 C(带头结点)中数据域值等于e的结点指针,否则返回NULL
LNode *p;
p=C;
while( p!=NULL && p->data!=e) //从第1个结点开始查找data域为e的结点
p=p->next;
return p; //找到后返回该结点指针,否则返回NULL
}
时间复杂度:按值查找操作的时间复杂度为O(n)。
<3>插入结点
①后插操作(利用前驱结点):插入操作是将值为x的新结点插入到单链表的第i个位置上。先检查插入位置的合法性,然后找到待插入位置的前驱结点,即第i-1个结点,再在其后插入新结点。
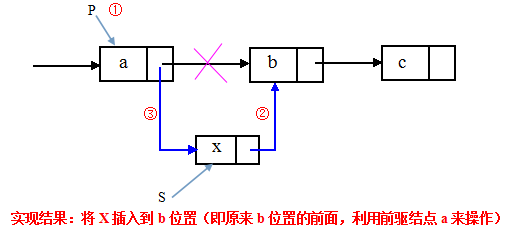
p=GetElem(L, i-) ; //①查找插入位置的前驱结点
s->next=p->next; //②令新结点*s的指针域指向*p的后继结点
p->next=s; //③令结点*p的指针域指向新插入的结点*s 注意:语句②③的顺序不能颠倒,否则,当先执行p->next=s后,指向其原后继的指针就不存在了,再执行s->next = p->next时,相当于执行了 s->next=s,显然是错误的。
时间复杂度:本算法主要的时间开销在于查找第i-1个元素,时间复杂度为O(n)。若是在给定的结点后面插入新结点,则时间复杂度仅为O()。
②前插操作(利用后继结点):设待插入结点为*s,将插入到*p的前面。我们仍然将*s插入到*p的后面,然后将p->data与s->data交换
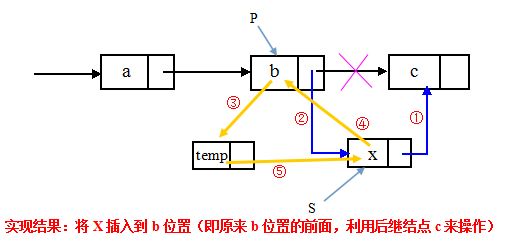
s->next = p->next; //①令新结点*s的指针域指向*p的后继结点
p->next = s; //②令结点*p的指针域指向新插入的结点*s
temp = p->data; //③把*p的指针域赋值给temp
p->data=s->data; //④把*s的指针域赋值给*p (③④⑤为交换数据域部分)
s->data=temp; //⑤把temp的指针域赋值给*s
时间复杂度:O()
<4>删除结点
①删除结点(利用前驱结点):先从链表的头结点开始顺序找到其前驱结点,然后再执行删除操作。
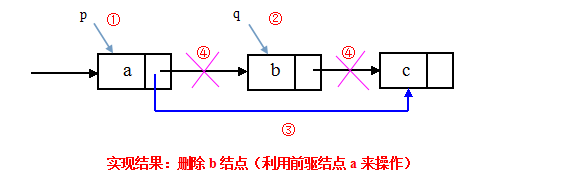
p=GetElem(L,i-); //①查找删除位置的前驱结点
q=p->next; //②令q指向被删除结点
p->next=q->next //③将*q结点从链中“断开”
free (q) ; //④释放结点的存储空间
时间复杂度:该算法的主要时间也是耗费在查找操作上,时间复杂度为O(n)
②删除结点(利用后继结点):用删除*p的后继结点操作来实现,实质就是将其后继结点的值赋予其自身,然后删除后继结点,也能使得时间复杂度为O(1)

q=p->next; //①令q指向*p的后继结点
p->data=p->next->data; //②和后继结点交换数据域(删除操作只考虑被留下来的数据即可)
p->next=q->next; //③将*q结点从链中“断开”
free (q) ; //④释放后继结点的存储空间
时间复杂度:O()
<5>创建链表
需求:n个元素已经储存在数组a中,建立链表C
①尾插法
viod creatlistR(LNode *&C,int a[],int n) //要改变的变量用引用型//(R代表rear 尾巴)
{
LNode *s,*r; //定义指针s(指向新申请的结点);r(指向C的终端结点)
C=(LNode*)malloc(sizeof(LNode)); //创建头结点(申请C的头结点空间)
C->next=NULL; //初始化成空链表(链表取头结点作为新链表的头)
r=C; //指针r指向头结点C(因为此时头结点也是终端结点)
int i;
for(i=;i<n;++i) //循环申请n个结点来接收数组a[]中的元素
{
s=(LNode*)malloc(sizeof(LNode)); //指针s指向新申请的结点
s->data=a[i]; //用新申请的结点来接收a数组中的一个元素
r->next=s; //用r来接纳新结点
r=r->next; //r始终指向终端结点,以便接收下一个新来的结点
}
r->next=NULL; //(r始终指向终端结点)r下一个设置为NULL,链表C建立完成
}
②头插法
viod creatlistF(LNode *&C,int a[],int n) //(F代表first 第一个,开头)
{
LNode *s;
C=(LNode*)malloc(sizeof(LNode));
C->next=NULL;
int i;
for(i=;i<n;++i)
{
s=(LNode*)malloc(sizeof(LNode));
s->data=a[i];
s->next=C->next; //s所指新结点的指针域next指向C中的开始结点
C->next=s; //头结点的指针域next指向s结点,使得s成为新的开始结点(插入结点操作)
}
}
<6>求表长
求表长操作就是计算单链表中数据结点(不含头结点)的个数,需要从第一个结点开始顺序依次访问表中的每一个结点,为此需要设置一个计数器变量,每访问一个结点,计数器加1,直到访问到空结点为止。算法的时间复杂度为O(n)。
注:因为单链表的长度是不包括头结点的,因此,不带头结点和带头结点的单链表在求表长操作上会略有不同。对不带头结点的单链表,当表为空时,要单独处理。
(3)双链表
概念:单链表中只有一个指针,指向直接后继,整个链表只能单方向从表头访问到表尾。如果算法中需要频繁地找某结点的前驱结点,单链表的解决方式是遍历整个链表,增加算法的时间复杂度,影响整体效率。
双链表:在单向链表的基础上,给各个结点额外配备一个指针变量,用于指向每个结点的直接前驱元素。
优点:双链表可以很方便地找到其前驱结点,因此,插入、删除结点算法的时间复杂度仅为O(1)


<1>双链表结点定义
typedef struct DLNode //定义双链表结点类型
{
int data; //数据域
struct DLNode *prior; //指向直接前驱
struct DLNode *next; //指向直接后继
}DLNode;
<2>插入结点
需求:1,2结点之间插入4结点(双链表中p所指的结点之后插入结点*q)
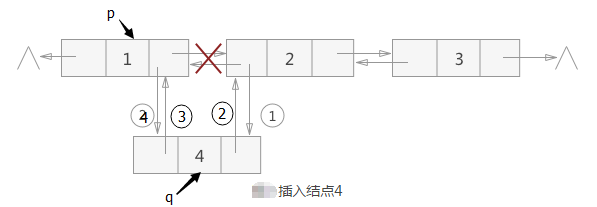
p->next->prior=q; // ①把4变成2的前驱结点(新结点*q的指针域指向*p的后继结点)
q->next=p->next; // ②把2变成4的后继结点(结点*p的指针域指向新插入的结点*s)
q->prior=p; // ③把1变成4的前驱结点
p->next=q; // ④把4变成1的后继结点 注:代码的语句顺序不是唯一的,但也不是任意的,①②两步必须在④步之前,否则*p 的后继结点的指针就丢掉了,导致插入失败。
<3>删除结点
双链表删除结点时,直接遍历链表,找到要删除的结点,然后利用该结点的两个指针域完成删除操作。
需求:删除2结点(删除双链表中结点*p的后继结点*q)
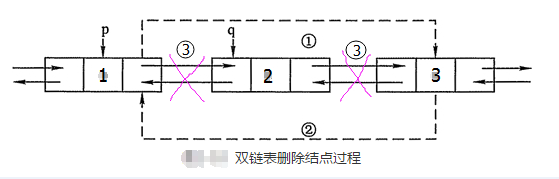
p->next=q->next; //①把3变成1的后继结点
q->next->prior=p; //②把1变成3的前驱结点
free (q) ; //③释放结点空间
建立双链表的操作中,也可以采用如同单链表的头插法和尾插法,但是在操作上需要注意指针的变化和单链表有所不同。
(4)循环单链表

在循环单链表中,表尾结点的next域指向L,故表中没有指针域为NULL的结点,因此,循环单链表的判空条件不是头结点的指针是否为空,而是它是否等于头指针。
循环单链表的插入、删除算法与单链表的几乎一样,所不同的是如果操作是在表尾进行,则执行的操作不相同,以让单链表继续保持循环的性质。当然,正是因为循环单链表是一个 “环”,因此,在任何一个位置上的插入和删除操作都是等价的,无须判断是否是表尾。
在单链表中只能从表头结点开始往后顺序遍历整个链表,而循环单链表可以从表中的任一结点开始遍历整个链表。有时对单链表常做的操作是在表头和表尾进行的,此时可对循环单链表不设头指针而仅设尾指针,从而使得操作效率更高。原因:若设置头指针,则对表尾进行操作需要时间复杂度O(n);若设置尾指针r,则头指针为r->next,即对表头表尾操作的时间复杂度都为O(1)
(5)循环双链表
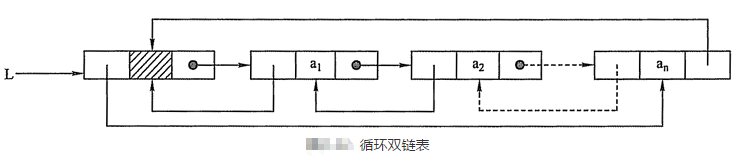
在循环双链表中,头结点的prior 指针还要指向表尾结点。
在循环双链表L中,某结点*p为尾结点时,p->next=L;当循环双链表为空表时,其头结点的prior域和next域都等于L。
(6)静态链表
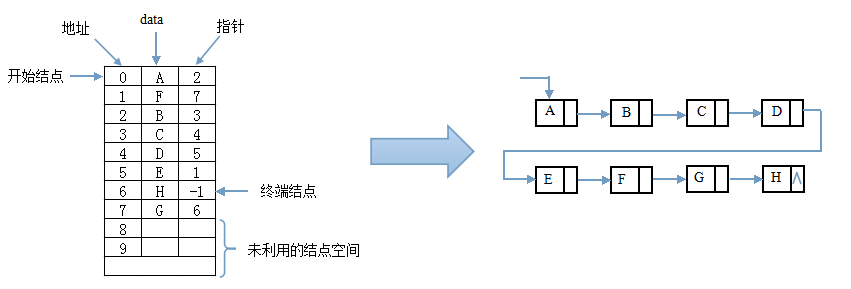
静态链表是借助数组来描述线性表的链式存储结构,结点也有数据域data和指针域 next,与前面所讲的链表中的指针不同的是,这里的指针是结点的相对地址(数组下标),又称为游标。和顺序表一样,静态链表也要预先分配一块连续的内存空间。
静态链表和动态链表的区别:静态链表限制了数据元素存放的位置范围;动态链表是整个内存空间。数据元素只允许在这块内存空间中随机存放。
静态链表结构体定义:
#define MaxSize 50 //静态链表的最大长度
typedef struct{ //静态链表结构类型的定义
ElemType data; //存储数据元素
int next; //下一个元素的数组下标
}SLinkList[MaxSize];
静态链表以next==-1作为其结束的标志。静态链表的插入、删除操作与动态链表相同,只需要修改指针,而不需要移动元素。总体来说,静态链表没有单链表使用起来方便,但是在一些不支持指针的高级语言(如Basic)中,这又是一种非常巧妙的设计方法。
下一篇预告:第三章《栈与队列》
数据结构与算法(C/C++版)【绪论/线性表】的更多相关文章
- 数据结构与算法(C#)入门 --- 线性表
线性表: 线性表是最简单,最基本,最常用的数据结构.线性表中的数据元素之间存在一对一的关系.即:除了第一个元素,其他元素前面有且只有一个元素:除了最后一个元素,其他元素后面有且只有一个元素.生活中的例 ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第4章 栈
定场诗 金山竹影几千秋,云索高飞水自流: 万里长江飘玉带,一轮银月滚金球. 远自湖北三千里,近到江南十六州: 美景一时观不透,天缘有分画中游. 前言 本章是重读<学习JavaScript数据结构 ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第5章 队列
定场诗 马瘦毛长蹄子肥,儿子偷爹不算贼,瞎大爷娶个瞎大奶奶,老两口过了多半辈,谁也没看见谁! 前言 本章为重读<学习JavaScript数据结构与算法-第三版>的系列文章,主要讲述队列数据 ...
- 数据结构和算法(Java版)快速学习(线性表)
线性表的基本特征: 第一个数据元素没有前驱元素: 最后一个数据元素没有后继元素: 其余每个数据元素只有一个前驱元素和一个后继元素. 线性表按物理存储结构的不同可分为顺序表(顺序存储)和链表(链式存储) ...
- 数据结构1:数据结构与算法C语言版分析概述
本节开始将带领大家系统地学习数据结构,作为一门计算机专业大二学生的必修课程,该课程面对的目标人群为初步具备基本编程能力和编程思想的程序员(大一接触了 C 语言或者 C++).通过系统地学习数据结构,可 ...
- 重读《学习JavaScript数据结构与算法-第三版》-第2章 ECMAScript与TypeScript概述
定场诗 八月中秋白露,路上行人凄凉: 小桥流水桂花香,日夜千思万想. 心中不得宁静,清早览罢文章, 十年寒苦在书房,方显才高志广. 前言 洛伊安妮·格罗纳女士所著的<学习JavaScript数据 ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第3章 数组(一)
定场诗 大将生来胆气豪,腰横秋水雁翎刀. 风吹鼍鼓山河动,电闪旌旗日月高. 天上麒麟原有种,穴中蝼蚁岂能逃. 太平待诏归来日,朕与先生解战袍. 此处应该有掌声... 前言 读<学习JavaScr ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第6章 链表(一)
定场诗 伤情最是晚凉天,憔悴厮人不堪言: 邀酒摧肠三杯醉.寻香惊梦五更寒. 钗头凤斜卿有泪,荼蘼花了我无缘: 小楼寂寞新雨月.也难如钩也难圆. 前言 本章为重读<学习JavaScript数据结构 ...
- 数据结构和算法(Java版)快速学习(栈与队列)
栈是仅允许在表尾进行插入和删除操作的线性表.我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom).栈是一种后进先出(Last In First Out)的线性表,简称(LIFO ...
随机推荐
- R学习笔记 第二篇:矩阵、数组和列表
向量是一维的,只有长度(行),没有其他维度.R中存在更高维度的对象,他们是矩阵,数据框,数组.这些对象的下标都是使用中括号[],第一个维度是row,第二个维度是column,依次类推,[row,col ...
- Java基础总结--多线程总结2
----多线程通信-----1.概述:多个线程处理同一个资源,但是各自的任务不相同eg:线程1负责存储数据,线程2负责处理该数据.数据--就是同一个资源怎样用java语言描述上面的例子:* 资源是变化 ...
- 【原创】基于禅道的Bug管理操作规范
1. 禅道简介 禅道是一个基于"敏捷开发"模式的软件开发全生命周期管理软件,在国内的软件开发公司里占据了超过70%的份额,从大公司到小公司,都能适用. 禅道官网:http://ww ...
- js获取当前页面的URL并且截取?之后的数据,返回json
js获取当前页面的URL并且截取'?'之后的数据,返回json格式的数据 最近想要把学到的东西整理一下,以后方便查找,也是一种自我累积,如果有错误或者更好的,欢迎提出! 这篇文档主要是写关于获取页面的 ...
- 读书笔记-你不知道的JS上-对象
好想要对象··· 函数的调用位置不同会造成this绑定对象不同.但是对象到底是什么,为什么要绑定他们呢?(可以可以,我也不太懂) 语法 对象声明有两个形式: 1.字面量 => var obj = ...
- VS2008生成DLL并使用
1.创建工程 2.在工程中添加类,创建.h和.cpp文件 //.h代码 /** 请注意此代码方法声明中的 __declspec(dllexport) 修饰符. 这些修饰符使 DLL 能够导出该方法以供 ...
- ajax跨域请求解决方案
大家好,今天我们学习了js的跨域请求的解决方案,由于JS中存在同源策略,当请求不同协议名,不同端口号.不同主机名下面的文件时,将会违背同源策略,无法请求成功!需要进行跨域处理! 方案一.后台PHP进行 ...
- 【机器学习】TensorFlow学习(一)
感谢中国人民大学胡鹤老师,课讲得非常好~ 首先,何谓tensor?即高维向量,例如矩阵是二维,tensor是更广义意义上的n维向量(有type+shape) TensorFlow执行过程为定义图,其中 ...
- C#的Main(String[] args)参数输入问题
1.新建一个控制台应用程序,保存在桌面上,Main函数如下所示 using System;using System.Collections.Generic;using System.Linq;usin ...
- CLR类型设计之类型之常量和字段
前言 孔子说:温故而知新,可以为师矣.所以对于学习过的知识要多复习,并且每一次复习都要尽可能的去扩展,而不是书本上的几句理论知识.很多人都喜欢分享自己的学习内容,记录下生活的点点滴滴 ...