python 面对post分页爬虫

分享一则对于网抓中面对post请求访问的页面或者在分页过程中需要post请求才可以访问的内容!
面的post请求的网址是不可以零参访问网址的,所以我们在网抓的过程中需要给请求传表单数据,下面看一下网页中post请求的网址:

post请求状态码和get请求的状态码一致,但是在参数中我们可以看到表单数据有很多的参数:
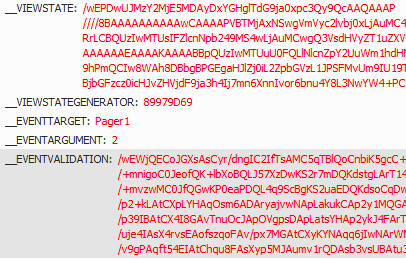
其中的__VIEWSTATE是必须要传的参数,而这个参数是在源码中能获取到的,这个__VIEWSTATE是asp.net中特有的,所以只有在访问asp.net的网站的时候这个参数是必须传的,其他的网站,只要有参数变化的表单数据就需要传到post请求中!
我们在转页的过程中会看到类似于这样的 表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
现在定义一个post_data:
post_data={"__EVENTTARGET":"Pager1","__EVENTARGUMENT":page_num,"ddlManufacturer":"","Pager1_input":str(page_num-1)}
这是我自定义的post参数,page_num代表着分页的页码。
__VIEWSTATE是在源码中,这里分享的是xpath方法:
a = doc.xpath('//input[@id="__VIEWSTATE"]')
if len(a) > 0:
post_data['__VIEWSTATE'] = a[0].get('value')
使用BeautifulSoup就是:
soup = BeautifulSoup(h,"html.parser")
a = soup.find('input',id='__VIEWSTATE')
if a:
post_data['__VIEWSTATE'] = a['value']
获取到重要的表单数据后,我们就只需要传参访问网页源码了!
r2 = requests.post(url,data=post_data,headers=headers,timeout=20)
ht2 = r2.content #这里就是访问的网页源码!
xpath的解析代码: doc2 = HTML.document_fromstring(网页源码)
网页的简单post请求就是这样来传递参数,访问的!我自己还有很多的学习资料分享在607021567qq群里面了!还有微信飞机大战的源代码分享!
python 面对post分页爬虫的更多相关文章
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程
点击了解更多Python课程>>> 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程 适用人群: 即将毕业的大学生,工资低工作重的白领,渴望崭露头角的职场新人, ...
- Python - 面对对象(进阶)
目录 Python - 面对对象(进阶) 类的成员 一. 字段 二. 方法 三. 属性 类的修饰符 类的特殊成员 Python - 面对对象(进阶) 类的成员 一. 字段 字段包括:普通字段和静态字段 ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- 使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道
使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道 使用python/casperjs编写终极爬虫-客户端App的抓取
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(50)--爬虫篇—基础认识
爬虫 1.什么是爬虫 爬虫就是昆虫一类的其中一个爬行物种,擅长爬行. 哈哈,开玩笑,在编程里,爬虫其实全名叫网络爬虫,网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者 ...
- 使用Python + Selenium打造浏览器爬虫
Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操 ...
随机推荐
- JQuery自定义插件详解之Banner图滚动插件
前 言 JRedu JQuery是什么相信已经不需要详细介绍了.作为时下最火的JS库之一,JQuery将其"Write Less,Do More!"的口号发挥的极致.而帮助J ...
- [置顶]
win10 uwp 参考
态度随意申请专栏,没想到通过 看了我的博客,都是在别的大神博客看到,然后修改他们的 我看到的大神博客 东邪独孤 http://www.cnblogs.com/tcjiaan/ 老周,买了他的<W ...
- SpringMVC 配置
1.在WEB-INF\web.xml中定义前端控制器 <servlet> <servlet-name>springmvc</servlet-name> <se ...
- Mysql数据库之auto_increment
一.概述 在数据库应用中,我们经常需要用到自动递增的唯一编号来标识记录.在MySQL中,可通过数据列的auto_increment属性来自动生成.可在建表时可用“auto_increment=n”选项 ...
- Ceph: A Scalable, High-Performance Distributed File System译文
原文地址:陈晓csdn博客 http://blog.csdn.net/juvxiao/article/details/39495037 论文概况 论文名称:Ceph: A Scalable, High ...
- angularJs 个人初探笔记
1.环境搭建与angular - phoneCat 安装可以通过git clone来下载源代码: git clone --depth=14 https://github.com/angular/ang ...
- Golang源码探索(一) 编译和调试源码
GO可以说是近几年最热门的新型语言之一了, 一般人看到分布式和大数据就会想到GO, 这个系列的文章会通过研究golang的源代码来分析内部的实现原理, 和CoreCLR不同的是, golang的源代码 ...
- Code Lock
Code Lock Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) Total Su ...
- 反馈法学习设计模式(一)——策略模式Strategy Pattern
简介(Introduction) 之前学习Java8实战时,遇到一个很好的策略模式示例.便想着借着这个示例结合反馈式的方法来,学习策略设计模式,也以便后面反复琢磨学习. 首先我们通过练习,逐步写出符合 ...
- jumpserver安装详解
环境说明 主机为最小 安装的centos6.9 x86_64. [root@m01 ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [ro ...