Sql Server——查询(二)
上次写了查询里的一些简单的查询方法,如果说上次的是初级查询,那这次的就是高级查询了。
今天主要是聚合函数、分组查询、连接查询、联合查询。在我看来前三个挺简单的,稍微难理解点的也就最后一个,为什么呢?因为在一个查询里面会用到多个查询语句,这样看起来就复杂些,也就难点。
聚合函数
在平时,聚合函数使用率最多的也就那么几个,其它的你有兴趣也可以去了解。
求最大值:max()
求最小值:min()
求总和:sum()
求平均值:avg()
求行数:count()
用法:select 聚合函数 from 表名 如:select count(*) from stuInfo ---->求stuInfo表中的总人数,因为一个人是一行数据,总的行数就是总人数,* 号和前面一样代表所有列,当然,* 号也可以改为要求的列名;如 求一个班的男生总人数: select count(*) from stuInfo where sex='男' ---->这里只需在后面加个where子句就可以了。
注意:聚合函数后面的括号里写的是要求的列名,聚合函数不能和列名一起使用,如 select max(score), stuId(这是一个列名) from stuInfo 这样的写法就是错误的。
分组查询
分组查询需要用到 group by 子句。
如: select count(*) as 人数, sex as 性别 from stuInfo group by sex ----->查询出班上男女人数总数。 查询男女人数分别为多少,我们就可以将数据分为男或女两组,group by 后面写的就是依据什么分组的列名(也就是说根据什么分组我们就写它的列名就可以了)。
再来一个栗子:
查询班上每个人及格的科目数量 首先我们要知道,我们需要的数据是分数大于60的,也就是说,分数小于60的数据我们就要将它过滤掉。 过滤后的数据就是及格的,然后再对它进行分组求和就可以了。
select count(*) as 及格数量, stuid as 学号 from stuInfo
where socre>60 --过滤数据,注意:where子句只能写在group by子句前面且后面不能跟聚合函数
group by stuid --根据学号对现有数据进行分组,求的是每个人的,所以要以学号来分组
最后来个难点的栗子:
上面我们说了where子句不能写在group by 子句后面,那如果我们要先分组后再来求和呢? 比如求班上人及格数量小于3门的人,这里我们就要先用where子句将分数小于60的数据过滤掉,再根据学号对每个人进行分组,分组后我们还要筛选出及格数量小于3门的。既然不能使用where子句,那我们可以使用having子句,专门解决这一问题。
Sql语句为:select count(*) as 数量, stuId as 学号 from stuInfo
where score>60 --过滤不及格的数据
group by stuId --根据学号进行分组
having count(*)<3 --筛选出分组后行数小于3的,也就是及格数量小于3的
having 用于group by 子句后,而且可以跟聚合函数
where子句用于分组前的筛选,不能跟聚合函数;having子句用于分组后的筛选,可以跟聚合函数。
连接查询
我们知道,在数据库中规定一个表只能描述一件事情,那在查询中我们需要查询多个表的内容怎么办呢?这时我们就可以使用连接查询。
连接查询有:内连接、外连接、交叉连接
内连接:(inner join) 查询两个表公共部分
1.等值连接 “=”
select * from 表名一 inner join 表名二 on 表名一.主键=表名二.外键
举个栗子,如下面两张表,现在将它们连接起来
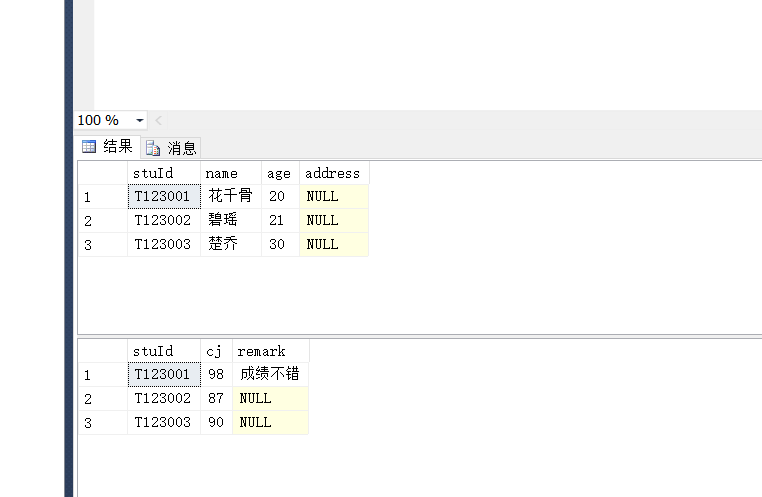
通过等值连接后就是这样
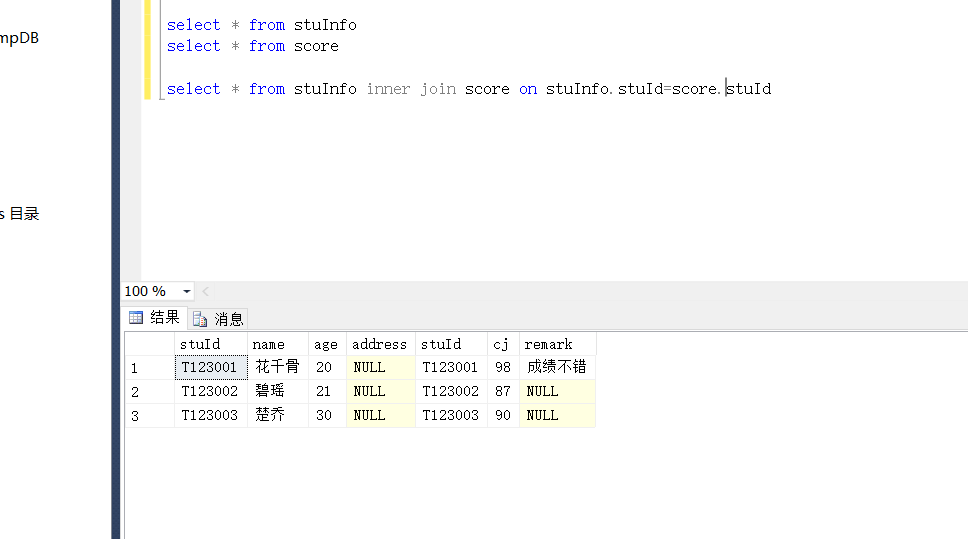
不等连接
概念:在连接条件中使用除等于号之外运算符(>、<、<>、>=、<=、!>和!<)
看看效果吧
<>

>

<
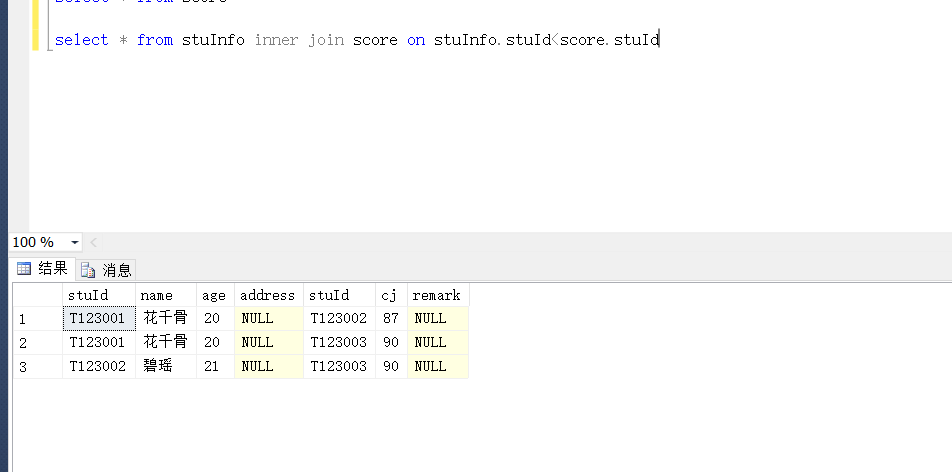
这里就举这几个栗子了,剩下的就你自己去试了。
刚刚已经说了,内连接显示的是两个表的公共部分,即使是空值它也会以NULL代替显示。
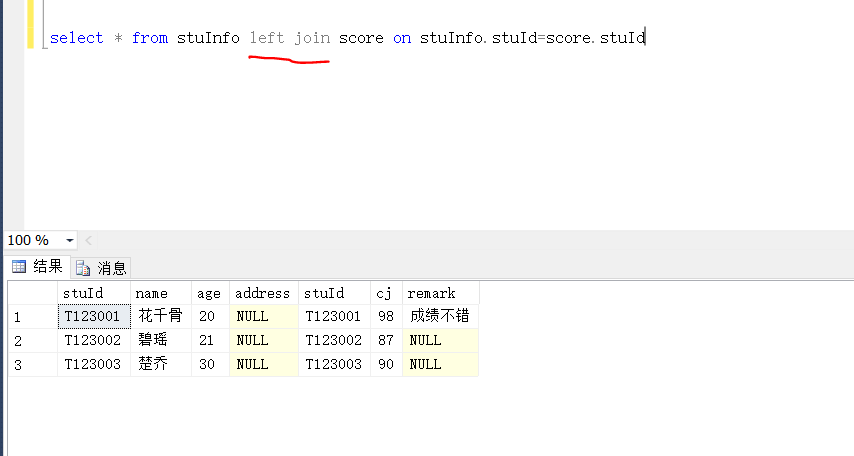
外连接
左连接: 返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
语法上只是大同小异,把inner改为left就可以了
还是上面两个表:
右连接: 恰与左连接相反,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
只需把inner改为right就可以了,这里我就不详细介绍了。
全连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
只需把inner改为full就可以了。
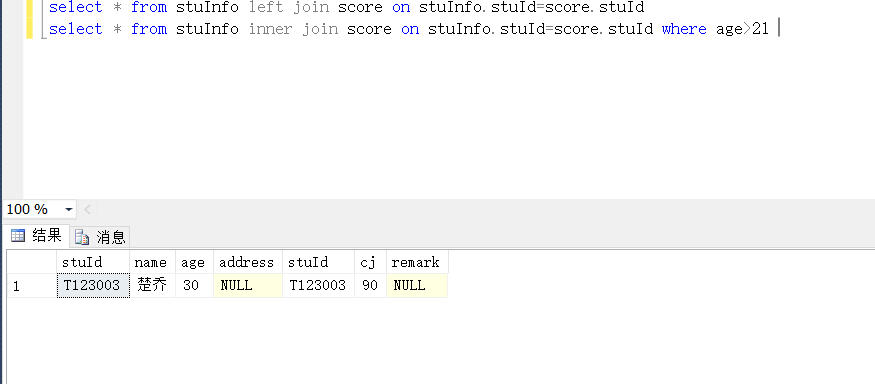
最后就是联合查询,联合查询就是多个查询语句配合使用,写在一个Sql语句里面。
如:查询年龄大于21岁的,我们只需加个where子句进行筛选就可以了。
上面的文章也许你看不懂,但你可以加我QQ 1289747698 和我在线讨论哦!Welcome。
Sql Server——查询(二)的更多相关文章
- SQL Server查询性能优化——堆表、碎片与索引(二)
本文是对 SQL Server查询性能优化——堆表.碎片与索引(一)的一些总结. 第一:先对 SQL Server查询性能优化——堆表.碎片与索引(一)中的例一的SET STATISTICS IO之 ...
- SQL Server查询性能优化——覆盖索引(二)
在SQL Server 查询性能优化——覆盖索引(一)中讲了覆盖索引的一些理论. 本文将具体讲一下使用不同索引对查询性能的影响. 下面通过实例,来查看不同的索引结构,如聚集索引.非聚集索引.组合索引等 ...
- [转] 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SET STATISTICS IO和SET STATISTICS TIME 在SQL Server查询性能优化中的作用
近段时间以来,一直在探究SQL Server查询性能的问题,当然也漫无目的的查找了很多资料,也从网上的大神们的文章中学到了很多,在这里,向各位大神致敬.正是受大神们无私奉献精神的影响,所以小弟也作为回 ...
- 数据库表设计时一对一关系存在的必要性 数据库一对一、一对多、多对多设计 面试逻辑题3.31 sql server 查询某个表被哪些存储过程调用 DataTable根据字段去重 .Net Core Cors中间件解析 分析MySQL中哪些情况下数据库索引会失效
数据库表设计时一对一关系存在的必要性 2017年07月24日 10:01:07 阅读数:694 在表设计过程中,我无意中觉得一对一关系觉得好没道理,直接放到一张表中不就可以了吗?真是说,网上信息什么都 ...
- 如何找出你性能最差的SQL Server查询
我经常会被反复问到这样的问题:”我有一个性能很差的SQL Server.我如何找出最差性能的查询?“.因此在今天的文章里会给你一些让你很容易找到问题答案的信息向导. 问SQL Server! SQL ...
随机推荐
- 两台主机之间单向Ping不通的问题
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px ".PingFang SC"; color: #454545 } p.p2 ...
- Mysql 数据库date, datetime类型设置0000-00-00默认值(default)报错问题
Mysql 数据库date, datetime类型设置0000-00-00默认值报错问题 现象:MySQL5.7版本之后,date, datetime类型设置默认值"0000-00-00&q ...
- Web桌面应用框架2:著名的WEB桌面应用分析
前一篇文章里,分析了包括NW.js和electron这种纯JS框架在内的几种Web桌面应用开发方式,实际上还有一种最古老的方式,那就是嵌入WebView的方式. 嵌入WebView的方式和整个程序都是 ...
- mysql创建字段非空NOT NULL的好处
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt338 很多表都包含可为 NULL (空值) 的列,即使应用程序井不需要保存 ...
- js变量以及其作用域详解
详见: http://blog.yemou.net/article/query/info/tytfjhfascvhzxcytp73 一.变量的类型 Javascript和Java.C这些语言不同 ...
- C# 导出Excel的示例(转)
using System; using System.Collections.Generic; using System.Text; using System.Data; using System.W ...
- 数据库学习任务三:执行数据库操作命令对象SqlCommand
数据库应用程序的开发流程一般主要分为以下几个步骤: 创建数据库 使用Connection对象连接数据库 使用Command对象对数据源执行SQL命令并返回数据 使用DataReader和DataSet ...
- JMeter打开脚本失败 如何解决?
最近有碰到JMeter打开之前的脚本,报错了,见下图: 后来发现这是因为之前保存脚本的 jmeter 和这次打开脚本的 jmeter 版本不一致(图一)或者版本一致而插件没有保持同步(图二)的原因: ...
- FileInputStream 小Demo
要求:设计如下界面 文本框里面可以输入的路径和文件名 单机按钮可以读取在 指定的文件 并把文件内容显示到一个文本域里面来 代码: /** * */ package com.niit.homewo ...
- 201521123070 《JAVA程序设计》第6周学习总结
1. 本章学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 注1:关键词与内容不求多,但概念之间的联系要清晰,内容覆盖 ...