利用子集构造法实现NFA到DFA的转换
概述
NFA非有穷自动机,即当前状态识别某个转换条件后到达的后继状态不唯一,这种自动机不便机械实现,而DFA是确定有限状态的自动机,它的状态转换的条件是确定的,且状态数目往往少于NFA,所以DFA能够比较方便的机械实现且识别能力方面也和NFA相当。本次实验采用子集构造法来实现不带空弧的由NFA到DFA的转换。
子集构造法的算法如下:
设NFA为M=(K,Σ,f,S0,Z),则构造相应的DFA M′=(Q,Σ,f′,I0,F)
①取I0=S0;
②对于状态集Q中任一尚未标记的状态qi={Si1,Si2,…,Sim},Sik∈K,做:
(1) 标记qi;
(2) 对于每个a∈Σ,置
T=f({Si1,Si2,…,Sim},a)
qj=εCLOSURE(T)
(3) 若qj不在Q中,则将qj作为一个未加标记的状态添加到Q中,且把状态转移f′(qi,a)=qj添加到M′。
③重复进行步骤②,直到Q中不再含有未标记的状态为止。对于由此构造的Q,我们把那些至少含有一个Z中的元素的qi作为M′的终态。

对于如图所示的NFA其在文件中保存的信息如下

转成DFA之后的形式为

重命名为

程序整体思路
首先将文件中所给的NFA输入读入程序,在读入过程中将其以图的邻接表的形式保存,其中将状态转移条件记为该边的权值,每种状态记为图的结点,该状态识别状态转移条件(权值)之后到达的状态为该结点的邻接点。
对于上面的例子,将其读入程序中后该图在程序中的逻辑存储结构(图的邻接表)如图所示,其中邻接点中第一个数字表示权值,第二个数字表示所连的结点。

将图读入程序中后,再使用子集构造算法来完成由NFA到DFA的转化。
对于每种状态,其数据结构定义为
typedef struct state
{
set<int> Set;
char name;
}state;
其中set里存放该状态识别某个条件后所能到达的状态集合的下标,name里存该状态重命名后的名字。
这些状态保存在状态数组States[max]中,状态数组States[max]数据结构定义为
state States[max];
子集构造法的过程就是不断向状态数组States[ ]中,添加识别某个条件后,新的未出现的状态的过程。
程序中函数说明
void creatph(algraph &g,FILE *fpr):将文件内容读入程序,并将其转换为图的邻接表子函数。
int change(algraph g,char p):将图中结点转化为对应下标子函数。
state move(state s,int n,algraph g):求当前状态集合的转移集合,即求s状态识别字母n之后的状态集合。
int equalSet(state m,state n):比较两个状态的set集合内容是否相等,不相等返回0,相等返回1。
void inStates(state &s):判断当前状态是否在States数组中存在,若存在,进行改名;若不存在,改名后加入States数组。
void changeToD(algraph g,FILE *fpw):由NFA转到DFA的主控程序子函数。
程序输入如下图所示
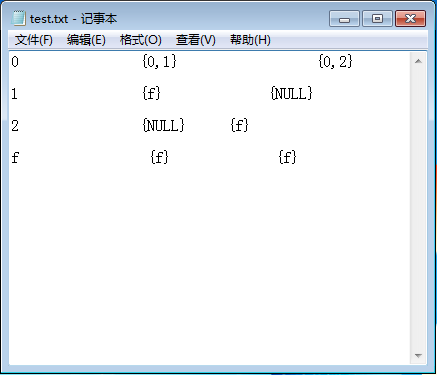
程序输出如下图所示

代码清单
#include<stdio.h>
#include<malloc.h>
#include <iostream>
#include <fstream>
#include <cstring>
#include<set> using namespace std; #define max 50//定义结点最大数量
typedef char vertype;//定义结点值域为字符类型
char buf[];//定义读文件内容时,程序缓冲数组
int num;//记录有穷字母表元素的个数
int length;//记录States数组的长度 typedef struct arcnode//图的边信息
{
int adjvex;
int weight;//边所对应的权值
struct arcnode *next;
}arcnode; typedef struct vnode//图的结点类型定义
{
vertype data;
arcnode *next;
}vnode,adjlist[max]; typedef struct//图的定义
{
adjlist a;
int vexnum,arcnum;
}algraph; typedef struct state//状态的定义
{
set<int> Set;
char name;
}state; state States[max]; int change(algraph g,char p)//将图中结点转化为对应下标
{
int i;
for(i=;i<g.vexnum;i++)
{
if(p==g.a[i].data)
return i;
}
return -;
} void creatph(algraph &g,FILE *fpr)
{
int line = ;
while(!feof(fpr))
{
fgets(buf,,fpr);
if(strlen(buf)>)//获取文件中图的结点个数
{
int i = ;
while(buf[i]==' ')
{
i++;
} g.a[line].data=buf[i];
g.a[line].next=NULL;
line++;
}
}
g.vexnum=line; rewind(fpr);//将文件指针返回到开头位置
line = ;
arcnode *s; while(!feof(fpr))//再次扫描文件将边的信息添上,构造图
{
int weight=;//边所对应的权值,每一行权值都从0开始
fgets(buf,,fpr);
if(strlen(buf)>)
{
for(int i=;i<strlen(buf)-;i++)
{
if(buf[i]=='{')
{
weight++;
if(num<weight)
num=weight; i++;
if(buf[i]=='N')
i=i+; while(buf[i]!='}')
{
if(buf[i]!=',')
{
//cout<<buf[i];////////////////////////////////
int x = change(g,buf[i]); s=(arcnode *)malloc(sizeof(arcnode));
s->adjvex=x;
s->weight=weight;
s->next=g.a[line].next;
g.a[line].next=s;
//cout<<line;////////////////////////////////
}
i++;
}
}
}
line++;
}
} } state move(state s,int n,algraph g)//求当前状态集合的转移集合,即求s状态识别字母n之后的状态集合
{
state temp;
arcnode *m;
set<int>::iterator itr;//迭代器
for(itr = s.Set.begin();itr!=s.Set.end();itr++)//遍历当前s状态中集合元素
{
int i = *itr;
m = g.a[i].next;
while(m)
{
if(m->weight==n)
{
temp.Set.insert(m->adjvex);//cout<<m->adjvex<<" ";
// temp.name=s.name+1;//cout<<temp.name<<endl;
}
m=m->next;
}
}
return temp;
} int equalSet(state m,state n)//比较两个状态的set集合内容是否相等
{
int flag = ;
if(m.Set.size()!=n.Set.size())
{
flag = ;
return flag;
} set<int>::iterator itrm;
set<int>::iterator itrn;
for(itrm = m.Set.begin(),itrn = n.Set.begin();itrm!=m.Set.end();itrm++,itrn++)
{
int m = *itrm;
int n = *itrn; if(m!=n)
{
flag = ;
break;
}
}
return flag;
} void inStates(state &s)//判断当前状态是否在States数组中存在,若存在,进行改名;若不存在,改名后加入States数组
{
int flag = ;
if(length==)
{
States[]=s;
States[].name='A';
length++;
}
else
{
for(int i=;i<length;i++)
{
//cout<<equalSet(States[i],s);
if(equalSet(States[i],s)==)//若存在,进行改名
{
s.name=States[i].name;
flag = ;
break;
}
} if(flag == )//若不存在,改名后加入States数组
{
s.name=States[length-].name+;
States[length]=s;
length++;
}
}
} void changeToD(algraph g,FILE *fpw)
{
state s,temp;
s.Set.insert();
s.name='A'; inStates(s); for(int i=;i<length;i++)
{
cout<<"{";
fprintf(fpw,"{"); set<int>::iterator itr;//迭代器
for(itr = States[i].Set.begin();itr!=States[i].Set.end();itr++)//遍历当前s状态中集合元素
{
int i = *itr;
cout<<g.a[i].data<<",";
fprintf(fpw,"%c,",g.a[i].data);
} cout<<"}";
fprintf(fpw,"}"); cout<<States[i].name;
fprintf(fpw,"%c",States[i].name); for(int j=;j<=num;j++)
{
temp = move(States[i],j,g);
inStates(temp);
//查看temp状态的set集合
/*
set<int>::iterator itr;//迭代器
for(itr = temp.Set.begin();itr!=temp.Set.end();itr++)//遍历当前s状态中集合元素
{
int i = *itr;
cout<<i<<" ";
}*/
cout<<temp.name;
fprintf(fpw,"%c",temp.name);
}
cout<<endl;
fprintf(fpw,"\n");
}
} int main()
{
algraph g; FILE *fpr = fopen("F:\\test.txt","r");
FILE *fpw = fopen("F:\\testOutput.txt","w"); /* FILE *fpr = fopen("test.txt","r");
FILE *fpw = fopen("output.txt","w");*/ creatph(g,fpr); //create测试
/*
for(int i=0;i<g.vexnum;i++)
{
cout<<g.a[i].data<<endl;////////////////// }
*/ changeToD(g,fpw);
//move测试
/*
state s;
s.Set.insert(0);
s.Set.insert(2);
s.Set.insert(3);
s.mark=1;
s.name='B'; move(s,2,g);
*/
return ;
}
利用子集构造法实现NFA到DFA的转换的更多相关文章
- 子集构造法实现NFA的确定化
功能: 采用子集构造算法实现NFA的确定化 输入:读取NFA的文件(文件名test.txt), 文件格式: 第一列表示状态名,第二列和第三列分别表示输入字符a和b到达的状态 输出:确定化后的DFA( ...
- NFA到DFA实例
下面图使用NFA表示的状态转换图, 使用子集构造法,有如下过程, ε-closure(0) = {0, 1, 2, 3, 4, 6, 7}初始值,令为AA = {0, 1, 2, 3, 4, 6, 7 ...
- NFA转DFA - json数字识别
json的主页上,提供了number类型的符号识别过程,如下: 图片引用:http://www.json.org/json-zh.html 实际上这张图片表示的是一个状态机,只是状态没有标出来.因为这 ...
- 计算理论:NFA转DFA的两种方法
本文将以两种方法实现NFA转DFA,并利用C语言实现. 方法二已利用HNU OJ系统验证,方法一迷之WA,但思路应该是对的,自试方案,测试均通过. (主要是思路,AC均浮云,大概又有什么奇怪的Case ...
- 【译】N 皇后问题 – 构造法原理与证明 时间复杂度O(1)
[原] E.J.Hoffman; J.C.Loessi; R.C.Moore The Johns Hopkins University Applied Physics Laboratory *[译]* ...
- 求子串-KPM模式匹配-NFA/DFA
求子串 数据结构中对串的5种最小操作子集:串赋值,串比较,求串长,串连接,求子串,其他操作均可在该子集上实现 数据结构中串的模式匹配 KPM模式匹配算法 基本的模式匹配算法 //求字串subStrin ...
- LeetCode42题,单调栈、构造法、two pointers,这道Hard题的解法这么多?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题的第23篇文章. 今天来看一道很有意思的题,它的难度是Hard,并且有许多种解法. 首先我们来看题面,说是我们有若 ...
- nfa转dfa,正式完成
为了加速转换的处理,我压缩了符号表.具体算法参考任何一本与编译或者自动机相关的书籍. 这里的核心问题是处理传递性闭包,transitive closure,这个我目前采取的是最简单的warshall算 ...
- NFA和DFA区别
一个数据块的访问时间等于寻道时间.旋转延迟时间和数据传输时间三者之和: NFA和DFA区别: 一个状态如A,遇0可以转换到下一个状态B或C,因为选择多所以不确定,因此为不确定的有限自动机: 一个状态还 ...
随机推荐
- ST HW1 An Error
曾经使用ThinkPHP完成一个网上电子银行的项目,凡是涉及到金钱的,需要注意的问题很多,比如使用float类型,比如金钱的数额不能为负数等等.最初没有考虑到剩余金额不能为负数或者消费的金额不能为负, ...
- SQL-with as基本用法(源码DEMO)
DROP TABLE #temp; with cr as ( SELECT At.SysNo AS AtSysNo , ( CASE WHEN At.Source = 1 THEN At.Vendor ...
- C++类对象大小的计算
(一)常规类大小计算 C++类对象计算需要考虑很多东西,如成员变量大小,内存对齐,是否有虚函数,是否有虚继承等.接下来,我将对此举例说明. 以下内存测试环境为Win7+VS2012,操作系统为32位 ...
- ehcache memcache redis 区别
之前用过redis 和 memcache ,没有ehcache 的开发经验,最近也查阅不少文档和博客,写一些总结,也有不少内容总结与诸多博客中的博主总结: Ehcache EhCache 是一个纯J ...
- Sql Server优化---统计信息维护策略
本位出处:http://www.cnblogs.com/wy123/p/5748933.html 首先解释一个概念,统计信息是什么: 简单说就是对某些字段数据分布的一种描述,让SQL Server大概 ...
- HTML学习笔记汇总
笔记几乎涵盖了日常开发中全部的知识点以及相关注意事项 想要学习网页制作的初学者可以通过本篇笔记初步掌握HTML的使用,也可以将该笔记作为查阅资料查看 HTML简单结构 <html> < ...
- 深入理解ajax系列第九篇——jQuery中的ajax
前面的话 jQuery提供了一些日常开发中需要的快捷操作,例如load.ajax.get和post等,使用jQuery开发ajax将变得极其简单.这样开发人员就可以将程序开发集中在业务和用户体验上,而 ...
- [.NET] 一步步打造一个简单的 MVC 电商网站 - BooksStore(三)
一步步打造一个简单的 MVC 电商网站 - BooksStore(三) 本系列的 GitHub地址:https://github.com/liqingwen2015/Wen.BooksStore &l ...
- Java基础—String类小结
一.String类是什么 public final class String implements java.io.Serializable, Comparable<String>, Ch ...
- MongoDB基础教程系列--第四篇 MongoDB 查询文档
查询文档 查询文档可以用 find() 方法查询全部文档,可以用 findOne() 查询第一个文档,当然还可以根据 条件操作符 和 $type操作符 查询满足条件的文档. find() 和 find ...