Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天)
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: https://my.oschina.net/yunshuxueyuan/blog
QQ技术交流群:299142667
一、 问题如何产生
庞老师只讲解了mysql和hdfs,mysq与hive的数据互导,因此决定研究一下将mysql数据直接导入hbase,这时出现了一系列问题。
心酸史:
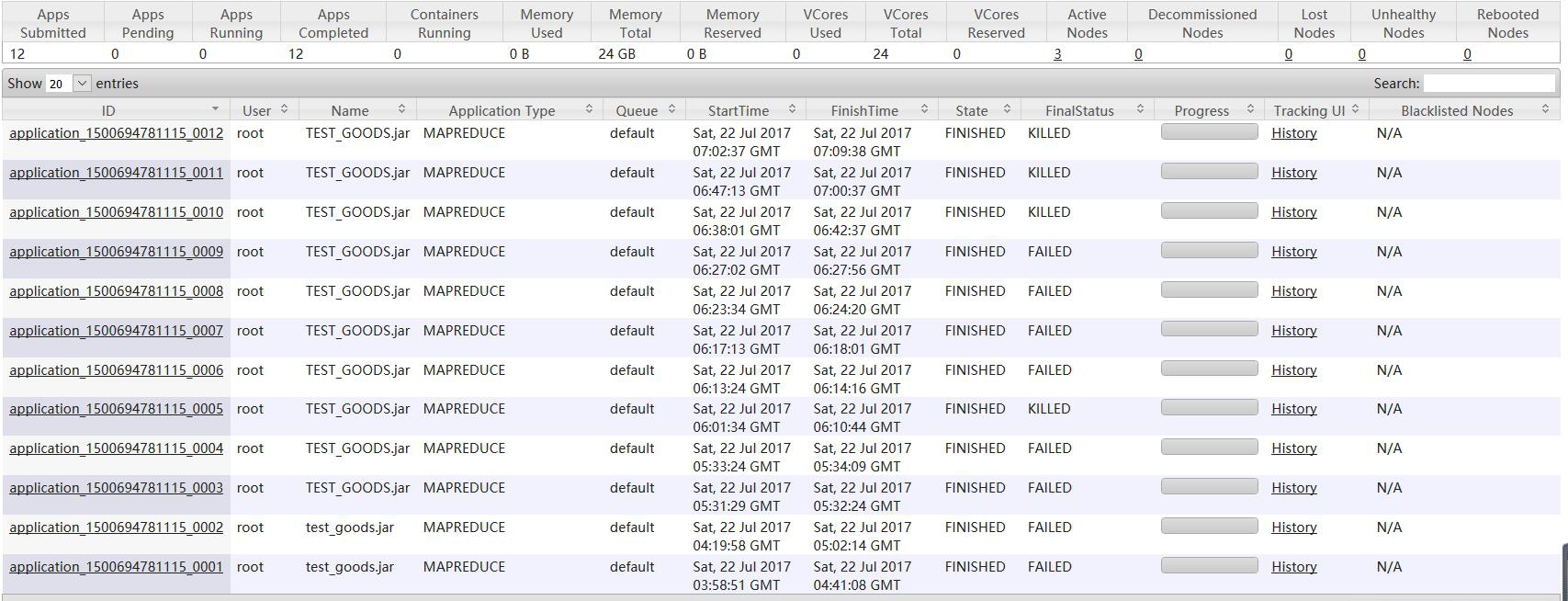
二、 开始具体解决问题
需求:(将以下这张表数据导入mysql)
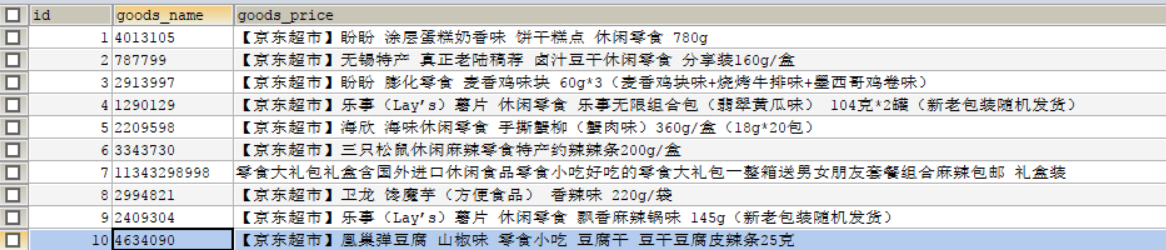
由此,编写如下sqoop导入命令
sqoop import -D sqoop.hbase.add.row.key=true --connect
jdbc:mysql://192.168.1.9/spider --username root --password root
--table test_goods --hbase-create-table --hbase-table t_goods
--column-family cf --hbase-row-key id -m 1

一切看着都很正常,接下来开始执行命令,报如下错误:
1、
Error during import: No primary key could be found for table *
报错原因就是指定的mysql表名不是大写,所以mysql表名必须大写
2、
Could not insert row with null value for row-key column
报错原因是没有指定mysql的列名,所以必须指定列名,并且hbase-row-key id 中的id,必须在–columns中显示。 --columns ID,GOODS_NAME, GOODS_PRICE
3、
Error parsing arguments for import Unrecognized argument
报错原因是在指定mysql的列名时,用逗号隔开的时候我多加了空格,所以在Columns后显示的列名只能用逗号隔开,不要带空格。
将以上三个问题排除后:我的最新导入命令变为如下:
sqoop import -D sqoop.hbase.add.row.key=true --connect
jdbc:mysql://192.168.1.9:3306/spider --username root --password root
--table TEST_GOODS --columns id,goods_name,goods_price
--hbase-create-table --hbase-table t_goods --column-family cf
--hbase-row-key id --where "id >= 5" -m 1
注意:这里有个小问题:记得将id>=5引起来
再次执行导入命令:出现如下情况(卡了好长时间)


发下map执行完成了,但是也就只卡在这里不动了,mapreduce任务一直在后台起着,一段时间后死掉,在这期间不停的执行导入命令和杀掉mapreduce的job
hadoop job -list 查看mapreduce 的job列表
hadoop job -kill job_id 杀死某个Job
经过长时间的测试,突然意识到当前用的是Hbase伪分布式,一下子恍然大悟:
原因:因为当前环境为hbase的伪分布式,所以hbase的数据是存在本地磁盘上的,
并且由自带的zookeeper进行管理。而将mysql数据导入hbase的原理其实就是将数据导入hdfs,所以要想导入成功,存放hbase的数据地址应该在hdfs上才可以。所以如何解决这个问题,我想大家知道了,那就是开启hbase完全分布式。
经过一顿折腾将虚拟机回复到hbase完全分布式的快照,安装好sqoop,进行最终的测试!
最终执行的导入命令如下:(完整的导入命令)
sqoop import -D sqoop.hbase.add.row.key=true --connect
jdbc:mysql://192.168.1.9:3306/spider --username root --password root
--table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE
--hbase-create-table --hbase-table t_goods --column-family cf
--hbase-row-key ID --where "ID >= 5" -m 1
终于见到久违的页面:

查看hbase,数据已经成功导入
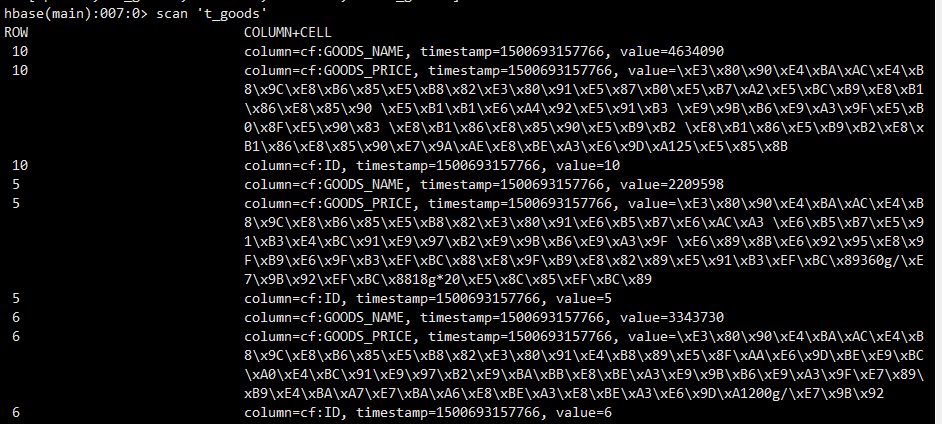
最后我将命令写入一个xxx文件,通过sqoop –options-file xxx 执行导入命令
错误写法如下:
import -D sqoop.hbase.add.row.key=true --connect jdbc:mysql://192.168.1.9:3306/spider --username root --password root --table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE --hbase-create-table --hbase-table test_goods --column-family cf --hbase-row-key ID --where "ID >= 5" -m 1
错误原因:参数的名称和参数的值没有进行回车换行
正确写法:
import -D sqoop.hbase.add.row.key=true --connect jdbc:mysql://192.168.1.9:3306/spider --username root --password root --table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE --hbase-create-table --hbase-table tt_goods --column-family cf --hbase-row-key ID --where ID>=5 -m 1
注:参数含义解释
-D sqoop.hbase.add.row.key=true 是否将rowkey相关字段写入列族中,默认为false,默认情况下你将在列族中看不到任何row key中的字段。注意,该参数必须放在import之后。
--connect 数据库连接字符串
--username –password mysql数据库的用户名密码
--table Test_Goods表名,注意大写
--hbase-create-table 如果hbase中该表不存在则创建
--hbase-table 对应的hbase表名
--hbase-row-key hbase表中的rowkey,注意格式
--column-family hbase表的列族
--where 导入是mysql表的where条件,写法和sql中一样
--split-by CREATE_TIME 默认情况下sqoop使用4个并发执行任务,需要制订split的列,如果不想使用并发,可以用参数 --m 1
到此,bug解决完成!!!
三、知识拓展,定时增量导入
1、Sqoop增量导入
sqoop import -D sqoop.hbase.add.row.key=true --connect
jdbc:mysql://192.168.1.9:3306/spider --username root --password root
--table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE
--hbase-create-table --hbase-table t_goods --column-family cf
--hbase-row-key ID --incremental lastmodified --check-column U_DATE
--last-value '2017-06-27' --split-by U_DATE
--incremental lastmodified 增量导入支持两种模式 append 递增的列;lastmodified时间戳。
--check-column 增量导入时参考的列
--last-value 最小值,这个例子中表示导入2017-06-27到今天的值
2、Sqoop job:
sqoop job --create testjob01 --import --connect
jdbc:mysql://192.168.1.9:3306/spider --username root --password root
--table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE
--hbase-create-table --hbase-table t_goods --column-family cf
--hbase-row-key ID -m 1
设置定时执行以上sqoop job
使用linux定时器:crontab -e
例如每天执行
0 0 * * * /opt/local/sqoop-1.4.6/bin/sqoop job ….
--exec testjob01
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: https://my.oschina.net/yunshuxueyuan/blog
QQ技术交流群:299142667
Sqoop将mysql数据导入hbase的血与泪的更多相关文章
- sqoop将mysql数据导入hbase、hive的常见异常处理
原创不易,如需转载,请注明出处https://www.cnblogs.com/baixianlong/p/10700700.html,否则将追究法律责任!!! 一.需求: 1.将以下这张表(test_ ...
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- 使用 sqoop 将mysql数据导入到hive表(import)
Sqoop将mysql数据导入到hive表中 先在mysql创建表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` varchar() ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- 使用sqoop将mysql数据导入到hive中
首先准备工具环境:hadoop2.7+mysql5.7+sqoop1.4+hive3.1 准备一张数据库表: 接下来就可以操作了... 一.将MySQL数据导入到hdfs 首先我测试将zhaopin表 ...
- 使用sqoop将mysql数据导入到hadoop
hadoop的安装配置这里就不讲了. Sqoop的安装也很简单. 完成sqoop的安装后,可以这样测试是否可以连接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): ...
- python脚本 用sqoop把mysql数据导入hive
转:https://blog.csdn.net/wulantian/article/details/53064123 用python把mysql数据库的数据导入到hive中,该过程主要是通过pytho ...
- Sqoop导入mysql数据到Hbase
sqoop import --driver com.mysql.jdbc.Driver --connect "jdbc:mysql://11.143.18.29:3306/db_1" ...
- 使用sqoop将MySQL数据库中的数据导入Hbase
使用sqoop将MySQL数据库中的数据导入Hbase 前提:安装好 sqoop.hbase. 下载jbdc驱动:mysql-connector-java-5.1.10.jar 将 mysql-con ...
随机推荐
- 脑洞大开--一条项目中常用的linux命令引发的经典算法题
小时候家里定了<读者>的月刊,里面记录一个故事:说有有个偏僻的乡村一日突然来了一个美女,她携着万贯家财子女在当地安家落户,成了当地的乡绅.她让她的子女世世代代的保守这个秘密,直到这个秘密不 ...
- javacpp-opencv图像处理系列:国内车辆牌照检测识别系统(万份测试车牌识别准确率99.7%以上,单次平均耗时39ms)
javaCV图像处理系列: 一.javaCV图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体.位置.大小.粗度.翻转.平滑等操作 二.javaCV图像处理之2:实时视频添 ...
- Dojo初探之2:设置dojoConfig详解,dojoConfig参数详解+Dojo中预置自定义AMD模块的四种方式(基于dojo1.11.2)
Dojo中想要加载自定义的AMD模块,需要先设置好这个模块对应的路径,模块的路径就是这个模块的唯一标识符. 一.dojoConfig参数设置详解 var dojoConfig = { baseUrl: ...
- 如何添加自己封装的代码到Cocoapod
这两天学习了如何添加自己封装的代码到Cocoapod中 以下是我这两天遇到的各种坑: 旧的方法: http://my.oschina.net/u/727843/blog/392784 这个看看可以大 ...
- Navicat11全系列激活(注册机)
Navicat是一款数据库管理工具, 用于简化, 开发和管理MySQL, SQL Server, SQLite, Oracle 和 PostgreSQL 的数据库: Navicat数据模型工具以图形化 ...
- Grunt压缩图片
今天我们来说一下用Grunt来压缩图片和JS吧! 首先要安装插件: 这是压缩图片的; npm install --save-dev gulp-imagemin 这是压缩JS的: npm install ...
- 用php+mysql+ajax实现淘宝客服或阿里旺旺聊天功能 之 后台页面
在上一篇随笔中,我们已经看了如何实现前台的对话功能:前台我限定了店主只有一人,店铺只有一个,所有比较单一,但后台就不一样了,而后台更像是我们常见的聊天软件:当然,前台也应该实现这种效果,但原理懂了,可 ...
- MATLAB仿真中连续和离散的控制器有何区别?
matlab系统同时提供连续和离散的控制器和对象的目的是:在降低用户使用复杂程度的同时提高仿真精度.仿真速度和应用的广泛性. 仿真步长和求解精度的概念对于理解这个问题至关重要. 首先是步长,步长和求解 ...
- IIS虚拟目录与UNC路径权限初探
最近在一个项目中涉及到了虚拟目录与UNC路径的问题,总结出来分享给大家. 问题描述 某客户定制化项目(官网),有一个图片上传的功能.客户的Web机器有10台,通过F5负载均衡分摊请求. 假设这10台机 ...
- 关于Javascript循环体变量声明与初始化的效率问题
针对循环体变量声明与初始化的效率问题,将执行的简单测试代码如下: function test(n) { console.time('Internally initialized'); for (var ...