Python初学——多进程Multiprocessing
1.1 什么是 Multiprocessing
多线程在同一时间只能处理一个任务。
可把任务平均分配给每个核,而每个核具有自己的运算空间。
1.2 添加进程 Process
与线程类似,如下所示,但是该程序直接运行无结果,因为IDLE不支持多进程,在命令行终端运行才有结果显示
import multiprocessing as mp def job(a,b):
print('abc')
if __name__=='__main__':
p1=mp.Process(target=job,args=(1,2))
p1.start()
p1.join()
1.3 存储进程输出 Queue
不知道为什么下面的这个程序可以在IDLE中正常运行。首先定义了一个job函数作系列数学运算,然后将结果放到res中,在main函数运行,取出queue中存储的结果再进行一次加法运算。
import multiprocessing as mp def job(q):
res=0
for i in range(1000):
res+=i+i**2+i**3
q.put(res) if __name__ == '__main__':
q=mp.Queue()
p1 = mp.Process(target=job,args=(q,))#注意当参数只有一个时,应加上逗号
p2 = mp.Process(target=job,args=(q,))
p1.start()
p2.start() p1.join()
p2.join()
res1=q.get()
res2=q.get()
print(res1+res2)
结果如下所示:

1.4 效率比对 threading & multiprocessing
在job函数中定义了数学运算,比较正常情况、多线程和多进程分别的运行时间。
import multiprocessing as mp
import threading as td
import time def job(q):
res = 0
for i in range(10000000):
res += i+i**2+i**3
q.put(res) # queue def multicore():
q = mp.Queue()
p1 = mp.Process(target=job, args=(q,))
p2 = mp.Process(target=job, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
res1 = q.get()
res2 = q.get()
print('multicore:' , res1+res2) def normal():
res = 0
for _ in range(2):#线程或进程都构造了两个,进行了两次运算,所以这里循环两次
for i in range(10000000):
res += i+i**2+i**3
print('normal:', res) def multithread():
q = mp.Queue()
t1 = td.Thread(target=job, args=(q,))
t2 = td.Thread(target=job, args=(q,))
t1.start()
t2.start()
t1.join()
t2.join()
res1 = q.get()
res2 = q.get()
print('multithread:', res1+res2) if __name__ == '__main__':
st = time.time()
normal()
st1= time.time()
print('normal time:', st1 - st)
multithread()
st2 = time.time()
print('multithread time:', st2 - st1)
multicore()
print('multicore time:', time.time()-st2)
在视频中的运行结果是多进程<正常<多线程,而我的运行结果为下图所示:
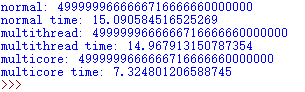
综上,多核/多进程运行最快,说明在同时间运行了多个任务,而多线程却不一定会比正常情况下的运行来的快,这和多线程中的GIL有关。
1.5 进程池
进程池Pool,就是我们将所要运行的东西,放到池子里,Python会自行解决多进程的问题。
import multiprocessing as mp def job(x):
return x*x def multicore():
pool=mp.Pool(processes=2)#定义一个Pool,并定义CPU核数量为2
res=pool.map(job,range(10))
print(res)
res=pool.apply_async(job,(2,))
print(res.get())
multi_res=[pool.apply_async(job,(i,)) for i in range(10)]
print([res.get()for res in multi_res]) if __name__=='__main__':
multicore()
运行结果如下所示:

首先定义一个池子,有了池子之后,就可以让池子对应某一个函数,在上述代码中定义的pool对应job函数。我们向池子里丢数据,池子就会返回函数返回的值。 Pool和之前的Process的不同点是丢向Pool的函数有返回值,而Process的没有返回值。
接下来用map()获取结果,在map()中需要放入函数和需要迭代运算的值,然后它会自动分配给CPU核,返回结果

我们怎么知道Pool是否真的调用了多个核呢?我们可以把迭代次数增大些,然后打开CPU负载看下CPU运行情况
打开CPU负载(Mac):活动监视器 > CPU > CPU负载(单击一下即可)
Pool默认大小是CPU的核数,我们也可以通过在Pool中传入processes参数即可自定义需要的核数量。
Pool除了可以用map来返回结果之外,还可以用apply_async(),与map不同的是,只能传递一个值,只会放入一个核进行计算,但是传入值时要注意是可迭代的,所以在传入值后需要加逗号, 同时需要用get()方法获取返回值。所对应的代码为:
res=pool.apply_async(job,(2,))
print(res.get())
运行结果为4。
由于传入值是可以迭代的,则我们同样可以使用apply_async()来输出多个结果。如果在apply_async()中输入多个传入值:
res = pool.apply_async(job, (2,3,4,))
结果会报错:
TypeError: job() takes exactly 1 argument (3 given)
即apply_async()只能输入一组参数。
在此我们将apply_async()放入迭代器中,定义一个新的multi_res
multi_res = [pool.apply_async(job, (i,)) for i in range(10)]
同样在取出值时需要一个一个取出来
print([res.get() for res in multi_res])
apply用迭代器的运行结果与map取出的结果相同。
note:
(1)Pool默认调用是CPU的核数,传入processes参数可自定义CPU核数
(2)map() 放入迭代参数,返回多个结果
(3)apply_async()只能放入一组参数,并返回一个结果,如果想得到map()的效果需要通过迭代
1.6 共享内存 shared memory
只有通过共享内存才能让CPU之间进行交流。
通过Value将数据存储在一个共享的内存表中。
import multiprocessing as mp
value1 = mp.Value('i', 0)
value2 = mp.Value('d', 3.14)
其中,i和d表示数据类型。i为带符号的整型,d为双精浮点类型。更多数据类型可参考网址:https://docs.python.org/3/library/array.html
在多进程中有一个Array类,可以和共享内存交互,来实现进程之间共享数据。
和numpy中的不同,这里的Array只能是一维的,并且需要定义数据类型否则会报错。
array = mp.Array('i', [1, 2, 3, 4])
1.7 进程锁 Lock
首先是不加进程锁的运行情况,在下述代码中定义了共享变量v,定义了两个进程,均可对v进行操作。job函数的作用是每隔0.1s输出一次累加num的值,累加值num在两个进程中分别为1和3。
import multiprocessing as mp
import time def job(v,num):
for _ in range(10):
time.sleep(0.1)#暂停0.1s,让输出效果更明显
v.value+=num #v.value获取共享变量值
print(v.value) def multicore():
v=mp.Value('i',0)#定义共享变量
p1=mp.Process(target=job,args=(v,1))
p2=mp.Process(target=job,args=(v,3))
p1.start()
p2.start()
p1.join()
p2.join() if __name__=='__main__':
multicore()
运行结果如下所示:
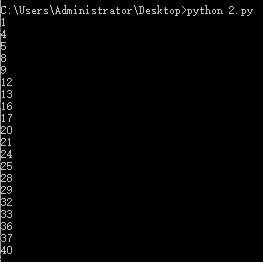
可以看到两个进程互相抢占共享内存v。
为了解决上述不同进程抢共享资源的问题,我们可以用加进程锁来解决。
首先需要定义一个进程锁:
l = mp.Lock() # 定义一个进程锁
然后将进程锁的信息传入各个进程中
p1 = mp.Process(target=job, args=(v,1,l)) # 需要将Lock传入
p2 = mp.Process(target=job, args=(v,3,l))
在job()中设置进程锁的使用,保证运行时一个进程的对锁内内容的独占
def job(v, num, l):
l.acquire() # 锁住
for _ in range(5):
time.sleep(0.1)
v.value += num # v.value获取共享内存
print(v.value)
l.release() # 释放
完整代码:
def job(v, num, l):
l.acquire() # 锁住
for _ in range(5):
time.sleep(0.1)
v.value += num # 获取共享内存
print(v.value)
l.release() # 释放 def multicore():
l = mp.Lock() # 定义一个进程锁
v = mp.Value('i', 0) # 定义共享内存
p1 = mp.Process(target=job, args=(v,1,l)) # 需要将lock传入
p2 = mp.Process(target=job, args=(v,3,l))
p1.start()
p2.start()
p1.join()
p2.join() if __name__ == '__main__':
multicore()
运行结果如下所示:
可以看到进程1运行完之后才运行进程2。
Python初学——多进程Multiprocessing的更多相关文章
- python之多进程multiprocessing模块
process类介绍 multiprocessing 模块官方说明文档 Process 类用来描述一个进程对象.创建子进程的时候,只需要传入一个执行函数和函数的参数即可完成 Process 示例的创建 ...
- python中多进程multiprocessing、多线程threading、线程池threadpool
浅显点理解:进程就是一个程序,里面的线程就是用来干活的,,,进程大,线程小 一.多线程threading 简单的单线程和多线程运行:一个参数时,后面要加逗号 步骤:for循环,相当于多个线程——t=t ...
- Python 多进程multiprocessing
一.python多线程其实在底层来说只是单线程,因此python多线程也称为假线程,之所以用多线程的意义是因为线程不停的切换这样比串行还是要快很多.python多线程中只要涉及到io或者sleep就会 ...
- python ---多进程 Multiprocessing
和 threading 的比较 多进程 Multiprocessing 和多线程 threading 类似, 他们都是在 python 中用来并行运算的. 不过既然有了 threading, 为什么 ...
- python学习笔记——multiprocessing 多进程组件 进程池Pool
1 进程池Pool基本概述 在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量时间,如果操作的对象数目不大时,还可以直接适用Process类动态生成 ...
- python多进程-----multiprocessing包
multiprocessing并非是python的一个模块,而是python中多进程管理的一个包,在学习的时候可以与threading这个模块作类比,正如我们在上一篇转载的文章中所提,python的多 ...
- python 3 并发编程之多进程 multiprocessing模块
一 .multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程. ...
- python多进程multiprocessing Pool相关问题
python多进程想必大部分人都用到过,可以充分利用多核CPU让代码效率更高效. 我们看看multiprocessing.pool.Pool.map的官方用法 map(func, iterable[, ...
- 操作系统OS,Python - 多进程(multiprocessing)、多线程(multithreading)
多进程(multiprocessing) 参考: https://docs.python.org/3.6/library/multiprocessing.html 1. 多进程概念 multiproc ...
随机推荐
- 50行代码实现的高性能动画定时器 raf-interval
写在前面 raf-interval 是基于 window.requestAnimationFrame() 封装的定时器. Github: https://github.com/dntzhang/raf ...
- 获取cpu真实型号
感谢文洋兄的思路.亲测有效. [root@storage GetCpuType]# ./main.o Intel(R) Xeon(R) CPU C5528 @ 2.13GHz #include < ...
- ES6中的Set和Map集合
前面的话 在ES6标准制定以前,由于可选的集合类型有限,数组使用的又是数值型索引,因而经常被用于创建队列和栈.如果需要使用非数值型索引,就会用非数组对象创建所需的数据结构,而这就是Set集合与Map集 ...
- 【PHP】数据类型转换
PHP的数据类型转换属于强制转换,允许转换的PHP数据类型有: (int).(integer):转换成整形 (float).(double).(real):转换成浮点型 (string):转换成字符串 ...
- Django中ORM模型总结(一)[概述,查询语句]
理解ORM框架 概述 O:(objects)->类和对象. R:(Relation)->关系,关系数据库中的表格. M:(Mapping)->映射. 作用: 可以通过类和类对象就可以 ...
- 看望朋友(家达)--->>对事情的专注及时间效率学习
本意是想去堕落街吃完饭就回寝室休息了,结果偶遇尹阳,便说是一同去走走.路上边走边聊,我便提议去十教楼顶,十教是全学校最高的教学楼,这也是刘智学长给我说的.在十教楼顶的那种感觉,特别想吹口琴,可惜没有带 ...
- Hadoop - 国内各站点最高温度、气压和风速统计
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处(http://www.cnblogs.com/mikevictor07/),以下内容为个人理解,仅供参考. 一.简介 该实例统计国内 ...
- C——Network Saboteur (POJ2531)
题目: A university network is composed of N computers. System administrators gathered information on t ...
- Redis-位图法实现简单统计
比如一个网站有1亿个用户, 现在要统计一周内连续登录的用户 方法: 可以用一个字节8个位表示7个人, 首位不算固定为0, 若某人周一登录则置为1, 没登录则为0 127.0.0.1:6379> ...
- springMVC两种方式实现多文件上传及效率比较
springMVC实现 多文件上传的方式有两种,一种是我们经常使用的以字节流的方式进行文件上传,另外一种是使用springMVC包装好的解析器进行上传.这两种方式对于实 现多文件上传效率上却有着很大的 ...