storm从入门到放弃(一),storm介绍
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了20多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来。

Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理。
Storm核心组件

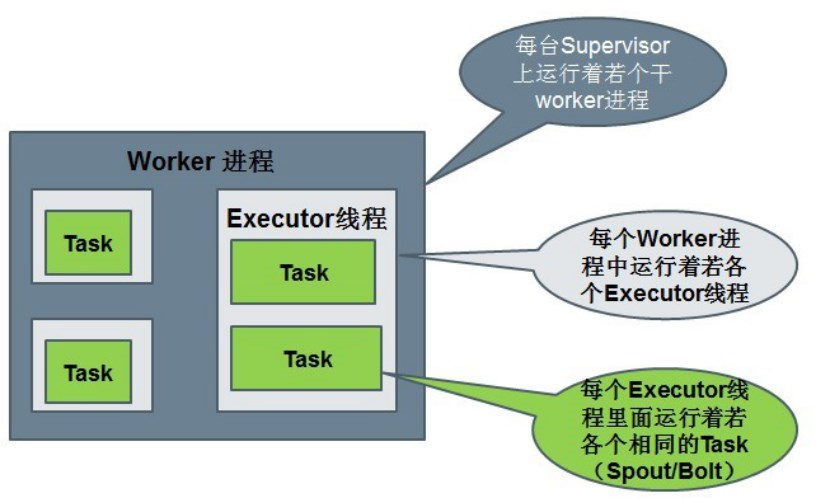
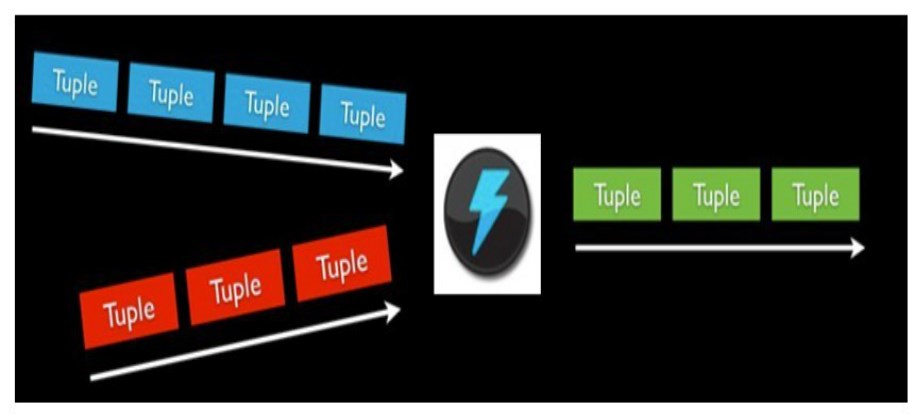
Storm编程模型

public class RandomSentenceSpout extends BaseRichSpout {
public void nextTuple() {
collector.emit(new Values("+ - * % /"));
Utils.sleep(50000);
}
......
}
public class SplitSentenceBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = (String)input.getValueByField("intsmaze");
System.out.println(Thread.currentThread().getId()+" "+sentence);
}
......
}
public class TwoBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = (String)input.getValueByField("intsmaze");
System.out.println(Thread.currentThread().getId()+" "+sentence);
}
......
}
public class WordCountTopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout1", new RandomSentenceSpout(),1);
builder.setBolt("two", new TwoBolt(),1).shuffleGrouping("spout1");
builder.setBolt("split1", new SplitSentenceBolt(),2).shuffleGrouping("spout1");
Config conf = new Config();
conf.setDebug(false);
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
}
}
}
可以发现spout每隔一段时间间隔发一份数据,这份数据会被两个bolt同时接收,而不是说这次A bolt接收下次B bolt接收。 同一个bolt业务逻辑如果设置了并行度,他们才会根据分组策略依次接收上游发来的消息。
----------------84 + - * % / 这个是tow bolt接收
----------------78 + - * % / 这个是split1 bolt 中78线程接收的
----------------80 + - * % / 这个是split1 bolt中线程80接收的。
----------------84 + - * % /
----------------78 + - * % /
----------------84 + - * % /
Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
conf.setNumWorkers(4) 表示设置了4个worker来执行整个topology的所有组件
builder.setBolt("boltA-intsmaze",new BoltA(), 4) ---->指明 boltA组件的线程数excutors总共有4个
builder.setBolt("boltB-intsmaze",new BoltB(), 4) ---->指明 boltB组件的线程数excutors总共有4个
builder.setSpout("randomSpout-intsmaze",new RandomSpout(), 2) ---->指明randomSpout组件的线程数excutors总共有2个
-----意味着整个topology中执行所有组件的总线程数为4+4+2=10个
----worker数量是4个,有可能会出现这样的负载情况,worker-1有2个线程,worker-2有2个线程,worker-3有3个线程,worker-4有3个线程
如果指定某个组件的具体task并发实例数
builder.setSpout("randomspout-intsmaze", new RandomWordSpout(), 4).setNumTasks(8);
----意味着对于这个组件的执行线程excutor来说,一个excutor将执行8/4=2个task,默认情况一个线程执行一个task.
storm从入门到放弃(一),storm介绍的更多相关文章
- Storm编程入门API系列之Storm的Topology多个Workers数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 继续编写 StormTopologyMoreWorker.java ...
- Storm编程入门API系列之Storm的Topology多个Executors数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的Topology多个tasks数目控制实现
前期博客 Storm编程入门API系列之Storm的Topology默认Workers.默认executors和默认tasks数目 Storm编程入门API系列之Storm的Topology多个Wor ...
- Storm编程入门API系列之Storm的定时任务实现
概念,见博客 Storm概念学习系列之storm的定时任务 Storm的定时任务,分为两种实现方式,都是可以达到目的的. 我这里,分为StormTopologyTimer1.java 和 Sto ...
- Storm编程入门API系列之Storm的Topology的stream grouping
概念,见博客 Storm概念学习系列之stream grouping(流分组) Storm的stream grouping的Shuffle Grouping 它是随机分组,随机派发stream里面的t ...
- Storm编程入门API系列之Storm的Topology默认Workers、默认executors和默认tasks数目
关于,storm的启动我这里不多说了. 见博客 storm的3节点集群详细启动步骤(非HA和HA)(图文详解) 建立stormDemo项目 Group Id : zhouls.bigdata Art ...
- Storm编程入门API系列之Storm的可靠性的ACK消息确认机制
概念,见博客 Storm概念学习系列之storm的可靠性 什么业务场景需要storm可靠性的ACK确认机制? 答:想要保住数据不丢,或者保住数据总是被处理.即若没被处理的,得让我们知道. publi ...
- storm从入门到放弃(二),任务分配过程-核心机密
背景:目前就职于国内最大的IT咨询公司,恰巧又是毕业季,所在部门招了100多个应届毕业生,本人要跟部门新人进行为期一个月的大数据入职培训,特此将整理的文档分享出来. 原文和作者一起讨论:http:// ...
- storm从入门到放弃(三),放弃使用《StreamId》特性。
序:StreamId是storm中实现DAG有向无环图的重要一个特性,但是从实际生产环境来看,这个功能其实蛮影响生产环境的稳定性的,我们系统在迭代时会带来整体服务的不可用. StreamId是stor ...
随机推荐
- Angular JS从入门基础 mvc三层架构 常用指令
Angular JS从入门基础 mvc模型 常用指令 ★ 最近一直在复习AngularJS,它是一款优秀的前端JS框架,已经被用于Google的多款产品当中.AngularJS有着诸多特性,最为核心 ...
- MFC简单绘制安卓机器人
原始日期:2014-03-29 20:35 众所周知,google的安卓机器人形象十分经典,包括眼睛的位置,胳膊以及天线的位置都是有固定位置和比例的,而且是最恰当的,看起来最美.而微软基础类库MFC绘 ...
- Rest模式get,put,post,delete含义与区别(转)
POST /uri 创建 DELETE /uri/xxx 删除 PUT /uri/xxx 更新或创建 GET /uri/xxx 查看 GET操作是安全的.所谓安全是指不管进行多 ...
- 各开放平台API接口通用 SDK 前言
最近两年一直在做API接口相关的工作,在平时工作中以及网上看到很多刚接触API接口调用的新人一开始会感到很不适应,包括自己刚开始做API接口调用的相关工作时,也是比较抓狂的,所有写一序列文章把之前的工 ...
- c++课程设计之菜单选择
a) 从键盘输入n个数,选择升序还是降序输出 b)创新了日历 c) 添加了射箭游戏 d)还加入了好玩的24点游戏 学生签名: 年 月 日 课程设计(论文)评阅意见 等 级 项 ...
- Linux 最新SO_REUSEPORT特性
1.前言 昨天总结了一下Linux下网络编程“惊群”现象,给出Nginx处理惊群的方法,使用互斥锁.为例发挥多核的优势,目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景: ...
- java高并发锁的3种实现
初级技巧 - 乐观锁 乐观锁适合这样的场景:读不会冲突,写会冲突.同时读的频率远大于写. 以下面的代码为例,悲观锁的实现: Java代码 public Object get(Object key) ...
- Swift自增和自增运算
自增和自增运算 和 C 语言一样,Swift 也提供了方便对变量本身加1或减1的自增(++)和自减(--)的运算符.其操作对象可以是整形和浮点型. var i = ++i // 现在 i = 1 ...
- [leetcode-625-Minimum Factorization]
Given a positive integer a, find the smallest positive integer b whose multiplication of each digit ...
- 1.如何安装matlab2016a
下载:见网盘 安装教程: 解压安装文件,安装文件为 iso 格式,但是不能通过虚拟光驱安装,需要将 iso 文件用解压软件解压.注意,R2016b_win64_dvd1.iso 和 R2016b_wi ...