python3--网络爬虫--爬取图片
网上大多爬虫仍旧是python2的urllib2写的,不过,坚持用python3(3.5以上版本可以使用异步I/O)
相信有不少人爬虫第一次爬的是Mm图,网上很多爬虫的视频教程也是爬mm图,看了某人的视频后,把这个爬虫给完成了
因为爬取的内容涉及个人隐私,所以,爬取的代码及网址不在此公布,不过介绍一下爬取的经验:
1.我们首先得了解我们要爬取的是什么,在哪爬取这些信息,不要着急想用什么工具,怎么搞,怎么搞得
2.手动操作一遍爬虫要完成的任务,我这个就是爬图片的,可以自己操作一遍
3.打开抓包软件或者Google的F12调试工具,查看数据,了解请求过程中的信息,如网址,发送请求的数据
大概了解以上信息后,可以开始编写爬虫了(个人经验,大牛勿喷,,,)
介绍python3用于爬虫的模块及方法:
可以查看官方的API文档,看懂文档,下面的就不用看了
urllib包:在python2中urllib和urllib2是分开的,python3合并在了一起,强调,这是个包,所以很多函数不一样了,但是还是那个味道
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsingrobots.txtfiles
这四个模块中urllib.request是常用的,urllib.parse中urlencode()也是会用到的
在urllib.request中,常用的方法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
headers参数,如果不想很容易被服务器发现,那么最起码加个user-agent吧,当然,你可以设置代理ip
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
将请求发送的data字典转化为str,经过编码,data成了(get请求不用)
在爬取的过程中,正则表达式一定会用到,推荐一款软件:MTracer,可以自己尝试写正则: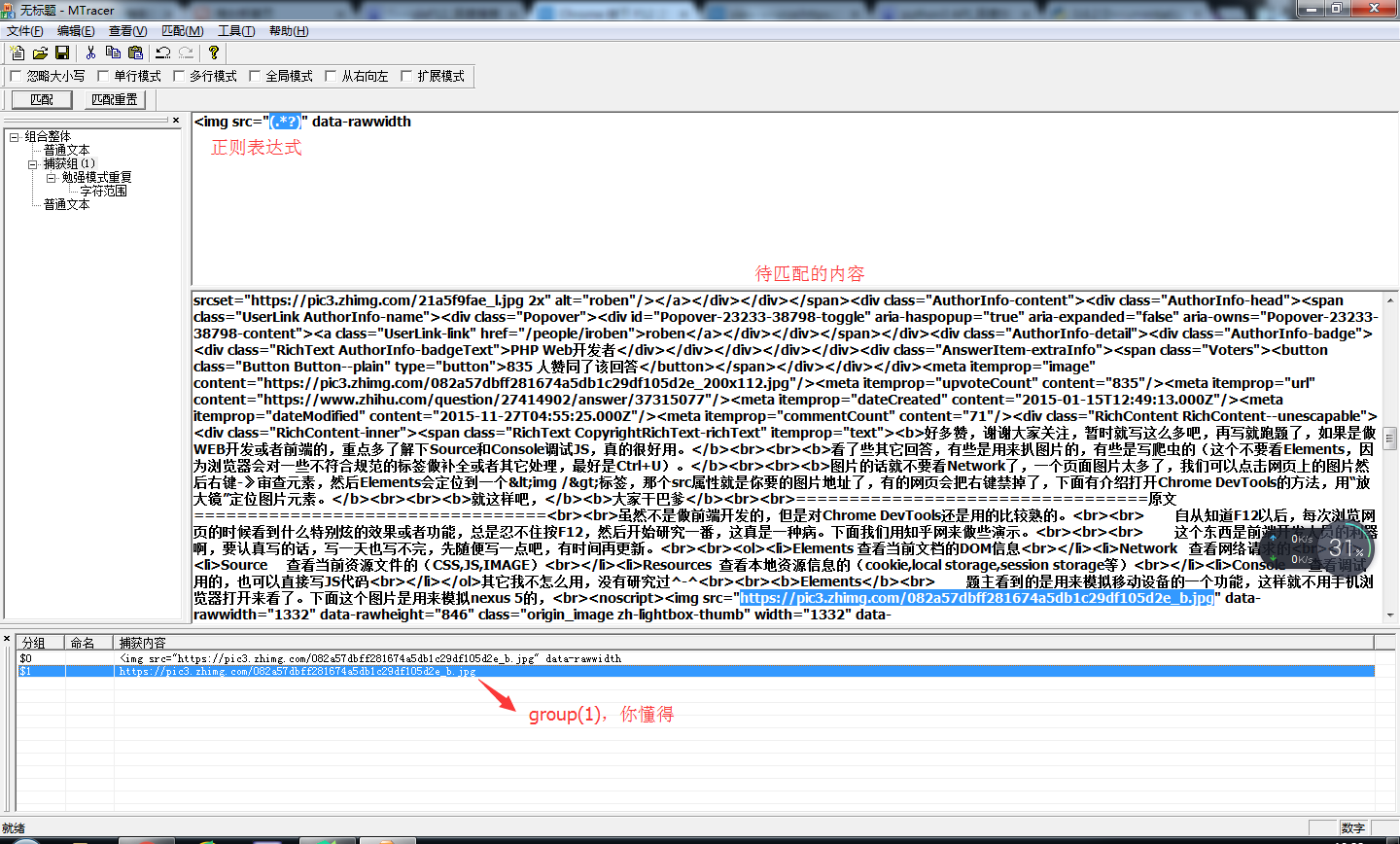
还是很不错的,谁爬谁知道
python3--网络爬虫--爬取图片的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫(四):使用User Agent和代理IP隐藏身份《转》
https://blog.csdn.net/c406495762/article/details/60137956 运行平台:Windows Python版本:Python3.x IDE:Sublim ...
随机推荐
- sublime 设置字体
通过菜单Preferences/Settings - User,添加下面这行配置就可以修改字体: "font_face": "Courier New", &qu ...
- 【项目1-1】使用HTML5+CSS3绘制HTML5的logo
作为一个WEB小萌新,自学了有一段时间,总是感觉停滞不前.最近反思中,想到前贤一句话:书读百遍其义自见.说到底,还是项目做的少,如果做多了,想必自然会得心应手. 利用HTML5+CSS3绘制HTML5 ...
- php imagemagick 处理 图片剪切、压缩、合并、插入文本、背景色透明
php有一款插件叫做imagemagick,功能很强大,提供了图片的很多操作,图片剪切.压缩.合并.插入文本.背景色透明等.并且有api方法调用和命令行操作两种方式,如果只是简单处理的话建议api方法 ...
- web项目直接在浏览器上访问不需要带.jsp,直接ip地址加项目名 在web.xml里配置
web.xml最上方 <welcome-file-list> <welcome-file> /view/login.jsp </welcome-file> < ...
- 【干货】Chrome插件(扩展)开发全攻略(不点进来看看你肯定后悔)
写在前面 我花了将近一个多月的时间断断续续写下这篇博文,并精心写下完整demo,写博客的辛苦大家懂的,所以转载务必保留出处.本文所有涉及到的大部分代码均在这个demo里面:https://github ...
- HTML5性能优化[转]
在看完这两章内容之后,我意犹未尽,于是乎从网上搜索关键字“Java Web高性能”,在IBM社区找到两篇不错的文章,而让人更意外的是我发现那两篇文章的内容跟<高性能HTML5>前两章高度相 ...
- Randoop测试类和方法(用例自动生成)
详细使用方法见randoop官网: https://randoop.github.io/randoop/manual/index.html 测试程序之前,先检测下你的Randoop是否配置好: 打开c ...
- 一颗简单的JDBC栗子
前言:安装好数据库之后,我们编写的java程序是不能直接使用数据库的,而JDBC(Java Database Connectivity,即java数据库连接)是java语言里用来规范客户端程序访问数据 ...
- SSH连不上虚拟机的问题解决
这几天工作任务不重,今早上班打算在liunx下运行下python脚本.打开VM,SSH突然连不上虚拟机了.网上试了很多方法都不行,最后花费2个小时解决了这一问题. 结合我的实际情况,问题解决如下: 1 ...
- rsync安装及其配置
服务端配置安装 服务器 第一步: 下载rsync 安装包(在线安装或者线下安装) wget https://download.samba.org/pub/rsync/rsync-3.1 ...