Hadoop源码篇--Client源码
一。前述
今天起剖析源码,先从Client看起,因为Client在MapReduce的过程中承担了很多重要的角色。
二。MapReduce框架主类
代码如下:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
//job 作业
Job job = Job.getInstance(conf);
// Create a new Job
// Job job = Job.getInstance();
job.setJarByClass(MyWC.class);
// Specify various job-specific parameters
job.setJobName("myjob");
// job.setInputPath(new Path("in"));
// job.setOutputPath(new Path("out"));
Path input = new Path("/user/root");
FileInputFormat.addInputPath(job, input );
Path output = new Path("/output/wordcount");
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output );
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
第一步,先分析Job,可以看见源码中Job实现了public class Job extends JobContextImpl implements JobContext
然后JobContext实现了 MRJobConfig,可以看见其中有很多配置
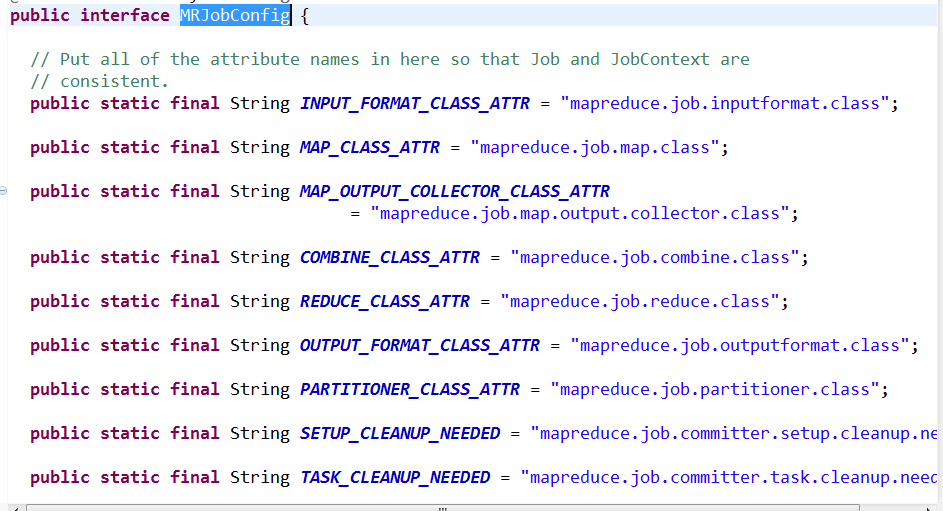
因为job中传的参数为conf,所以这里的配置即对应我们的配置文件中的属性值。
Job job = Job.getInstance(conf);
挑几个重要的看下:
public static final int DEFAULT_MAP_MEMORY_MB = 1024;//默认的Mapper任务内存大小。
第二步,分析提交过程 job.waitForCompletion(true); 追踪源码发现主要实现这个类
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException
- Checking the input and output specifications of the job.//检查输入输出路径
- Computing the
InputSplits for the job.//检查切片 - Setup the requisite accounting information for the
DistributedCacheof the job, if necessary. - Copying the job's jar and configuration to the map-reduce system directory on the distributed file-system.
- Submitting the job to the
JobTrackerand optionally monitoring it's status.
在此方法中,中重点看下此方法 int maps = writeSplits(job, submitJobDir);
追踪后具体实现可知
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); // sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
追踪job.getInputFormatClass()可以发现如下代码: public Class<? extends InputFormat<?,?>> getInputFormatClass()
throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
//根据用户配置文件首先取用,如果没有被取用则使用默认输入格式TextInputFormat
}
所以可得知用户的默认输入类是TextInputformat类并且继承关系如下:
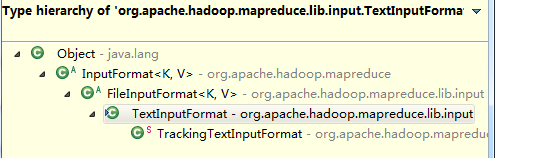
TextInputforMat-->FileinputFormat-->InputFormat
追踪 List<InputSplit> splits = input.getSplits(job);可以得到如下源码:
最为重要的一个源码!!!!!!!!!!!
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));如果用户设置则取用户,没有是1
long maxSize = getMaxSplitSize(job);//如果用户设置则取用户,没有取最大值
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();//取输入文件的大小和路径
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);//获得所有块的位置。
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);//获得切片大小
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);//这一块传参传的是切块的偏移量,返回这个块的索引
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),//根据当前块的索引号取出来块的位置包括副本的位置 然后传递给切片,然后切片知道往哪运算。即往块的位置信息计算
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
1.long splitSize = computeSplitSize(blockSize, minSize, maxSize);追踪源码发现
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
切片大小默认是块的大小!!!!
假如让切片大小 < 块的大小则更改配置的最大值MaxSize,让其小于blocksize
假如让切片大小 > 块的大小则更改配置的最小值MinSize,让其大于blocksize
通过FileInputFormat.setMinInputSplitSize即可。
2. int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining) 追踪源码发现
protected int getBlockIndex(BlockLocation[] blkLocations,
long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){//切片要大于>=块的起始量,小于一个块的末尾量。
return i;//返回这个块
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +
" is outside of file (0.." +
fileLength + ")");
}
3. splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()
创建切片的时候,一个切片对应一个mapperr任务,所以创建切片的四个位置(path,0,10,host)
根据host可知mapper任务的计算位置,则对应计算向数据移动!!!!块是逻辑的,并没有真正切割数据。!!
4.上述getSplits方法最终得到一个切片的清单,清单的数目就是mapper的数量!!即开始方法的入口 int maps = writeSplits(job, submitJobDir);返回值。
5.计算向数据移动时会拉取只属于自己的文件。
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Hadoop源码篇--Client源码的更多相关文章
- MyBatis 源码篇-MyBatis-Spring 剖析
本章通过分析 mybatis-spring-x.x.x.jar Jar 包中的源码,了解 MyBatis 是如何与 Spring 进行集成的. Spring 配置文件 MyBatis 与 Spring ...
- MyBatis 源码篇-Transaction
本章简单介绍一下 MyBatis 的事务模块,这块内容比较简单,主要为后面介绍 mybatis-spring-1.**.jar(MyBatis 与 Spring 集成)中的事务模块做准备. 类图结构 ...
- MyBatis 源码篇-DataSource
本章介绍 MyBatis 提供的数据源模块,为后面与 Spring 集成做铺垫,从以下三点出发: 描述 MyBatis 数据源模块的类图结构: MyBatis 是如何集成第三方数据源组件的: Pool ...
- MyBatis 源码篇-插件模块
本章主要描述 MyBatis 插件模块的原理,从以下两点出发: MyBatis 是如何加载插件配置的? MyBatis 是如何实现用户使用自定义拦截器对 SQL 语句执行过程中的某一点进行拦截的? 示 ...
- MyBatis 源码篇-日志模块2
上一章的案例,配置日志级别为 debug,执行一个简单的查询操作,会将 JDBC 操作打印出来.本章通过 MyBatis 日志部分源码分析它是如何实现日志打印的. 在 MyBatis 的日志模块中有一 ...
- MyBatis 源码篇-日志模块1
在 Java 开发中常用的日志框架有 Log4j.Log4j2.Apache Common Log.java.util.logging.slf4j 等,这些日志框架对外提供的接口各不相同.本章详细描述 ...
- MyBatis 源码篇-资源加载
本章主要描述 MyBatis 资源加载模块中的 ClassLoaderWrapper 类和 Java 加载配置文件的三种方式. ClassLoaderWrapper 上一章的案例,使用 org.apa ...
- MyBatis 源码篇-SQL 执行的流程
本章通过一个简单的例子,来了解 MyBatis 执行一条 SQL 语句的大致过程是怎样的. 案例代码如下所示: public class MybatisTest { @Test public void ...
- MyBatis 源码篇-整体架构
MyBatis 的整体架构分为三层, 分别是基础支持层.核心处理层和接口层,如下图所示. 基础支持层 反射模块 该模块对 Java 原生的反射进行了良好的封装,提供了更加简洁易用的 API ,方便上层 ...
随机推荐
- LABjs、RequireJS、SeaJS 哪个最好用?为什么?
感谢玉伯在知乎的奉献,下面全文转载:http://www.zhihu.com/question/20342350/answer/14828786 LABjs 的核心是 LAB(Loading and ...
- Hadoop 少量map/reduce任务执行慢问题
最近在做报表统计,跑hadoop任务. 之前也跑过map/reduce但是数据量不大,遇到某些map/reduce执行时间特别长的问题. 执行时间长有几种可能性: 1. 单个map/reduce任务处 ...
- hdu 5225 Tom and permutation(回溯)
题目链接:hdu 5225 Tom and permutation #include <cstdio> #include <cstring> #include <algo ...
- uva11059(最大乘积)
Problem D - Maximum Product Time Limit: 1 second Given a sequence of integers S = {S1, S2, ..., Sn}, ...
- 负载均衡之基于L7负载
L7负载平衡 还有一种较为经常使用的负载平衡解决方式则是L7负载平衡.顾名思义,其主要通过OSI模型中的第七层应用层中的数据决定怎样分发负载. 在执行时.L7负载平衡server上的操作系统会将接收到 ...
- IntelliJ IDEA(五) :Settings(中)
上篇介绍了Settings中的Appearance & Behavior和Keymap,这篇继续,将介绍Editor,Plugins,Version Control. 一.Editor(编辑) ...
- 十二、 Spring Boot 静态资源处理
spring Boot 默认为我们提供了静态资源处理,使用 WebMvcAutoConfiguration 中的配置各种属性. 建议大家使用Spring Boot的默认配置方式,如果需要特殊处理的再通 ...
- 使用Mkdocs构建你的项目文档
使用Mkdocs构建你的项目文档 环境搭建 安装必需软件 作者是在windows下安装的,如果是linux或mac用户,官网有更详细的安装说明. windows 10 x64 当然还有广大的windo ...
- Django的Form
Django的Form有两个基本用途: 1.用于生成html的Form表单 2.用于后台做表单验证 #!/usr/bin/env python # -*- coding:utf-8 -*- impor ...
- MyBatis:lazy loading
懒加载的原理 mybatis 会循环处理结果集中返回的每行数据的,在处理之前首先会通过反射调用构造方法来创建 result 对象,结果集中的一行数据最终会映射为一个 result 对象(严格的来说是不 ...