CoolBlog开发笔记第4课:数据库模型设计
教程目录
1.3 CoolBlog开发笔记第3课:创建Django应用
前言
我新书《Python爬虫开发与项目实战》出版了。 这本书包括基础篇,中级篇和深入篇三个部分,不仅适合零基础的朋友入门,也适合有一定基础的爬虫爱好者进阶,如果你不会分布式爬虫,不会千万级数据的去重,不会怎么突破反爬虫,不会分析js的加密,这本书会给你惊喜。如果大家对这本书感兴趣的话,可以看一下 试读样章。废话少说,开始讲正题。从上一节我们知道home应用需要涉及文章,分类和标签三个部分,其实这就是个人博客系统最核心的功能:发表文章。下面我们分析一下数据库该如何设计?
1.4.1数据库设计
1.先从分类说起,从下图中我们知道一个博客中对文章有很多分类,因此分类需要作为单独的数据表,里面需要存储分类的id和名称。
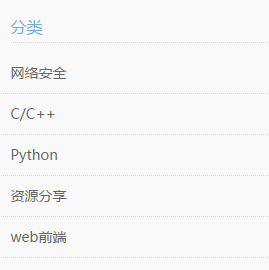
2.标签和分类类似,如下所示,博客有很多标签标记文章的主题,标签需要作为单独的数据表,里面需要存储标签的id和名称。

3.文章的存储是相对复杂的,从项目分析的图1.4可以看到,文章数据表需要存储文章的标题,内容,创建时间,修改时间,摘要,分类,标签,作者,浏览量和评论数,要存储的数据有几个需要注意:分类,标签和评论数。
首先在设计数据表时不考虑评论数,因为评论我们已经作为一个独立的应用,而且这和评论数据表与文章数据表的关系有关联,之后在讲评论功能时会说明。
文章数据表中有分类和标签的字段,如果大家有设计数据库的经历,此时应该很敏感,这时候需要考虑文章数据表与分类数据表,标签数据表的关系。
- 一个分类下可以有很多文章,而一篇文章只能有一个分类,这是一对多的关系。
- 一个标签下可以有很多文章,同样一篇文章可以有很多标签,这是多对多的关系。
通过上面的分析,我们使用Mysql Workbench设计如下三个数据表:Category表,Tag表和Article表,并描述了三个表之间的关系。
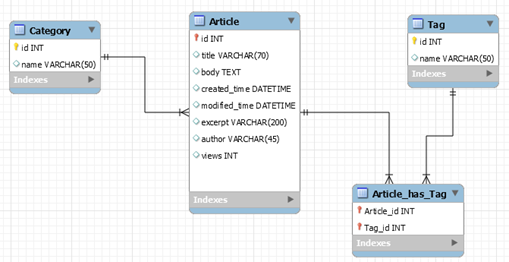
Category表通过外键与Acticle表相连,而Tag表与Article之间很特殊。大家会发现很奇怪,为什么设计了三个表,可是上图中却多出了一个Article_has_Tag表。这是为什么呢?其实这在数据库设计中很常见,描述两个表多对多的关系时,会生成一个中间表,将多对多的关系转化为两个表和中间表一对多的关系,这样可以使用外键将表联系起来。不过在代码实现时,是不用体现类似Acticle_has_Tag中间表的,Django会帮我们完成,咱们继续往下看。
1.4.2编写数据库模型
打开home应用下的models.py文件,这个文件是专门用来描述应用的数据库模型。
由于通过ORM的方式,因此在models中一个类即是一个数据表,一个属性对应着数据表中的字段。下面先把Category表列一下:
class Category(models.Model):
#分类名称
name = models.CharField(max_length=50,verbose_name="分类名称")
在上面的代码中,定义一个数据库模型,需要继承models.Model类,name是类中的一个属性,它是models.CharField的一个实例,对应着Category数据表中name字段。在1.4.1节中,设计的Category数据表中还有id字段,由于Django会默认创建id字段作为主键,这里我们不用再声明。models.CharField类的的初始化参数max_length代表着这存储数据的最大长度,verbose_name用来对name属性进行描述,在界面显示时有用。CharField主要用来存储短文本,可以看做是数据库中的varchar(50)。同样的道理,Tag类的内容如下:
class Tag(models.Model):
# 名称
name = models.CharField(max_length=50,verbose_name="标签名称")
下面定义复杂的Acticle表,一定要看注释。内容如下:
class Article(models.Model):
# 文章标题
title = models.CharField(max_length=70,verbose_name="文章标题")
#文章内容
body = models.TextField(verbose_name="文章内容",default='')
#创建时间
created_time = models.DateTimeField(verbose_name="创建时间")
# 修改时间
modified_time = models.DateTimeField(verbose_name="修改时间")
# 摘要
excerpt = models.CharField(max_length=200, blank=True,verbose_name="摘要")
# 分类
category = models.ForeignKey(Category,verbose_name="分类")
# 标签
tags = models.ManyToManyField(Tag, blank=True,verbose_name=u"标签")
# 作者
author = models.ForeignKey(User,verbose_name="作者")
#浏览量
views = models.PositiveIntegerField(defalut=0verbose_name="浏览量")
在上面的代码中主要有几点需要说明:
- body使用TextField来描述,它和CharField不同,用来存储大段的文本,default参数是用来设置字段的默认值,body默认设置为空。
- created_time和modified_time使用DateTimeField来表述,用来存储日期,大家可以想想数据库中用什么类型存储时间呢。
- excerpt用来存储文章的摘要,blank=True参数的意思是用来说明此字段可以为空值。
- category用来表示分类,通过传入Category类实例化ForeignKey,来描述一对多的关系。
- tags表示文章标签,通过传入Tag类实例化ManyToManyField,来表述多对多的关系,同时传入blank=True来设置可以为空。
- author表示文章作者,大家会发现我们使用了外键,这是因为User是Django内置的数据模型,从django.contrib.auth.models中导入的,专门用来负责用户信息的处理,本质上User就是一个数据表。一个作者可以拥有很多文章,而一篇文章只能有一个作者,是一对多的关系,因此使用外键和User数据模型建立联系。
- Views表示浏览量,通过实例化models.PositiveIntegerField来实现,PositiveIntegerField该类型只允许正整数和0,也就是说Views>=0。
经过以上的分析,数据模型基本上建立起来了,不过这还没有结束,因为还没有完成模型到真实数据库的迁移。接下来要做的是配置数据库,完成代码到数据库的“翻译”。
1.4.3数据库模型迁移
打开CoolBlog工程CoolBlog目录下的settings.py文件,其中Django已经默认配置好了sqlite3数据库。

DATABASES变量用来配置数据库,ENGINE代表使用数据库引擎,NAME对于sqlite3这种单文件数据库来说,代表着它的存储路径。但是这次我们不用默认的sqlite3数据库,在稍微大型的项目中,Mysql才是标配。首先使用Navicat for MySQL打开MySQL,新建一个coolblog数据库。

新建成功后,咱们接着在settings.py文件中配置MySQL。修改如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'coolblog',#数据库名称
'USER':'root',#用户名
'PASSWORD':'',#密码为空
'HOST':'127.0.0.1',#主机
'PORT':'3308'#端口
}
}
大家根据自己的MySQL进行配置。如果不想用MySQL,可以依然保持原样。配置完成后,开始进行通过Django提供的命令进行数据库迁移。激活虚拟环境,并切换到CoolBlog项目下,首先运行 python manage.py makemigrations命令会报出如下的错误,大致的意思是缺少MySQLdb模块。

由于我们使用MySQL作为数据库迁移,需要安装python版本MySQL引擎,Django默认使用MySQLdb。接下来理所当然是安装MySQLdb,但是作为有安装经验的人,很负责任地告诉大家MySQLdb在Windows平台下安装很不方便,尤其是有多个Python版本的时候,坑很多,因此我们这里不使用MySQLdb,我们使用另外一个更加友好流行的引擎:PyMySQL。我们在虚拟环境中运行:pip3 install pymysql。安装成功后,我们需要在与settings.py同级目录的__init__文件中加入以下代码:
import pymysql
pymysql.install_as_MySQLdb()
这样就将Django默认的MySQLdb进行了替换。下面接着运行python manage.py makemigrations和python manage.py migrate命令。执行效果如下图所示:
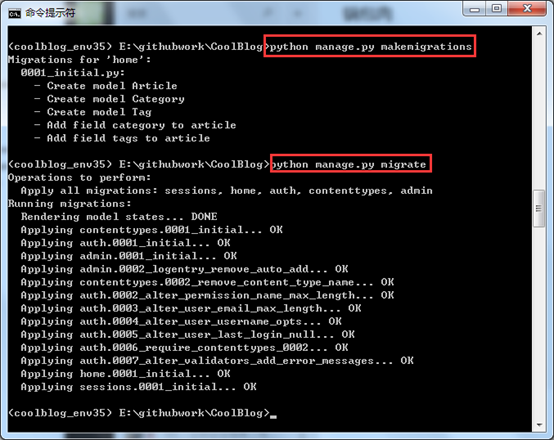
这样就完成了数据库模型的迁移,那咱们看看数据库有没有新建的表?下图所示,Django已经帮助我们完成了数据库的迁移,里面是不是还有之前说的中间表!

下面给大家讲解一下上面两条数据模型迁移命令到底干了些什么事情?
- makemigrations命令:是用来记录应用数据模型的改动,这些改动会记录到应用所在目录的migrations文件夹下,大家会看到里面产生了一些python文件,比如初次生成的0001_initial.py文件。
- migrate命令才是真正意义上将应用数据模型映射到数据库中,Django通过检测migrations文件夹下的文件,就可以知道我们对数据模型做了哪些修改,然后Django将这些改动翻译成SQL语句,并作用于数据库。比如home应用,migrate命令其实是在检查刚才makemigrations命令生成的0001_initial.py脚本,将这些改动应用到数据库中。
那Django将这些模型的改动翻译成什么样的SQL语句呢?我么可以通过sqlmigrate 命令进行查看。在命令行中执行:python manage.py sqlmigrate home 0001。如下图所示。
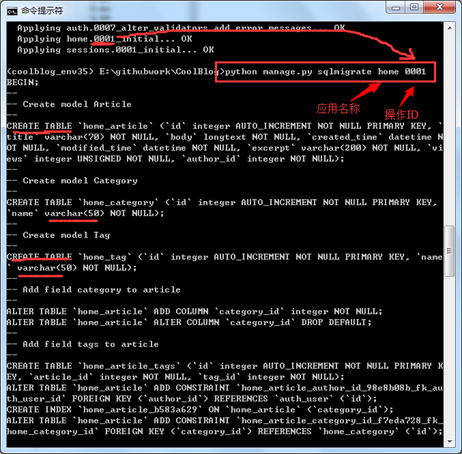
大家有没有发现,除了home应用的数据库模型进行了迁移,还有很多数据的改动,其实这是为Django内置的应用进行数据模型的迁移。大家可以和settings.py中的INSTALLED_APPS变量联系起来看。
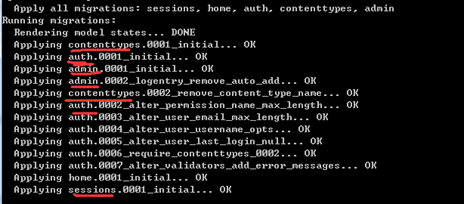
本节课程结束了,下一节咱们接着讲,要涉及到请求与响应方面的内容了。
最后
我新书《Python爬虫开发与项目实战》出版了。 这本书包括基础篇,中级篇和深入篇三个部分,不仅适合零基础的朋友入门,也适合有一定基础的爬虫爱好者进阶,如果你不会分布式爬虫,不会千万级数据的去重,不会怎么突破反爬虫,不会分析js的加密,这本书会给你惊喜。如果大家对这本书感兴趣的话,可以看一下 试读样章。

欢迎大家支持我公众号:

CoolBlog开发笔记第4课:数据库模型设计的更多相关文章
- CoolBlog开发笔记第5课:请求与响应
教程目录 1.1 CoolBlog开发笔记第1课:项目分析 1.2 CoolBlog开发笔记第2课:搭建开发环境 1.3 CoolBlog开发笔记第3课:创建Django应用 1.4 CoolBlog ...
- CoolBlog开发笔记第3课:创建Django应用
教程目录 1.1 CoolBlog开发笔记第1课:项目分析 1.2 CoolBlog开发笔记第2课:搭建开发环境 前言 经过上一节我们已经创建了CoolBlog工程,但是关于CoolBlog的功能代码 ...
- CoolBlog开发笔记第2课:搭建开发环境
教程目录 1.1 CoolBlog开发笔记第1课:项目分析 前言 今天是CoolBlog开发笔记的第2课,我们将要讲解的是开发环境的搭建.俗话说"工欲善其事必先利其器",Djang ...
- CoolBlog开发笔记第1课:项目分析
首先说一下CoolBlog开发笔记是我制作的<Django实战项目>系列教程基础篇的内容,使用Django来开发一个酷炫的个人博客,涉及的知识包括项目的分析,环境的搭建,模型和视图定义等等 ...
- [转至云风的博客]开发笔记 (2) :redis 数据库结构设计
接上回,按照我们一期项目的需求,昨天我简单设计了数据库里的数据格式.数据库采用的是 Redis ,我把它看成一个远端的数据结构保存设备.它提供基本的 Key-Value 储存功能,没有层级表.如果需要 ...
- odoo开发笔记 -- odoo和postgresql数据库导入相关
odoo数据库 导入.导出 首先odoo框架下postgresql数据库中,表结构的存储方式: 存在id(小写),并没有所谓的外部ID 例如数据库中的国家表:模块名_tb_country (注意: ...
- 【开发笔记】- 将MySQL数据库表中自增ID从0开始
命令: 用于清空某表的数据 且让自增的id重新从0开始 truncate table 你的表名
- 第16课-数据库开发及ado.net-数据库SQl,创建数据库和表,增删改语句,约束,top和Distinct,聚合函数介绍
第16课-数据库开发及ado.net 数据库SQl,创建数据库和表,增删改语句,约束,top和Distinct,聚合函数介绍 SQL语句入门(脚本.命令) SQL全名是结构化查询语言(Structur ...
- Android开发笔记:打包数据库
对于数据比较多的控制一般会加入SQLite数据库进行数据存储,在打包时这些数据库是不自动打包到apk中的,如何创建数据库呢 方法1:将创建数据库的sql语句在SQLiteHelper继承类中实现,在第 ...
随机推荐
- OC中的私有变量和私有方法
在类的实现即.m文件中也可以声明成员变量,但是因为在其他文件中通常都只是包含头文件而不会包含实现文件,所以在.m文件中声明的成员变量是@private得.在 .m中定义的成员变量不能和它的头文件.h中 ...
- vue2.0结合Element实现select动态控制input禁用
今天有一个盆友问小颖,怎么实现用select动态控制input禁用,也就是说,input默认是可编辑的,但是每当我选一次select,input就会变成禁用,虽然小颖不知道她为什么这样做,因为小颖觉得 ...
- AFNetworking源码阅读
get方法: - (NSURLSessionDataTask *)GET:(NSString *)URLString parameters:(id)parameters progress:(void ...
- gitlab 取消注册功能
gitlab 默认安装完成以后是允许用户注册,公司内部使用所以准备禁用了注册功能,只允许管理员从后台开通权限: 1.进入"Admin Area" 2.在左边菜单栏最低下点击&quo ...
- 深入理解Struts2----数据校验
在表现层的数据处理方面主要分为两种类型,一种是类型转换,这点我们上篇已经简单介绍过,另外一种则是我们本篇文章将要介绍的:数据校验.对于我们的web应用,我们经常需要和用户进行交互收集用户信息,那么无论 ...
- java关键字transient与volatile小结
本文转自:http://heaven-arch.iteye.com/blog/1160693 transient和volatile两个关键字一个用于对象序列化,一个用于线程同步,都是Java中比较高阶 ...
- 取代netcat
前言 众所周知,netcat是网络界的瑞士军刀,它的主要作用是:提供连接其他终端的方法,可以上传文件,反弹shell等等各种利于别人控制你电脑的操作.所以聪明的系统管理员会将它从系统中移除,这样当别人 ...
- 【.net 深呼吸】通过标准输入/输出流来完成进程间通信
实现进程之间煲电话粥的方式,有好几种,比如,你可以用这些方案: 1.使用socket来传递.这个好像很无聊,本地进程之间也用socket?不过,通过本机回环网络确实可以进程之间通信. 2.WCF,与上 ...
- Random Forest Classification of Mushrooms
There is a plethora of classification algorithms available to people who have a bit of coding experi ...
- 安卓ios和angularjs相互调用解决首次调用ios传递标题失败的问题
1.angular 调用客户端方法放在 try catch中 try { js_invoke.showShareDialog(angular.toJson(obj)); // 在这里放客户端的方法即 ...